 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Pretraining Can Learn In-Context Reinforcement Learning
Jun 26, 2023



Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In this paper, we study the in-context learning capabilities of transformers in decision-making problems, i.e., reinforcement learning (RL) for bandits and Markov decision processes. To do so, we introduce and study Decision-Pretrained Transformer (DPT), a supervised pretraining method where the transformer predicts an optimal action given a query state and an in-context dataset of interactions, across a diverse set of tasks. This procedure, while simple, produces a model with several surprising capabilities. We find that the pretrained transformer can be used to solve a range of RL problems in-context, exhibiting both exploration online and conservatism offline, despite not being explicitly trained to do so. The model also generalizes beyond the pretraining distribution to new tasks and automatically adapts its decision-making strategies to unknown structure. Theoretically, we show DPT can be viewed as an efficient implementation of Bayesian posterior sampling, a provably sample-efficient RL algorithm. We further leverage this connection to provide guarantees on the regret of the in-context algorithm yielded by DPT, and prove that it can learn faster than algorithms used to generate the pretraining data. These results suggest a promising yet simple path towards instilling strong in-context decision-making abilities in transformers.
A Unified Model and Dimension for Interactive Estimation
Jun 09, 2023
We study an abstract framework for interactive learning called interactive estimation in which the goal is to estimate a target from its "similarity'' to points queried by the learner. We introduce a combinatorial measure called dissimilarity dimension which largely captures learnability in our model. We present a simple, general, and broadly-applicable algorithm, for which we obtain both regret and PAC generalization bounds that are polynomial in the new dimension. We show that our framework subsumes and thereby unifies two classic learning models: statistical-query learning and structured bandits. We also delineate how the dissimilarity dimension is related to well-known parameters for both frameworks, in some cases yielding significantly improved analyses.
Data-Driven Regret Balancing for Online Model Selection in Bandits
Jun 05, 2023



We consider model selection for sequential decision making in stochastic environments with bandit feedback, where a meta-learner has at its disposal a pool of base learners, and decides on the fly which action to take based on the policies recommended by each base learner. Model selection is performed by regret balancing but, unlike the recent literature on this subject, we do not assume any prior knowledge about the base learners like candidate regret guarantees; instead, we uncover these quantities in a data-driven manner. The meta-learner is therefore able to leverage the realized regret incurred by each base learner for the learning environment at hand (as opposed to the expected regret), and single out the best such regret. We design two model selection algorithms operating with this more ambitious notion of regret and, besides proving model selection guarantees via regret balancing, we experimentally demonstrate the compelling practical benefits of dealing with actual regrets instead of candidate regret bounds.
Improving Offline RL by Blending Heuristics
Jun 01, 2023We propose Heuristic Blending (HUBL), a simple performance-improving technique for a broad class of offline RL algorithms based on value bootstrapping. HUBL modifies Bellman operators used in these algorithms, partially replacing the bootstrapped values with Monte-Carlo returns as heuristics. For trajectories with higher returns, HUBL relies more on heuristics and less on bootstrapping; otherwise, it leans more heavily on bootstrapping. We show that this idea can be easily implemented by relabeling the offline datasets with adjusted rewards and discount factors, making HUBL readily usable by many existing offline RL implementations. We theoretically prove that HUBL reduces offline RL's complexity and thus improves its finite-sample performance. Furthermore, we empirically demonstrate that HUBL consistently improves the policy quality of four state-of-the-art bootstrapping-based offline RL algorithms (ATAC, CQL, TD3+BC, and IQL), by 9% on average over 27 datasets of the D4RL and Meta-World benchmarks.
Estimating Optimal Policy Value in General Linear Contextual Bandits
Feb 19, 2023


In many bandit problems, the maximal reward achievable by a policy is often unknown in advance. We consider the problem of estimating the optimal policy value in the sublinear data regime before the optimal policy is even learnable. We refer to this as $V^*$ estimation. It was recently shown that fast $V^*$ estimation is possible but only in disjoint linear bandits with Gaussian covariates. Whether this is possible for more realistic context distributions has remained an open and important question for tasks such as model selection. In this paper, we first provide lower bounds showing that this general problem is hard. However, under stronger assumptions, we give an algorithm and analysis proving that $\widetilde{\mathcal{O}}(\sqrt{d})$ sublinear estimation of $V^*$ is indeed information-theoretically possible, where $d$ is the dimension. We then present a more practical, computationally efficient algorithm that estimates a problem-dependent upper bound on $V^*$ that holds for general distributions and is tight when the context distribution is Gaussian. We prove our algorithm requires only $\widetilde{\mathcal{O}}(\sqrt{d})$ samples to estimate the upper bound. We use this upper bound and the estimator to obtain novel and improved guarantees for several applications in bandit model selection and testing for treatment effects.
Transfer RL via the Undo Maps Formalism
Nov 26, 2022Transferring knowledge across domains is one of the most fundamental problems in machine learning, but doing so effectively in the context of reinforcement learning remains largely an open problem. Current methods make strong assumptions on the specifics of the task, often lack principled objectives, and -- crucially -- modify individual policies, which might be sub-optimal when the domains differ due to a drift in the state space, i.e., it is intrinsic to the environment and therefore affects every agent interacting with it. To address these drawbacks, we propose TvD: transfer via distribution matching, a framework to transfer knowledge across interactive domains. We approach the problem from a data-centric perspective, characterizing the discrepancy in environments by means of (potentially complex) transformation between their state spaces, and thus posing the problem of transfer as learning to undo this transformation. To accomplish this, we introduce a novel optimization objective based on an optimal transport distance between two distributions over trajectories -- those generated by an already-learned policy in the source domain and a learnable pushforward policy in the target domain. We show this objective leads to a policy update scheme reminiscent of imitation learning, and derive an efficient algorithm to implement it. Our experiments in simple gridworlds show that this method yields successful transfer learning across a wide range of environment transformations.
Leveraging Offline Data in Online Reinforcement Learning
Nov 09, 2022Two central paradigms have emerged in the reinforcement learning (RL) community: online RL and offline RL. In the online RL setting, the agent has no prior knowledge of the environment, and must interact with it in order to find an $\epsilon$-optimal policy. In the offline RL setting, the learner instead has access to a fixed dataset to learn from, but is unable to otherwise interact with the environment, and must obtain the best policy it can from this offline data. Practical scenarios often motivate an intermediate setting: if we have some set of offline data and, in addition, may also interact with the environment, how can we best use the offline data to minimize the number of online interactions necessary to learn an $\epsilon$-optimal policy? In this work, we consider this setting, which we call the \textsf{FineTuneRL} setting, for MDPs with linear structure. We characterize the necessary number of online samples needed in this setting given access to some offline dataset, and develop an algorithm, \textsc{FTPedel}, which is provably optimal. We show through an explicit example that combining offline data with online interactions can lead to a provable improvement over either purely offline or purely online RL. Finally, our results illustrate the distinction between \emph{verifiable} learning, the typical setting considered in online RL, and \emph{unverifiable} learning, the setting often considered in offline RL, and show that there is a formal separation between these regimes.
Learning General World Models in a Handful of Reward-Free Deployments
Oct 23, 2022



Building generally capable agents is a grand challenge for deep reinforcement learning (RL). To approach this challenge practically, we outline two key desiderata: 1) to facilitate generalization, exploration should be task agnostic; 2) to facilitate scalability, exploration policies should collect large quantities of data without costly centralized retraining. Combining these two properties, we introduce the reward-free deployment efficiency setting, a new paradigm for RL research. We then present CASCADE, a novel approach for self-supervised exploration in this new setting. CASCADE seeks to learn a world model by collecting data with a population of agents, using an information theoretic objective inspired by Bayesian Active Learning. CASCADE achieves this by specifically maximizing the diversity of trajectories sampled by the population through a novel cascading objective. We provide theoretical intuition for CASCADE which we show in a tabular setting improves upon na\"ive approaches that do not account for population diversity. We then demonstrate that CASCADE collects diverse task-agnostic datasets and learns agents that generalize zero-shot to novel, unseen downstream tasks on Atari, MiniGrid, Crafter and the DM Control Suite. Code and videos are available at https://ycxuyingchen.github.io/cascade/
Unpacking Reward Shaping: Understanding the Benefits of Reward Engineering on Sample Complexity
Oct 18, 2022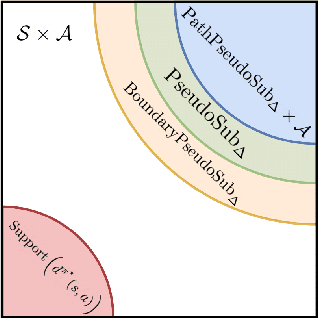

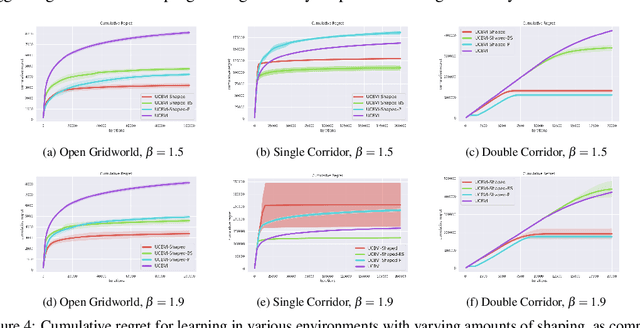
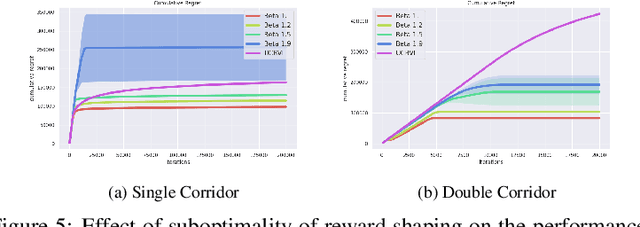
Reinforcement learning provides an automated framework for learning behaviors from high-level reward specifications, but in practice the choice of reward function can be crucial for good results -- while in principle the reward only needs to specify what the task is, in reality practitioners often need to design more detailed rewards that provide the agent with some hints about how the task should be completed. The idea of this type of ``reward-shaping'' has been often discussed in the literature, and is often a critical part of practical applications, but there is relatively little formal characterization of how the choice of reward shaping can yield benefits in sample complexity. In this work, we build on the framework of novelty-based exploration to provide a simple scheme for incorporating shaped rewards into RL along with an analysis tool to show that particular choices of reward shaping provably improve sample efficiency. We characterize the class of problems where these gains are expected to be significant and show how this can be connected to practical algorithms in the literature. We confirm that these results hold in practice in an experimental evaluation, providing an insight into the mechanisms through which reward shaping can significantly improve the complexity of reinforcement learning while retaining asymptotic performance.
Neural Design for Genetic Perturbation Experiments
Jul 26, 2022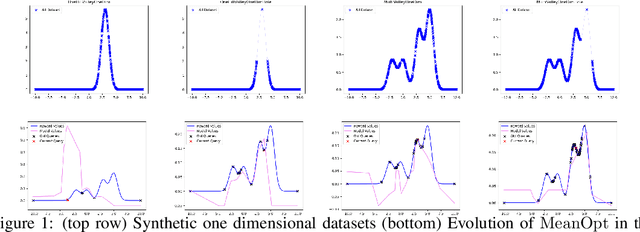
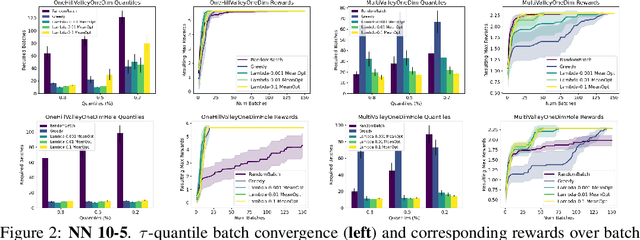
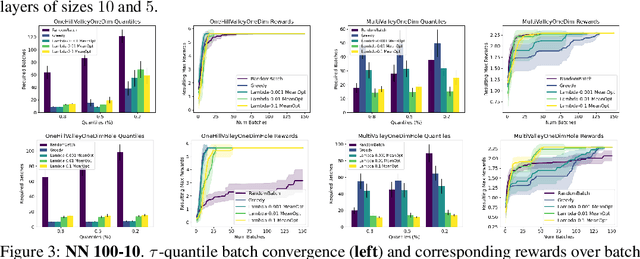

The problem of how to genetically modify cells in order to maximize a certain cellular phenotype has taken center stage in drug development over the last few years (with, for example, genetically edited CAR-T, CAR-NK, and CAR-NKT cells entering cancer clinical trials). Exhausting the search space for all possible genetic edits (perturbations) or combinations thereof is infeasible due to cost and experimental limitations. This work provides a theoretically sound framework for iteratively exploring the space of perturbations in pooled batches in order to maximize a target phenotype under an experimental budget. Inspired by this application domain, we study the problem of batch query bandit optimization and introduce the Optimistic Arm Elimination ($\mathrm{OAE}$) principle designed to find an almost optimal arm under different functional relationships between the queries (arms) and the outputs (rewards). We analyze the convergence properties of $\mathrm{OAE}$ by relating it to the Eluder dimension of the algorithm's function class and validate that $\mathrm{OAE}$ outperforms other strategies in finding optimal actions in experiments on simulated problems, public datasets well-studied in bandit contexts, and in genetic perturbation datasets when the regression model is a deep neural network. OAE also outperforms the benchmark algorithms in 3 of 4 datasets in the GeneDisco experimental planning challenge.