 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Privacy-Preserving Ensemble Attention Distillation
Oct 16, 2022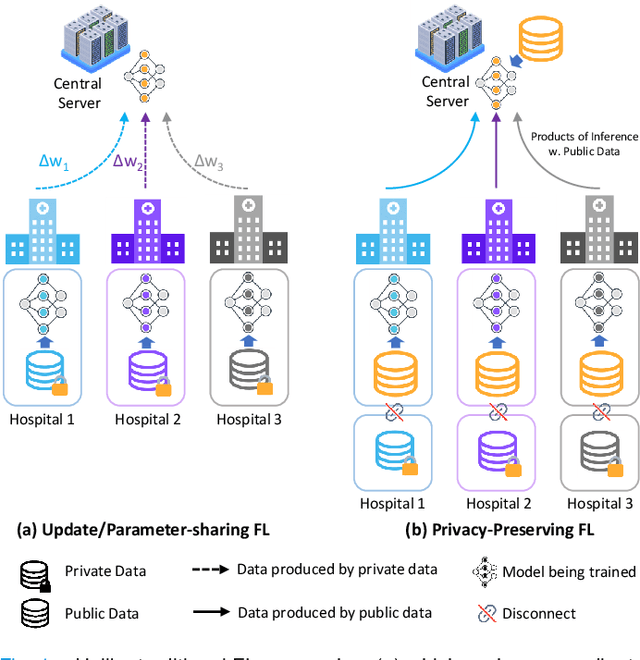
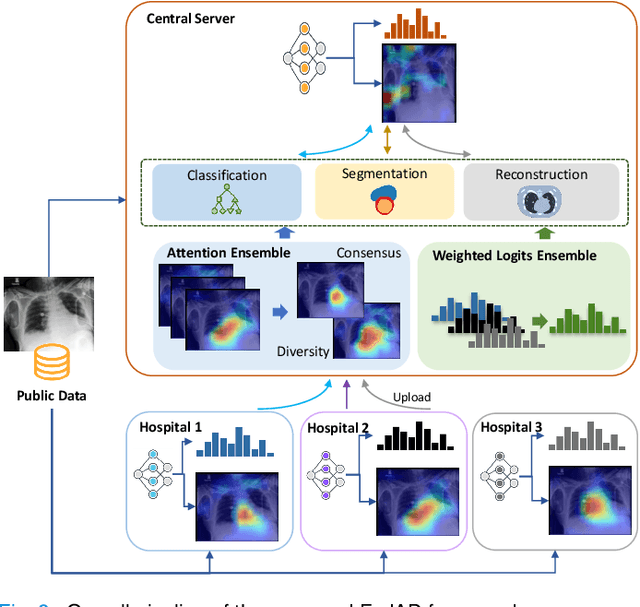
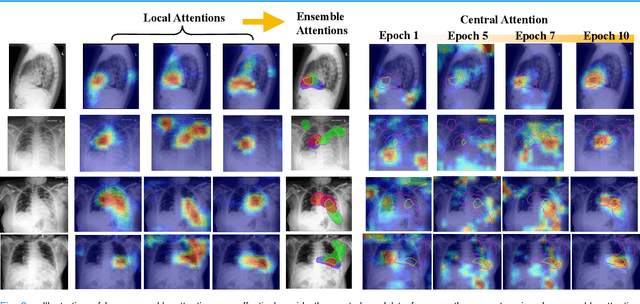
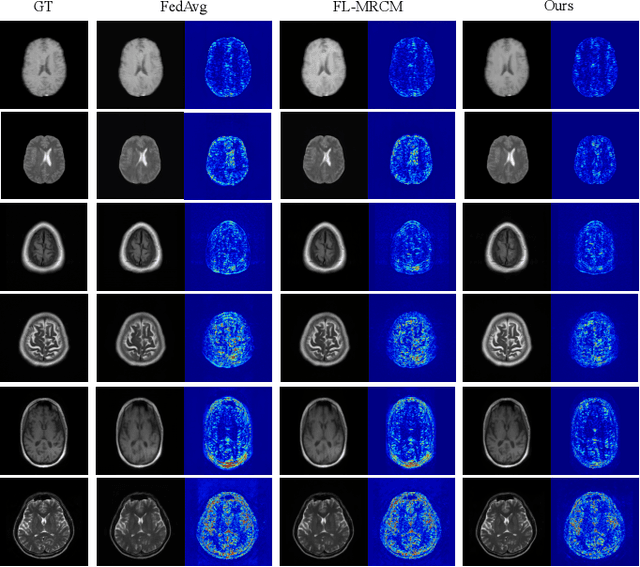
Federated Learning (FL) is a machine learning paradigm where many local nodes collaboratively train a central model while keeping the training data decentralized. This is particularly relevant for clinical applications since patient data are usually not allowed to be transferred out of medical facilities, leading to the need for FL. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they also require numerous rounds of synchronized communication and, more importantly, suffer from a privacy leakage risk. We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation in this work. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022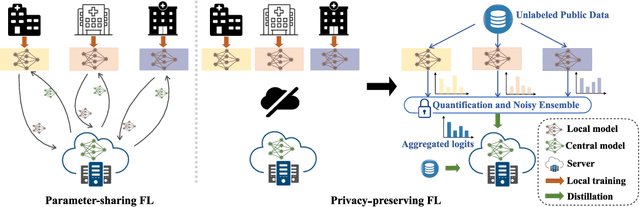
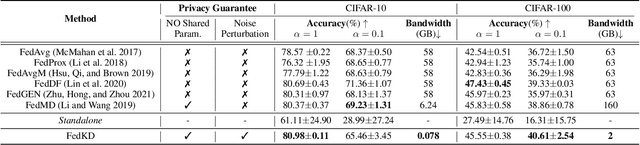
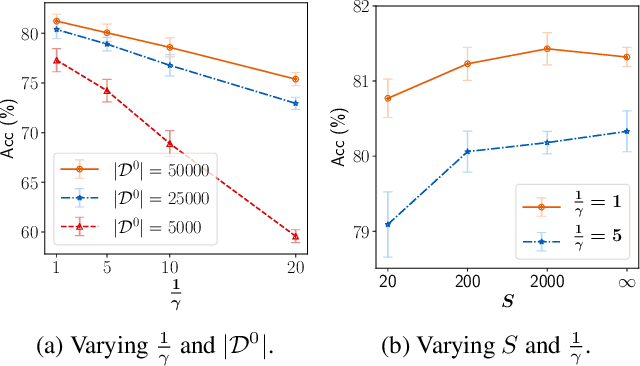
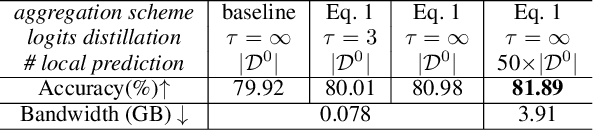
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
Surya Namaskar: real-time advanced yoga pose recognition and correction for smart healthcare
Sep 06, 2022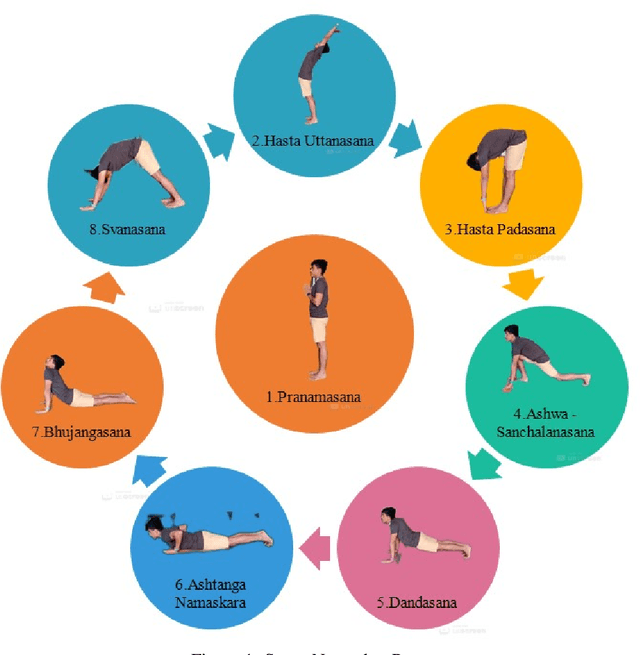
Nowadays, yoga has gained worldwide attention because of increasing levels of stress in the modern way of life, and there are many ways or resources to learn yoga. The word yoga means a deep connection between the mind and body. Today there is substantial Medical and scientific evidence to show that the very fundamentals of the activity of our brain, our chemistry even our genetic content can be changed by practicing different systems of yoga. Suryanamaskar, also known as salute to the sun, is a yoga practice that combines eight different forms and 12 asanas(4 asana get repeated) devoted to the Hindu Sun God, Surya. Suryanamaskar offers a number of health benefits such as strengthening muscles and helping to control blood sugar levels. Here the Mediapipe Library is used to analyze Surya namaskar situations. Standing is detected in real time with advanced software, as one performs Surya namaskar in front of the camera. The class divider identifies the form as one of the following: Pranamasana, Hasta Padasana, Hasta Uttanasana, Ashwa - Sanchalan asana, Ashtanga Namaskar, Dandasana, or Bhujangasana and Svanasana. Deep learning-based techniques(CNN) are used to develop this model with model accuracy of 98.68 percent and an accuracy score of 0.75 to detect correct yoga (Surya Namaskar ) posture. With this method, the users can practice the desired pose and can check if the pose that the person is doing is correct or not. It will help in doing all the different poses of surya namaskar correctly and increase the efficiency of the yoga practitioner. This paper describes the whole framework which is to be implemented in the model.
A Joint Learning Approach for Semi-supervised Neural Topic Modeling
Apr 07, 2022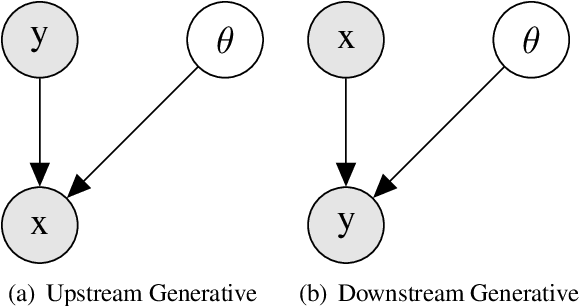

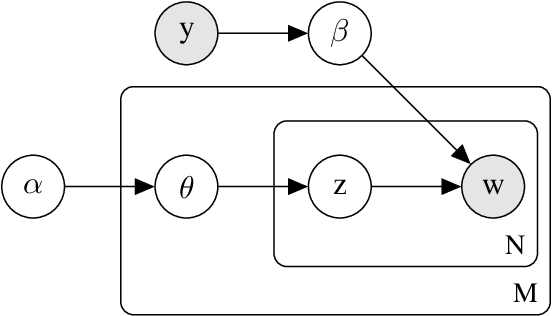

Topic models are some of the most popular ways to represent textual data in an interpret-able manner. Recently, advances in deep generative models, specifically auto-encoding variational Bayes (AEVB), have led to the introduction of unsupervised neural topic models, which leverage deep generative models as opposed to traditional statistics-based topic models. We extend upon these neural topic models by introducing the Label-Indexed Neural Topic Model (LI-NTM), which is, to the extent of our knowledge, the first effective upstream semi-supervised neural topic model. We find that LI-NTM outperforms existing neural topic models in document reconstruction benchmarks, with the most notable results in low labeled data regimes and for data-sets with informative labels; furthermore, our jointly learned classifier outperforms baseline classifiers in ablation studies.
Real-time Recognition of Yoga Poses using computer Vision for Smart Health Care
Jan 19, 2022Nowadays, yoga has become a part of life for many people. Exercises and sports technological assistance is implemented in yoga pose identification. In this work, a self-assistance based yoga posture identification technique is developed, which helps users to perform Yoga with the correction feature in Real-time. The work also presents Yoga-hand mudra (hand gestures) identification. The YOGI dataset has been developed which include 10 Yoga postures with around 400-900 images of each pose and also contain 5 mudras for identification of mudras postures. It contains around 500 images of each mudra. The feature has been extracted by making a skeleton on the body for yoga poses and hand for mudra poses. Two different algorithms have been used for creating a skeleton one for yoga poses and the second for hand mudras. Angles of the joints have been extracted as a features for different machine learning and deep learning models. among all the models XGBoost with RandomSearch CV is most accurate and gives 99.2\% accuracy. The complete design framework is described in the present paper.
Joint Symmetry Detection and Shape Matching for Non-Rigid Point Cloud
Dec 05, 2021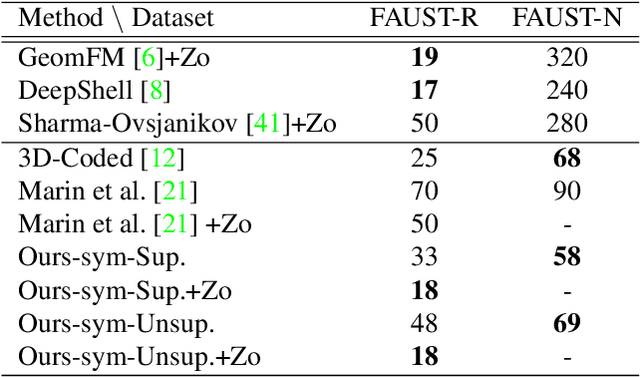



Despite the success of deep functional maps in non-rigid 3D shape matching, there exists no learning framework that models both self-symmetry and shape matching simultaneously. This is despite the fact that errors due to symmetry mismatch are a major challenge in non-rigid shape matching. In this paper, we propose a novel framework that simultaneously learns both self symmetry as well as a pairwise map between a pair of shapes. Our key idea is to couple a self symmetry map and a pairwise map through a regularization term that provides a joint constraint on both of them, thereby, leading to more accurate maps. We validate our method on several benchmarks where it outperforms many competitive baselines on both tasks.
Object-Aware Cropping for Self-Supervised Learning
Dec 01, 2021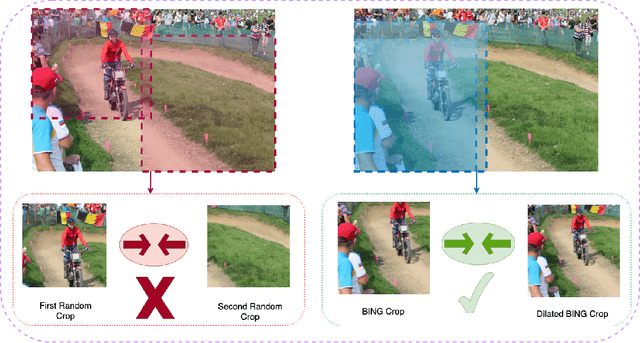
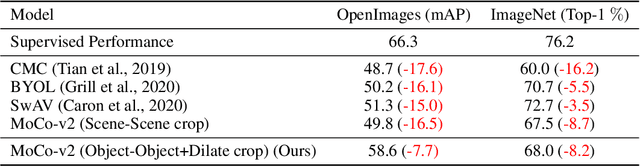
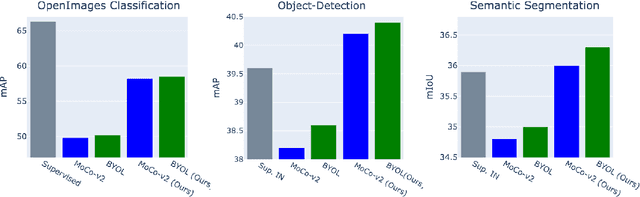

A core component of the recent success of self-supervised learning is cropping data augmentation, which selects sub-regions of an image to be used as positive views in the self-supervised loss. The underlying assumption is that randomly cropped and resized regions of a given image share information about the objects of interest, which the learned representation will capture. This assumption is mostly satisfied in datasets such as ImageNet where there is a large, centered object, which is highly likely to be present in random crops of the full image. However, in other datasets such as OpenImages or COCO, which are more representative of real world uncurated data, there are typically multiple small objects in an image. In this work, we show that self-supervised learning based on the usual random cropping performs poorly on such datasets. We propose replacing one or both of the random crops with crops obtained from an object proposal algorithm. This encourages the model to learn both object and scene level semantic representations. Using this approach, which we call object-aware cropping, results in significant improvements over scene cropping on classification and object detection benchmarks. For example, on OpenImages, our approach achieves an improvement of 8.8% mAP over random scene-level cropping using MoCo-v2 based pre-training. We also show significant improvements on COCO and PASCAL-VOC object detection and segmentation tasks over the state-of-the-art self-supervised learning approaches. Our approach is efficient, simple and general, and can be used in most existing contrastive and non-contrastive self-supervised learning frameworks.
On Learning Prediction-Focused Mixtures
Oct 27, 2021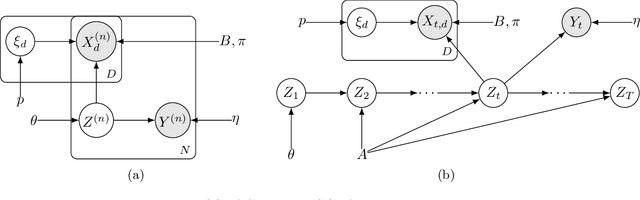
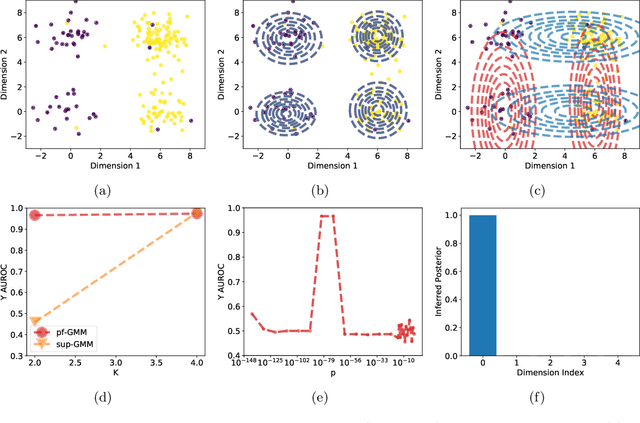
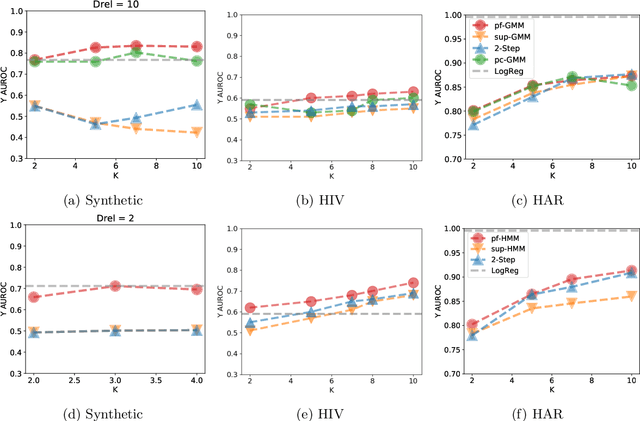
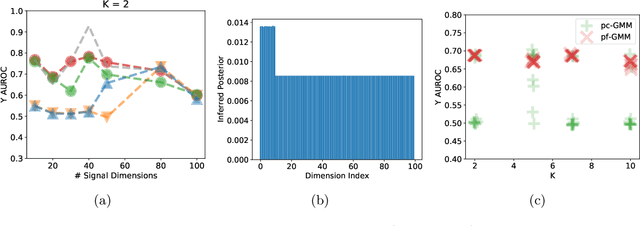
Probabilistic models help us encode latent structures that both model the data and are ideally also useful for specific downstream tasks. Among these, mixture models and their time-series counterparts, hidden Markov models, identify discrete components in the data. In this work, we focus on a constrained capacity setting, where we want to learn a model with relatively few components (e.g. for interpretability purposes). To maintain prediction performance, we introduce prediction-focused modeling for mixtures, which automatically selects the dimensions relevant to the prediction task. Our approach identifies relevant signal from the input, outperforms models that are not prediction-focused, and is easy to optimize; we also characterize when prediction-focused modeling can be expected to work.
Learning Canonical Embedding for Non-rigid Shape Matching
Oct 06, 2021
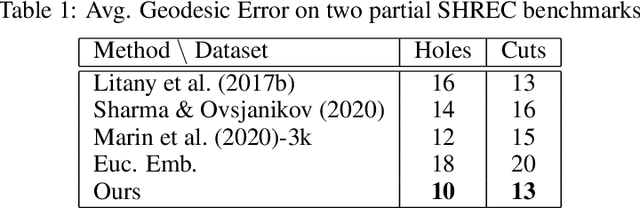
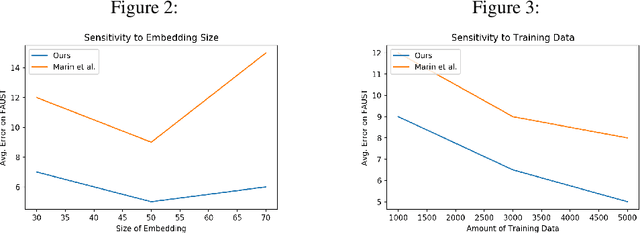
This paper provides a novel framework that learns canonical embeddings for non-rigid shape matching. In contrast to prior work in this direction, our framework is trained end-to-end and thus avoids instabilities and constraints associated with the commonly-used Laplace-Beltrami basis or sequential optimization schemes. On multiple datasets, we demonstrate that learning self symmetry maps with a deep functional map projects 3D shapes into a low dimensional canonical embedding that facilitates non-rigid shape correspondence via a simple nearest neighbor search. Our framework outperforms multiple recent learning based methods on FAUST and SHREC benchmarks while being computationally cheaper, data-efficient, and robust.
Scale Normalized Image Pyramids with AutoFocus for Object Detection
Feb 10, 2021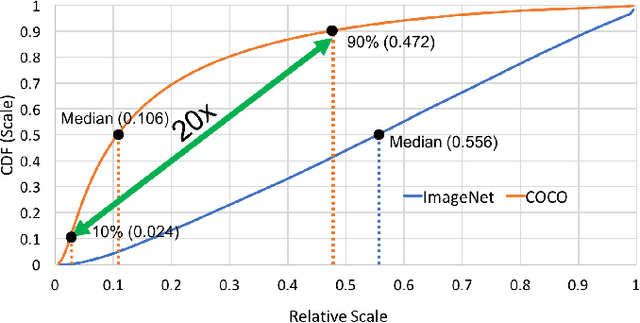

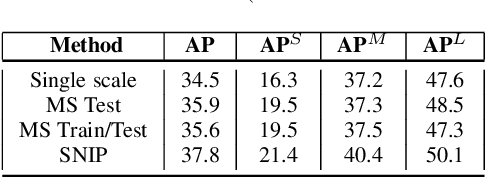
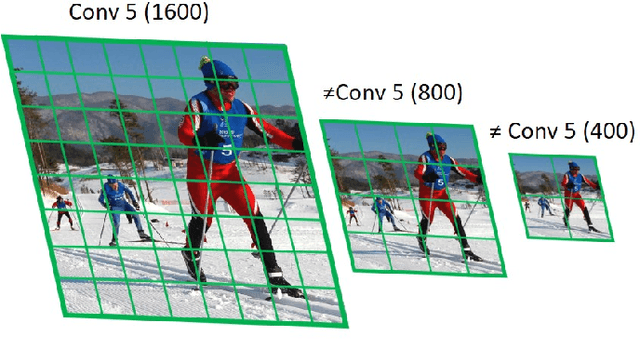
We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects' size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3 times speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it's akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5 times speed-up during inference when used with SNIP.