 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Computational Hardness of Transformers
Mar 11, 2026The transformer has revolutionized modern AI across language, vision, and beyond. It consists of $L$ layers, each running $H$ attention heads in parallel and feeding the combined output to the subsequent layer. In attention, the input consists of $N$ tokens, each a vector of dimension $m$. The attention mechanism involves multiplying three $N \times m$ matrices, applying softmax to an intermediate product. Several recent works have advanced our understanding of the complexity of attention. Known algorithms for transformers compute each attention head independently. This raises a fundamental question that has recurred throughout TCS under the guise of ``direct sum'' problems: can multiple instances of the same problem be solved more efficiently than solving each instance separately? Many answers to this question, both positive and negative, have arisen in fields spanning communication complexity and algorithm design. Thus, we ask whether transformers can be computed more efficiently than $LH$ independent evaluations of attention. In this paper, we resolve this question in the negative, and give the first non-trivial computational lower bounds for multi-head multi-layer transformers. In the small embedding regime ($m = N^{o(1)}$), computing $LH$ attention heads separately takes $LHN^{2 + o(1)}$ time. We establish that this is essentially optimal under SETH. In the large embedding regime ($m = N$), one can compute $LH$ attention heads separately using $LHN^{ω+ o(1)}$ arithmetic operations (plus exponents), where $ω$ is the matrix multiplication exponent. We establish that this is optimal, by showing that $LHN^{ω- o(1)}$ arithmetic operations are necessary when $ω> 2$. Our lower bound in the large embedding regime relies on a novel application of the Baur-Strassen theorem, a powerful algorithmic tool underpinning the famous backpropagation algorithm.
Fast attention mechanisms: a tale of parallelism
Sep 10, 2025Transformers have the representational capacity to simulate Massively Parallel Computation (MPC) algorithms, but they suffer from quadratic time complexity, which severely limits their scalability. We introduce an efficient attention mechanism called Approximate Nearest Neighbor Attention (ANNA) with sub-quadratic time complexity. We prove that ANNA-transformers (1) retain the expressive power previously established for standard attention in terms of matching the capabilities of MPC algorithms, and (2) can solve key reasoning tasks such as Match2 and $k$-hop with near-optimal depth. Using the MPC framework, we further prove that constant-depth ANNA-transformers can simulate constant-depth low-rank transformers, thereby providing a unified way to reason about a broad class of efficient attention approximations.
Two heads are better than one: simulating large transformers with small ones
Jun 13, 2025The quadratic complexity of self-attention prevents transformers from scaling effectively to long input sequences. On the other hand, modern GPUs and other specialized hardware accelerators are well-optimized for processing small input sequences in transformers during both training and inference. A natural question arises: can we take advantage of the efficiency of small transformers to deal with long input sequences? In this paper, we show that transformers with long input sequences (large transformers) can be efficiently simulated by transformers that can only take short input sequences (small transformers). Specifically, we prove that any transformer with input length $N$ can be efficiently simulated by only $O((N/M)^2)$ transformers with input length $M \ll N$, and that this cannot be improved in the worst case. However, we then prove that in various natural scenarios including average-case inputs, sliding window masking and attention sinks, the optimal number $O(N/M)$ of small transformers suffice.
Fundamental Limitations on Subquadratic Alternatives to Transformers
Oct 05, 2024The Transformer architecture is widely deployed in many popular and impactful Large Language Models. At its core is the attention mechanism for calculating correlations between pairs of tokens. Performing an attention computation takes quadratic time in the input size, and had become the time bottleneck for transformer operations. In order to circumvent this, researchers have used a variety of approaches, including designing heuristic algorithms for performing attention computations faster, and proposing alternatives to the attention mechanism which can be computed more quickly. For instance, state space models such as Mamba were designed to replace attention with an almost linear time alternative. In this paper, we prove that any such approach cannot perform important tasks that Transformer is able to perform (assuming a popular conjecture from fine-grained complexity theory). We focus on document similarity tasks, where one is given as input many documents and would like to find a pair which is (approximately) the most similar. We prove that Transformer is able to perform this task, and we prove that this task cannot be performed in truly subquadratic time by any algorithm. Thus, any model which can be evaluated in subquadratic time - whether because of subquadratic-time heuristics for attention, faster attention replacements like Mamba, or any other reason - cannot perform this task. In other words, in order to perform tasks that (implicitly or explicitly) involve document similarity, one may as well use Transformer and cannot avoid its quadratic running time.
Robust Empirical Risk Minimization with Tolerance
Oct 02, 2022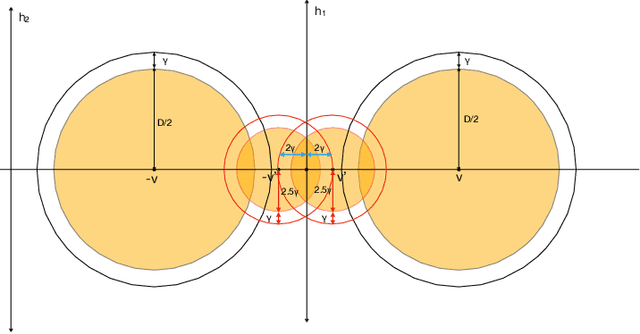
Developing simple, sample-efficient learning algorithms for robust classification is a pressing issue in today's tech-dominated world, and current theoretical techniques requiring exponential sample complexity and complicated improper learning rules fall far from answering the need. In this work we study the fundamental paradigm of (robust) $\textit{empirical risk minimization}$ (RERM), a simple process in which the learner outputs any hypothesis minimizing its training error. RERM famously fails to robustly learn VC classes (Montasser et al., 2019a), a bound we show extends even to `nice' settings such as (bounded) halfspaces. As such, we study a recent relaxation of the robust model called $\textit{tolerant}$ robust learning (Ashtiani et al., 2022) where the output classifier is compared to the best achievable error over slightly larger perturbation sets. We show that under geometric niceness conditions, a natural tolerant variant of RERM is indeed sufficient for $\gamma$-tolerant robust learning VC classes over $\mathbb{R}^d$, and requires only $\tilde{O}\left( \frac{VC(H)d\log \frac{D}{\gamma\delta}}{\epsilon^2}\right)$ samples for robustness regions of (maximum) diameter $D$.
Active Learning Polynomial Threshold Functions
Jan 24, 2022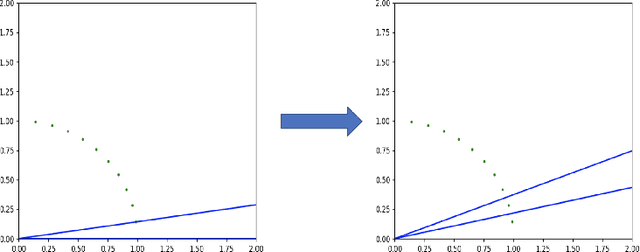
We initiate the study of active learning polynomial threshold functions (PTFs). While traditional lower bounds imply that even univariate quadratics cannot be non-trivially actively learned, we show that allowing the learner basic access to the derivatives of the underlying classifier circumvents this issue and leads to a computationally efficient algorithm for active learning degree-$d$ univariate PTFs in $\tilde{O}(d^3\log(1/\varepsilon\delta))$ queries. We also provide near-optimal algorithms and analyses for active learning PTFs in several average case settings. Finally, we prove that access to derivatives is insufficient for active learning multivariate PTFs, even those of just two variables.