 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 25, 2020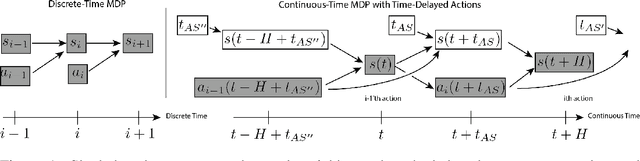
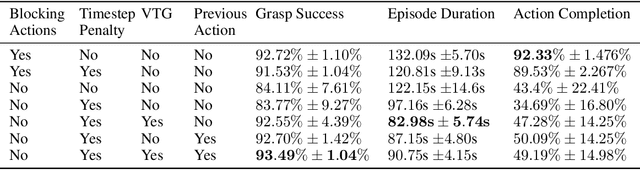
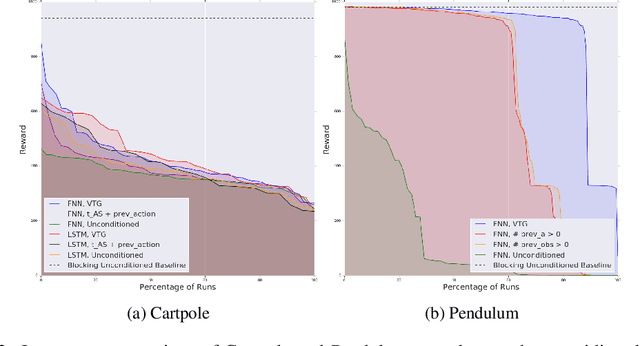

We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
Nov 28, 2018


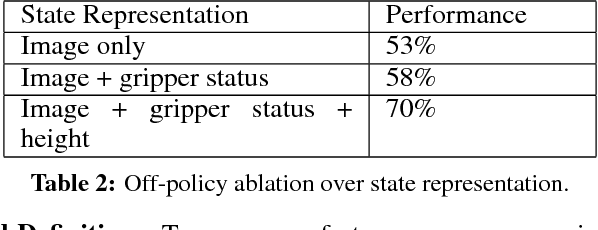
In this paper, we study the problem of learning vision-based dynamic manipulation skills using a scalable reinforcement learning approach. We study this problem in the context of grasping, a longstanding challenge in robotic manipulation. In contrast to static learning behaviors that choose a grasp point and then execute the desired grasp, our method enables closed-loop vision-based control, whereby the robot continuously updates its grasp strategy based on the most recent observations to optimize long-horizon grasp success. To that end, we introduce QT-Opt, a scalable self-supervised vision-based reinforcement learning framework that can leverage over 580k real-world grasp attempts to train a deep neural network Q-function with over 1.2M parameters to perform closed-loop, real-world grasping that generalizes to 96% grasp success on unseen objects. Aside from attaining a very high success rate, our method exhibits behaviors that are quite distinct from more standard grasping systems: using only RGB vision-based perception from an over-the-shoulder camera, our method automatically learns regrasping strategies, probes objects to find the most effective grasps, learns to reposition objects and perform other non-prehensile pre-grasp manipulations, and responds dynamically to disturbances and perturbations.
Transfer Topic Labeling with Domain-Specific Knowledge Base: An Analysis of UK House of Commons Speeches 1935-2014
Aug 27, 2018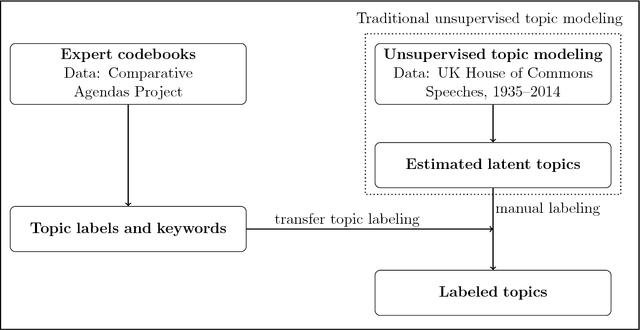
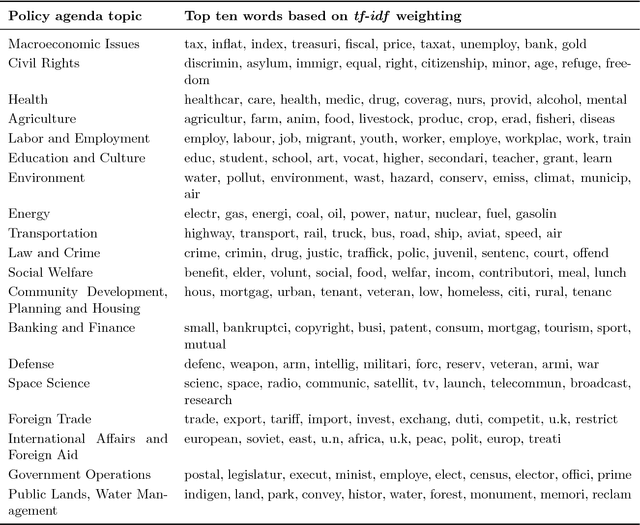
Topic models are widely used in natural language processing, allowing researchers to estimate the underlying themes in a collection of documents. Most topic models use unsupervised methods and hence require the additional step of attaching meaningful labels to estimated topics. This process of manual labeling is not scalable and suffers from human bias. We present a semi-automatic transfer topic labeling method that seeks to remedy these problems. Domain-specific codebooks form the knowledge-base for automated topic labeling. We demonstrate our approach with a dynamic topic model analysis of the complete corpus of UK House of Commons speeches 1935-2014, using the coding instructions of the Comparative Agendas Project to label topics. We show that our method works well for a majority of the topics we estimate; but we also find that institution-specific topics, in particular on subnational governance, require manual input. We validate our results using human expert coding.
Learning a Structured Neural Network Policy for a Hopping Task
Aug 06, 2018

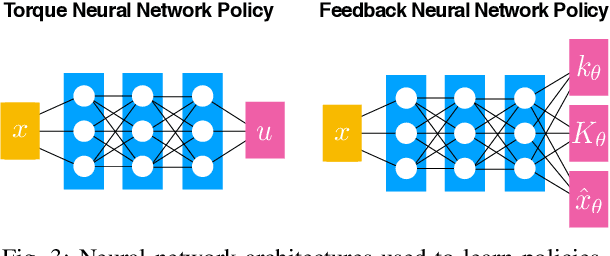
In this work we present a method for learning a reactive policy for a simple dynamic locomotion task involving hard impact and switching contacts where we assume the contact location and contact timing to be unknown. To learn such a policy, we use optimal control to optimize a local controller for a fixed environment and contacts. We learn the contact-rich dynamics for our underactuated systems along these trajectories in a sample efficient manner. We use the optimized policies to learn the reactive policy in form of a neural network. Using a new neural network architecture, we are able to preserve more information from the local policy and make its output interpretable in the sense that its output in terms of desired trajectories, feedforward commands and gains can be interpreted. Extensive simulations demonstrate the robustness of the approach to changing environments, outperforming a model-free gradient policy based methods on the same tasks in simulation. Finally, we show that the learned policy can be robustly transferred on a real robot.
Walking Control Based on Step Timing Adaptation
Jul 23, 2018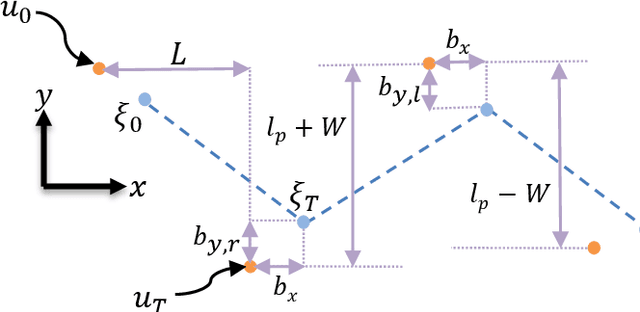

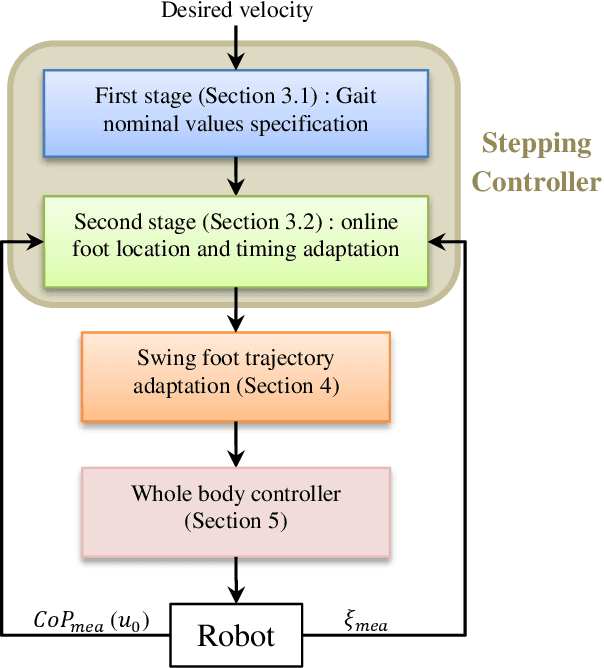
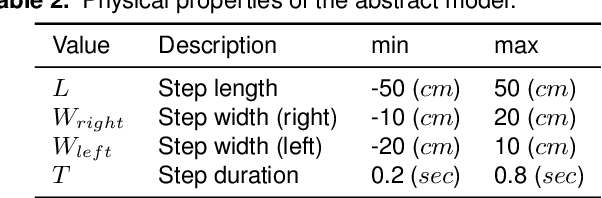
Step adjustment for biped robots has been shown to improve gait robustness, however the adaptation of step timing is often neglected in control strategies because it gives rise to non-convex problems when optimized over several steps. In this paper, we argue that it is not necessary to optimize walking over several steps to guarantee stability and that it is sufficient to merely select the next step timing and location. From this insight, we propose a novel walking pattern generator with linear constraints that optimally selects step location and timing at every control cycle. The resulting controller is computationally simple, yet guarantees that any viable state will remain viable in the future. We propose a swing foot adaptation strategy and show how the approach can be used with an inverse dynamics controller without any explicit control of the center of mass or the foot center of pressure. This is particularly useful for biped robots with limited control authority on their foot center of pressure, such as robots with point feet and robots with passive ankles. Extensive simulations on a humanoid robot with passive ankles subject to external pushes and foot slippage demonstrate the capabilities of the approach in cases where the foot center of pressure cannot be controlled and emphasize the importance of step timing adaptation to stabilize walking.
On Time Optimization of Centroidal Momentum Dynamics
Feb 26, 2018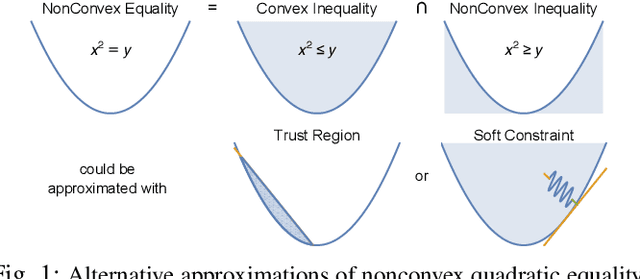
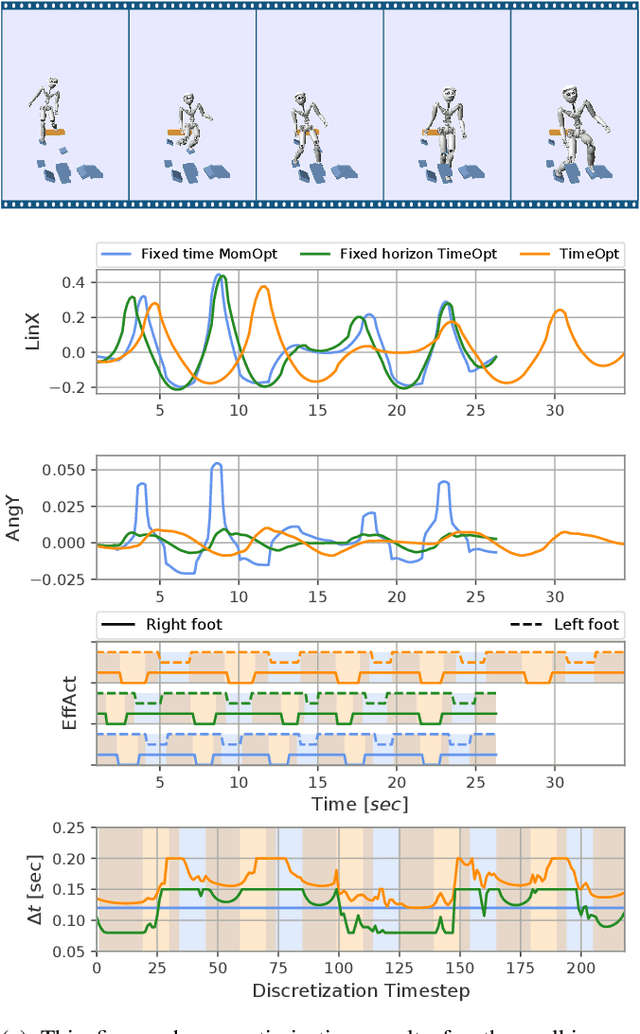
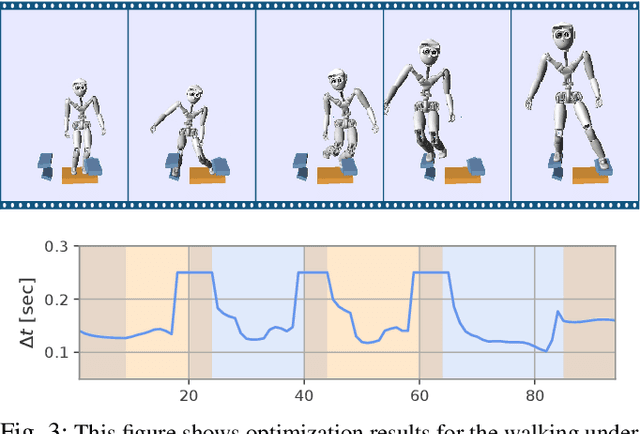
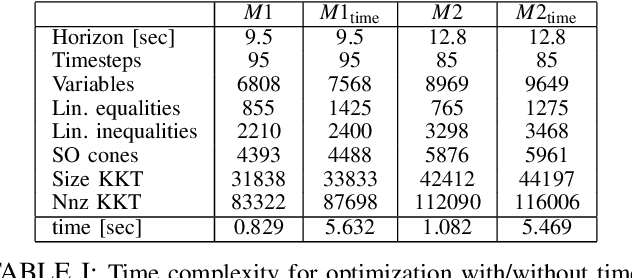
Recently, the centroidal momentum dynamics has received substantial attention to plan dynamically consistent motions for robots with arms and legs in multi-contact scenarios. However, it is also non convex which renders any optimization approach difficult and timing is usually kept fixed in most trajectory optimization techniques to not introduce additional non convexities to the problem. But this can limit the versatility of the algorithms. In our previous work, we proposed a convex relaxation of the problem that allowed to efficiently compute momentum trajectories and contact forces. However, our approach could not minimize a desired angular momentum objective which seriously limited its applicability. Noticing that the non-convexity introduced by the time variables is of similar nature as the centroidal dynamics one, we propose two convex relaxations to the problem based on trust regions and soft constraints. The resulting approaches can compute time-optimized dynamically consistent trajectories sufficiently fast to make the approach realtime capable. The performance of the algorithm is demonstrated in several multi-contact scenarios for a humanoid robot. In particular, we show that the proposed convex relaxation of the original problem finds solutions that are consistent with the original non-convex problem and illustrate how timing optimization allows to find motion plans that would be difficult to plan with fixed timing.
Scalable Dynamic Topic Modeling with Clustered Latent Dirichlet Allocation (CLDA)
Oct 15, 2017
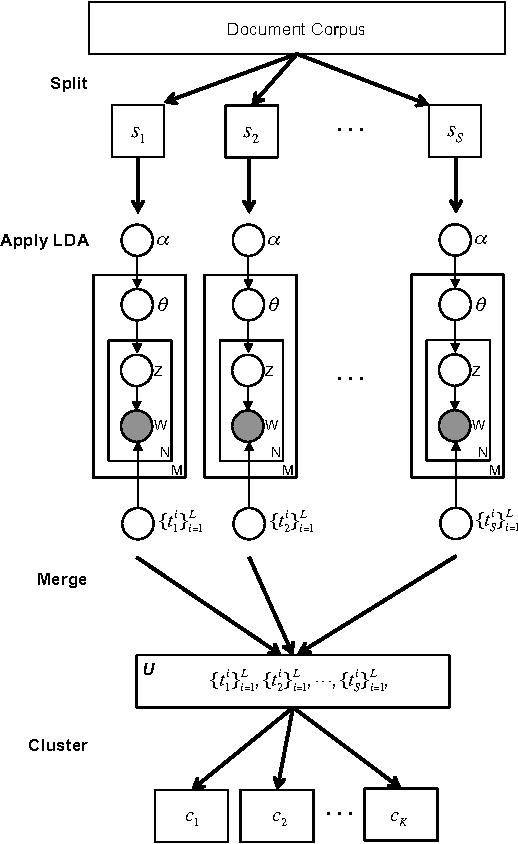
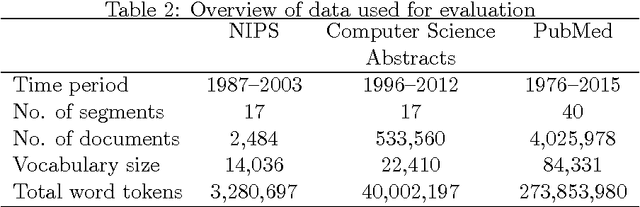
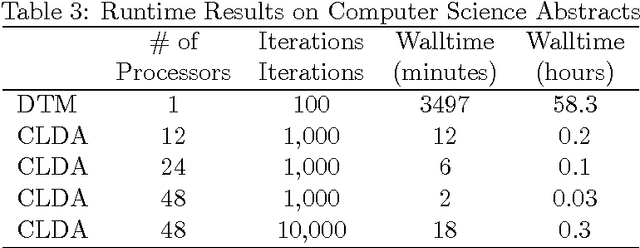
Topic modeling, a method for extracting the underlying themes from a collection of documents, is an increasingly important component of the design of intelligent systems enabling the sense-making of highly dynamic and diverse streams of text data. Traditional methods such as Dynamic Topic Modeling (DTM) do not lend themselves well to direct parallelization because of dependencies from one time step to another. In this paper, we introduce and empirically analyze Clustered Latent Dirichlet Allocation (CLDA), a method for extracting dynamic latent topics from a collection of documents. Our approach is based on data decomposition in which the data is partitioned into segments, followed by topic modeling on the individual segments. The resulting local models are then combined into a global solution using clustering. The decomposition and resulting parallelization leads to very fast runtime even on very large datasets. Our approach furthermore provides insight into how the composition of topics changes over time and can also be applied using other data partitioning strategies over any discrete features of the data, such as geographic features or classes of users. In this paper CLDA is applied successfully to seventeen years of NIPS conference papers (2,484 documents and 3,280,697 words), seventeen years of computer science journal abstracts (533,560 documents and 32,551,540 words), and to forty years of the PubMed corpus (4,025,978 documents and 273,853,980 words).
Pattern Generation for Walking on Slippery Terrains
Oct 07, 2017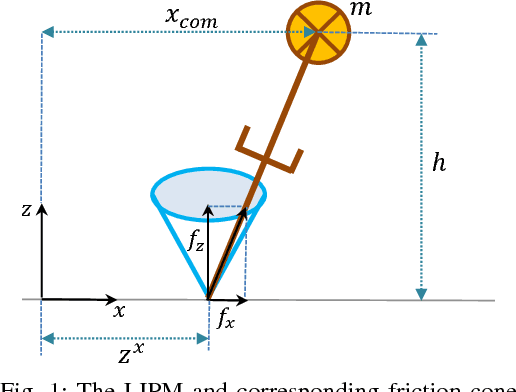
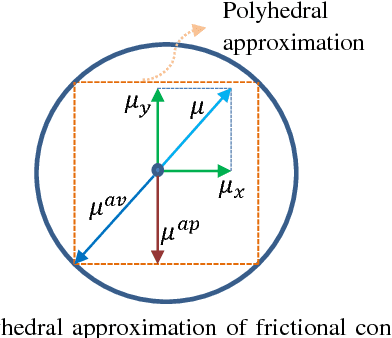
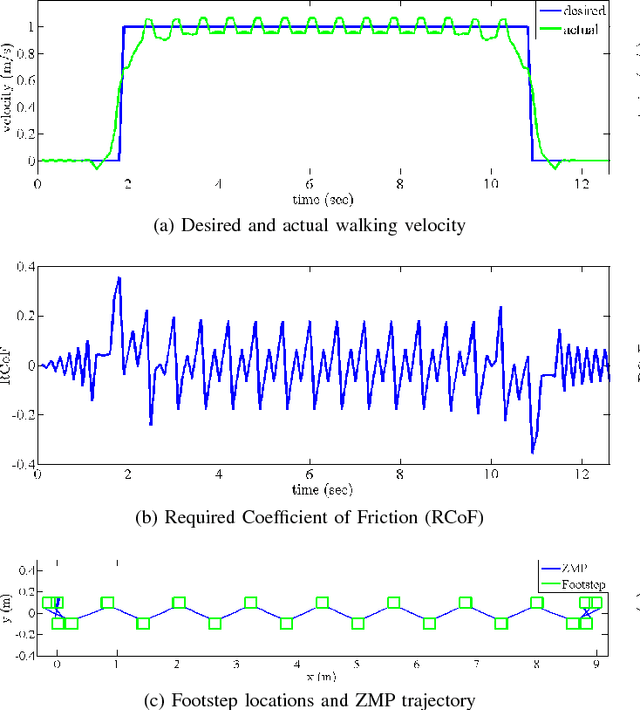
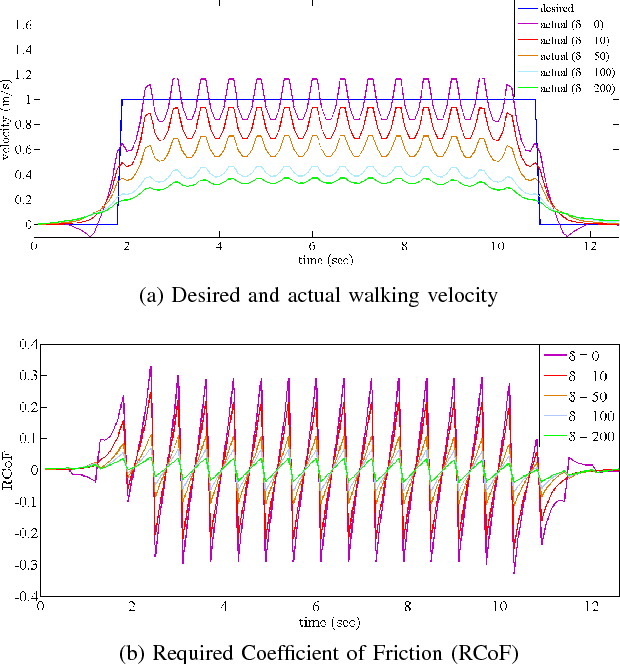
In this paper, we extend state of the art Model Predictive Control (MPC) approaches to generate safe bipedal walking on slippery surfaces. In this setting, we formulate walking as a trade off between realizing a desired walking velocity and preserving robust foot-ground contact. Exploiting this formulation inside MPC, we show that safe walking on various flat terrains can be achieved by compromising three main attributes, i. e. walking velocity tracking, the Zero Moment Point (ZMP) modulation, and the Required Coefficient of Friction (RCoF) regulation. Simulation results show that increasing the walking velocity increases the possibility of slippage, while reducing the slippage possibility conflicts with reducing the tip-over possibility of the contact and vice versa.
Database of Parliamentary Speeches in Ireland, 1919-2013
Aug 15, 2017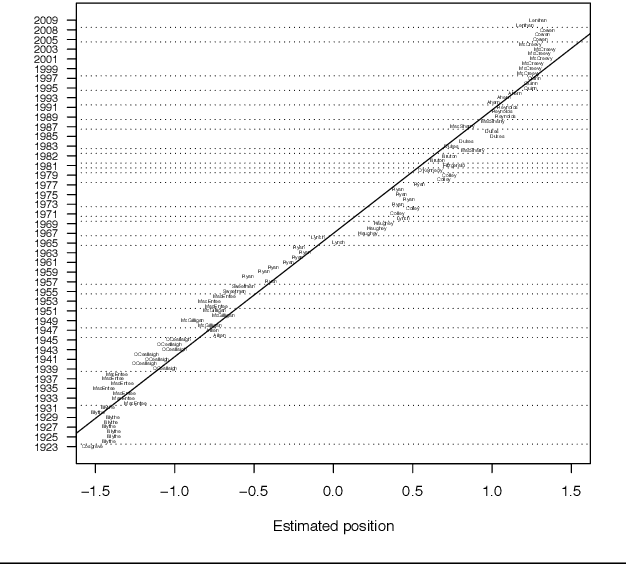
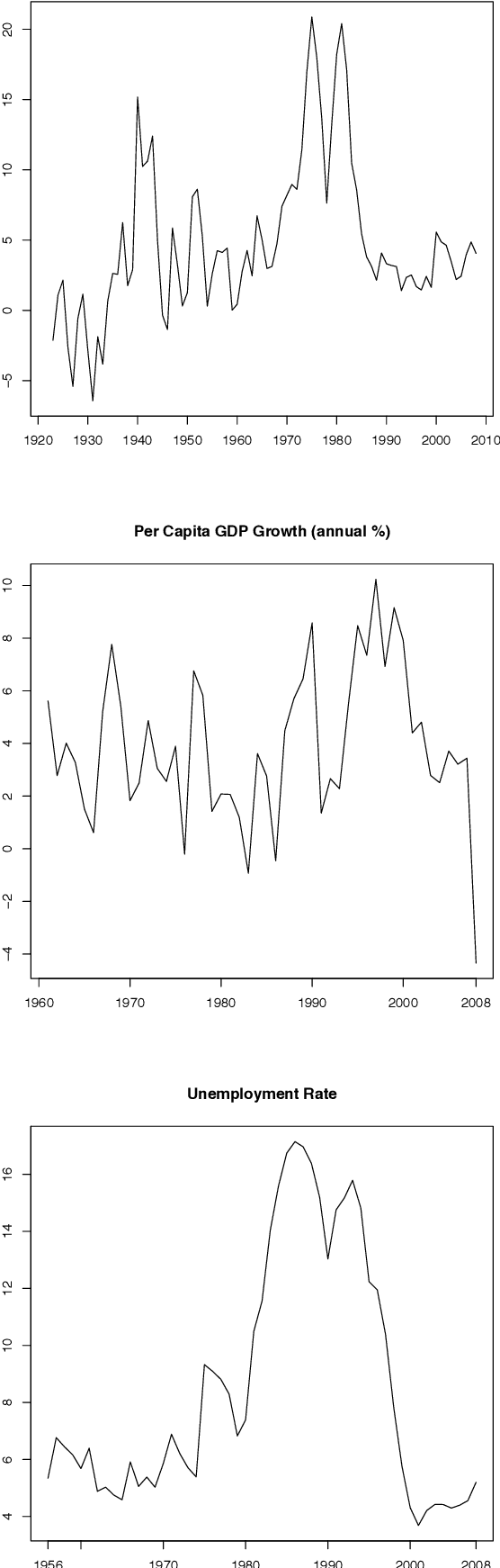
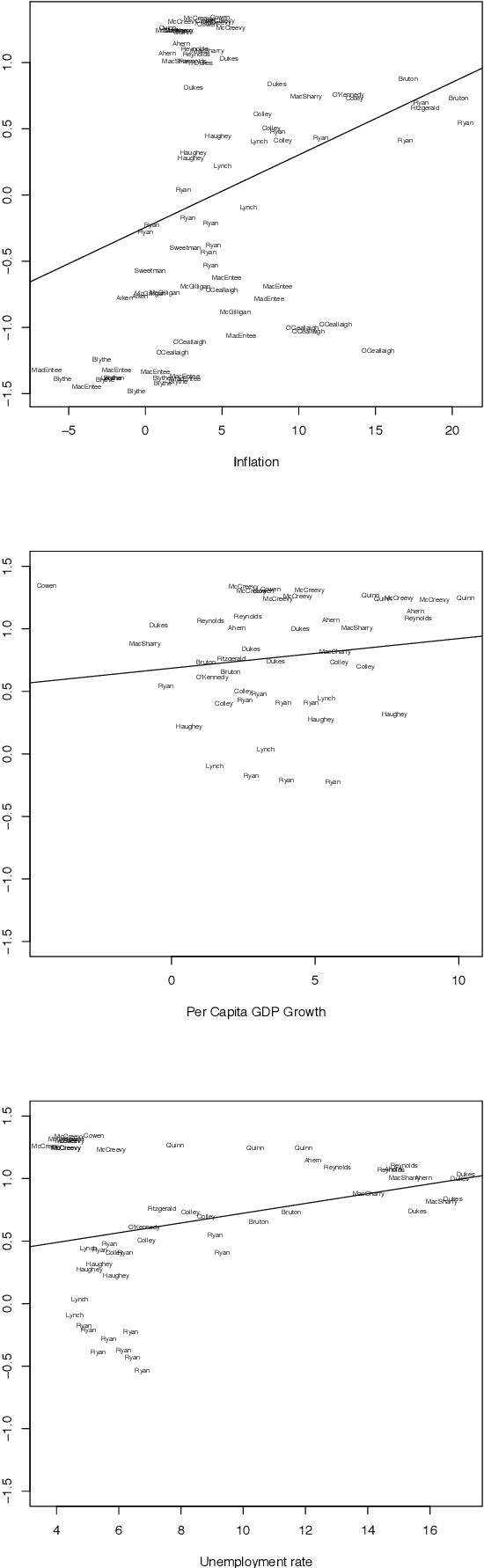
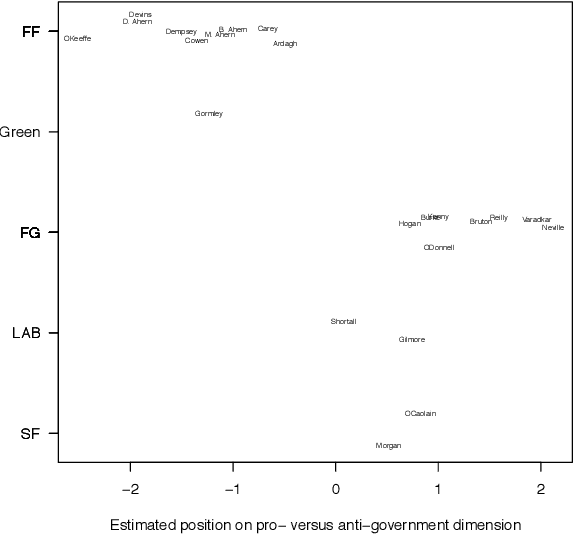
We present a database of parliamentary debates that contains the complete record of parliamentary speeches from D\'ail \'Eireann, the lower house and principal chamber of the Irish parliament, from 1919 to 2013. In addition, the database contains background information on all TDs (Teachta D\'ala, members of parliament), such as their party affiliations, constituencies and office positions. The current version of the database includes close to 4.5 million speeches from 1,178 TDs. The speeches were downloaded from the official parliament website and further processed and parsed with a Python script. Background information on TDs was collected from the member database of the parliament website. Data on cabinet positions (ministers and junior ministers) was collected from the official website of the government. A record linkage algorithm and human coders were used to match TDs and ministers.
Structured contact force optimization for kino-dynamic motion generation
Dec 24, 2016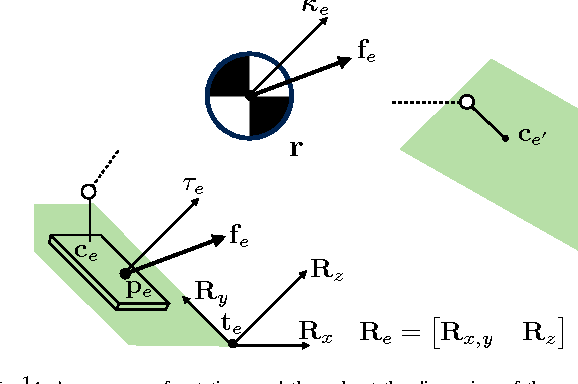
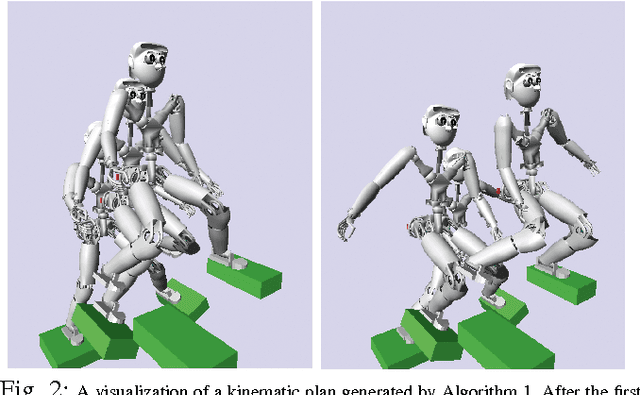
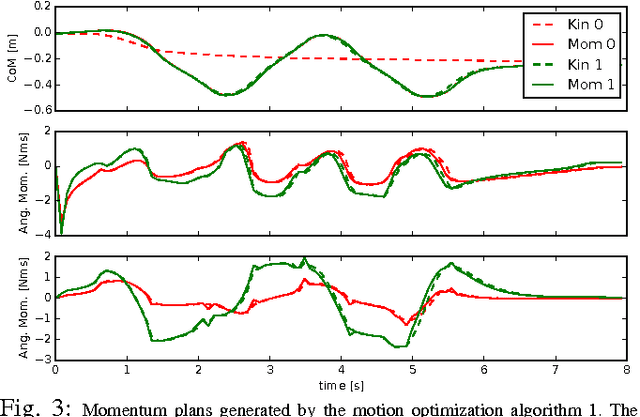
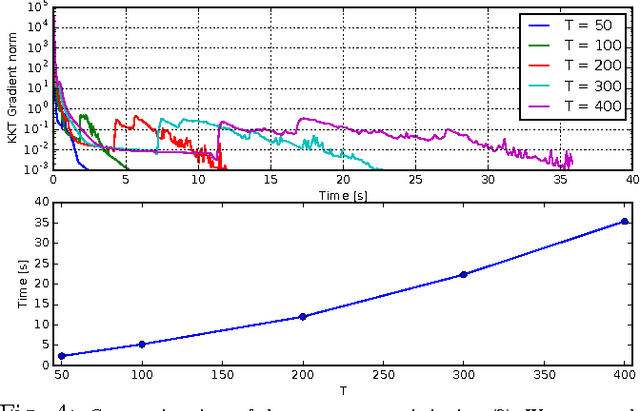
Optimal control approaches in combination with trajectory optimization have recently proven to be a promising control strategy for legged robots. Computationally efficient and robust algorithms were derived using simplified models of the contact interaction between robot and environment such as the linear inverted pendulum model (LIPM). However, as humanoid robots enter more complex environments, less restrictive models become increasingly important. As we leave the regime of linear models, we need to build dedicated solvers that can compute interaction forces together with consistent kinematic plans for the whole-body. In this paper, we address the problem of planning robot motion and interaction forces for legged robots given predefined contact surfaces. The motion generation process is decomposed into two alternating parts computing force and motion plans in coherence. We focus on the properties of the momentum computation leading to sparse optimal control formulations to be exploited by a dedicated solver. In our experiments, we demonstrate that our motion generation algorithm computes consistent contact forces and joint trajectories for our humanoid robot. We also demonstrate the favorable time complexity due to our formulation and composition of the momentum equations.