 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreconditioned DeltaNet: Curvature-aware Sequence Modeling for Linear Recurrences
Apr 22, 2026To address the increasing long-context compute limitations of softmax attention, several subquadratic recurrent operators have been developed. This work includes models such as Mamba-2, DeltaNet, Gated DeltaNet (GDN), and Kimi Delta Attention (KDA). As the space of recurrences grows, a parallel line of work has arisen to taxonomize them. One compelling view is the test-time regression (TTR) framework, which interprets recurrences as performing online least squares updates that learn a linear map from the keys to values. Existing delta-rule recurrences can be seen as first-order approximations to this objective, but notably ignore the curvature of the least-squares loss during optimization. In this work, we address this by introducing preconditioning to these recurrences. Starting from the theory of online least squares, we derive equivalences between linear attention and the delta rule in the exactly preconditioned case. Next, we realize this theory in practice by proposing a diagonal approximation: this enables us to introduce preconditioned variants of DeltaNet, GDN, and KDA alongside efficient chunkwise parallel algorithms for computing them. Empirically, we find that our preconditioned delta-rule recurrences yield consistent performance improvements across synthetic recall benchmarks and language modeling at the 340M and 1B scale.
Quantifying Memory Utilization with Effective State-Size
Apr 28, 2025The need to develop a general framework for architecture analysis is becoming increasingly important, given the expanding design space of sequence models. To this end, we draw insights from classical signal processing and control theory, to develop a quantitative measure of \textit{memory utilization}: the internal mechanisms through which a model stores past information to produce future outputs. This metric, which we call \textbf{\textit{effective state-size}} (ESS), is tailored to the fundamental class of systems with \textit{input-invariant} and \textit{input-varying linear operators}, encompassing a variety of computational units such as variants of attention, convolutions, and recurrences. Unlike prior work on memory utilization, which either relies on raw operator visualizations (e.g. attention maps), or simply the total \textit{memory capacity} (i.e. cache size) of a model, our metrics provide highly interpretable and actionable measurements. In particular, we show how ESS can be leveraged to improve initialization strategies, inform novel regularizers and advance the performance-efficiency frontier through model distillation. Furthermore, we demonstrate that the effect of context delimiters (such as end-of-speech tokens) on ESS highlights cross-architectural differences in how large language models utilize their available memory to recall information. Overall, we find that ESS provides valuable insights into the dynamics that dictate memory utilization, enabling the design of more efficient and effective sequence models.
Leveraging Low-Rank and Sparse Recurrent Connectivity for Robust Closed-Loop Control
Oct 05, 2023



Developing autonomous agents that can interact with changing environments is an open challenge in machine learning. Robustness is particularly important in these settings as agents are often fit offline on expert demonstrations but deployed online where they must generalize to the closed feedback loop within the environment. In this work, we explore the application of recurrent neural networks to tasks of this nature and understand how a parameterization of their recurrent connectivity influences robustness in closed-loop settings. Specifically, we represent the recurrent connectivity as a function of rank and sparsity and show both theoretically and empirically that modulating these two variables has desirable effects on network dynamics. The proposed low-rank, sparse connectivity induces an interpretable prior on the network that proves to be most amenable for a class of models known as closed-form continuous-time neural networks (CfCs). We find that CfCs with fewer parameters can outperform their full-rank, fully-connected counterparts in the online setting under distribution shift. This yields memory-efficient and robust agents while opening a new perspective on how we can modulate network dynamics through connectivity.
A Joint Learning Approach for Semi-supervised Neural Topic Modeling
Apr 07, 2022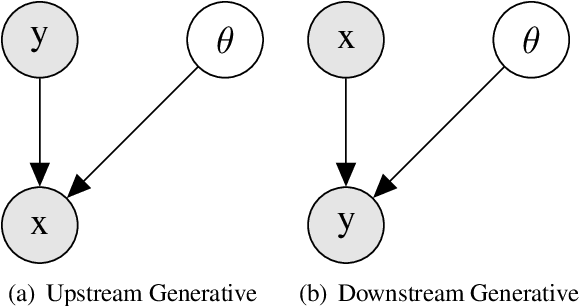

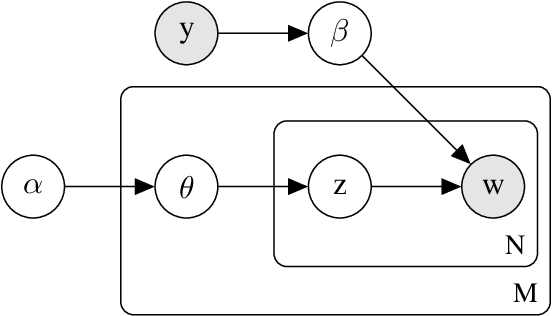

Topic models are some of the most popular ways to represent textual data in an interpret-able manner. Recently, advances in deep generative models, specifically auto-encoding variational Bayes (AEVB), have led to the introduction of unsupervised neural topic models, which leverage deep generative models as opposed to traditional statistics-based topic models. We extend upon these neural topic models by introducing the Label-Indexed Neural Topic Model (LI-NTM), which is, to the extent of our knowledge, the first effective upstream semi-supervised neural topic model. We find that LI-NTM outperforms existing neural topic models in document reconstruction benchmarks, with the most notable results in low labeled data regimes and for data-sets with informative labels; furthermore, our jointly learned classifier outperforms baseline classifiers in ablation studies.