 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of boosted and resolved multi-Higgs-boson events with symmetry-preserving attention networks
Dec 05, 2024



The production of multiple Higgs bosons at the CERN LHC provides a direct way to measure the trilinear and quartic Higgs self-interaction strengths as well as potential access to beyond the standard model effects that can enhance production at large transverse momentum $p_{\mathrm{T}}$. The largest event fraction arises from the fully hadronic final state in which every Higgs boson decays to a bottom quark-antiquark pair ($b\bar{b}$). This introduces a combinatorial challenge known as the \emph{jet assignment problem}: assigning jets to sets representing Higgs boson candidates. Symmetry-preserving attention networks (SPA-Nets) have been been developed to address this challenge. However, the complexity of jet assignment increases when simultaneously considering both $H\rightarrow b\bar{b}$ reconstruction possibilities, i.e., two "resolved" small-radius jets each containing a shower initiated by a $b$-quark or one "boosted" large-radius jet containing a merged shower initiated by a $b\bar{b}$ pair. The latter improves the reconstruction efficiency at high $p_{\mathrm{T}}$. In this work, we introduce a generalization to the SPA-Net approach to simultaneously consider both boosted and resolved reconstruction possibilities and unambiguously interpret an event as "fully resolved'', "fully boosted", or in between. We report the performance of baseline methods, the original SPA-Net approach, and our generalized version on nonresonant $HH$ and $HHH$ production at the LHC. Considering both boosted and resolved topologies, our SPA-Net approach increases the Higgs boson reconstruction purity by 57--62\% and the efficiency by 23--38\% compared to the baseline method depending on the final state.
The Landscape of Unfolding with Machine Learning
Apr 29, 2024



Recent innovations from machine learning allow for data unfolding, without binning and including correlations across many dimensions. We describe a set of known, upgraded, and new methods for ML-based unfolding. The performance of these approaches are evaluated on the same two datasets. We find that all techniques are capable of accurately reproducing the particle-level spectra across complex observables. Given that these approaches are conceptually diverse, they offer an exciting toolkit for a new class of measurements that can probe the Standard Model with an unprecedented level of detail and may enable sensitivity to new phenomena.
Full Event Particle-Level Unfolding with Variable-Length Latent Variational Diffusion
Apr 22, 2024



The measurements performed by particle physics experiments must account for the imperfect response of the detectors used to observe the interactions. One approach, unfolding, statistically adjusts the experimental data for detector effects. Recently, generative machine learning models have shown promise for performing unbinned unfolding in a high number of dimensions. However, all current generative approaches are limited to unfolding a fixed set of observables, making them unable to perform full-event unfolding in the variable dimensional environment of collider data. A novel modification to the variational latent diffusion model (VLD) approach to generative unfolding is presented, which allows for unfolding of high- and variable-dimensional feature spaces. The performance of this method is evaluated in the context of semi-leptonic top quark pair production at the Large Hadron Collider.
Function Approximation for Reinforcement Learning Controller for Energy from Spread Waves
Apr 17, 2024



The industrial multi-generator Wave Energy Converters (WEC) must handle multiple simultaneous waves coming from different directions called spread waves. These complex devices in challenging circumstances need controllers with multiple objectives of energy capture efficiency, reduction of structural stress to limit maintenance, and proactive protection against high waves. The Multi-Agent Reinforcement Learning (MARL) controller trained with the Proximal Policy Optimization (PPO) algorithm can handle these complexities. In this paper, we explore different function approximations for the policy and critic networks in modeling the sequential nature of the system dynamics and find that they are key to better performance. We investigated the performance of a fully connected neural network (FCN), LSTM, and Transformer model variants with varying depths and gated residual connections. Our results show that the transformer model of moderate depth with gated residual connections around the multi-head attention, multi-layer perceptron, and the transformer block (STrXL) proposed in this paper is optimal and boosts energy efficiency by an average of 22.1% for these complex spread waves over the existing spring damper (SD) controller. Furthermore, unlike the default SD controller, the transformer controller almost eliminated the mechanical stress from the rotational yaw motion for angled waves. Demo: https://tinyurl.com/yueda3jh
* IJCAI 2023, Proceedings of the Thirty-Second International Joint Conference on Artificial IntelligenceAugust 2023
AI for Interpretable Chemistry: Predicting Radical Mechanistic Pathways via Contrastive Learning
Nov 02, 2023



Deep learning-based reaction predictors have undergone significant architectural evolution. However, their reliance on reactions from the US Patent Office results in a lack of interpretable predictions and limited generalization capability to other chemistry domains, such as radical and atmospheric chemistry. To address these challenges, we introduce a new reaction predictor system, RMechRP, that leverages contrastive learning in conjunction with mechanistic pathways, the most interpretable representation of chemical reactions. Specifically designed for radical reactions, RMechRP provides different levels of interpretation of chemical reactions. We develop and train multiple deep-learning models using RMechDB, a public database of radical reactions, to establish the first benchmark for predicting radical reactions. Our results demonstrate the effectiveness of RMechRP in providing accurate and interpretable predictions of radical reactions, and its potential for various applications in atmospheric chemistry.
RTDK-BO: High Dimensional Bayesian Optimization with Reinforced Transformer Deep kernels
Oct 09, 2023Bayesian Optimization (BO), guided by Gaussian process (GP) surrogates, has proven to be an invaluable technique for efficient, high-dimensional, black-box optimization, a critical problem inherent to many applications such as industrial design and scientific computing. Recent contributions have introduced reinforcement learning (RL) to improve the optimization performance on both single function optimization and \textit{few-shot} multi-objective optimization. However, even few-shot techniques fail to exploit similarities shared between closely related objectives. In this paper, we combine recent developments in Deep Kernel Learning (DKL) and attention-based Transformer models to improve the modeling powers of GP surrogates with meta-learning. We propose a novel method for improving meta-learning BO surrogates by incorporating attention mechanisms into DKL, empowering the surrogates to adapt to contextual information gathered during the BO process. We combine this Transformer Deep Kernel with a learned acquisition function trained with continuous Soft Actor-Critic Reinforcement Learning to aid in exploration. This Reinforced Transformer Deep Kernel (RTDK-BO) approach yields state-of-the-art results in continuous high-dimensional optimization problems.
Extended Symmetry Preserving Attention Networks for LHC Analysis
Sep 05, 2023Reconstructing unstable heavy particles requires sophisticated techniques to sift through the large number of possible permutations for assignment of detector objects to partons. An approach based on a generalized attention mechanism, symmetry preserving attention networks (SPANet), has been previously applied to top quark pair decays at the Large Hadron Collider, which produce six hadronic jets. Here we extend the SPANet architecture to consider multiple input streams, such as leptons, as well as global event features, such as the missing transverse momentum. In addition, we provide regression and classification outputs to supplement the parton assignment. We explore the performance of the extended capability of SPANet in the context of semi-leptonic decays of top quark pairs as well as top quark pairs produced in association with a Higgs boson. We find significant improvements in the power of three representative studies: search for ttH, measurement of the top quark mass and a search for a heavy Z' decaying to top quark pairs. We present ablation studies to provide insight on what the network has learned in each case.
End-To-End Latent Variational Diffusion Models for Inverse Problems in High Energy Physics
May 17, 2023High-energy collisions at the Large Hadron Collider (LHC) provide valuable insights into open questions in particle physics. However, detector effects must be corrected before measurements can be compared to certain theoretical predictions or measurements from other detectors. Methods to solve this \textit{inverse problem} of mapping detector observations to theoretical quantities of the underlying collision are essential parts of many physics analyses at the LHC. We investigate and compare various generative deep learning methods to approximate this inverse mapping. We introduce a novel unified architecture, termed latent variation diffusion models, which combines the latent learning of cutting-edge generative art approaches with an end-to-end variational framework. We demonstrate the effectiveness of this approach for reconstructing global distributions of theoretical kinematic quantities, as well as for ensuring the adherence of the learned posterior distributions to known physics constraints. Our unified approach achieves a distribution-free distance to the truth of over 20 times less than non-latent state-of-the-art baseline and 3 times less than traditional latent diffusion models.
Interpretable Joint Event-Particle Reconstruction for Neutrino Physics at NOvA with Sparse CNNs and Transformers
Mar 10, 2023



The complex events observed at the NOvA long-baseline neutrino oscillation experiment contain vital information for understanding the most elusive particles in the standard model. The NOvA detectors observe interactions of neutrinos from the NuMI beam at Fermilab. Associating the particles produced in these interaction events to their source particles, a process known as reconstruction, is critical for accurately measuring key parameters of the standard model. Events may contain several particles, each producing sparse high-dimensional spatial observations, and current methods are limited to evaluating individual particles. To accurately label these numerous, high-dimensional observations, we present a novel neural network architecture that combines the spatial learning enabled by convolutions with the contextual learning enabled by attention. This joint approach, TransformerCVN, simultaneously classifies each event and reconstructs every individual particle's identity. TransformerCVN classifies events with 90\% accuracy and improves the reconstruction of individual particles by 6\% over baseline methods which lack the integrated architecture of TransformerCVN. In addition, this architecture enables us to perform several interpretability studies which provide insights into the network's predictions and show that TransformerCVN discovers several fundamental principles that stem from the standard model.
Skip Training for Multi-Agent Reinforcement Learning Controller for Industrial Wave Energy Converters
Sep 13, 2022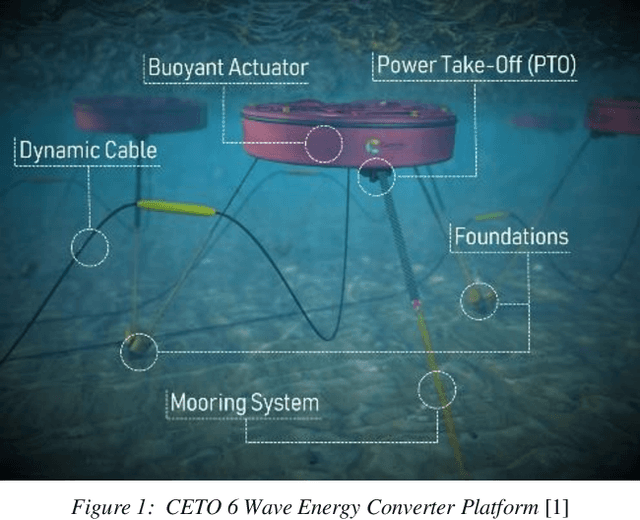
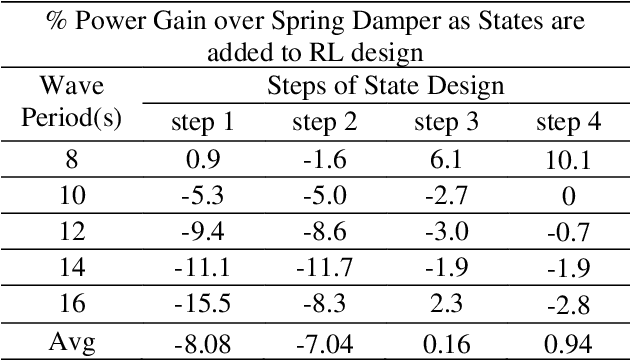
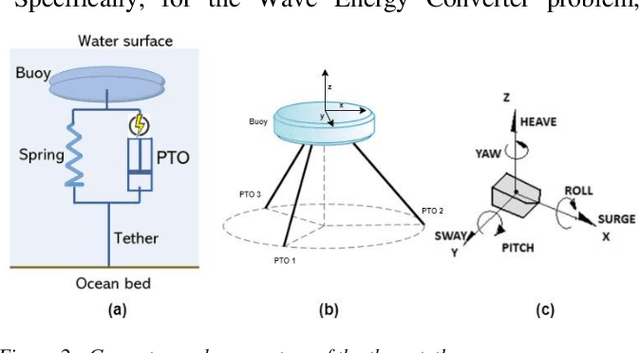
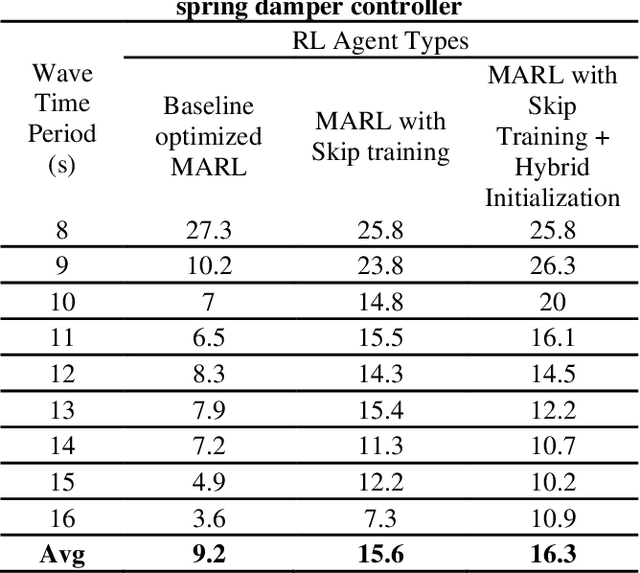
Recent Wave Energy Converters (WEC) are equipped with multiple legs and generators to maximize energy generation. Traditional controllers have shown limitations to capture complex wave patterns and the controllers must efficiently maximize the energy capture. This paper introduces a Multi-Agent Reinforcement Learning controller (MARL), which outperforms the traditionally used spring damper controller. Our initial studies show that the complex nature of problems makes it hard for training to converge. Hence, we propose a novel skip training approach which enables the MARL training to overcome performance saturation and converge to more optimum controllers compared to default MARL training, boosting power generation. We also present another novel hybrid training initialization (STHTI) approach, where the individual agents of the MARL controllers can be initially trained against the baseline Spring Damper (SD) controller individually and then be trained one agent at a time or all together in future iterations to accelerate convergence. We achieved double-digit gains in energy efficiency over the baseline Spring Damper controller with the proposed MARL controllers using the Asynchronous Advantage Actor-Critic (A3C) algorithm.