 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Complex Tasks for Goal-Directed Interactive Agents
Sep 27, 2024Goal-directed interactive agents, which autonomously complete tasks through interactions with their environment, can assist humans in various domains of their daily lives. Recent advances in large language models (LLMs) led to a surge of new, more and more challenging tasks to evaluate such agents. To properly contextualize performance across these tasks, it is imperative to understand the different challenges they pose to agents. To this end, this survey compiles relevant tasks and environments for evaluating goal-directed interactive agents, structuring them along dimensions relevant for understanding current obstacles. An up-to-date compilation of relevant resources can be found on our project website: https://coli-saar.github.io/interactive-agents.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
Jul 26, 2024



Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs, but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment. However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built $\textbf{AppWorld Engine}$, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users. We then created $\textbf{AppWorld Benchmark}$ (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage. The state-of-the-art LLM, GPT-4o, solves only ~49% of our 'normal' tasks and ~30% of 'challenge' tasks, while other models solve at least 16% fewer. This highlights the benchmark's difficulty and AppWorld's potential to push the frontiers of interactive coding agents. The project website is available at https://appworld.dev/.
Adapting Multilingual LLMs to Low-Resource Languages with Knowledge Graphs via Adapters
Jul 01, 2024



This paper explores the integration of graph knowledge from linguistic ontologies into multilingual Large Language Models (LLMs) using adapters to improve performance for low-resource languages (LRLs) in sentiment analysis (SA) and named entity recognition (NER). Building upon successful parameter-efficient fine-tuning techniques, such as K-ADAPTER and MAD-X, we propose a similar approach for incorporating knowledge from multilingual graphs, connecting concepts in various languages with each other through linguistic relationships, into multilingual LLMs for LRLs. Specifically, we focus on eight LRLs -- Maltese, Bulgarian, Indonesian, Nepali, Javanese, Uyghur, Tibetan, and Sinhala -- and employ language-specific adapters fine-tuned on data extracted from the language-specific section of ConceptNet, aiming to enable knowledge transfer across the languages covered by the knowledge graph. We compare various fine-tuning objectives, including standard Masked Language Modeling (MLM), MLM with full-word masking, and MLM with targeted masking, to analyse their effectiveness in learning and integrating the extracted graph data. Through empirical evaluation on language-specific tasks, we assess how structured graph knowledge affects the performance of multilingual LLMs for LRLs in SA and NER, providing insights into the potential benefits of adapting language models for low-resource scenarios.
ADaPT: As-Needed Decomposition and Planning with Language Models
Nov 08, 2023Large Language Models (LLMs) are increasingly being used for interactive decision-making tasks requiring planning and adapting to the environment. Recent works employ LLMs-as-agents in broadly two ways: iteratively determining the next action (iterative executors) or generating plans and executing sub-tasks using LLMs (plan-and-execute). However, these methods struggle with task complexity, as the inability to execute any sub-task may lead to task failure. To address these shortcomings, we introduce As-Needed Decomposition and Planning for complex Tasks (ADaPT), an approach that explicitly plans and decomposes complex sub-tasks as-needed, i.e., when the LLM is unable to execute them. ADaPT recursively decomposes sub-tasks to adapt to both task complexity and LLM capability. Our results demonstrate that ADaPT substantially outperforms established strong baselines, achieving success rates up to 28.3% higher in ALFWorld, 27% in WebShop, and 33% in TextCraft -- a novel compositional dataset that we introduce. Through extensive analysis, we illustrate the importance of multilevel decomposition and establish that ADaPT dynamically adjusts to the capabilities of the executor LLM as well as to task complexity.
Putting Humans in the Image Captioning Loop
Jun 06, 2023Image Captioning (IC) models can highly benefit from human feedback in the training process, especially in cases where data is limited. We present work-in-progress on adapting an IC system to integrate human feedback, with the goal to make it easily adaptable to user-specific data. Our approach builds on a base IC model pre-trained on the MS COCO dataset, which generates captions for unseen images. The user will then be able to offer feedback on the image and the generated/predicted caption, which will be augmented to create additional training instances for the adaptation of the model. The additional instances are integrated into the model using step-wise updates, and a sparse memory replay component is used to avoid catastrophic forgetting. We hope that this approach, while leading to improved results, will also result in customizable IC models.
Towards Adaptable and Interactive Image Captioning with Data Augmentation and Episodic Memory
Jun 06, 2023



Interactive machine learning (IML) is a beneficial learning paradigm in cases of limited data availability, as human feedback is incrementally integrated into the training process. In this paper, we present an IML pipeline for image captioning which allows us to incrementally adapt a pre-trained image captioning model to a new data distribution based on user input. In order to incorporate user input into the model, we explore the use of a combination of simple data augmentation methods to obtain larger data batches for each newly annotated data instance and implement continual learning methods to prevent catastrophic forgetting from repeated updates. For our experiments, we split a domain-specific image captioning dataset, namely VizWiz, into non-overlapping parts to simulate an incremental input flow for continually adapting the model to new data. We find that, while data augmentation worsens results, even when relatively small amounts of data are available, episodic memory is an effective strategy to retain knowledge from previously seen clusters.
Cross-lingual German Biomedical Information Extraction: from Zero-shot to Human-in-the-Loop
Jan 24, 2023

This paper presents our project proposal for extracting biomedical information from German clinical narratives with limited amounts of annotations. We first describe the applied strategies in transfer learning and active learning for solving our problem. After that, we discuss the design of the user interface for both supplying model inspection and obtaining user annotations in the interactive environment.
A survey on improving NLP models with human explanations
Apr 19, 2022
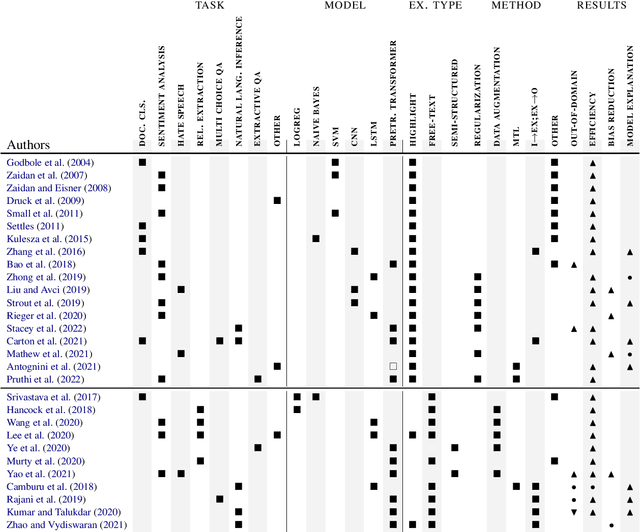
Training a model with access to human explanations can improve data efficiency and model performance on in- and out-of-domain data. Adding to these empirical findings, similarity with the process of human learning makes learning from explanations a promising way to establish a fruitful human-machine interaction. Several methods have been proposed for improving natural language processing (NLP) models with human explanations, that rely on different explanation types and mechanism for integrating these explanations into the learning process. These methods are rarely compared with each other, making it hard for practitioners to choose the best combination of explanation type and integration mechanism for a specific use-case. In this paper, we give an overview of different methods for learning from human explanations, and discuss different factors that can inform the decision of which method to choose for a specific use-case.
Interactive Machine Learning for Image Captioning
Feb 28, 2022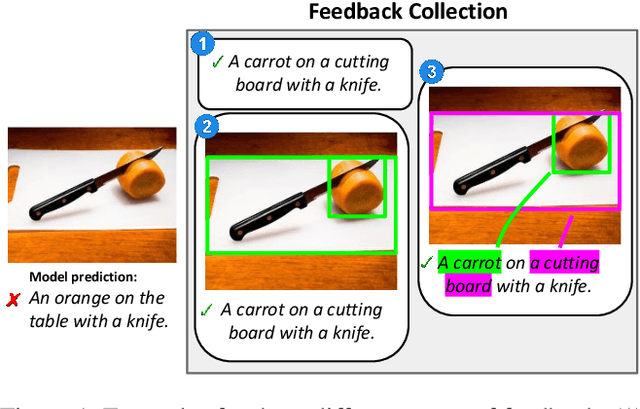
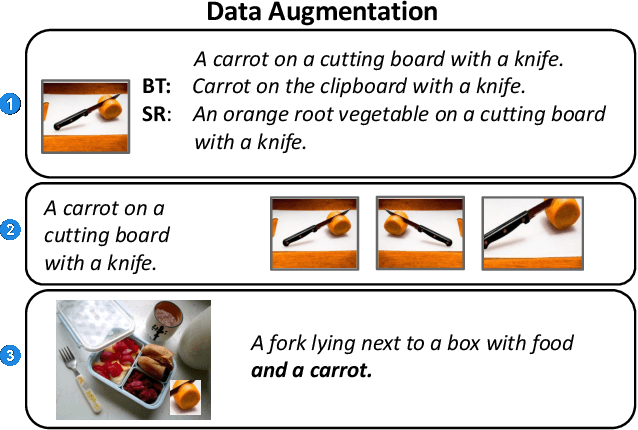
We propose an approach for interactive learning for an image captioning model. As human feedback is expensive and modern neural network based approaches often require large amounts of supervised data to be trained, we envision a system that exploits human feedback as good as possible by multiplying the feedback using data augmentation methods, and integrating the resulting training examples into the model in a smart way. This approach has three key components, for which we need to find suitable practical implementations: feedback collection, data augmentation, and model update. We outline our idea and review different possibilities to address these tasks.
MDAPT: Multilingual Domain Adaptive Pretraining in a Single Model
Sep 14, 2021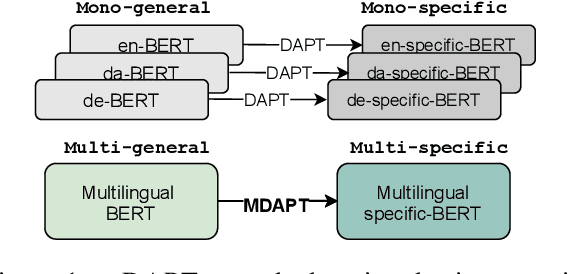
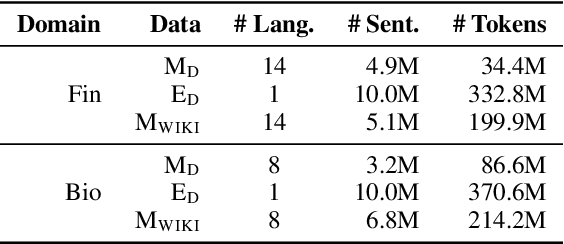
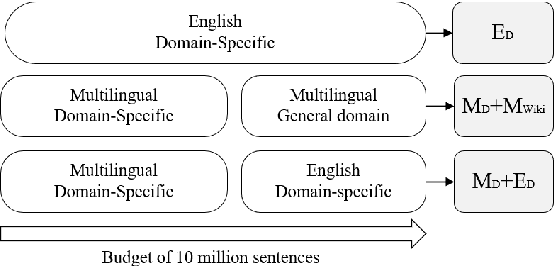
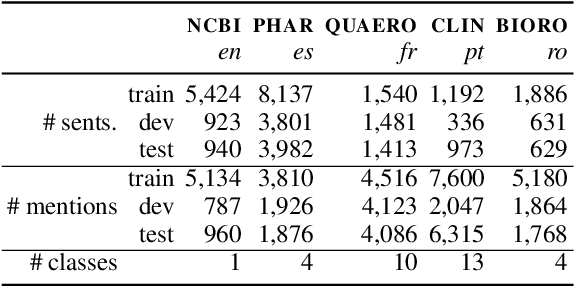
Domain adaptive pretraining, i.e. the continued unsupervised pretraining of a language model on domain-specific text, improves the modelling of text for downstream tasks within the domain. Numerous real-world applications are based on domain-specific text, e.g. working with financial or biomedical documents, and these applications often need to support multiple languages. However, large-scale domain-specific multilingual pretraining data for such scenarios can be difficult to obtain, due to regulations, legislation, or simply a lack of language- and domain-specific text. One solution is to train a single multilingual model, taking advantage of the data available in as many languages as possible. In this work, we explore the benefits of domain adaptive pretraining with a focus on adapting to multiple languages within a specific domain. We propose different techniques to compose pretraining corpora that enable a language model to both become domain-specific and multilingual. Evaluation on nine domain-specific datasets-for biomedical named entity recognition and financial sentence classification-covering seven different languages show that a single multilingual domain-specific model can outperform the general multilingual model, and performs close to its monolingual counterpart. This finding holds across two different pretraining methods, adapter-based pretraining and full model pretraining.