 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast 3D Surrogate Modeling for Data Center Thermal Management
Nov 13, 2025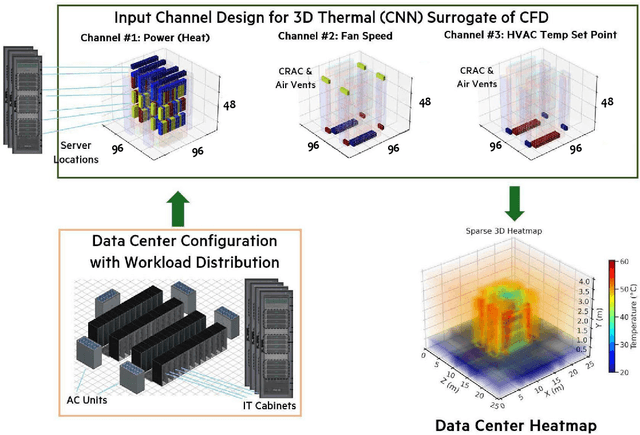
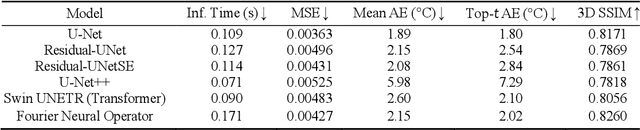


Reducing energy consumption and carbon emissions in data centers by enabling real-time temperature prediction is critical for sustainability and operational efficiency. Achieving this requires accurate modeling of the 3D temperature field to capture airflow dynamics and thermal interactions under varying operating conditions. Traditional thermal CFD solvers, while accurate, are computationally expensive and require expert-crafted meshes and boundary conditions, making them impractical for real-time use. To address these limitations, we develop a vision-based surrogate modeling framework that operates directly on a 3D voxelized representation of the data center, incorporating server workloads, fan speeds, and HVAC temperature set points. We evaluate multiple architectures, including 3D CNN U-Net variants, a 3D Fourier Neural Operator, and 3D vision transformers, to map these thermal inputs to high-fidelity heat maps. Our results show that the surrogate models generalize across data center configurations and achieve up to 20,000x speedup (hundreds of milliseconds vs. hours). This fast and accurate estimation of hot spots and temperature distribution enables real-time cooling control and workload redistribution, leading to substantial energy savings (7\%) and reduced carbon footprint.
Robustness Evaluation for Video Models with Reinforcement Learning
Jun 05, 2025Evaluating the robustness of Video classification models is very challenging, specifically when compared to image-based models. With their increased temporal dimension, there is a significant increase in complexity and computational cost. One of the key challenges is to keep the perturbations to a minimum to induce misclassification. In this work, we propose a multi-agent reinforcement learning approach (spatial and temporal) that cooperatively learns to identify the given video's sensitive spatial and temporal regions. The agents consider temporal coherence in generating fine perturbations, leading to a more effective and visually imperceptible attack. Our method outperforms the state-of-the-art solutions on the Lp metric and the average queries. Our method enables custom distortion types, making the robustness evaluation more relevant to the use case. We extensively evaluate 4 popular models for video action recognition on two popular datasets, HMDB-51 and UCF-101.
Coordinated Robustness Evaluation Framework for Vision-Language Models
Jun 05, 2025Vision-language models, which integrate computer vision and natural language processing capabilities, have demonstrated significant advancements in tasks such as image captioning and visual question and answering. However, similar to traditional models, they are susceptible to small perturbations, posing a challenge to their robustness, particularly in deployment scenarios. Evaluating the robustness of these models requires perturbations in both the vision and language modalities to learn their inter-modal dependencies. In this work, we train a generic surrogate model that can take both image and text as input and generate joint representation which is further used to generate adversarial perturbations for both the text and image modalities. This coordinated attack strategy is evaluated on the visual question and answering and visual reasoning datasets using various state-of-the-art vision-language models. Our results indicate that the proposed strategy outperforms other multi-modal attacks and single-modality attacks from the recent literature. Our results demonstrate their effectiveness in compromising the robustness of several state-of-the-art pre-trained multi-modal models such as instruct-BLIP, ViLT and others.
Hierarchical Multi-Agent Framework for Carbon-Efficient Liquid-Cooled Data Center Clusters
Feb 12, 2025Reducing the environmental impact of cloud computing requires efficient workload distribution across geographically dispersed Data Center Clusters (DCCs) and simultaneously optimizing liquid and air (HVAC) cooling with time shift of workloads within individual data centers (DC). This paper introduces Green-DCC, which proposes a Reinforcement Learning (RL) based hierarchical controller to optimize both workload and liquid cooling dynamically in a DCC. By incorporating factors such as weather, carbon intensity, and resource availability, Green-DCC addresses realistic constraints and interdependencies. We demonstrate how the system optimizes multiple data centers synchronously, enabling the scope of digital twins, and compare the performance of various RL approaches based on carbon emissions and sustainability metrics while also offering a framework and benchmark simulation for broader ML research in sustainability.
Reinforcement Learning Platform for Adversarial Black-box Attacks with Custom Distortion Filters
Jan 23, 2025



We present a Reinforcement Learning Platform for Adversarial Black-box untargeted and targeted attacks, RLAB, that allows users to select from various distortion filters to create adversarial examples. The platform uses a Reinforcement Learning agent to add minimum distortion to input images while still causing misclassification by the target model. The agent uses a novel dual-action method to explore the input image at each step to identify sensitive regions for adding distortions while removing noises that have less impact on the target model. This dual action leads to faster and more efficient convergence of the attack. The platform can also be used to measure the robustness of image classification models against specific distortion types. Also, retraining the model with adversarial samples significantly improved robustness when evaluated on benchmark datasets. The proposed platform outperforms state-of-the-art methods in terms of the average number of queries required to cause misclassification. This advances trustworthiness with a positive social impact.
SustainDC -- Benchmarking for Sustainable Data Center Control
Aug 14, 2024



Machine learning has driven an exponential increase in computational demand, leading to massive data centers that consume significant amounts of energy and contribute to climate change. This makes sustainable data center control a priority. In this paper, we introduce SustainDC, a set of Python environments for benchmarking multi-agent reinforcement learning (MARL) algorithms for data centers (DC). SustainDC supports custom DC configurations and tasks such as workload scheduling, cooling optimization, and auxiliary battery management, with multiple agents managing these operations while accounting for the effects of each other. We evaluate various MARL algorithms on SustainDC, showing their performance across diverse DC designs, locations, weather conditions, grid carbon intensity, and workload requirements. Our results highlight significant opportunities for improvement of data center operations using MARL algorithms. Given the increasing use of DC due to AI, SustainDC provides a crucial platform for the development and benchmarking of advanced algorithms essential for achieving sustainable computing and addressing other heterogeneous real-world challenges.
A Configurable Pythonic Data Center Model for Sustainable Cooling and ML Integration
Apr 18, 2024


There have been growing discussions on estimating and subsequently reducing the operational carbon footprint of enterprise data centers. The design and intelligent control for data centers have an important impact on data center carbon footprint. In this paper, we showcase PyDCM, a Python library that enables extremely fast prototyping of data center design and applies reinforcement learning-enabled control with the purpose of evaluating key sustainability metrics including carbon footprint, energy consumption, and observing temperature hotspots. We demonstrate these capabilities of PyDCM and compare them to existing works in EnergyPlus for modeling data centers. PyDCM can also be used as a standalone Gymnasium environment for demonstrating sustainability-focused data center control.
Function Approximation for Reinforcement Learning Controller for Energy from Spread Waves
Apr 17, 2024



The industrial multi-generator Wave Energy Converters (WEC) must handle multiple simultaneous waves coming from different directions called spread waves. These complex devices in challenging circumstances need controllers with multiple objectives of energy capture efficiency, reduction of structural stress to limit maintenance, and proactive protection against high waves. The Multi-Agent Reinforcement Learning (MARL) controller trained with the Proximal Policy Optimization (PPO) algorithm can handle these complexities. In this paper, we explore different function approximations for the policy and critic networks in modeling the sequential nature of the system dynamics and find that they are key to better performance. We investigated the performance of a fully connected neural network (FCN), LSTM, and Transformer model variants with varying depths and gated residual connections. Our results show that the transformer model of moderate depth with gated residual connections around the multi-head attention, multi-layer perceptron, and the transformer block (STrXL) proposed in this paper is optimal and boosts energy efficiency by an average of 22.1% for these complex spread waves over the existing spring damper (SD) controller. Furthermore, unlike the default SD controller, the transformer controller almost eliminated the mechanical stress from the rotational yaw motion for angled waves. Demo: https://tinyurl.com/yueda3jh
* IJCAI 2023, Proceedings of the Thirty-Second International Joint Conference on Artificial IntelligenceAugust 2023
Sustainability of Data Center Digital Twins with Reinforcement Learning
Apr 16, 2024



The rapid growth of machine learning (ML) has led to an increased demand for computational power, resulting in larger data centers (DCs) and higher energy consumption. To address this issue and reduce carbon emissions, intelligent design and control of DC components such as IT servers, cabinets, HVAC cooling, flexible load shifting, and battery energy storage are essential. However, the complexity of designing and controlling them in tandem presents a significant challenge. While some individual components like CFD-based design and Reinforcement Learning (RL) based HVAC control have been researched, there's a gap in the holistic design and optimization covering all elements simultaneously. To tackle this, we've developed DCRL-Green, a multi-agent RL environment that empowers the ML community to design data centers and research, develop, and refine RL controllers for carbon footprint reduction in DCs. It is a flexible, modular, scalable, and configurable platform that can handle large High Performance Computing (HPC) clusters. Furthermore, in its default setup, DCRL-Green provides a benchmark for evaluating single as well as multi-agent RL algorithms. It easily allows users to subclass the default implementations and design their own control approaches, encouraging community development for sustainable data centers. Open Source Link: https://github.com/HewlettPackard/dc-rl
* 2024 Proceedings of the AAAI Conference on Artificial Intelligence
Robustness and Visual Explanation for Black Box Image, Video, and ECG Signal Classification with Reinforcement Learning
Mar 27, 2024We present a generic Reinforcement Learning (RL) framework optimized for crafting adversarial attacks on different model types spanning from ECG signal analysis (1D), image classification (2D), and video classification (3D). The framework focuses on identifying sensitive regions and inducing misclassifications with minimal distortions and various distortion types. The novel RL method outperforms state-of-the-art methods for all three applications, proving its efficiency. Our RL approach produces superior localization masks, enhancing interpretability for image classification and ECG analysis models. For applications such as ECG analysis, our platform highlights critical ECG segments for clinicians while ensuring resilience against prevalent distortions. This comprehensive tool aims to bolster both resilience with adversarial training and transparency across varied applications and data types.
* AAAI Proceedings reference: https://ojs.aaai.org/index.php/AAAI/article/view/30579