 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Graph Networks Generalize to Large and Diverse Molecular Systems?
Apr 06, 2022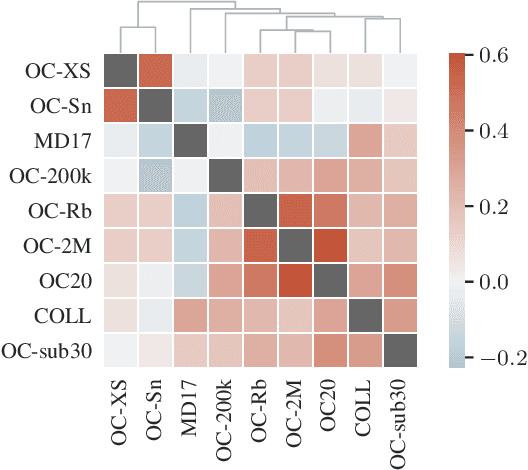
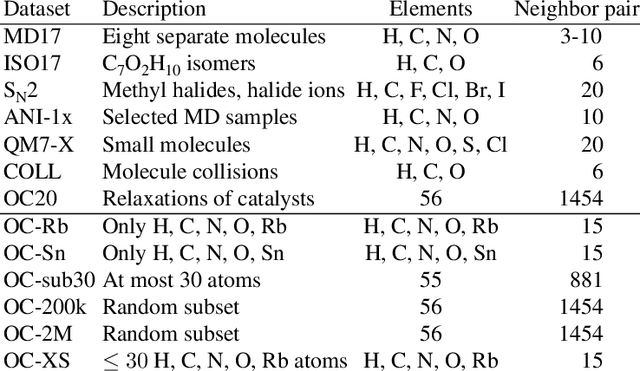
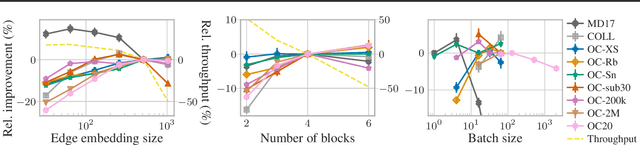
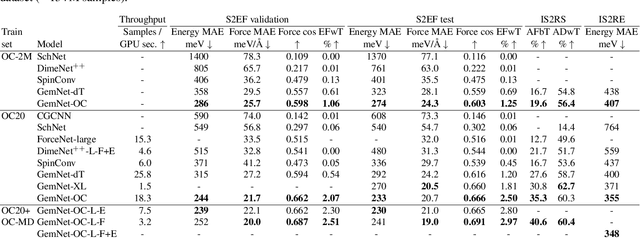
The predominant method of demonstrating progress of atomic graph neural networks are benchmarks on small and limited datasets. The implicit hypothesis behind this approach is that progress on these narrow datasets generalize to the large diversity of chemistry. This generalizability would be very helpful for research, but currently remains untested. In this work we test this assumption by identifying four aspects of complexity in which many datasets are lacking: 1. Chemical diversity (number of different elements), 2. system size (number of atoms per sample), 3. dataset size (number of data samples), and 4. domain shift (similarity of the training and test set). We introduce multiple subsets of the large Open Catalyst 2020 (OC20) dataset to independently investigate each of these aspects. We then perform 21 ablation studies and sensitivity analyses on 9 datasets testing both previously proposed and new model enhancements. We find that some improvements are consistent between datasets, but many are not and some even have opposite effects. Based on this analysis, we identify a smaller dataset that correlates well with the full OC20 dataset, and propose the GemNet-OC model, which outperforms the previous state-of-the-art on OC20 by 16%, while reducing training time by a factor of 10. Overall, our findings challenge the common belief that graph neural networks work equally well independent of dataset size and diversity, and suggest that caution must be exercised when making generalizations based on narrow datasets.
Towards Training Billion Parameter Graph Neural Networks for Atomic Simulations
Mar 18, 2022
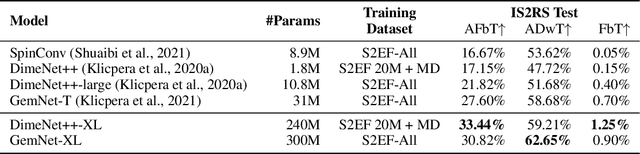
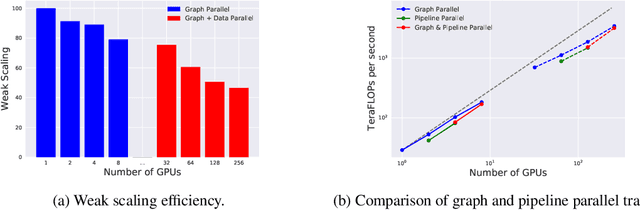
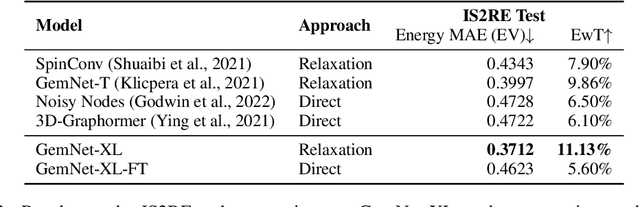
Recent progress in Graph Neural Networks (GNNs) for modeling atomic simulations has the potential to revolutionize catalyst discovery, which is a key step in making progress towards the energy breakthroughs needed to combat climate change. However, the GNNs that have proven most effective for this task are memory intensive as they model higher-order interactions in the graphs such as those between triplets or quadruplets of atoms, making it challenging to scale these models. In this paper, we introduce Graph Parallelism, a method to distribute input graphs across multiple GPUs, enabling us to train very large GNNs with hundreds of millions or billions of parameters. We empirically evaluate our method by scaling up the number of parameters of the recently proposed DimeNet++ and GemNet models by over an order of magnitude. On the large-scale Open Catalyst 2020 (OC20) dataset, these graph-parallelized models lead to relative improvements of 1) 15% on the force MAE metric for the S2EF task and 2) 21% on the AFbT metric for the IS2RS task, establishing new state-of-the-art results.
NarrationBot and InfoBot: A Hybrid System for Automated Video Description
Nov 07, 2021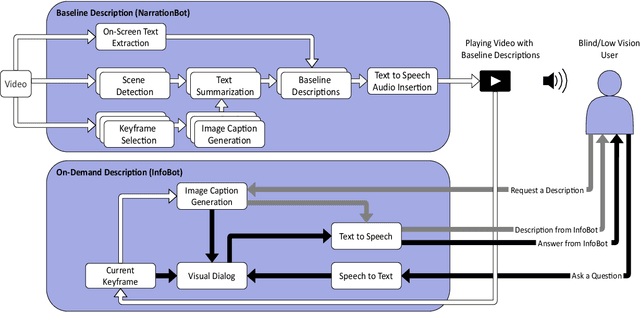
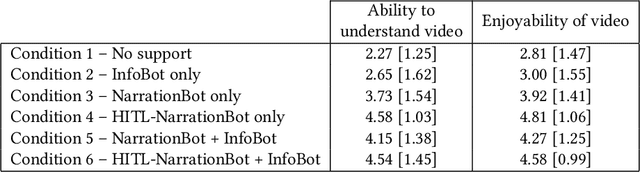


Video accessibility is crucial for blind and low vision users for equitable engagements in education, employment, and entertainment. Despite the availability of professional and amateur services and tools, most human-generated descriptions are expensive and time consuming. Moreover, the rate of human-generated descriptions cannot match the speed of video production. To overcome the increasing gaps in video accessibility, we developed a hybrid system of two tools to 1) automatically generate descriptions for videos and 2) provide answers or additional descriptions in response to user queries on a video. Results from a mixed-methods study with 26 blind and low vision individuals show that our system significantly improved user comprehension and enjoyment of selected videos when both tools were used in tandem. In addition, participants reported no significant difference in their ability to understand videos when presented with autogenerated descriptions versus human-revised autogenerated descriptions. Our results demonstrate user enthusiasm about the developed system and its promise for providing customized access to videos. We discuss the limitations of the current work and provide recommendations for the future development of automated video description tools.
Rotation Invariant Graph Neural Networks using Spin Convolutions
Jun 17, 2021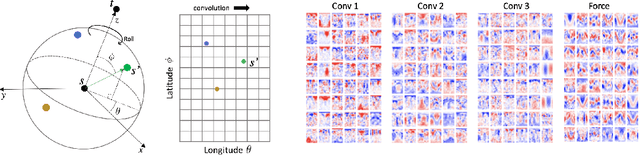
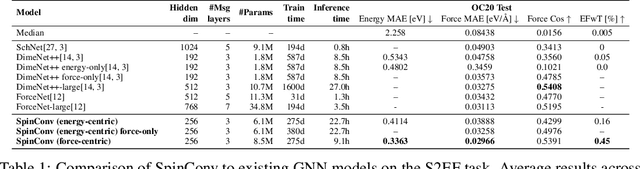
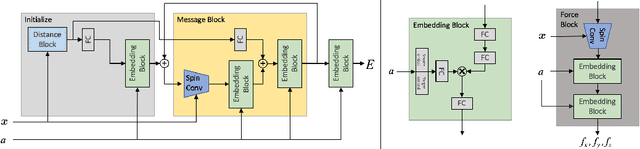
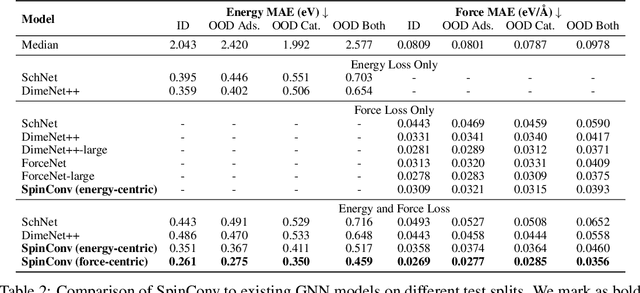
Progress towards the energy breakthroughs needed to combat climate change can be significantly accelerated through the efficient simulation of atomic systems. Simulation techniques based on first principles, such as Density Functional Theory (DFT), are limited in their practical use due to their high computational expense. Machine learning approaches have the potential to approximate DFT in a computationally efficient manner, which could dramatically increase the impact of computational simulations on real-world problems. Approximating DFT poses several challenges. These include accurately modeling the subtle changes in the relative positions and angles between atoms, and enforcing constraints such as rotation invariance or energy conservation. We introduce a novel approach to modeling angular information between sets of neighboring atoms in a graph neural network. Rotation invariance is achieved for the network's edge messages through the use of a per-edge local coordinate frame and a novel spin convolution over the remaining degree of freedom. Two model variants are proposed for the applications of structure relaxation and molecular dynamics. State-of-the-art results are demonstrated on the large-scale Open Catalyst 2020 dataset. Comparisons are also performed on the MD17 and QM9 datasets.
Auxiliary Tasks and Exploration Enable ObjectNav
Apr 08, 2021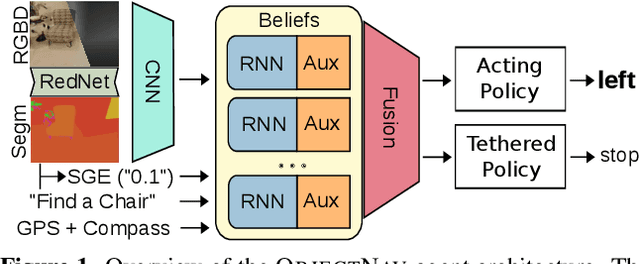
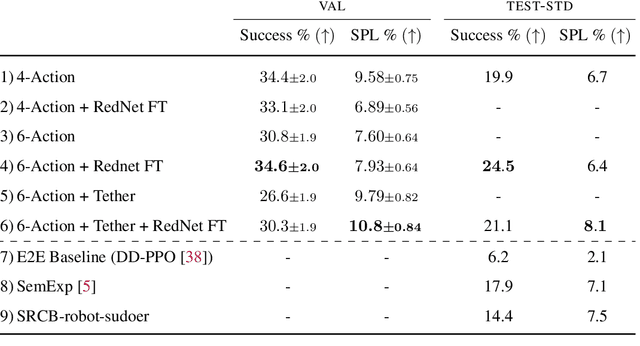
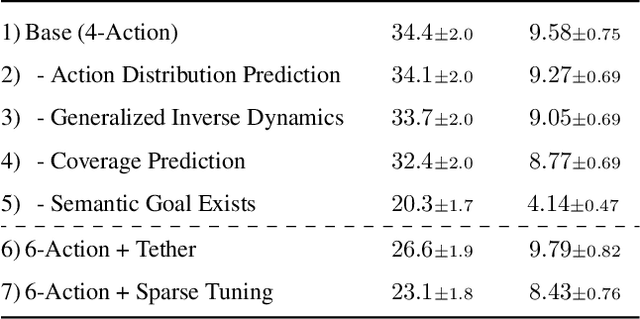
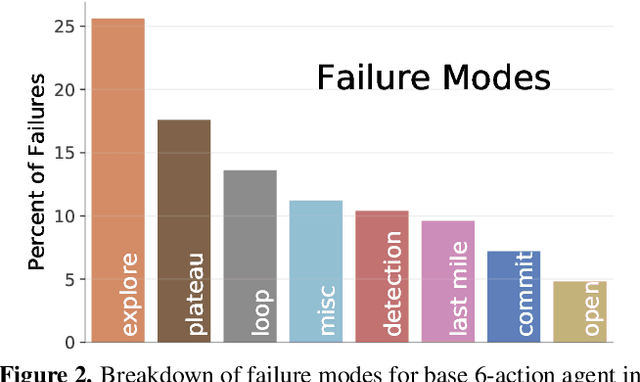
ObjectGoal Navigation (ObjectNav) is an embodied task wherein agents are to navigate to an object instance in an unseen environment. Prior works have shown that end-to-end ObjectNav agents that use vanilla visual and recurrent modules, e.g. a CNN+RNN, perform poorly due to overfitting and sample inefficiency. This has motivated current state-of-the-art methods to mix analytic and learned components and operate on explicit spatial maps of the environment. We instead re-enable a generic learned agent by adding auxiliary learning tasks and an exploration reward. Our agents achieve 24.5% success and 8.1% SPL, a 37% and 8% relative improvement over prior state-of-the-art, respectively, on the Habitat ObjectNav Challenge. From our analysis, we propose that agents will act to simplify their visual inputs so as to smooth their RNN dynamics, and that auxiliary tasks reduce overfitting by minimizing effective RNN dimensionality; i.e. a performant ObjectNav agent that must maintain coherent plans over long horizons does so by learning smooth, low-dimensional recurrent dynamics. Site: https://joel99.github.io/objectnav/
ForceNet: A Graph Neural Network for Large-Scale Quantum Calculations
Mar 02, 2021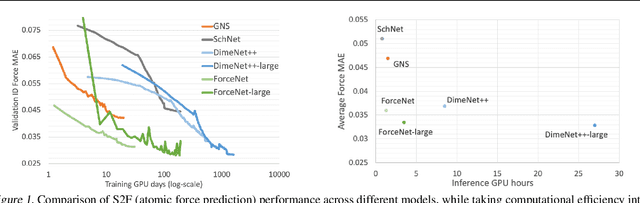
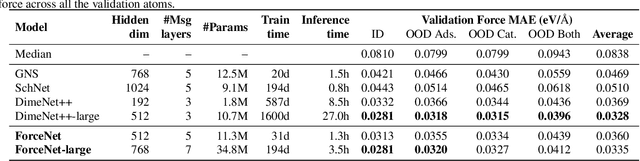

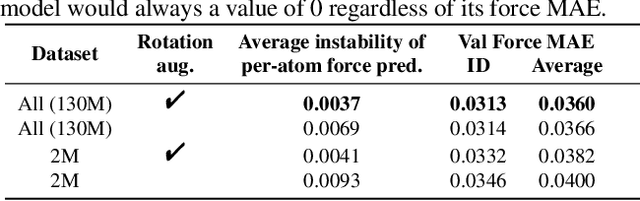
With massive amounts of atomic simulation data available, there is a huge opportunity to develop fast and accurate machine learning models to approximate expensive physics-based calculations. The key quantity to estimate is atomic forces, where the state-of-the-art Graph Neural Networks (GNNs) explicitly enforce basic physical constraints such as rotation-covariance. However, to strictly satisfy the physical constraints, existing models have to make tradeoffs between computational efficiency and model expressiveness. Here we explore an alternative approach. By not imposing explicit physical constraints, we can flexibly design expressive models while maintaining their computational efficiency. Physical constraints are implicitly imposed by training the models using physics-based data augmentation. To evaluate the approach, we carefully design a scalable and expressive GNN model, ForceNet, and apply it to OC20 (Chanussot et al., 2020), an unprecedentedly-large dataset of quantum physics calculations. Our proposed ForceNet is able to predict atomic forces more accurately than state-of-the-art physics-based GNNs while being faster both in training and inference. Overall, our promising and counter-intuitive results open up an exciting avenue for future research.
Rain Sensing Automatic Car Wiper Using AT89C51 Microcontroller
Jan 02, 2021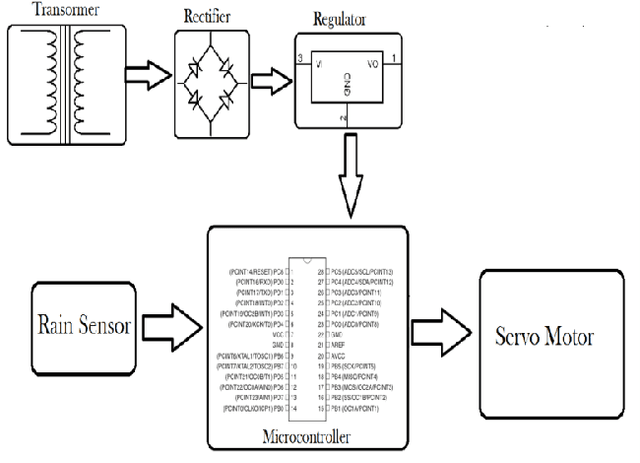

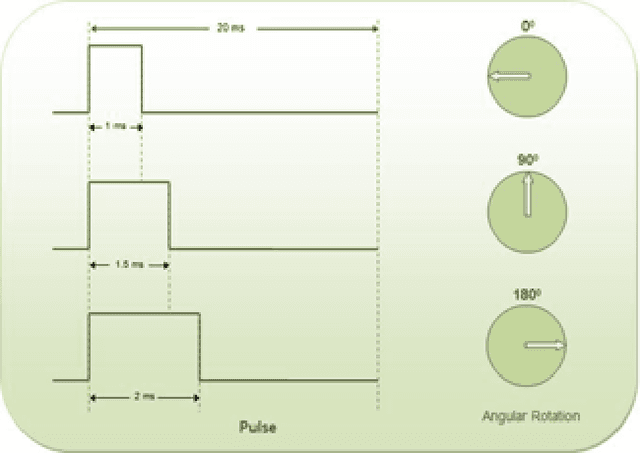
The turn of the century has seen a tremendous rise in technological advances in the field of automobiles. With 5G technology on its way and the development in the IoT sector, cars will start interacting with each other using V2V communications and become much more autonomous. In this project, an effort is made to move in the same direction by proposing a model for an automatic car wiper system that operates on sensing rain and snow on the windshield of a car. We develop a prototype for our idea by integrating a servo motor and raindrop sensor with an AT89C51 Microcontroller.
Multi-Image Steganography Using Deep Neural Networks
Jan 02, 2021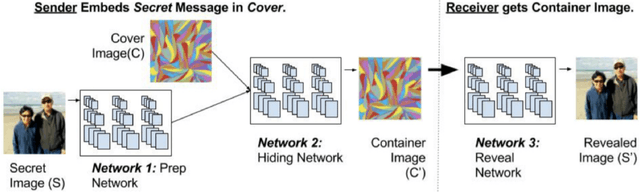
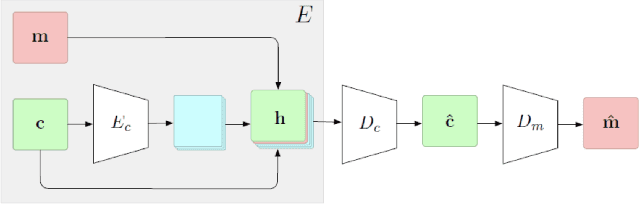

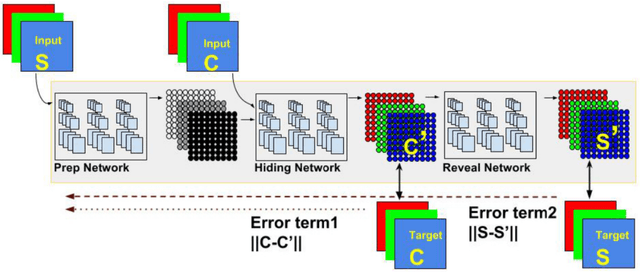
Steganography is the science of hiding a secret message within an ordinary public message. Over the years, steganography has been used to encode a lower resolution image into a higher resolution image by simple methods like LSB manipulation. We aim to utilize deep neural networks for the encoding and decoding of multiple secret images inside a single cover image of the same resolution.
Detecting Hate Speech in Multi-modal Memes
Dec 29, 2020

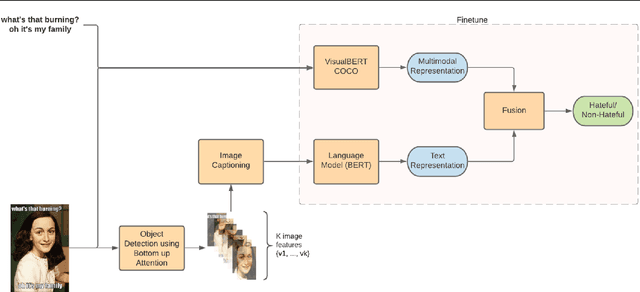
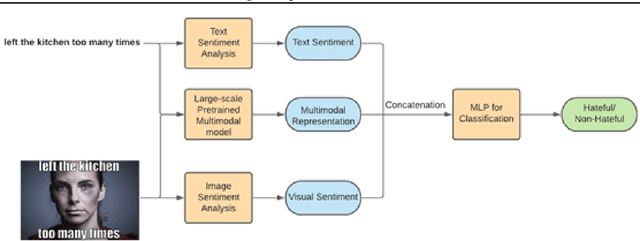
In the past few years, there has been a surge of interest in multi-modal problems, from image captioning to visual question answering and beyond. In this paper, we focus on hate speech detection in multi-modal memes wherein memes pose an interesting multi-modal fusion problem. We aim to solve the Facebook Meme Challenge \cite{kiela2020hateful} which aims to solve a binary classification problem of predicting whether a meme is hateful or not. A crucial characteristic of the challenge is that it includes "benign confounders" to counter the possibility of models exploiting unimodal priors. The challenge states that the state-of-the-art models perform poorly compared to humans. During the analysis of the dataset, we realized that majority of the data points which are originally hateful are turned into benign just be describing the image of the meme. Also, majority of the multi-modal baselines give more preference to the hate speech (language modality). To tackle these problems, we explore the visual modality using object detection and image captioning models to fetch the "actual caption" and then combine it with the multi-modal representation to perform binary classification. This approach tackles the benign text confounders present in the dataset to improve the performance. Another approach we experiment with is to improve the prediction with sentiment analysis. Instead of only using multi-modal representations obtained from pre-trained neural networks, we also include the unimodal sentiment to enrich the features. We perform a detailed analysis of the above two approaches, providing compelling reasons in favor of the methodologies used.
The Open Catalyst 2020 Dataset and Community Challenges
Oct 20, 2020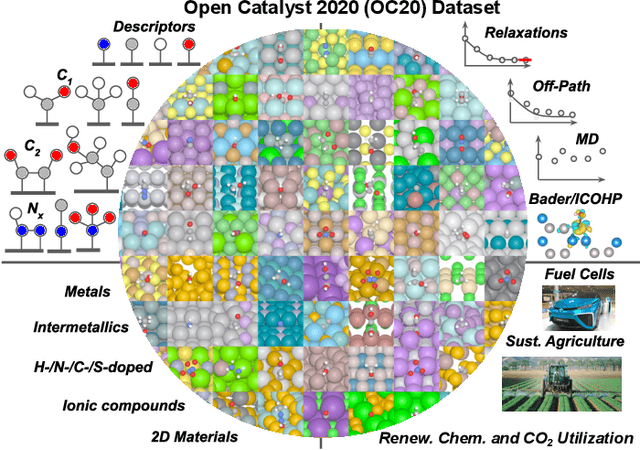

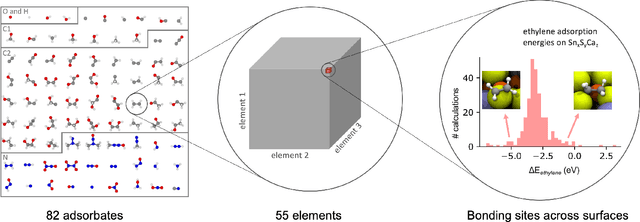
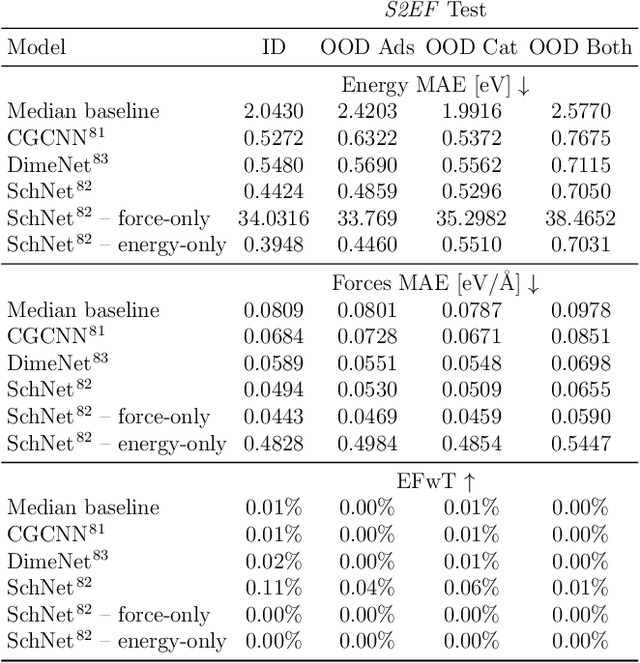
Catalyst discovery and optimization is key to solving many societal and energy challenges including solar fuels synthesis, long-term energy storage, and renewable fertilizer production. Despite considerable effort by the catalysis community to apply machine learning models to the computational catalyst discovery process, it remains an open challenge to build models that can generalize across both elemental compositions of surfaces and adsorbate identity/configurations, perhaps because datasets have been smaller in catalysis than related fields. To address this we developed the OC20 dataset, consisting of 1,281,121 Density Functional Theory (DFT) relaxations (264,900,500 single point evaluations) across a wide swath of materials, surfaces, and adsorbates (nitrogen, carbon, and oxygen chemistries). We supplemented this dataset with randomly perturbed structures, short timescale molecular dynamics, and electronic structure analyses. The dataset comprises three central tasks indicative of day-to-day catalyst modeling and comes with pre-defined train/validation/test splits to facilitate direct comparisons with future model development efforts. We applied three state-of-the-art graph neural network models (SchNet, Dimenet, CGCNN) to each of these tasks as baseline demonstrations for the community to build on. In almost every task, no upper limit on model size was identified, suggesting that even larger models are likely to improve on initial results. The dataset and baseline models are both provided as open resources, as well as a public leader board to encourage community contributions to solve these important tasks.