 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Small-to-Large Generalization: Data Influences Models Consistently Across Scale
May 22, 2025Choice of training data distribution greatly influences model behavior. Yet, in large-scale settings, precisely characterizing how changes in training data affects predictions is often difficult due to model training costs. Current practice is to instead extrapolate from scaled down, inexpensive-to-train proxy models. However, changes in data do not influence smaller and larger models identically. Therefore, understanding how choice of data affects large-scale models raises the question: how does training data distribution influence model behavior across compute scale? We find that small- and large-scale language model predictions (generally) do highly correlate across choice of training data. Equipped with these findings, we characterize how proxy scale affects effectiveness in two downstream proxy model applications: data attribution and dataset selection.
DataMIL: Selecting Data for Robot Imitation Learning with Datamodels
May 14, 2025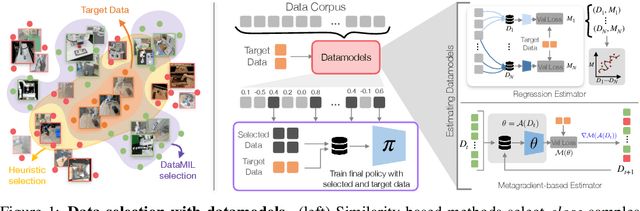
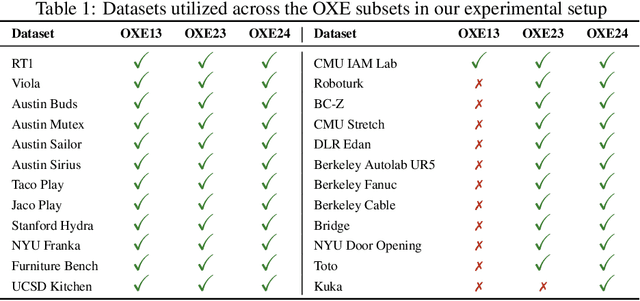
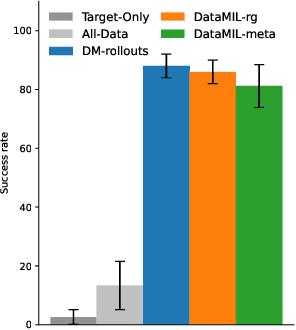
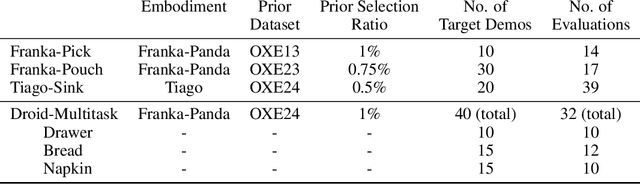
Recently, the robotics community has amassed ever larger and more diverse datasets to train generalist robot policies. However, while these policies achieve strong mean performance across a variety of tasks, they often underperform on individual, specialized tasks and require further tuning on newly acquired task-specific data. Combining task-specific data with carefully curated subsets of large prior datasets via co-training can produce better specialized policies, but selecting data naively may actually harm downstream performance. To address this, we introduce DataMIL, a policy-driven data selection framework built on the datamodels paradigm that reasons about data selection in an end-to-end manner, using the policy itself to identify which data points will most improve performance. Unlike standard practices that filter data using human notions of quality (e.g., based on semantic or visual similarity), DataMIL directly optimizes data selection for task success, allowing us to select data that enhance the policy while dropping data that degrade it. To avoid performing expensive rollouts in the environment during selection, we use a novel surrogate loss function on task-specific data, allowing us to use DataMIL in the real world without degrading performance. We validate our approach on a suite of more than 60 simulation and real-world manipulation tasks - most notably showing successful data selection from the Open X-Embodiment datasets-demonstrating consistent gains in success rates and superior performance over multiple baselines. Our results underscore the importance of end-to-end, performance-aware data selection for unlocking the potential of large prior datasets in robotics. More information at https://robin-lab.cs.utexas.edu/datamodels4imitation/
Learning to Attribute with Attention
Apr 18, 2025Given a sequence of tokens generated by a language model, we may want to identify the preceding tokens that influence the model to generate this sequence. Performing such token attribution is expensive; a common approach is to ablate preceding tokens and directly measure their effects. To reduce the cost of token attribution, we revisit attention weights as a heuristic for how a language model uses previous tokens. Naive approaches to attribute model behavior with attention (e.g., averaging attention weights across attention heads to estimate a token's influence) have been found to be unreliable. To attain faithful attributions, we propose treating the attention weights of different attention heads as features. This way, we can learn how to effectively leverage attention weights for attribution (using signal from ablations). Our resulting method, Attribution with Attention (AT2), reliably performs on par with approaches that involve many ablations, while being significantly more efficient. To showcase the utility of AT2, we use it to prune less important parts of a provided context in a question answering setting, improving answer quality. We provide code for AT2 at https://github.com/MadryLab/AT2 .
Optimizing ML Training with Metagradient Descent
Mar 17, 2025A major challenge in training large-scale machine learning models is configuring the training process to maximize model performance, i.e., finding the best training setup from a vast design space. In this work, we unlock a gradient-based approach to this problem. We first introduce an algorithm for efficiently calculating metagradients -- gradients through model training -- at scale. We then introduce a "smooth model training" framework that enables effective optimization using metagradients. With metagradient descent (MGD), we greatly improve on existing dataset selection methods, outperform accuracy-degrading data poisoning attacks by an order of magnitude, and automatically find competitive learning rate schedules.
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Mar 14, 2025Mitigating reward hacking--where AI systems misbehave due to flaws or misspecifications in their learning objectives--remains a key challenge in constructing capable and aligned models. We show that we can monitor a frontier reasoning model, such as OpenAI o3-mini, for reward hacking in agentic coding environments by using another LLM that observes the model's chain-of-thought (CoT) reasoning. CoT monitoring can be far more effective than monitoring agent actions and outputs alone, and we further found that a LLM weaker than o3-mini, namely GPT-4o, can effectively monitor a stronger model. Because CoT monitors can be effective at detecting exploits, it is natural to ask whether those exploits can be suppressed by incorporating a CoT monitor directly into the agent's training objective. While we show that integrating CoT monitors into the reinforcement learning reward can indeed produce more capable and more aligned agents in the low optimization regime, we find that with too much optimization, agents learn obfuscated reward hacking, hiding their intent within the CoT while still exhibiting a significant rate of reward hacking. Because it is difficult to tell when CoTs have become obfuscated, it may be necessary to pay a monitorability tax by not applying strong optimization pressures directly to the chain-of-thought, ensuring that CoTs remain monitorable and useful for detecting misaligned behavior.
Do Large Language Model Benchmarks Test Reliability?
Feb 05, 2025When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs' growing capabilities, however there has been no similar focus on measuring their reliability. To understand the potential ramifications of this gap, we investigate how well current benchmarks quantify model reliability. We find that pervasive label errors can compromise these evaluations, obscuring lingering model failures and hiding unreliable behavior. Motivated by this gap in the evaluation of reliability, we then propose the concept of so-called platinum benchmarks, i.e., benchmarks carefully curated to minimize label errors and ambiguity. As a first attempt at constructing such benchmarks, we revise examples from fifteen existing popular benchmarks. We evaluate a wide range of models on these platinum benchmarks and find that, indeed, frontier LLMs still exhibit failures on simple tasks such as elementary-level math word problems. Analyzing these failures further reveals previously unidentified patterns of problems on which frontier models consistently struggle. We provide code at https://github.com/MadryLab/platinum-benchmarks
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Attribute-to-Delete: Machine Unlearning via Datamodel Matching
Oct 30, 2024



Machine unlearning -- efficiently removing the effect of a small "forget set" of training data on a pre-trained machine learning model -- has recently attracted significant research interest. Despite this interest, however, recent work shows that existing machine unlearning techniques do not hold up to thorough evaluation in non-convex settings. In this work, we introduce a new machine unlearning technique that exhibits strong empirical performance even in such challenging settings. Our starting point is the perspective that the goal of unlearning is to produce a model whose outputs are statistically indistinguishable from those of a model re-trained on all but the forget set. This perspective naturally suggests a reduction from the unlearning problem to that of data attribution, where the goal is to predict the effect of changing the training set on a model's outputs. Thus motivated, we propose the following meta-algorithm, which we call Datamodel Matching (DMM): given a trained model, we (a) use data attribution to predict the output of the model if it were re-trained on all but the forget set points; then (b) fine-tune the pre-trained model to match these predicted outputs. In a simple convex setting, we show how this approach provably outperforms a variety of iterative unlearning algorithms. Empirically, we use a combination of existing evaluations and a new metric based on the KL-divergence to show that even in non-convex settings, DMM achieves strong unlearning performance relative to existing algorithms. An added benefit of DMM is that it is a meta-algorithm, in the sense that future advances in data attribution translate directly into better unlearning algorithms, pointing to a clear direction for future progress in unlearning.
ContextCite: Attributing Model Generation to Context
Sep 01, 2024



How do language models use information provided as context when generating a response? Can we infer whether a particular generated statement is actually grounded in the context, a misinterpretation, or fabricated? To help answer these questions, we introduce the problem of context attribution: pinpointing the parts of the context (if any) that led a model to generate a particular statement. We then present ContextCite, a simple and scalable method for context attribution that can be applied on top of any existing language model. Finally, we showcase the utility of ContextCite through three applications: (1) helping verify generated statements (2) improving response quality by pruning the context and (3) detecting poisoning attacks. We provide code for ContextCite at https://github.com/MadryLab/context-cite.