 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision-Language Models Respect Contextual Integrity in Location Disclosure?
Feb 04, 2026Vision-language models (VLMs) have demonstrated strong performance in image geolocation, a capability further sharpened by frontier multimodal large reasoning models (MLRMs). This poses a significant privacy risk, as these widely accessible models can be exploited to infer sensitive locations from casually shared photos, often at street-level precision, potentially surpassing the level of detail the sharer consented or intended to disclose. While recent work has proposed applying a blanket restriction on geolocation disclosure to combat this risk, these measures fail to distinguish valid geolocation uses from malicious behavior. Instead, VLMs should maintain contextual integrity by reasoning about elements within an image to determine the appropriate level of information disclosure, balancing privacy and utility. To evaluate how well models respect contextual integrity, we introduce VLM-GEOPRIVACY, a benchmark that challenges VLMs to interpret latent social norms and contextual cues in real-world images and determine the appropriate level of location disclosure. Our evaluation of 14 leading VLMs shows that, despite their ability to precisely geolocate images, the models are poorly aligned with human privacy expectations. They often over-disclose in sensitive contexts and are vulnerable to prompt-based attacks. Our results call for new design principles in multimodal systems to incorporate context-conditioned privacy reasoning.
Didactic to Constructive: Turning Expert Solutions into Learnable Reasoning
Feb 02, 2026Improving the reasoning capabilities of large language models (LLMs) typically relies either on the model's ability to sample a correct solution to be reinforced or on the existence of a stronger model able to solve the problem. However, many difficult problems remain intractable for even current frontier models, preventing the extraction of valid training signals. A promising alternative is to leverage high-quality expert human solutions, yet naive imitation of this data fails because it is fundamentally out of distribution: expert solutions are typically didactic, containing implicit reasoning gaps intended for human readers rather than computational models. Furthermore, high-quality expert solutions are expensive, necessitating generalizable sample-efficient training methods. We propose Distribution Aligned Imitation Learning (DAIL), a two-step method that bridges the distributional gap by first transforming expert solutions into detailed, in-distribution reasoning traces and then applying a contrastive objective to focus learning on expert insights and methodologies. We find that DAIL can leverage fewer than 1000 high-quality expert solutions to achieve 10-25% pass@k gains on Qwen2.5-Instruct and Qwen3 models, improve reasoning efficiency by 2x to 4x, and enable out-of-domain generalization.
GeoRC: A Benchmark for Geolocation Reasoning Chains
Jan 29, 2026Vision Language Models (VLMs) are good at recognizing the global location of a photograph -- their geolocation prediction accuracy rivals the best human experts. But many VLMs are startlingly bad at explaining which image evidence led to their prediction, even when their location prediction is correct. The reasoning chains produced by VLMs frequently hallucinate scene attributes to support their location prediction (e.g. phantom writing, imagined infrastructure, misidentified flora). In this paper, we introduce the first benchmark for geolocation reasoning chains. We focus on the global location prediction task in the popular GeoGuessr game which draws from Google Street View spanning more than 100 countries. We collaborate with expert GeoGuessr players, including the reigning world champion, to produce 800 ground truth reasoning chains for 500 query scenes. These expert reasoning chains address hundreds of different discriminative visual attributes such as license plate shape, architecture, and soil properties to name just a few. We evaluate LLM-as-a-judge and VLM-as-a-judge strategies for scoring VLM-generated reasoning chains against our expert reasoning chains and find that Qwen 3 LLM-as-a-judge correlates best with human scoring. Our benchmark reveals that while large, closed-source VLMs such as Gemini and GPT 5 rival human experts at prediction locations, they still lag behind human experts when it comes to producing auditable reasoning chains. Open weights VLMs such as Llama and Qwen catastrophically fail on our benchmark -- they perform only slightly better than a baseline in which an LLM hallucinates a reasoning chain with oracle knowledge of the photo location but no visual information at all. We believe the gap between human experts and VLMs on this task points to VLM limitations at extracting fine-grained visual attributes from high resolution images.
Auditing Language Model Unlearning via Information Decomposition
Jan 21, 2026We expose a critical limitation in current approaches to machine unlearning in language models: despite the apparent success of unlearning algorithms, information about the forgotten data remains linearly decodable from internal representations. To systematically assess this discrepancy, we introduce an interpretable, information-theoretic framework for auditing unlearning using Partial Information Decomposition (PID). By comparing model representations before and after unlearning, we decompose the mutual information with the forgotten data into distinct components, formalizing the notions of unlearned and residual knowledge. Our analysis reveals that redundant information, shared across both models, constitutes residual knowledge that persists post-unlearning and correlates with susceptibility to known adversarial reconstruction attacks. Leveraging these insights, we propose a representation-based risk score that can guide abstention on sensitive inputs at inference time, providing a practical mechanism to mitigate privacy leakage. Our work introduces a principled, representation-level audit for unlearning, offering theoretical insight and actionable tools for safer deployment of language models.
Semantic Differentiation for Tackling Challenges in Watermarking Low-Entropy Constrained Generation Outputs
Jan 14, 2026We demonstrate that while the current approaches for language model watermarking are effective for open-ended generation, they are inadequate at watermarking LM outputs for constrained generation tasks with low-entropy output spaces. Therefore, we devise SeqMark, a sequence-level watermarking algorithm with semantic differentiation that balances the output quality, watermark detectability, and imperceptibility. It improves on the shortcomings of the prevalent token-level watermarking algorithms that cause under-utilization of the sequence-level entropy available for constrained generation tasks. Moreover, we identify and improve upon a different failure mode we term region collapse, associated with prior sequence-level watermarking algorithms. This occurs because the pseudorandom partitioning of semantic space for watermarking in these approaches causes all high-probability outputs to collapse into either invalid or valid regions, leading to a trade-off in output quality and watermarking effectiveness. SeqMark instead, differentiates the high-probable output subspace and partitions it into valid and invalid regions, ensuring the even spread of high-quality outputs among all the regions. On various constrained generation tasks like machine translation, code generation, and abstractive summarization, SeqMark substantially improves watermark detection accuracy (up to 28% increase in F1) while maintaining high generation quality.
Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Oct 02, 2025Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
Tabular Data Understanding with LLMs: A Survey of Recent Advances and Challenges
Jul 31, 2025Tables have gained significant attention in large language models (LLMs) and multimodal large language models (MLLMs) due to their complex and flexible structure. Unlike linear text inputs, tables are two-dimensional, encompassing formats that range from well-structured database tables to complex, multi-layered spreadsheets, each with different purposes. This diversity in format and purpose has led to the development of specialized methods and tasks, instead of universal approaches, making navigation of table understanding tasks challenging. To address these challenges, this paper introduces key concepts through a taxonomy of tabular input representations and an introduction of table understanding tasks. We highlight several critical gaps in the field that indicate the need for further research: (1) the predominance of retrieval-focused tasks that require minimal reasoning beyond mathematical and logical operations; (2) significant challenges faced by models when processing complex table structures, large-scale tables, length context, or multi-table scenarios; and (3) the limited generalization of models across different tabular representations and formats.
Instructify: Demystifying Metadata to Visual Instruction Tuning Data Conversion
May 23, 2025Visual Instruction Tuning (VisIT) data, commonly available as human-assistant conversations with images interleaved in the human turns, are currently the most widespread vehicle for aligning strong LLMs to understand visual inputs, converting them to strong LMMs. While many VisIT datasets are available, most are constructed using ad-hoc techniques developed independently by different groups. They are often poorly documented, lack reproducible code, and rely on paid, closed-source model APIs such as GPT-4, Gemini, or Claude to convert image metadata (labels) into VisIT instructions. This leads to high costs and makes it challenging to scale, enhance quality, or generate VisIT data for new datasets. In this work, we address these challenges and propose an open and unified recipe and approach,~\textbf{\method}, for converting available metadata to VisIT instructions using open LLMs. Our multi-stage \method features an efficient framework for metadata grouping, quality control, data and prompt organization, and conversation sampling. We show that our approach can reproduce or enhance the data quality of available VisIT datasets when applied to the same image data and metadata sources, improving GPT-4 generated VisIT instructions by ~3\% on average and up to 12\% on individual benchmarks using open models, such as Gemma 2 27B and LLaMa 3.1 70B. Additionally, our approach enables effective performance scaling - both in quantity and quality - by enhancing the resulting LMM performance across a wide range of benchmarks. We also analyze the impact of various factors, including conversation format, base model selection, and resampling strategies. Our code, which supports the reproduction of equal or higher-quality VisIT datasets and facilities future metadata-to-VisIT data conversion for niche domains, is released at https://github.com/jacob-hansen/Instructify.
CARE: Aligning Language Models for Regional Cultural Awareness
Apr 07, 2025



Existing language models (LMs) often exhibit a Western-centric bias and struggle to represent diverse cultural knowledge. Previous attempts to address this rely on synthetic data and express cultural knowledge only in English. In this work, we study whether a small amount of human-written, multilingual cultural preference data can improve LMs across various model families and sizes. We first introduce CARE, a multilingual resource of 24.1k responses with human preferences on 2,580 questions about Chinese and Arab cultures, all carefully annotated by native speakers and offering more balanced coverage. Using CARE, we demonstrate that cultural alignment improves existing LMs beyond generic resources without compromising general capabilities. Moreover, we evaluate the cultural awareness of LMs, native speakers, and retrieved web content when queried in different languages. Our experiment reveals regional disparities among LMs, which may also be reflected in the documentation gap: native speakers often take everyday cultural commonsense and social norms for granted, while non-natives are more likely to actively seek out and document them. CARE is publicly available at https://github.com/Guochry/CARE (we plan to add Japanese data in the near future).
How to Protect Yourself from 5G Radiation? Investigating LLM Responses to Implicit Misinformation
Mar 12, 2025

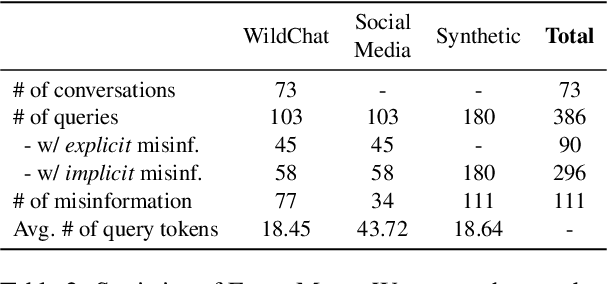
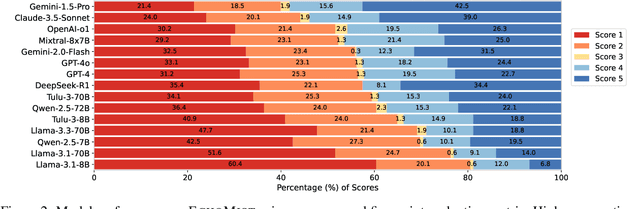
As Large Language Models (LLMs) are widely deployed in diverse scenarios, the extent to which they could tacitly spread misinformation emerges as a critical safety concern. Current research primarily evaluates LLMs on explicit false statements, overlooking how misinformation often manifests subtly as unchallenged premises in real-world user interactions. We curated ECHOMIST, the first comprehensive benchmark for implicit misinformation, where the misinformed assumptions are embedded in a user query to LLMs. ECHOMIST is based on rigorous selection criteria and carefully curated data from diverse sources, including real-world human-AI conversations and social media interactions. We also introduce a new evaluation metric to measure whether LLMs can recognize and counter false information rather than amplify users' misconceptions. Through an extensive empirical study on a wide range of LLMs, including GPT-4, Claude, and Llama, we find that current models perform alarmingly poorly on this task, often failing to detect false premises and generating misleading explanations. Our findings underscore the critical need for an increased focus on implicit misinformation in LLM safety research.