 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Data Normalization on Deep Neural Network for Time Series Forecasting
Jan 07, 2019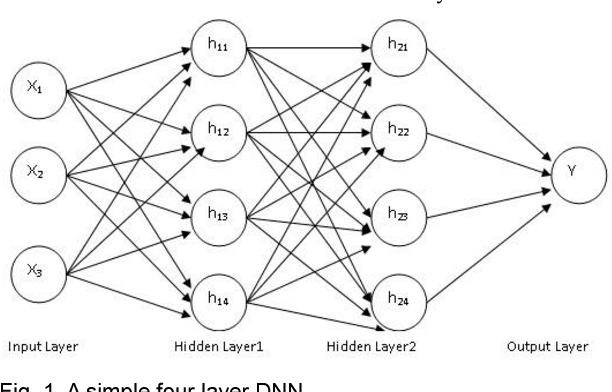
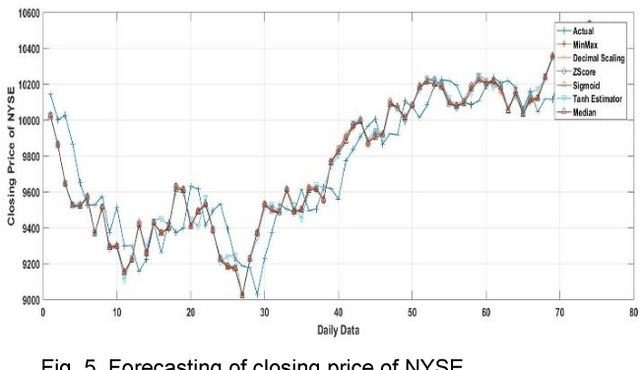
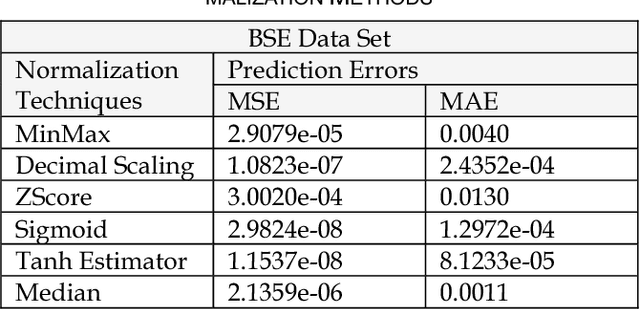
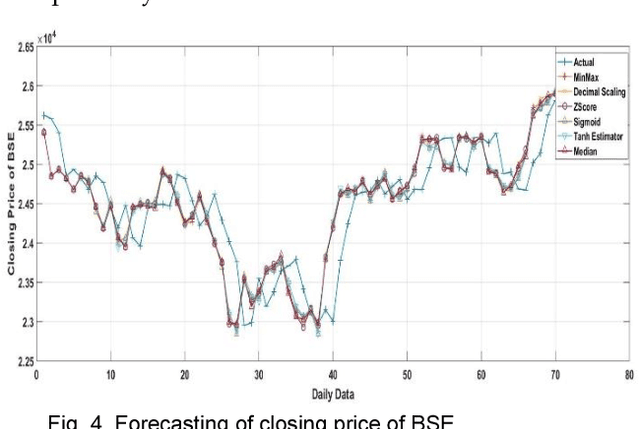
For the last few years it has been observed that the Deep Neural Networks (DNNs) has achieved an excellent success in image classification, speech recognition. But DNNs are suffer great deal of challenges for time series forecasting because most of the time series data are nonlinear in nature and highly dynamic in behaviour. The time series forecasting has a great impact on our socio-economic environment. Hence, to deal with these challenges its need to be redefined the DNN model and keeping this in mind, data pre-processing, network architecture and network parameters are need to be consider before feeding the data into DNN models. Data normalization is the basic data pre-processing technique form which learning is to be done. The effectiveness of time series forecasting is heavily depend on the data normalization technique. In this paper, different normalization methods are used on time series data before feeding the data into the DNN model and we try to find out the impact of each normalization technique on DNN to forecast the time series. Here the Deep Recurrent Neural Network (DRNN) is used to predict the closing index of Bombay Stock Exchange (BSE) and New York Stock Exchange (NYSE) by using BSE and NYSE time series data.
TarMAC: Targeted Multi-Agent Communication
Oct 26, 2018
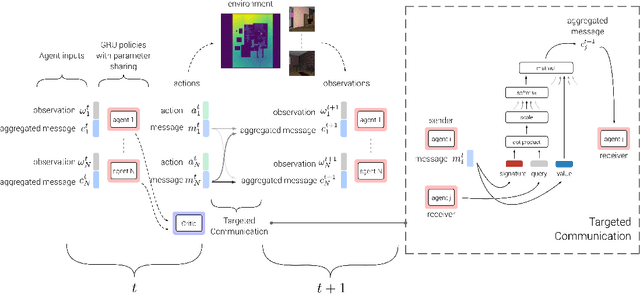
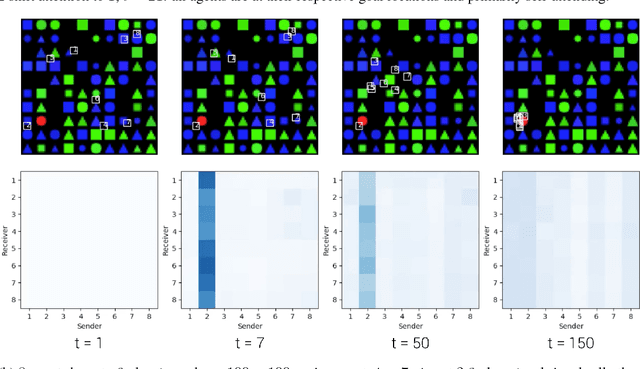

We explore a collaborative multi-agent reinforcement learning setting where a team of agents attempts to solve cooperative tasks in partially-observable environments. In this scenario, learning an effective communication protocol is key. We propose a communication architecture that allows for targeted communication, where agents learn both what messages to send and who to send them to, solely from downstream task-specific reward without any communication supervision. Additionally, we introduce a multi-stage communication approach where the agents co-ordinate via multiple rounds of communication before taking actions in the environment. We evaluate our approach on a diverse set of cooperative multi-agent tasks, of varying difficulties, with varying number of agents, in a variety of environments ranging from 2D grid layouts of shapes and simulated traffic junctions to complex 3D indoor environments. We demonstrate the benefits of targeted as well as multi-stage communication. Moreover, we show that the targeted communication strategies learned by agents are both interpretable and intuitive.
Neural Modular Control for Embodied Question Answering
Oct 26, 2018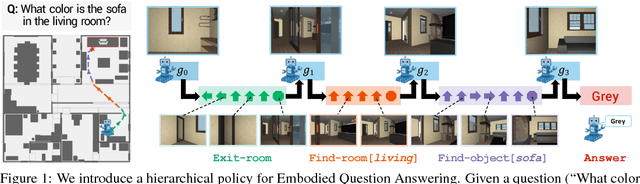

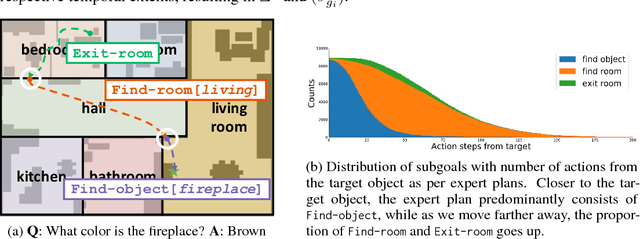
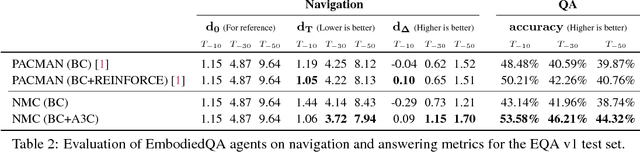
We present a modular approach for learning policies for navigation over long planning horizons from language input. Our hierarchical policy operates at multiple timescales, where the higher-level master policy proposes subgoals to be executed by specialized sub-policies. Our choice of subgoals is compositional and semantic, i.e. they can be sequentially combined in arbitrary orderings, and assume human-interpretable descriptions (e.g. 'exit room', 'find kitchen', 'find refrigerator', etc.). We use imitation learning to warm-start policies at each level of the hierarchy, dramatically increasing sample efficiency, followed by reinforcement learning. Independent reinforcement learning at each level of hierarchy enables sub-policies to adapt to consequences of their actions and recover from errors. Subsequent joint hierarchical training enables the master policy to adapt to the sub-policies.
End-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Jun 30, 2018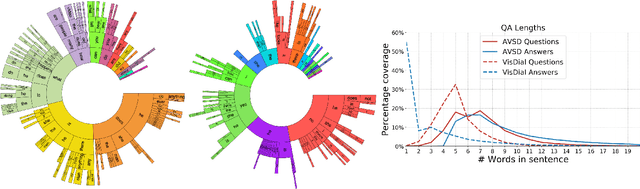
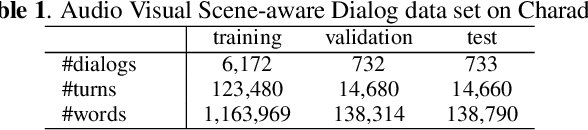
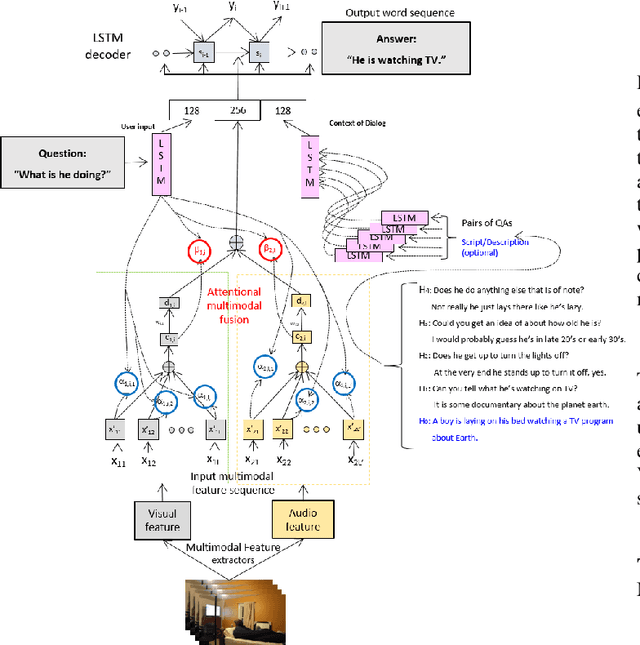
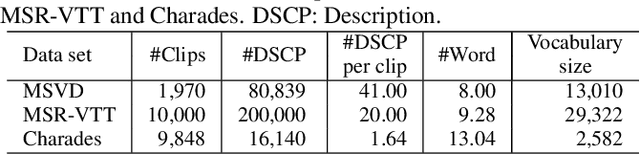
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.
Audio Visual Scene-Aware Dialog Challenge at DSTC7
Jun 01, 2018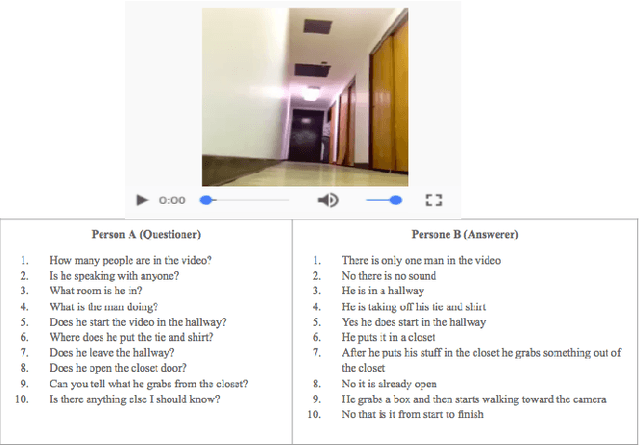
Scene-aware dialog systems will be able to have conversations with users about the objects and events around them. Progress on such systems can be made by integrating state-of-the-art technologies from multiple research areas including end-to-end dialog systems visual dialog, and video description. We introduce the Audio Visual Scene Aware Dialog (AVSD) challenge and dataset. In this challenge, which is one track of the 7th Dialog System Technology Challenges (DSTC7) workshop1, the task is to build a system that generates responses in a dialog about an input video
Embodied Question Answering
Dec 01, 2017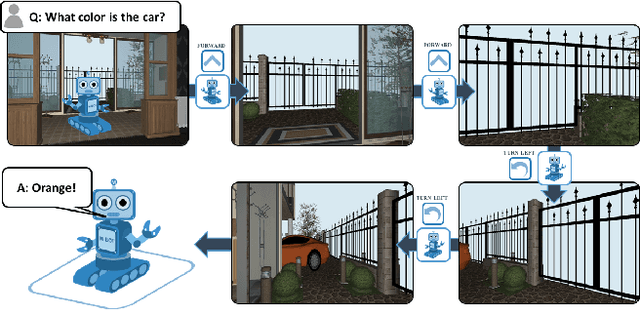
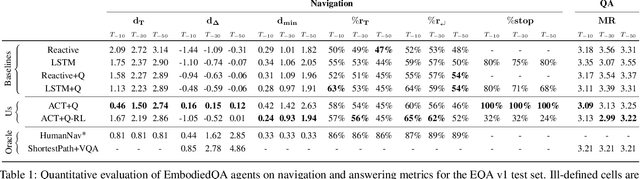


We present a new AI task -- Embodied Question Answering (EmbodiedQA) -- where an agent is spawned at a random location in a 3D environment and asked a question ("What color is the car?"). In order to answer, the agent must first intelligently navigate to explore the environment, gather information through first-person (egocentric) vision, and then answer the question ("orange"). This challenging task requires a range of AI skills -- active perception, language understanding, goal-driven navigation, commonsense reasoning, and grounding of language into actions. In this work, we develop the environments, end-to-end-trained reinforcement learning agents, and evaluation protocols for EmbodiedQA.
Evaluating Visual Conversational Agents via Cooperative Human-AI Games
Aug 17, 2017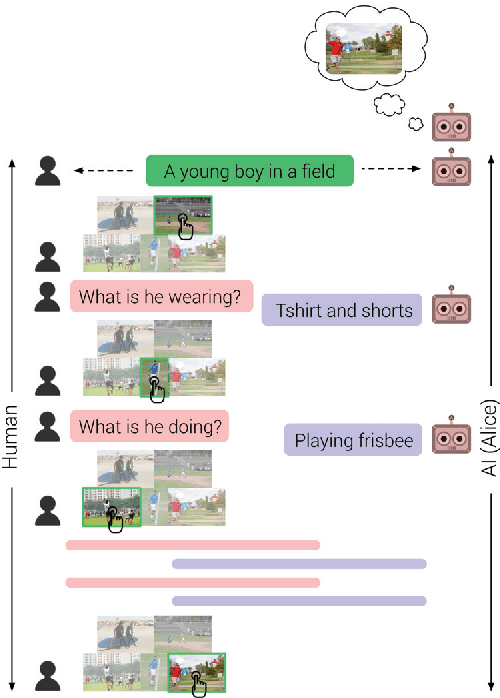


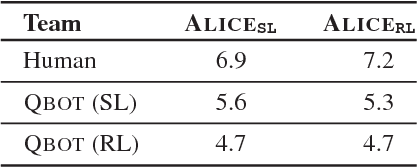
As AI continues to advance, human-AI teams are inevitable. However, progress in AI is routinely measured in isolation, without a human in the loop. It is crucial to benchmark progress in AI, not just in isolation, but also in terms of how it translates to helping humans perform certain tasks, i.e., the performance of human-AI teams. In this work, we design a cooperative game - GuessWhich - to measure human-AI team performance in the specific context of the AI being a visual conversational agent. GuessWhich involves live interaction between the human and the AI. The AI, which we call ALICE, is provided an image which is unseen by the human. Following a brief description of the image, the human questions ALICE about this secret image to identify it from a fixed pool of images. We measure performance of the human-ALICE team by the number of guesses it takes the human to correctly identify the secret image after a fixed number of dialog rounds with ALICE. We compare performance of the human-ALICE teams for two versions of ALICE. Our human studies suggest a counterintuitive trend - that while AI literature shows that one version outperforms the other when paired with an AI questioner bot, we find that this improvement in AI-AI performance does not translate to improved human-AI performance. This suggests a mismatch between benchmarking of AI in isolation and in the context of human-AI teams.
Visual Dialog
Aug 01, 2017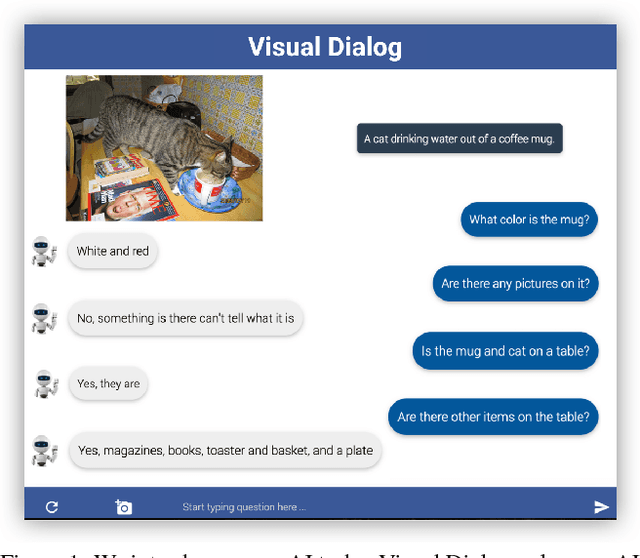
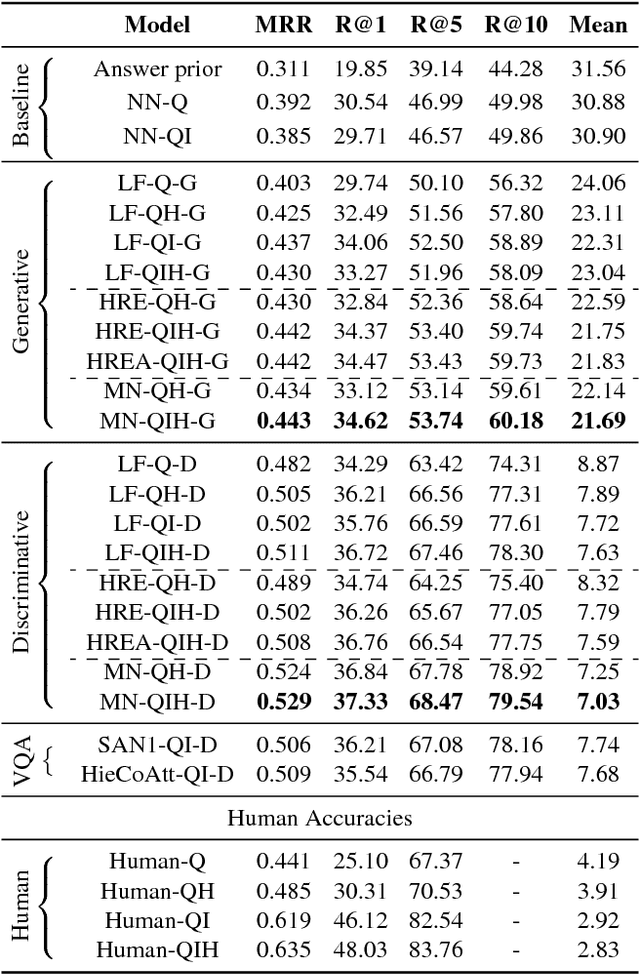


We introduce the task of Visual Dialog, which requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Specifically, given an image, a dialog history, and a question about the image, the agent has to ground the question in image, infer context from history, and answer the question accurately. Visual Dialog is disentangled enough from a specific downstream task so as to serve as a general test of machine intelligence, while being grounded in vision enough to allow objective evaluation of individual responses and benchmark progress. We develop a novel two-person chat data-collection protocol to curate a large-scale Visual Dialog dataset (VisDial). VisDial v0.9 has been released and contains 1 dialog with 10 question-answer pairs on ~120k images from COCO, with a total of ~1.2M dialog question-answer pairs. We introduce a family of neural encoder-decoder models for Visual Dialog with 3 encoders -- Late Fusion, Hierarchical Recurrent Encoder and Memory Network -- and 2 decoders (generative and discriminative), which outperform a number of sophisticated baselines. We propose a retrieval-based evaluation protocol for Visual Dialog where the AI agent is asked to sort a set of candidate answers and evaluated on metrics such as mean-reciprocal-rank of human response. We quantify gap between machine and human performance on the Visual Dialog task via human studies. Putting it all together, we demonstrate the first 'visual chatbot'! Our dataset, code, trained models and visual chatbot are available on https://visualdialog.org
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Mar 21, 2017
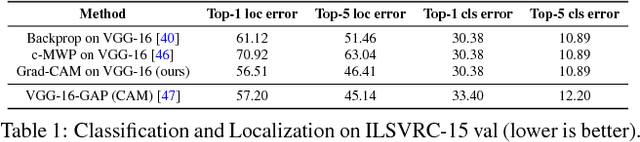
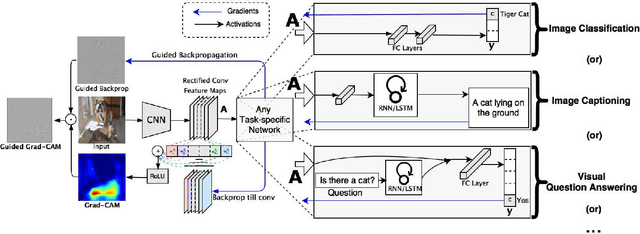
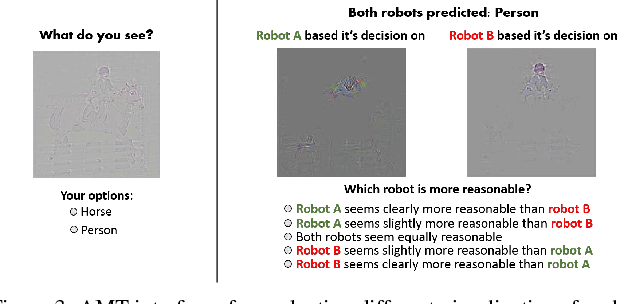
We propose a technique for producing "visual explanations" for decisions from a large class of CNN-based models, making them more transparent. Our approach - Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept, flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept. Unlike previous approaches, GradCAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers (e.g. VGG), (2) CNNs used for structured outputs (e.g. captioning), (3) CNNs used in tasks with multimodal inputs (e.g. VQA) or reinforcement learning, without any architectural changes or re-training. We combine GradCAM with fine-grained visualizations to create a high-resolution class-discriminative visualization and apply it to off-the-shelf image classification, captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into their failure modes (showing that seemingly unreasonable predictions have reasonable explanations), (b) are robust to adversarial images, (c) outperform previous methods on weakly-supervised localization, (d) are more faithful to the underlying model and (e) help achieve generalization by identifying dataset bias. For captioning and VQA, our visualizations show that even non-attention based models can localize inputs. Finally, we conduct human studies to measure if GradCAM explanations help users establish trust in predictions from deep networks and show that GradCAM helps untrained users successfully discern a "stronger" deep network from a "weaker" one. Our code is available at https://github.com/ramprs/grad-cam. A demo and a video of the demo can be found at http://gradcam.cloudcv.org and youtu.be/COjUB9Izk6E.
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
Mar 21, 2017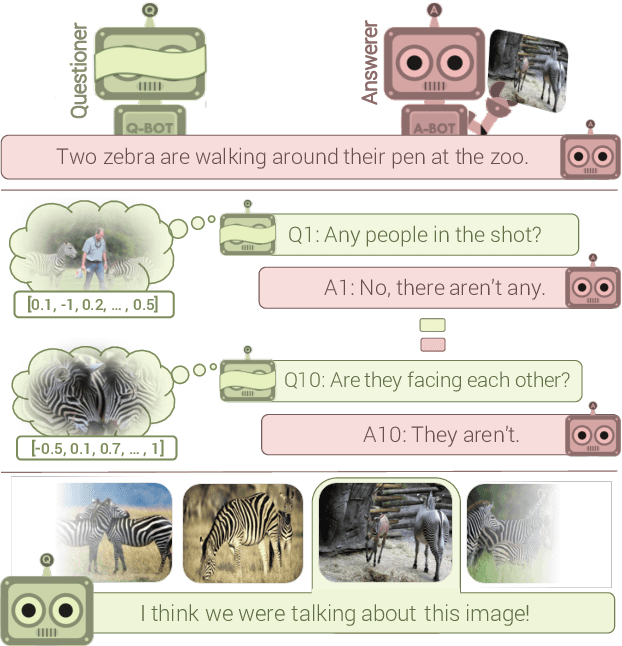
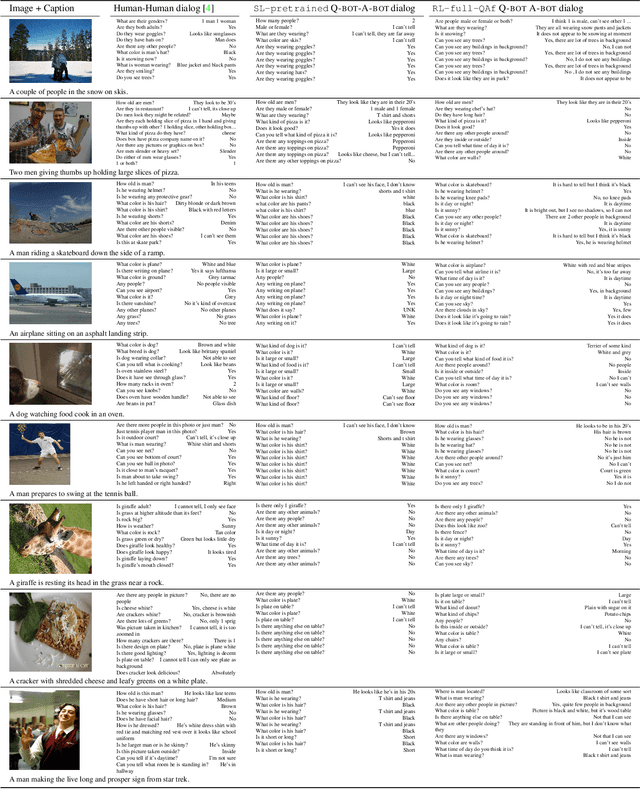
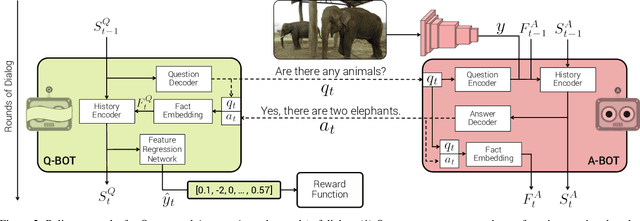

We introduce the first goal-driven training for visual question answering and dialog agents. Specifically, we pose a cooperative 'image guessing' game between two agents -- Qbot and Abot -- who communicate in natural language dialog so that Qbot can select an unseen image from a lineup of images. We use deep reinforcement learning (RL) to learn the policies of these agents end-to-end -- from pixels to multi-agent multi-round dialog to game reward. We demonstrate two experimental results. First, as a 'sanity check' demonstration of pure RL (from scratch), we show results on a synthetic world, where the agents communicate in ungrounded vocabulary, i.e., symbols with no pre-specified meanings (X, Y, Z). We find that two bots invent their own communication protocol and start using certain symbols to ask/answer about certain visual attributes (shape/color/style). Thus, we demonstrate the emergence of grounded language and communication among 'visual' dialog agents with no human supervision. Second, we conduct large-scale real-image experiments on the VisDial dataset, where we pretrain with supervised dialog data and show that the RL 'fine-tuned' agents significantly outperform SL agents. Interestingly, the RL Qbot learns to ask questions that Abot is good at, ultimately resulting in more informative dialog and a better team.