 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Robustness Enhancement Via Test-Time Transformation
Mar 27, 2023



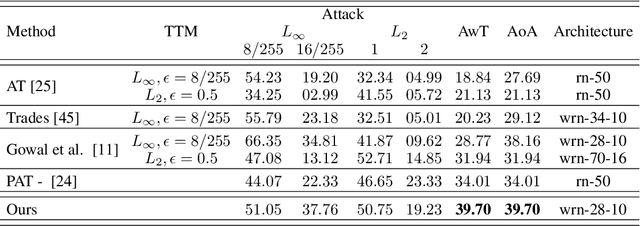
It has been recently discovered that adversarially trained classifiers exhibit an intriguing property, referred to as perceptually aligned gradients (PAG). PAG implies that the gradients of such classifiers possess a meaningful structure, aligned with human perception. Adversarial training is currently the best-known way to achieve classification robustness under adversarial attacks. The PAG property, however, has yet to be leveraged for further improving classifier robustness. In this work, we introduce Classifier Robustness Enhancement Via Test-Time Transformation (TETRA) -- a novel defense method that utilizes PAG, enhancing the performance of trained robust classifiers. Our method operates in two phases. First, it modifies the input image via a designated targeted adversarial attack into each of the dataset's classes. Then, it classifies the input image based on the distance to each of the modified instances, with the assumption that the shortest distance relates to the true class. We show that the proposed method achieves state-of-the-art results and validate our claim through extensive experiments on a variety of defense methods, classifier architectures, and datasets. We also empirically demonstrate that TETRA can boost the accuracy of any differentiable adversarial training classifier across a variety of attacks, including ones unseen at training. Specifically, applying TETRA leads to substantial improvement of up to $+23\%$, $+20\%$, and $+26\%$ on CIFAR10, CIFAR100, and ImageNet, respectively.
Multi PILOT: Learned Feasible Multiple Acquisition Trajectories for Dynamic MRI
Mar 23, 2023Dynamic Magnetic Resonance Imaging (MRI) is known to be a powerful and reliable technique for the dynamic imaging of internal organs and tissues, making it a leading diagnostic tool. A major difficulty in using MRI in this setting is the relatively long acquisition time (and, hence, increased cost) required for imaging in high spatio-temporal resolution, leading to the appearance of related motion artifacts and decrease in resolution. Compressed Sensing (CS) techniques have become a common tool to reduce MRI acquisition time by subsampling images in the k-space according to some acquisition trajectory. Several studies have particularly focused on applying deep learning techniques to learn these acquisition trajectories in order to attain better image reconstruction, rather than using some predefined set of trajectories. To the best of our knowledge, learning acquisition trajectories has been only explored in the context of static MRI. In this study, we consider acquisition trajectory learning in the dynamic imaging setting. We design an end-to-end pipeline for the joint optimization of multiple per-frame acquisition trajectories along with a reconstruction neural network, and demonstrate improved image reconstruction quality in shorter acquisition times. The code for reproducing all experiments is accessible at https://github.com/tamirshor7/MultiPILOT.
Threat Model-Agnostic Adversarial Defense using Diffusion Models
Jul 17, 2022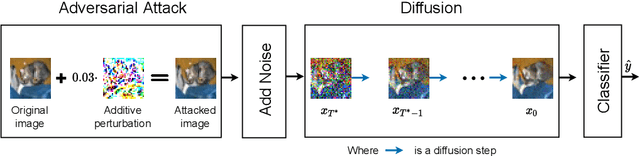
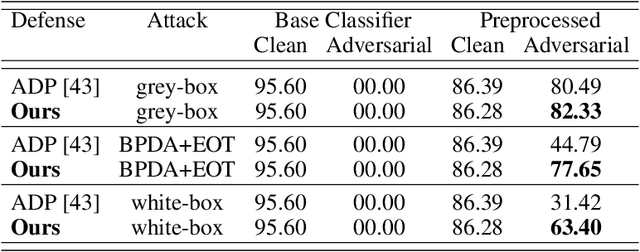
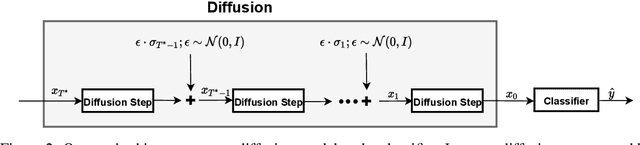
Deep Neural Networks (DNNs) are highly sensitive to imperceptible malicious perturbations, known as adversarial attacks. Following the discovery of this vulnerability in real-world imaging and vision applications, the associated safety concerns have attracted vast research attention, and many defense techniques have been developed. Most of these defense methods rely on adversarial training (AT) -- training the classification network on images perturbed according to a specific threat model, which defines the magnitude of the allowed modification. Although AT leads to promising results, training on a specific threat model fails to generalize to other types of perturbations. A different approach utilizes a preprocessing step to remove the adversarial perturbation from the attacked image. In this work, we follow the latter path and aim to develop a technique that leads to robust classifiers across various realizations of threat models. To this end, we harness the recent advances in stochastic generative modeling, and means to leverage these for sampling from conditional distributions. Our defense relies on an addition of Gaussian i.i.d noise to the attacked image, followed by a pretrained diffusion process -- an architecture that performs a stochastic iterative process over a denoising network, yielding a high perceptual quality denoised outcome. The obtained robustness with this stochastic preprocessing step is validated through extensive experiments on the CIFAR-10 dataset, showing that our method outperforms the leading defense methods under various threat models.
Joint optimization of system design and reconstruction in MIMO radar imaging
Oct 07, 2021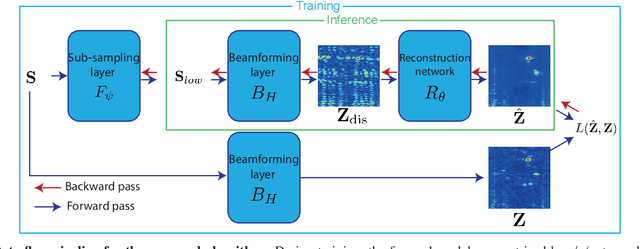
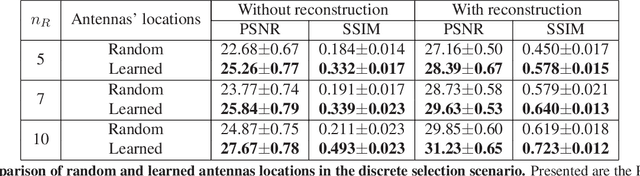
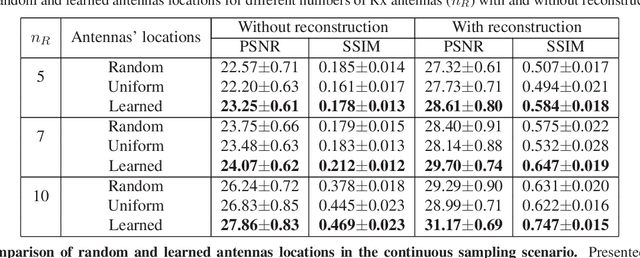
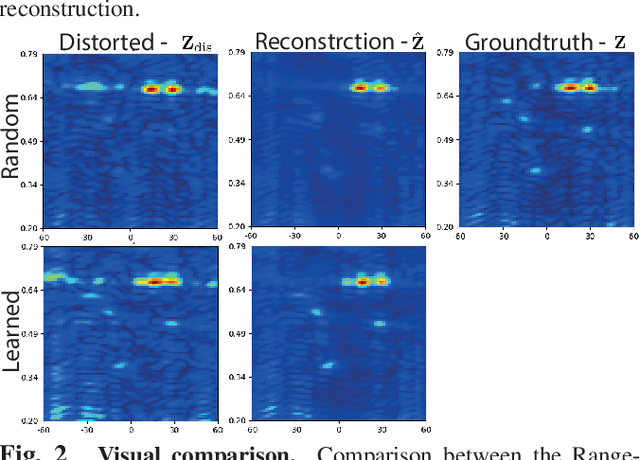
Multiple-input multiple-output (MIMO) radar is one of the leading depth sensing modalities. However, the usage of multiple receive channels lead to relative high costs and prevent the penetration of MIMOs in many areas such as the automotive industry. Over the last years, few studies concentrated on designing reduced measurement schemes and image reconstruction schemes for MIMO radars, however these problems have been so far addressed separately. On the other hand, recent works in optical computational imaging have demonstrated growing success of simultaneous learning-based design of the acquisition and reconstruction schemes, manifesting significant improvement in the reconstruction quality. Inspired by these successes, in this work, we propose to learn MIMO acquisition parameters in the form of receive (Rx) antenna elements locations jointly with an image neural-network based reconstruction. To this end, we propose an algorithm for training the combined acquisition-reconstruction pipeline end-to-end in a differentiable way. We demonstrate the significance of using our learned acquisition parameters with and without the neural-network reconstruction.
GRASP: Graph Alignment through Spectral Signatures
Jun 11, 2021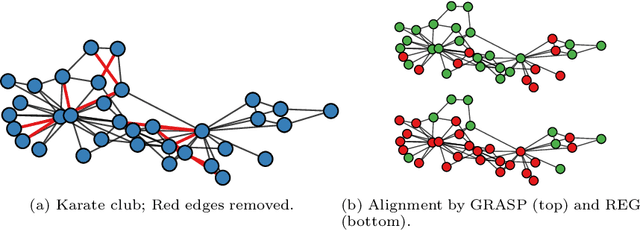
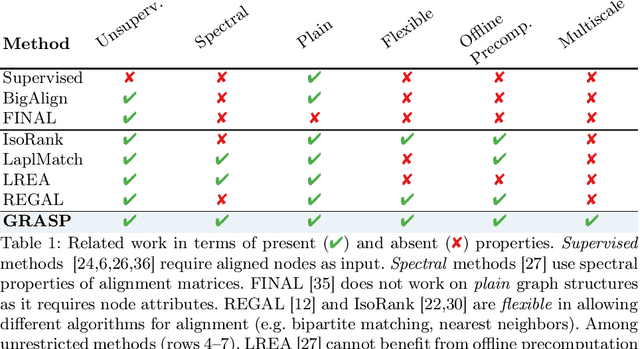
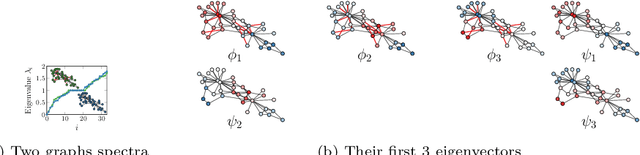
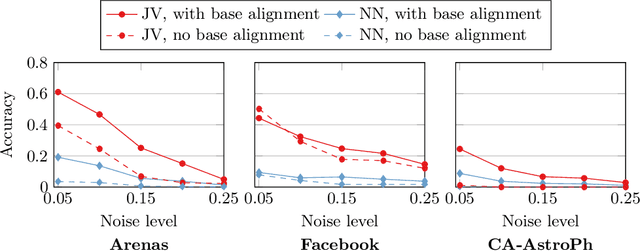
What is the best way to match the nodes of two graphs? This graph alignment problem generalizes graph isomorphism and arises in applications from social network analysis to bioinformatics. Some solutions assume that auxiliary information on known matches or node or edge attributes is available, or utilize arbitrary graph features. Such methods fare poorly in the pure form of the problem, in which only graph structures are given. Other proposals translate the problem to one of aligning node embeddings, yet, by doing so, provide only a single-scale view of the graph. In this paper, we transfer the shape-analysis concept of functional maps from the continuous to the discrete case, and treat the graph alignment problem as a special case of the problem of finding a mapping between functions on graphs. We present GRASP, a method that first establishes a correspondence between functions derived from Laplacian matrix eigenvectors, which capture multiscale structural characteristics, and then exploits this correspondence to align nodes. Our experimental study, featuring noise levels higher than anything used in previous studies, shows that GRASP outperforms state-of-the-art methods for graph alignment across noise levels and graph types.
Detector-Free Weakly Supervised Grounding by Separation
Apr 20, 2021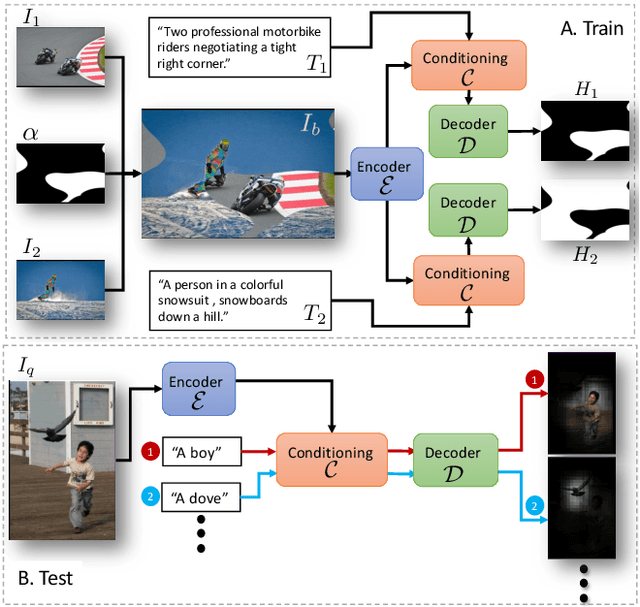
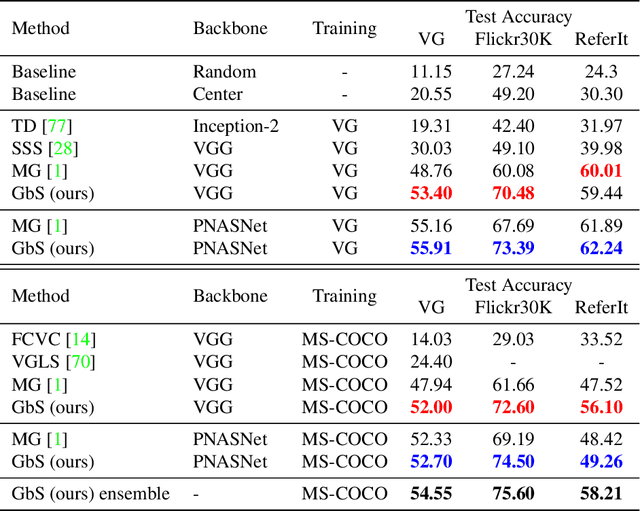
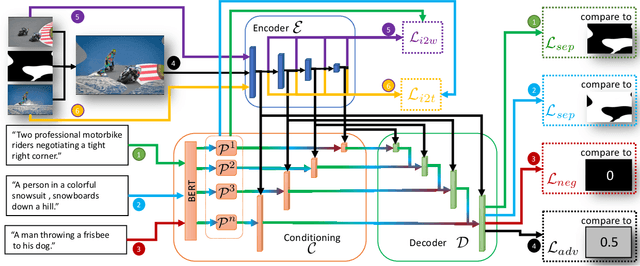
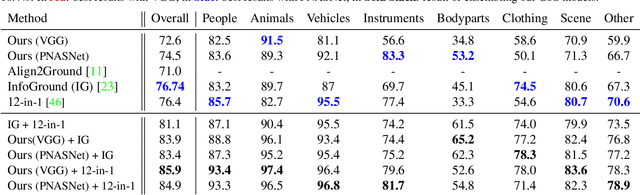
Nowadays, there is an abundance of data involving images and surrounding free-form text weakly corresponding to those images. Weakly Supervised phrase-Grounding (WSG) deals with the task of using this data to learn to localize (or to ground) arbitrary text phrases in images without any additional annotations. However, most recent SotA methods for WSG assume the existence of a pre-trained object detector, relying on it to produce the ROIs for localization. In this work, we focus on the task of Detector-Free WSG (DF-WSG) to solve WSG without relying on a pre-trained detector. We directly learn everything from the images and associated free-form text pairs, thus potentially gaining an advantage on the categories unsupported by the detector. The key idea behind our proposed Grounding by Separation (GbS) method is synthesizing `text to image-regions' associations by random alpha-blending of arbitrary image pairs and using the corresponding texts of the pair as conditions to recover the alpha map from the blended image via a segmentation network. At test time, this allows using the query phrase as a condition for a non-blended query image, thus interpreting the test image as a composition of a region corresponding to the phrase and the complement region. Using this approach we demonstrate a significant accuracy improvement, of up to $8.5\%$ over previous DF-WSG SotA, for a range of benchmarks including Flickr30K, Visual Genome, and ReferIt, as well as a significant complementary improvement (above $7\%$) over the detector-based approaches for WSG.
Self-Supervised Classification Network
Mar 19, 2021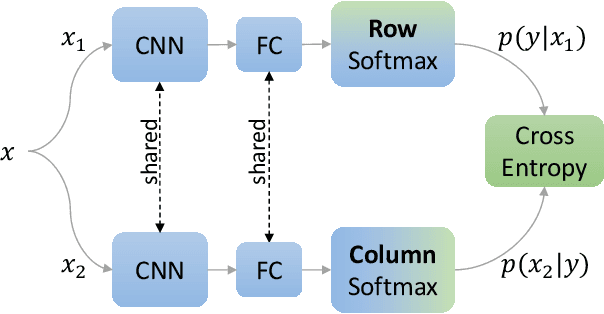
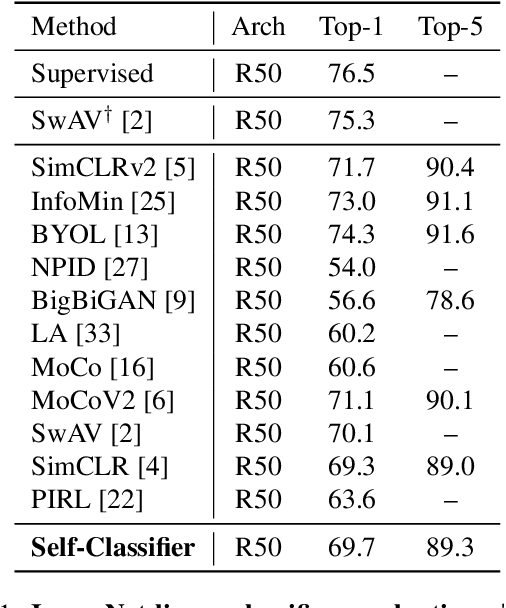
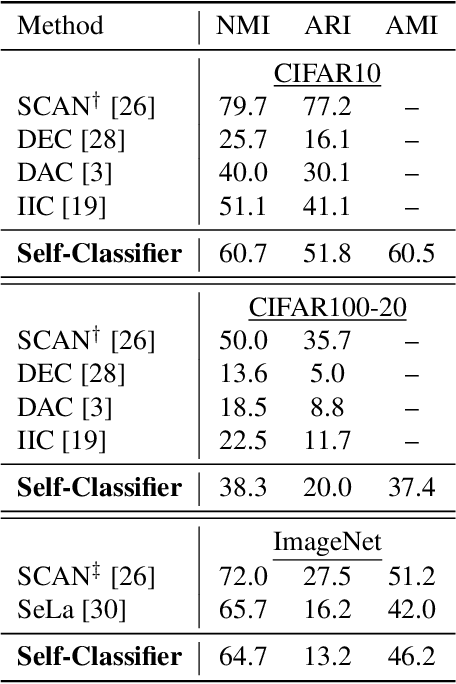
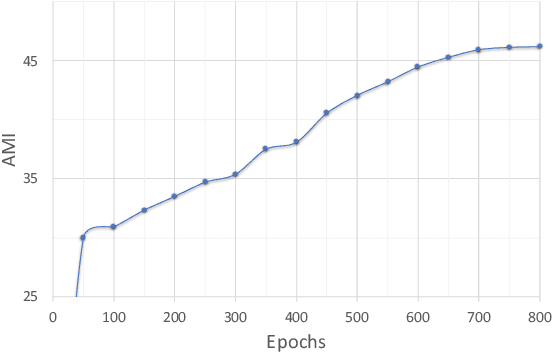
We present Self-Classifier -- a novel self-supervised end-to-end classification neural network. Self-Classifier learns labels and representations simultaneously in a single-stage end-to-end manner by optimizing for same-class prediction of two augmented views of the same sample. To guarantee non-degenerate solutions (i.e., solutions where all labels are assigned to the same class), a uniform prior is asserted on the labels. We show mathematically that unlike the regular cross-entropy loss, our approach avoids such solutions. Self-Classifier is simple to implement and is scalable to practically unlimited amounts of data. Unlike other unsupervised classification approaches, it does not require any form of pre-training or the use of expectation maximization algorithms, pseudo-labelling or external clustering. Unlike other contrastive learning representation learning approaches, it does not require a memory bank or a second network. Despite its relative simplicity, our approach achieves comparable results to state-of-the-art performance with ImageNet, CIFAR10 and CIFAR100 for its two objectives: unsupervised classification and unsupervised representation learning. Furthermore, it is the first unsupervised end-to-end classification network to perform well on the large-scale ImageNet dataset. Code will be made available.
ISP Distillation
Jan 25, 2021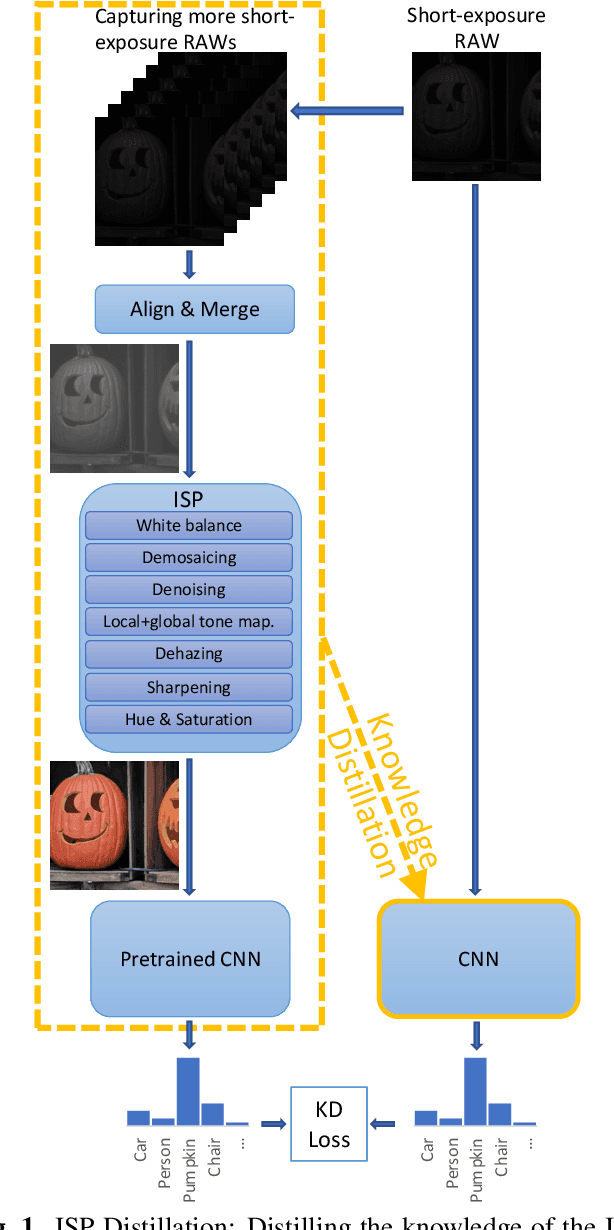
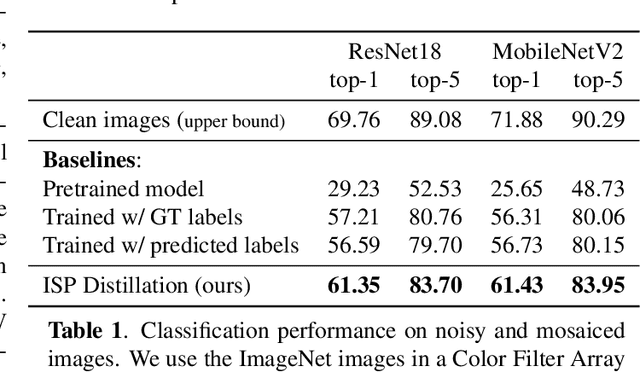
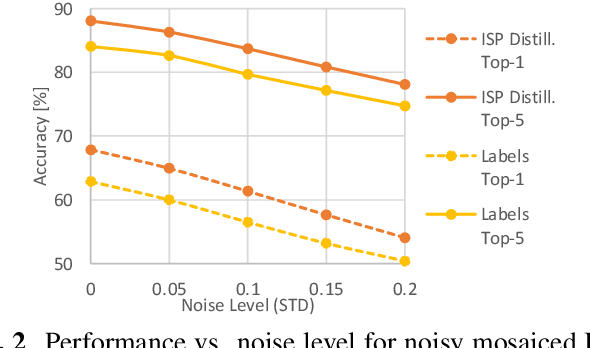
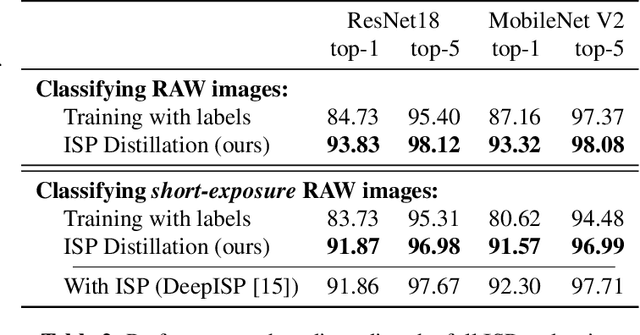
Nowadays, many of the images captured are "observed" by machines only and not by humans, for example, robots' or autonomous cars' cameras. High-level machine vision models, such as object recognition, assume images are transformed to some canonical image space by the camera ISP. However, the camera ISP is optimized for producing visually pleasing images to human observers and not for machines, thus, one may spare the ISP compute time and apply the vision models directly to the raw data. Yet, it has been shown that training such models directly on the RAW images results in a performance drop. To mitigate this drop in performance (without the need to annotate RAW data), we use a dataset of RAW and RGB image pairs, which can be easily acquired with no human labeling. We then train a model that is applied directly to the RAW data by using knowledge distillation such that the model predictions for RAW images will be aligned with the predictions of an off-the-shelf pre-trained model for processed RGB images. Our experiments show that our performance on RAW images is significantly better than a model trained on labeled RAW images. It also reasonably matches the predictions of a pre-trained model on processed RGB images, while saving the ISP compute overhead.
Non-Rigid Puzzles
Nov 26, 2020Shape correspondence is a fundamental problem in computer graphics and vision, with applications in various problems including animation, texture mapping, robotic vision, medical imaging, archaeology and many more. In settings where the shapes are allowed to undergo non-rigid deformations and only partial views are available, the problem becomes very challenging. To this end, we present a non-rigid multi-part shape matching algorithm. We assume to be given a reference shape and its multiple parts undergoing a non-rigid deformation. Each of these query parts can be additionally contaminated by clutter, may overlap with other parts, and there might be missing parts or redundant ones. Our method simultaneously solves for the segmentation of the reference model, and for a dense correspondence to (subsets of) the parts. Experimental results on synthetic as well as real scans demonstrate the effectiveness of our method in dealing with this challenging matching scenario.
3D FLAT: Feasible Learned Acquisition Trajectories for Accelerated MRI
Aug 11, 2020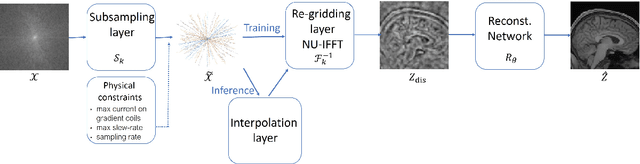

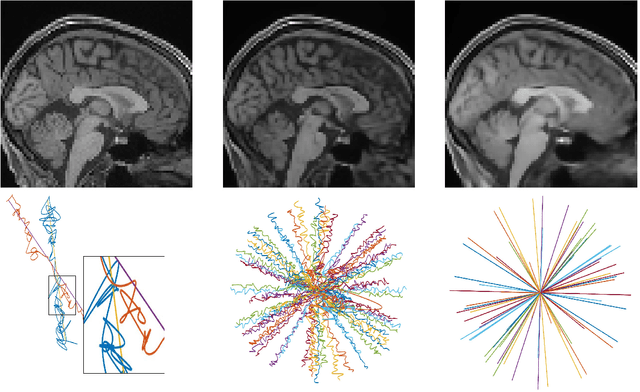
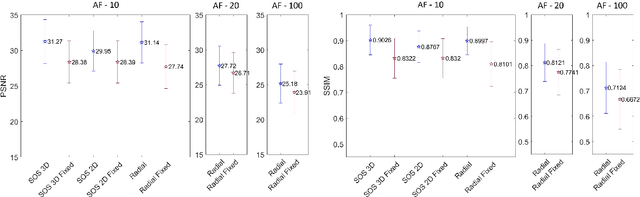
Magnetic Resonance Imaging (MRI) has long been considered to be among the gold standards of today's diagnostic imaging. The most significant drawback of MRI is long acquisition times, prohibiting its use in standard practice for some applications. Compressed sensing (CS) proposes to subsample the k-space (the Fourier domain dual to the physical space of spatial coordinates) leading to significantly accelerated acquisition. However, the benefit of compressed sensing has not been fully exploited; most of the sampling densities obtained through CS do not produce a trajectory that obeys the stringent constraints of the MRI machine imposed in practice. Inspired by recent success of deep learning based approaches for image reconstruction and ideas from computational imaging on learning-based design of imaging systems, we introduce 3D FLAT, a novel protocol for data-driven design of 3D non-Cartesian accelerated trajectories in MRI. Our proposal leverages the entire 3D k-space to simultaneously learn a physically feasible acquisition trajectory with a reconstruction method. Experimental results, performed as a proof-of-concept, suggest that 3D FLAT achieves higher image quality for a given readout time compared to standard trajectories such as radial, stack-of-stars, or 2D learned trajectories (trajectories that evolve only in the 2D plane while fully sampling along the third dimension). Furthermore, we demonstrate evidence supporting the significant benefit of performing MRI acquisitions using non-Cartesian 3D trajectories over 2D non-Cartesian trajectories acquired slice-wise.