 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitch Point biased Self-Training: Re-purposing Pretrained Models for Code-Switching
Nov 01, 2021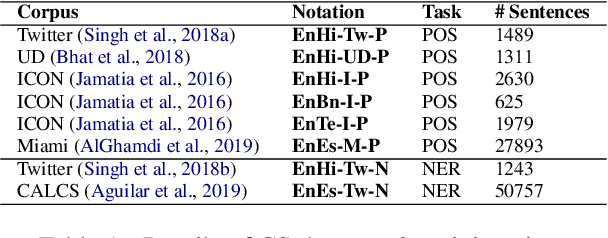
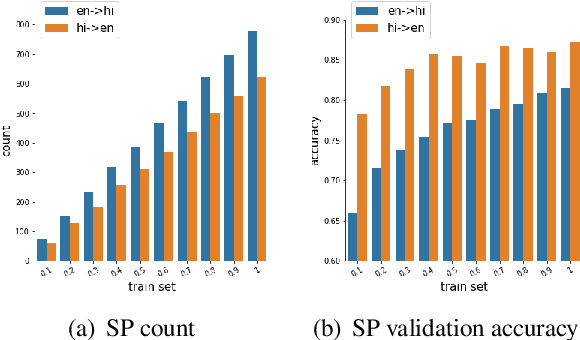
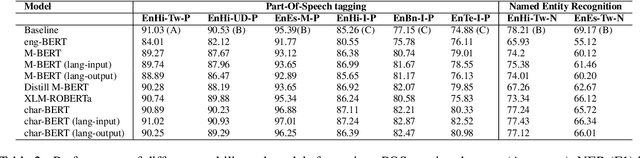
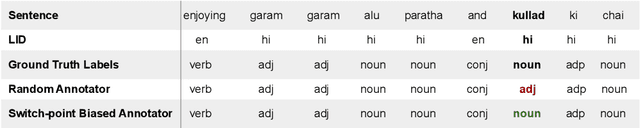
Code-switching (CS), a ubiquitous phenomenon due to the ease of communication it offers in multilingual communities still remains an understudied problem in language processing. The primary reasons behind this are: (1) minimal efforts in leveraging large pretrained multilingual models, and (2) the lack of annotated data. The distinguishing case of low performance of multilingual models in CS is the intra-sentence mixing of languages leading to switch points. We first benchmark two sequence labeling tasks -- POS and NER on 4 different language pairs with a suite of pretrained models to identify the problems and select the best performing model, char-BERT, among them (addressing (1)). We then propose a self training method to repurpose the existing pretrained models using a switch-point bias by leveraging unannotated data (addressing (2)). We finally demonstrate that our approach performs well on both tasks by reducing the gap between the switch point performance while retaining the overall performance on two distinct language pairs in both the tasks. Our code is available here: https://github.com/PC09/EMNLP2021-Switch-Point-biased-Self-Training.
Towards Language Modelling in the Speech Domain Using Sub-word Linguistic Units
Oct 31, 2021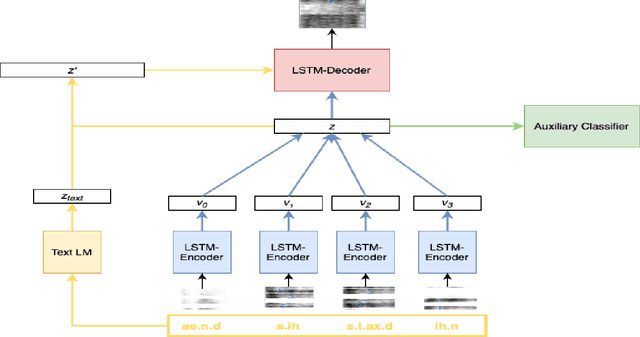

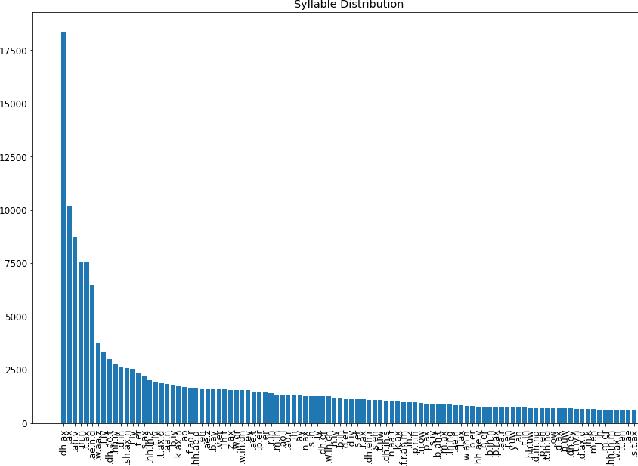
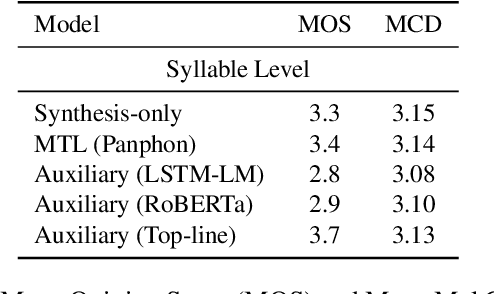
Language models (LMs) for text data have been studied extensively for their usefulness in language generation and other downstream tasks. However, language modelling purely in the speech domain is still a relatively unexplored topic, with traditional speech LMs often depending on auxiliary text LMs for learning distributional aspects of the language. For the English language, these LMs treat words as atomic units, which presents inherent challenges to language modelling in the speech domain. In this paper, we propose a novel LSTM-based generative speech LM that is inspired by the CBOW model and built on linguistic units including syllables and phonemes. This offers better acoustic consistency across utterances in the dataset, as opposed to single melspectrogram frames, or whole words. With a limited dataset, orders of magnitude smaller than that required by contemporary generative models, our model closely approximates babbling speech. We show the effect of training with auxiliary text LMs, multitask learning objectives, and auxiliary articulatory features. Through our experiments, we also highlight some well known, but poorly documented challenges in training generative speech LMs, including the mismatch between the supervised learning objective with which these models are trained such as Mean Squared Error (MSE), and the true objective, which is speech quality. Our experiments provide an early indication that while validation loss and Mel Cepstral Distortion (MCD) are not strongly correlated with generated speech quality, traditional text language modelling metrics like perplexity and next-token-prediction accuracy might be.
Intent Classification Using Pre-Trained Embeddings For Low Resource Languages
Oct 18, 2021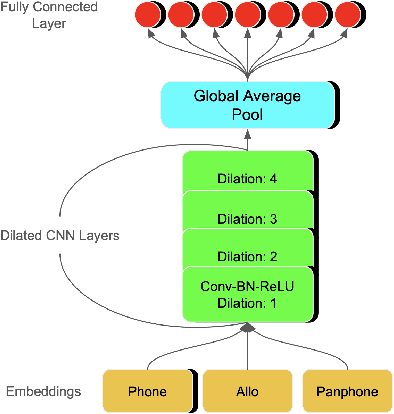
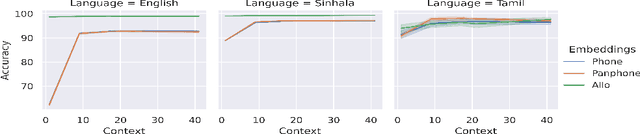
Building Spoken Language Understanding (SLU) systems that do not rely on language specific Automatic Speech Recognition (ASR) is an important yet less explored problem in language processing. In this paper, we present a comparative study aimed at employing a pre-trained acoustic model to perform SLU in low resource scenarios. Specifically, we use three different embeddings extracted using Allosaurus, a pre-trained universal phone decoder: (1) Phone (2) Panphone, and (3) Allo embeddings. These embeddings are then used in identifying the spoken intent. We perform experiments across three different languages: English, Sinhala, and Tamil each with different data sizes to simulate high, medium, and low resource scenarios. Our system improves on the state-of-the-art (SOTA) intent classification accuracy by approximately 2.11% for Sinhala and 7.00% for Tamil and achieves competitive results on English. Furthermore, we present a quantitative analysis of how the performance scales with the number of training examples used per intent.
Speech Summarization using Restricted Self-Attention
Oct 12, 2021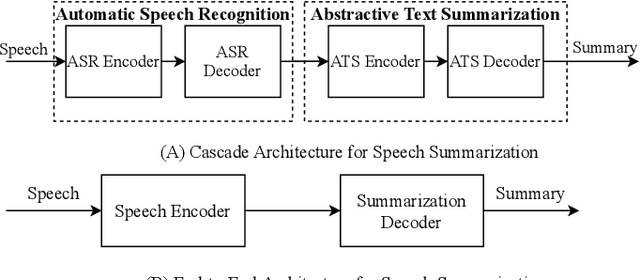
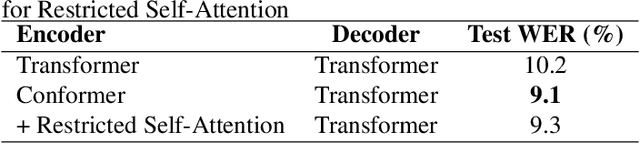
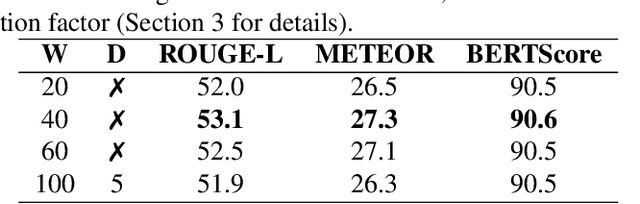
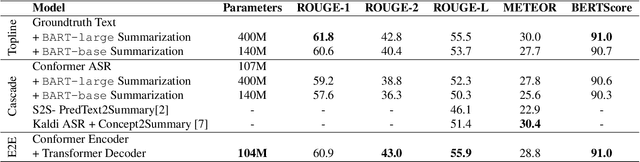
Speech summarization is typically performed by using a cascade of speech recognition and text summarization models. End-to-end modeling of speech summarization models is challenging due to memory and compute constraints arising from long input audio sequences. Recent work in document summarization has inspired methods to reduce the complexity of self-attentions, which enables transformer models to handle long sequences. In this work, we introduce a single model optimized end-to-end for speech summarization. We apply the restricted self-attention technique from text-based models to speech models to address the memory and compute constraints. We demonstrate that the proposed model learns to directly summarize speech for the How-2 corpus of instructional videos. The proposed end-to-end model outperforms the previously proposed cascaded model by 3 points absolute on ROUGE. Further, we consider the spoken language understanding task of predicting concepts from speech inputs and show that the proposed end-to-end model outperforms the cascade model by 4 points absolute F-1.
Rethinking End-to-End Evaluation of Decomposable Tasks: A Case Study on Spoken Language Understanding
Jun 29, 2021
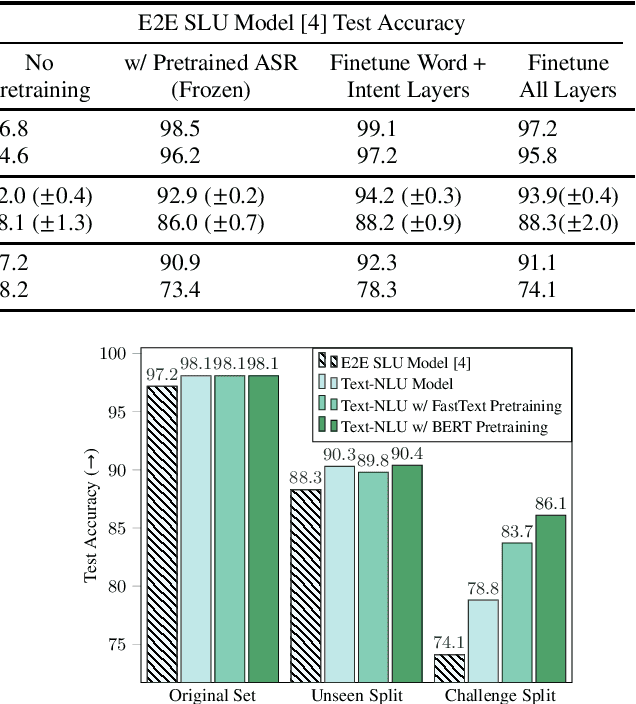
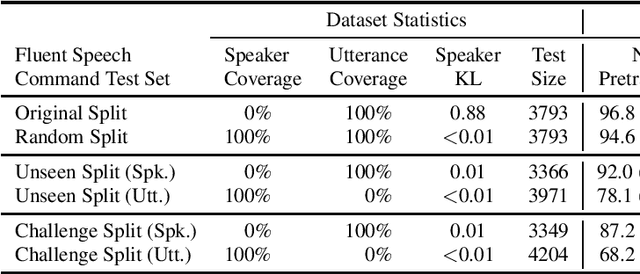

Decomposable tasks are complex and comprise of a hierarchy of sub-tasks. Spoken intent prediction, for example, combines automatic speech recognition and natural language understanding. Existing benchmarks, however, typically hold out examples for only the surface-level sub-task. As a result, models with similar performance on these benchmarks may have unobserved performance differences on the other sub-tasks. To allow insightful comparisons between competitive end-to-end architectures, we propose a framework to construct robust test sets using coordinate ascent over sub-task specific utility functions. Given a dataset for a decomposable task, our method optimally creates a test set for each sub-task to individually assess sub-components of the end-to-end model. Using spoken language understanding as a case study, we generate new splits for the Fluent Speech Commands and Snips SmartLights datasets. Each split has two test sets: one with held-out utterances assessing natural language understanding abilities, and one with held-out speakers to test speech processing skills. Our splits identify performance gaps up to 10% between end-to-end systems that were within 1% of each other on the original test sets. These performance gaps allow more realistic and actionable comparisons between different architectures, driving future model development. We release our splits and tools for the community.
CodemixedNLP: An Extensible and Open NLP Toolkit for Code-Mixing
Jun 10, 2021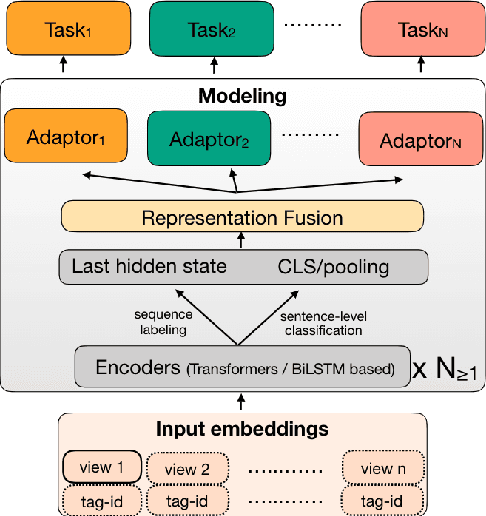
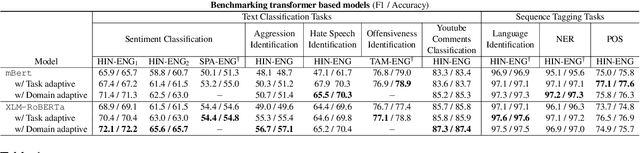
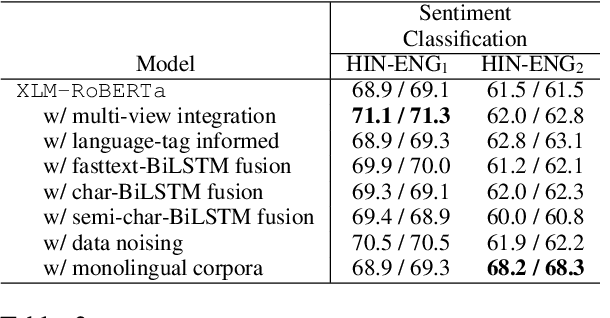

The NLP community has witnessed steep progress in a variety of tasks across the realms of monolingual and multilingual language processing recently. These successes, in conjunction with the proliferating mixed language interactions on social media have boosted interest in modeling code-mixed texts. In this work, we present CodemixedNLP, an open-source library with the goals of bringing together the advances in code-mixed NLP and opening it up to a wider machine learning community. The library consists of tools to develop and benchmark versatile model architectures that are tailored for mixed texts, methods to expand training sets, techniques to quantify mixing styles, and fine-tuned state-of-the-art models for 7 tasks in Hinglish. We believe this work has a potential to foster a distributed yet collaborative and sustainable ecosystem in an otherwise dispersed space of code-mixing research. The toolkit is designed to be simple, easily extensible, and resourceful to both researchers as well as practitioners.
Grounding 'Grounding' in NLP
Jun 04, 2021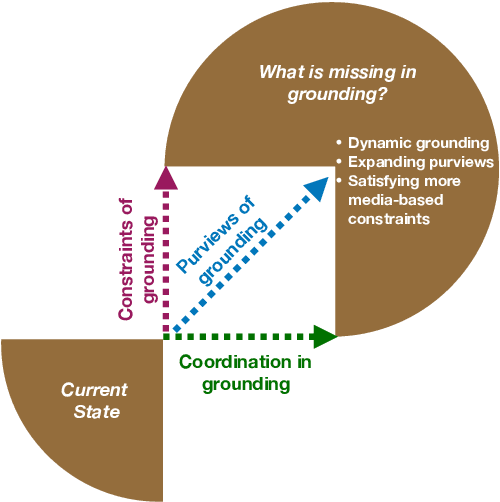
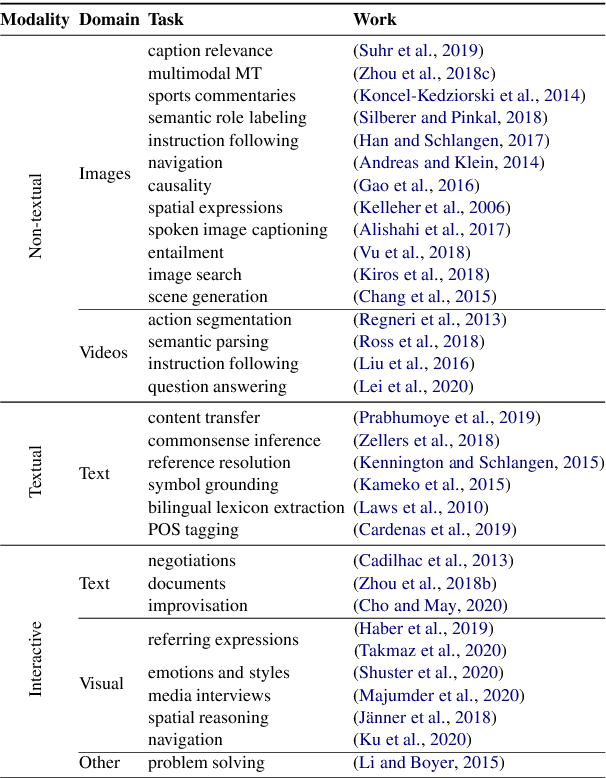
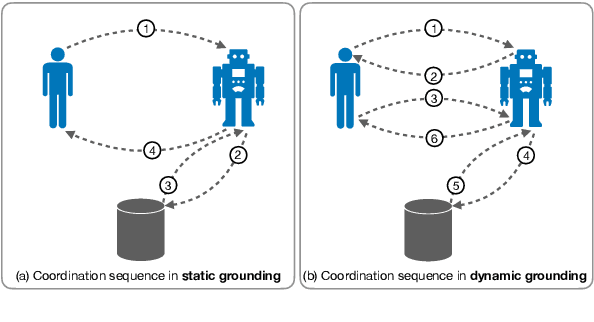

The NLP community has seen substantial recent interest in grounding to facilitate interaction between language technologies and the world. However, as a community, we use the term broadly to reference any linking of text to data or non-textual modality. In contrast, Cognitive Science more formally defines "grounding" as the process of establishing what mutual information is required for successful communication between two interlocutors -- a definition which might implicitly capture the NLP usage but differs in intent and scope. We investigate the gap between these definitions and seek answers to the following questions: (1) What aspects of grounding are missing from NLP tasks? Here we present the dimensions of coordination, purviews and constraints. (2) How is the term "grounding" used in the current research? We study the trends in datasets, domains, and tasks introduced in recent NLP conferences. And finally, (3) How to advance our current definition to bridge the gap with Cognitive Science? We present ways to both create new tasks or repurpose existing ones to make advancements towards achieving a more complete sense of grounding.
Focused Attention Improves Document-Grounded Generation
Apr 26, 2021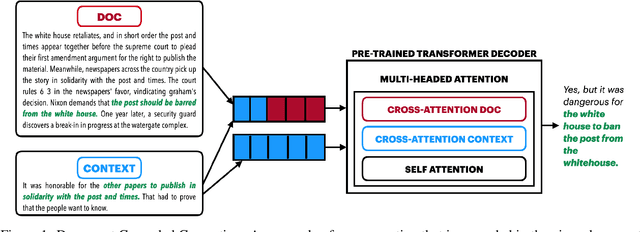
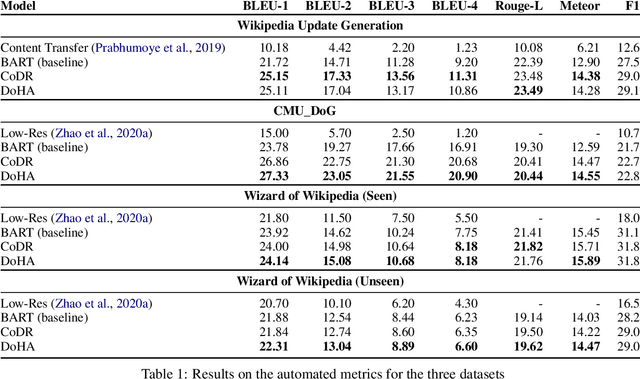
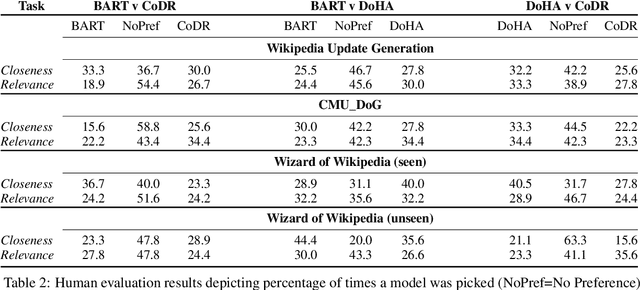
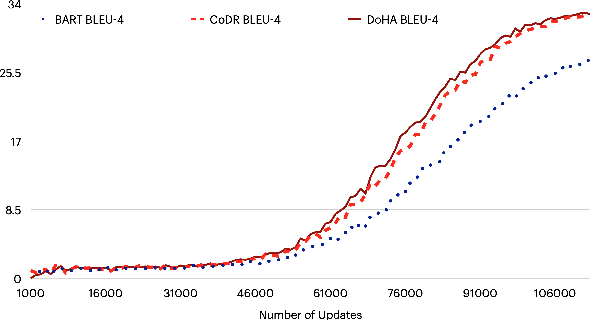
Document grounded generation is the task of using the information provided in a document to improve text generation. This work focuses on two different document grounded generation tasks: Wikipedia Update Generation task and Dialogue response generation. Our work introduces two novel adaptations of large scale pre-trained encoder-decoder models focusing on building context driven representation of the document and enabling specific attention to the information in the document. Additionally, we provide a stronger BART baseline for these tasks. Our proposed techniques outperform existing methods on both automated (at least 48% increase in BLEU-4 points) and human evaluation for closeness to reference and relevance to the document. Furthermore, we perform comprehensive manual inspection of the generated output and categorize errors to provide insights into future directions in modeling these tasks.
Intent Recognition and Unsupervised Slot Identification for Low Resourced Spoken Dialog Systems
Apr 03, 2021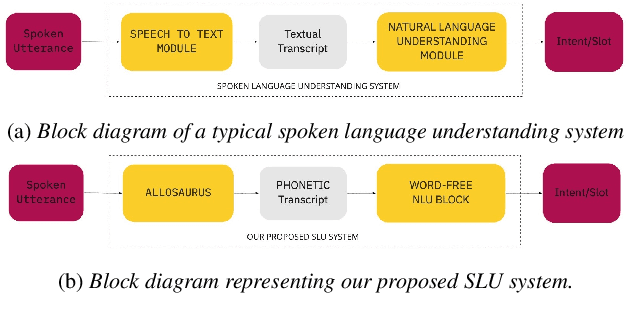

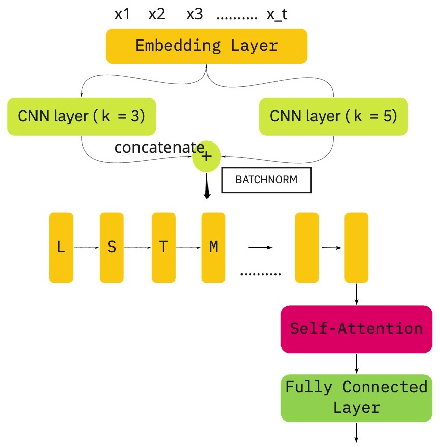

Intent Recognition and Slot Identification are crucial components in spoken language understanding (SLU) systems. In this paper, we present a novel approach towards both these tasks in the context of low resourced and unwritten languages. We present an acoustic based SLU system that converts speech to its phonetic transcription using a universal phone recognition system. We build a word-free natural language understanding module that does intent recognition and slot identification from these phonetic transcription. Our proposed SLU system performs competitively for resource rich scenarios and significantly outperforms existing approaches as the amount of available data reduces. We observe more than 10% improvement for intent classification in Tamil and more than 5% improvement for intent classification in Sinhala. We also present a novel approach towards unsupervised slot identification using normalized attention scores. This approach can be used for unsupervised slot labelling, data augmentation and to generate data for a new slot in a one-shot way with only one speech recording
Unsupervised Self-Training for Sentiment Analysis of Code-Switched Data
Mar 27, 2021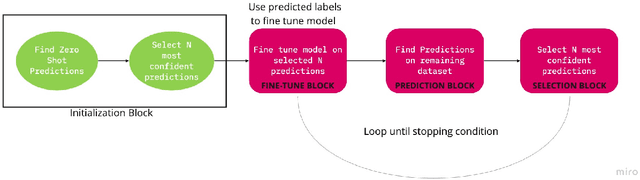

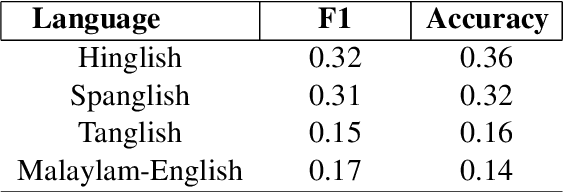
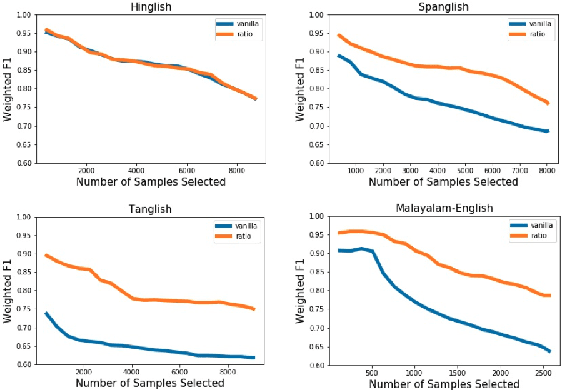
Sentiment analysis is an important task in understanding social media content like customer reviews, Twitter and Facebook feeds etc. In multilingual communities around the world, a large amount of social media text is characterized by the presence of Code-Switching. Thus, it has become important to build models that can handle code-switched data. However, annotated code-switched data is scarce and there is a need for unsupervised models and algorithms. We propose a general framework called Unsupervised Self-Training and show its applications for the specific use case of sentiment analysis of code-switched data. We use the power of pre-trained BERT models for initialization and fine-tune them in an unsupervised manner, only using pseudo labels produced by zero-shot transfer. We test our algorithm on multiple code-switched languages and provide a detailed analysis of the learning dynamics of the algorithm with the aim of answering the question - `Does our unsupervised model understand the Code-Switched languages or does it just learn its representations?'. Our unsupervised models compete well with their supervised counterparts, with their performance reaching within 1-7\% (weighted F1 scores) when compared to supervised models trained for a two class problem.