 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Videos in Space and Time
Jul 09, 2020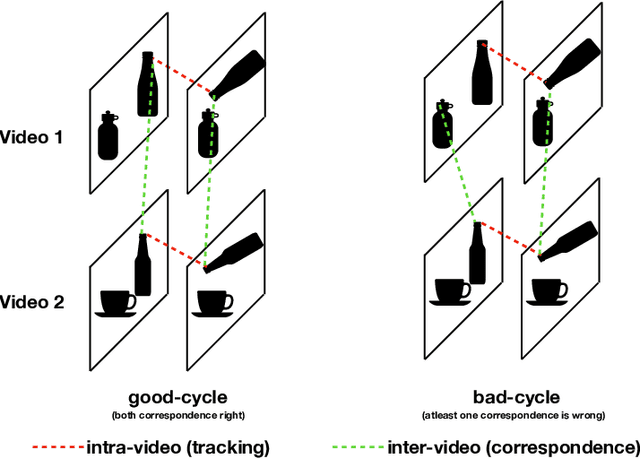

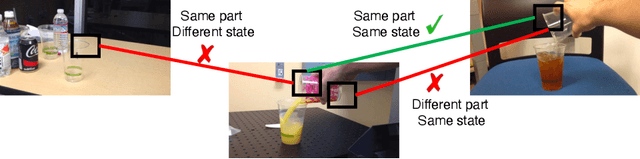

In this paper, we focus on the task of extracting visual correspondences across videos. Given a query video clip from an action class, we aim to align it with training videos in space and time. Obtaining training data for such a fine-grained alignment task is challenging and often ambiguous. Hence, we propose a novel alignment procedure that learns such correspondence in space and time via cross video cycle-consistency. During training, given a pair of videos, we compute cycles that connect patches in a given frame in the first video by matching through frames in the second video. Cycles that connect overlapping patches together are encouraged to score higher than cycles that connect non-overlapping patches. Our experiments on the Penn Action and Pouring datasets demonstrate that the proposed method can successfully learn to correspond semantically similar patches across videos, and learns representations that are sensitive to object and action states.
See, Hear, Explore: Curiosity via Audio-Visual Association
Jul 07, 2020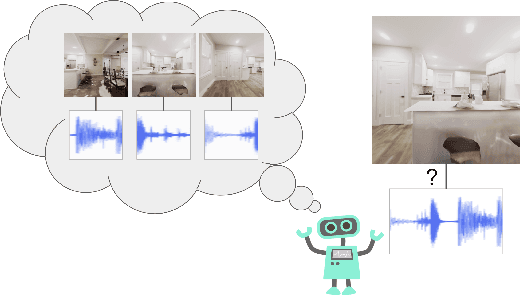
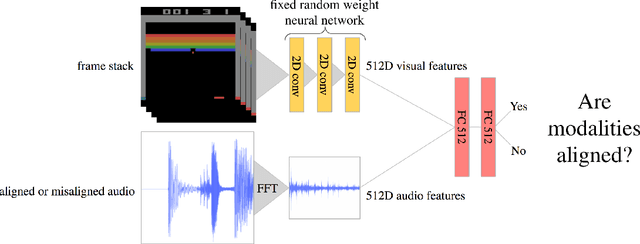
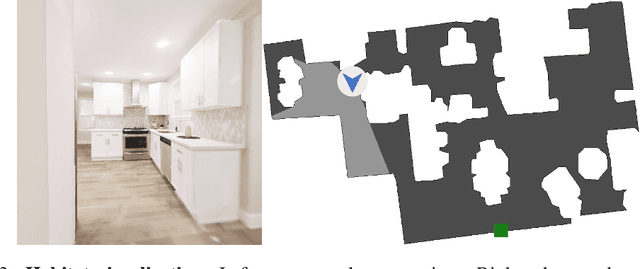
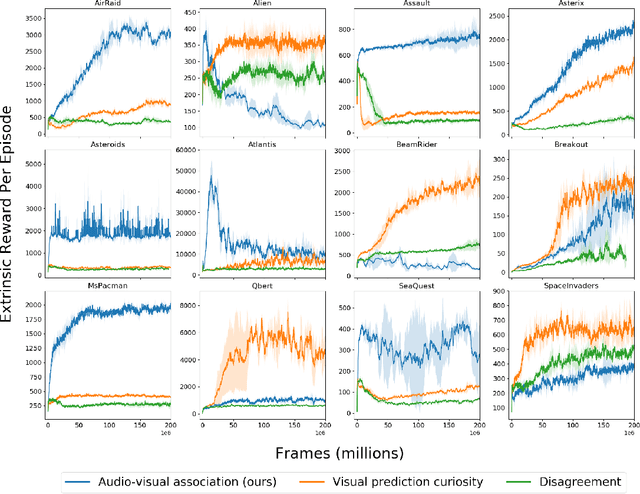
Exploration is one of the core challenges in reinforcement learning. A common formulation of curiosity-driven exploration uses the difference between the real future and the future predicted by a learned model. However, predicting the future is an inherently difficult task which can be ill-posed in the face of stochasticity. In this paper, we introduce an alternative form of curiosity that rewards novel associations between different senses. Our approach exploits multiple modalities to provide a stronger signal for more efficient exploration. Our method is inspired by the fact that, for humans, both sight and sound play a critical role in exploration. We present results on several Atari environments and Habitat (a photorealistic navigation simulator), showing the benefits of using an audio-visual association model for intrinsically guiding learning agents in the absence of external rewards. For videos and code, see https://vdean.github.io/audio-curiosity.html.
Swoosh! Rattle! Thump! -- Actions that Sound
Jul 03, 2020
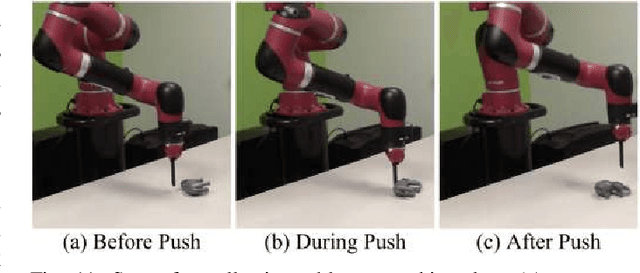


Truly intelligent agents need to capture the interplay of all their senses to build a rich physical understanding of their world. In robotics, we have seen tremendous progress in using visual and tactile perception; however, we have often ignored a key sense: sound. This is primarily due to the lack of data that captures the interplay of action and sound. In this work, we perform the first large-scale study of the interactions between sound and robotic action. To do this, we create the largest available sound-action-vision dataset with 15,000 interactions on 60 objects using our robotic platform Tilt-Bot. By tilting objects and allowing them to crash into the walls of a robotic tray, we collect rich four-channel audio information. Using this data, we explore the synergies between sound and action and present three key insights. First, sound is indicative of fine-grained object class information, e.g., sound can differentiate a metal screwdriver from a metal wrench. Second, sound also contains information about the causal effects of an action, i.e. given the sound produced, we can predict what action was applied to the object. Finally, object representations derived from audio embeddings are indicative of implicit physical properties. We demonstrate that on previously unseen objects, audio embeddings generated through interactions can predict forward models 24% better than passive visual embeddings. Project videos and data are at https://dhiraj100892.github.io/swoosh/
Object Goal Navigation using Goal-Oriented Semantic Exploration
Jul 02, 2020
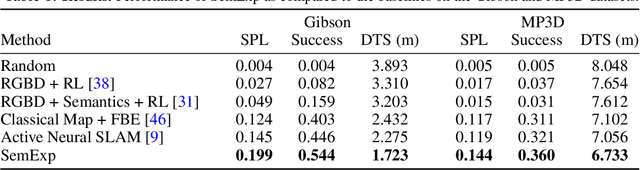
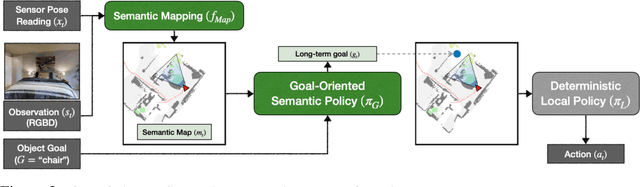

This work studies the problem of object goal navigation which involves navigating to an instance of the given object category in unseen environments. End-to-end learning-based navigation methods struggle at this task as they are ineffective at exploration and long-term planning. We propose a modular system called, `Goal-Oriented Semantic Exploration' which builds an episodic semantic map and uses it to explore the environment efficiently based on the goal object category. Empirical results in visually realistic simulation environments show that the proposed model outperforms a wide range of baselines including end-to-end learning-based methods as well as modular map-based methods and led to the winning entry of the CVPR-2020 Habitat ObjectNav Challenge. Ablation analysis indicates that the proposed model learns semantic priors of the relative arrangement of objects in a scene, and uses them to explore efficiently. Domain-agnostic module design allow us to transfer our model to a mobile robot platform and achieve similar performance for object goal navigation in the real-world.
Learning Robot Skills with Temporal Variational Inference
Jun 29, 2020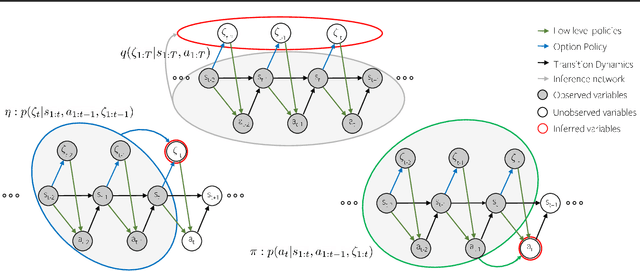
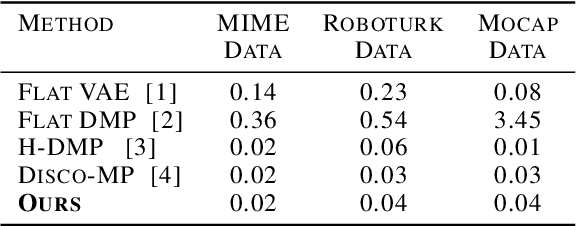
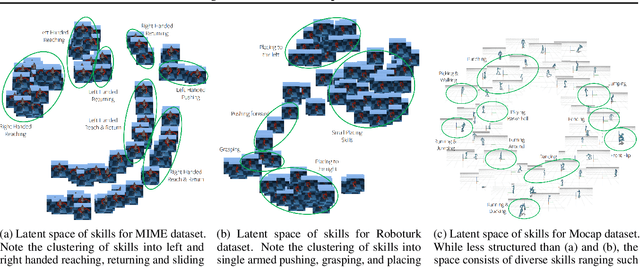

In this paper, we address the discovery of robotic options from demonstrations in an unsupervised manner. Specifically, we present a framework to jointly learn low-level control policies and higher-level policies of how to use them from demonstrations of a robot performing various tasks. By representing options as continuous latent variables, we frame the problem of learning these options as latent variable inference. We then present a temporal formulation of variational inference based on a temporal factorization of trajectory likelihoods,that allows us to infer options in an unsupervised manner. We demonstrate the ability of our framework to learn such options across three robotic demonstration datasets.
Empirically Verifying Hypotheses Using Reinforcement Learning
Jun 29, 2020
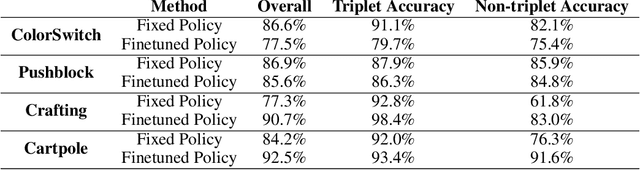
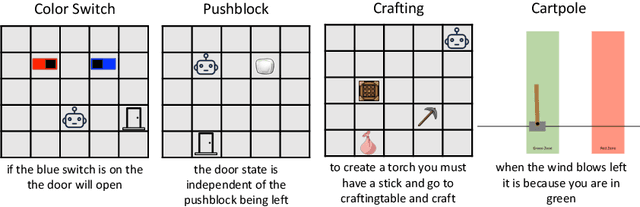
This paper formulates hypothesis verification as an RL problem. Specifically, we aim to build an agent that, given a hypothesis about the dynamics of the world, can take actions to generate observations which can help predict whether the hypothesis is true or false. Existing RL algorithms fail to solve this task, even for simple environments. In order to train the agents, we exploit the underlying structure of many hypotheses, factorizing them as {pre-condition, action sequence, post-condition} triplets. By leveraging this structure we show that RL agents are able to succeed at the task. Furthermore, subsequent fine-tuning of the policies allows the agent to correctly verify hypotheses not amenable to the above factorization.
Semantic Curiosity for Active Visual Learning
Jun 16, 2020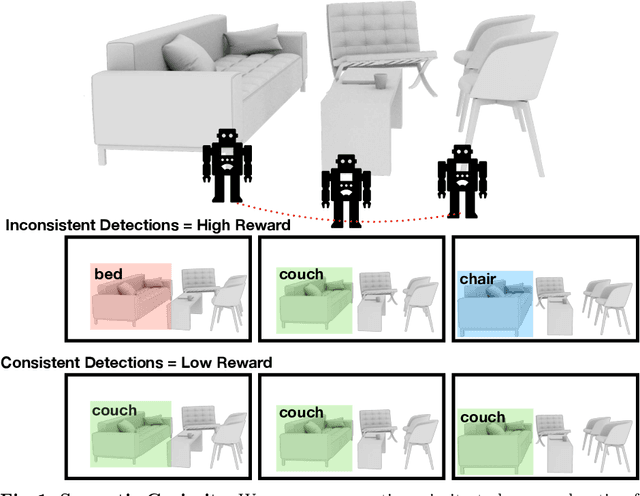

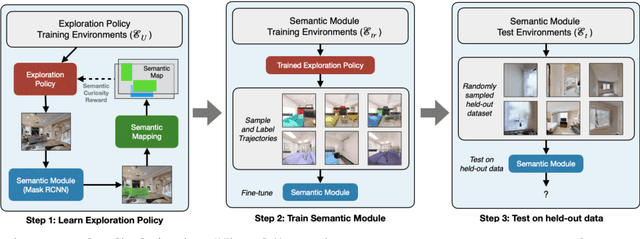
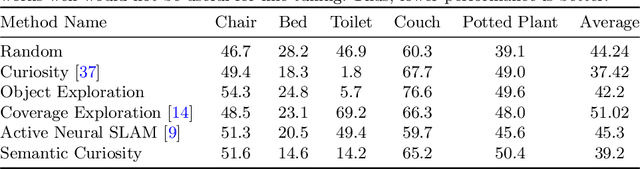
In this paper, we study the task of embodied interactive learning for object detection. Given a set of environments (and some labeling budget), our goal is to learn an object detector by having an agent select what data to obtain labels for. How should an exploration policy decide which trajectory should be labeled? One possibility is to use a trained object detector's failure cases as an external reward. However, this will require labeling millions of frames required for training RL policies, which is infeasible. Instead, we explore a self-supervised approach for training our exploration policy by introducing a notion of semantic curiosity. Our semantic curiosity policy is based on a simple observation -- the detection outputs should be consistent. Therefore, our semantic curiosity rewards trajectories with inconsistent labeling behavior and encourages the exploration policy to explore such areas. The exploration policy trained via semantic curiosity generalizes to novel scenes and helps train an object detector that outperforms baselines trained with other possible alternatives such as random exploration, prediction-error curiosity, and coverage-maximizing exploration.
Neural Topological SLAM for Visual Navigation
May 28, 2020
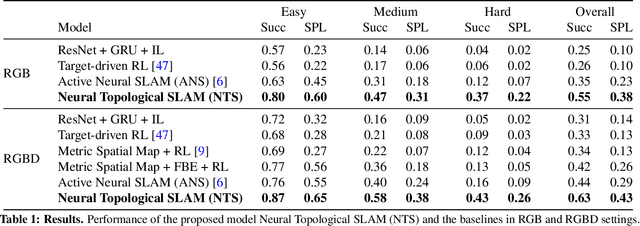

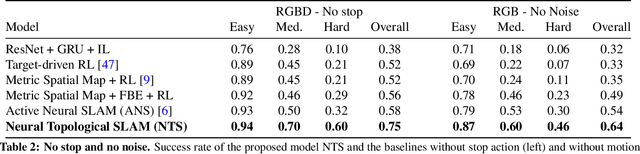
This paper studies the problem of image-goal navigation which involves navigating to the location indicated by a goal image in a novel previously unseen environment. To tackle this problem, we design topological representations for space that effectively leverage semantics and afford approximate geometric reasoning. At the heart of our representations are nodes with associated semantic features, that are interconnected using coarse geometric information. We describe supervised learning-based algorithms that can build, maintain and use such representations under noisy actuation. Experimental study in visually and physically realistic simulation suggests that our method builds effective representations that capture structural regularities and efficiently solve long-horizon navigation problems. We observe a relative improvement of more than 50% over existing methods that study this task.
Learning to Explore using Active Neural SLAM
Apr 10, 2020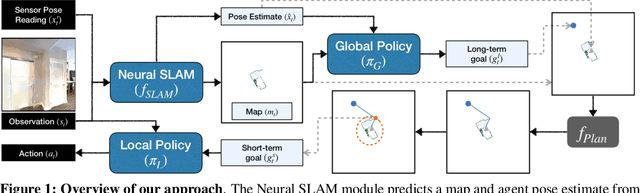
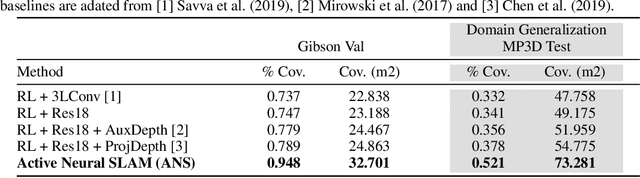
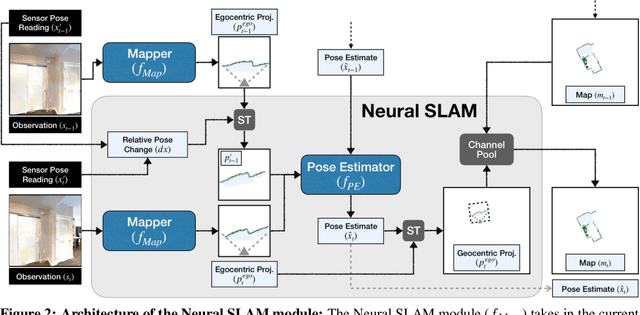
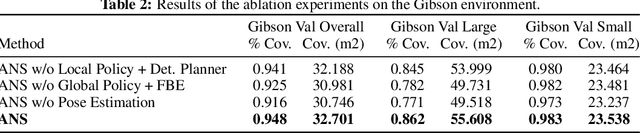
This work presents a modular and hierarchical approach to learn policies for exploring 3D environments, called `Active Neural SLAM'. Our approach leverages the strengths of both classical and learning-based methods, by using analytical path planners with learned SLAM module, and global and local policies. The use of learning provides flexibility with respect to input modalities (in the SLAM module), leverages structural regularities of the world (in global policies), and provides robustness to errors in state estimation (in local policies). Such use of learning within each module retains its benefits, while at the same time, hierarchical decomposition and modular training allow us to sidestep the high sample complexities associated with training end-to-end policies. Our experiments in visually and physically realistic simulated 3D environments demonstrate the effectiveness of our approach over past learning and geometry-based approaches. The proposed model can also be easily transferred to the PointGoal task and was the winning entry of the CVPR 2019 Habitat PointGoal Navigation Challenge.
Articulation-aware Canonical Surface Mapping
Apr 02, 2020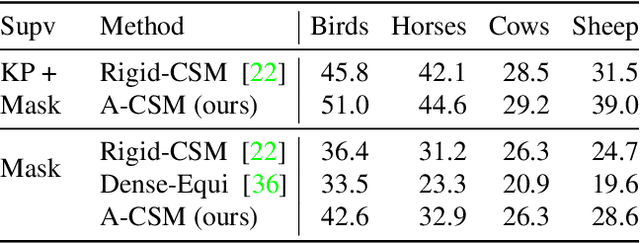
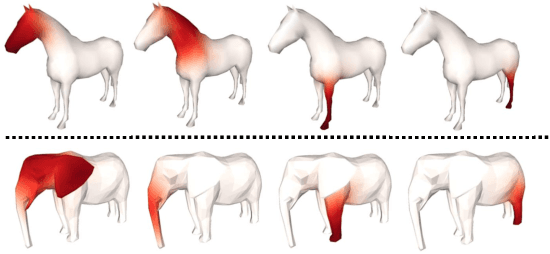
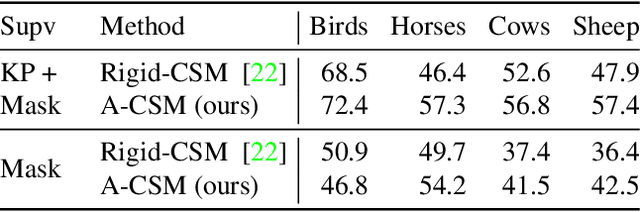
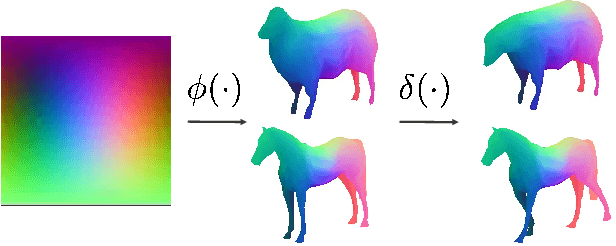
We tackle the tasks of: 1) predicting a Canonical Surface Mapping (CSM) that indicates the mapping from 2D pixels to corresponding points on a canonical template shape, and 2) inferring the articulation and pose of the template corresponding to the input image. While previous approaches rely on keypoint supervision for learning, we present an approach that can learn without such annotations. Our key insight is that these tasks are geometrically related, and we can obtain supervisory signal via enforcing consistency among the predictions. We present results across a diverse set of animal object categories, showing that our method can learn articulation and CSM prediction from image collections using only foreground mask labels for training. We empirically show that allowing articulation helps learn more accurate CSM prediction, and that enforcing the consistency with predicted CSM is similarly critical for learning meaningful articulation.