 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychological stress during Examination and its estimation by handwriting in answer script
Nov 08, 2025This research explores the fusion of graphology and artificial intelligence to quantify psychological stress levels in students by analyzing their handwritten examination scripts. By leveraging Optical Character Recognition and transformer based sentiment analysis models, we present a data driven approach that transcends traditional grading systems, offering deeper insights into cognitive and emotional states during examinations. The system integrates high resolution image processing, TrOCR, and sentiment entropy fusion using RoBERTa based models to generate a numerical Stress Index. Our method achieves robustness through a five model voting mechanism and unsupervised anomaly detection, making it an innovative framework in academic forensics.
Developing Visual Augmented Q&A System using Scalable Vision Embedding Retrieval & Late Interaction Re-ranker
Jul 16, 2025Traditional information extraction systems face challenges with text only language models as it does not consider infographics (visual elements of information) such as tables, charts, images etc. often used to convey complex information to readers. Multimodal LLM (MLLM) face challenges of finding needle in the haystack problem i.e., either longer context length or substantial number of documents as search space. Late interaction mechanism over visual language models has shown state of the art performance in retrieval-based vision augmented Q&A tasks. There are yet few challenges using it for RAG based multi-modal Q&A. Firstly, many popular and widely adopted vector databases do not support native multi-vector retrieval. Secondly, late interaction requires computation which inflates space footprint and can hinder enterprise adoption. Lastly, the current state of late interaction mechanism does not leverage the approximate neighbor search indexing methods for large speed ups in retrieval process. This paper explores a pragmatic approach to make vision retrieval process scalable and efficient without compromising on performance quality. We propose multi-step custom implementation utilizing widely adopted hybrid search (metadata & embedding) and state of the art late interaction re-ranker to retrieve best matching pages. Finally, MLLM are prompted as reader to generate answers from contextualized best matching pages. Through experiments, we observe that the proposed design is scalable (significant speed up) and stable (without degrading performance quality), hence can be used as production systems at enterprises.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Leveraging Retrieval Augmented Generative LLMs For Automated Metadata Description Generation to Enhance Data Catalogs
Mar 12, 2025



Data catalogs serve as repositories for organizing and accessing diverse collection of data assets, but their effectiveness hinges on the ease with which business users can look-up relevant content. Unfortunately, many data catalogs within organizations suffer from limited searchability due to inadequate metadata like asset descriptions. Hence, there is a need of content generation solution to enrich and curate metadata in a scalable way. This paper explores the challenges associated with metadata creation and proposes a unique prompt enrichment idea of leveraging existing metadata content using retrieval based few-shot technique tied with generative large language models (LLM). The literature also considers finetuning an LLM on existing content and studies the behavior of few-shot pretrained LLM (Llama, GPT3.5) vis-\`a-vis few-shot finetuned LLM (Llama2-7b) by evaluating their performance based on accuracy, factual grounding, and toxicity. Our preliminary results exhibit more than 80% Rouge-1 F1 for the generated content. This implied 87%- 88% of instances accepted as is or curated with minor edits by data stewards. By automatically generating descriptions for tables and columns in most accurate way, the research attempts to provide an overall framework for enterprises to effectively scale metadata curation and enrich its data catalog thereby vastly improving the data catalog searchability and overall usability.
Massimo: Public Queue Monitoring and Management using Mass-Spring Model
Oct 21, 2024An efficient system of a queue control and regulation in public spaces is very important in order to avoid the traffic jams and to improve the customer satisfaction. This article offers a detailed road map based on a merger of intelligent systems and creating an efficient systems of queues in public places. Through the utilization of different technologies i.e. computer vision, machine learning algorithms, deep learning our system provide accurate information about the place is crowded or not and the necessary efforts to be taken.
Measuring Sustainability Intention of ESG Fund Disclosure using Few-Shot Learning
Jul 09, 2024



Global sustainable fund universe encompasses open-end funds and exchange-traded funds (ETF) that, by prospectus or other regulatory filings, claim to focus on Environment, Social and Governance (ESG). Challengingly, the claims can only be confirmed by examining the textual disclosures to check if there is presence of intentionality and ESG focus on its investment strategy. Currently, there is no regulation to enforce sustainability in ESG products space. This paper proposes a unique method and system to classify and score the fund prospectuses in the sustainable universe regarding specificity and transparency of language. We aim to employ few-shot learners to identify specific, ambiguous, and generic sustainable investment-related language. Additionally, we construct a ratio metric to determine language score and rating to rank products and quantify sustainability claims for US sustainable universe. As a by-product, we publish manually annotated quality training dataset on Hugging Face (ESG-Prospectus-Clarity-Category under cc-by-nc-sa-4.0) of more than 1K ESG textual statements. The performance of the few-shot finetuning approach is compared with zero-shot models e.g., Llama-13B, GPT 3.5 Turbo etc. We found that prompting large language models are not accurate for domain specific tasks due to misalignment issues. The few-shot finetuning techniques outperform zero-shot models by large margins of more than absolute ~30% in precision, recall and F1 metrics on completely unseen ESG languages (test set). Overall, the paper attempts to establish a systematic and scalable approach to measure and rate sustainability intention quantitatively for sustainable funds using texts in prospectus. Regulatory bodies, investors, and advisors may utilize the findings of this research to reduce cognitive load in investigating or screening of ESG funds which accurately reflects the ESG intention.
Comparative Study of Language Models on Cross-Domain Data with Model Agnostic Explainability
Sep 09, 2020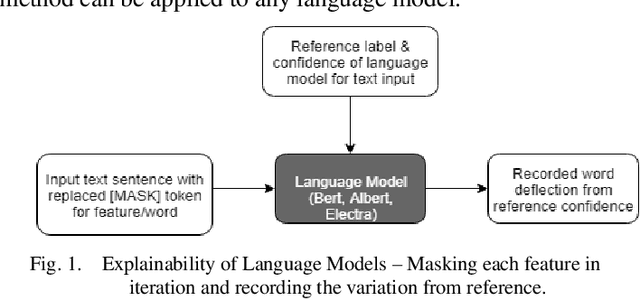
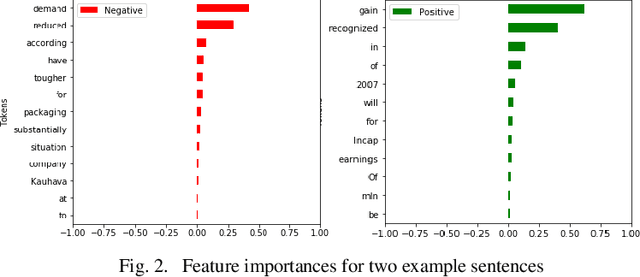
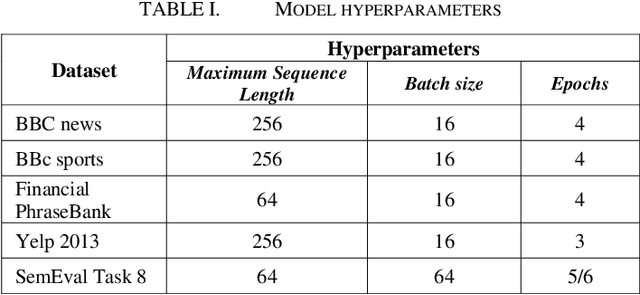
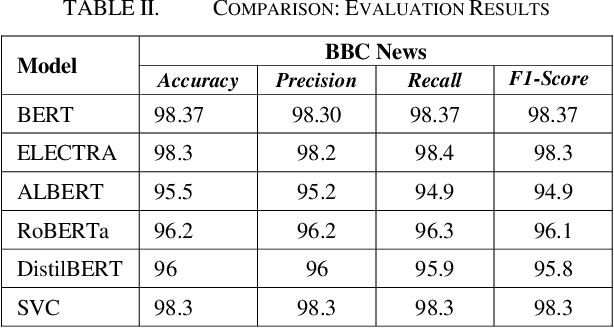
With the recent influx of bidirectional contextualized transformer language models in the NLP, it becomes a necessity to have a systematic comparative study of these models on variety of datasets. Also, the performance of these language models has not been explored on non-GLUE datasets. The study presented in paper compares the state-of-the-art language models - BERT, ELECTRA and its derivatives which include RoBERTa, ALBERT and DistilBERT. We conducted experiments by finetuning these models for cross domain and disparate data and penned an in-depth analysis of model's performances. Moreover, an explainability of language models coherent with pretraining is presented which verifies the context capturing capabilities of these models through a model agnostic approach. The experimental results establish new state-of-the-art for Yelp 2013 rating classification task and Financial Phrasebank sentiment detection task with 69% accuracy and 88.2% accuracy respectively. Finally, the study conferred here can greatly assist industry researchers in choosing the language model effectively in terms of performance or compute efficiency.
SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On
Jan 17, 2020
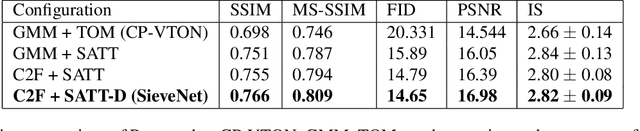
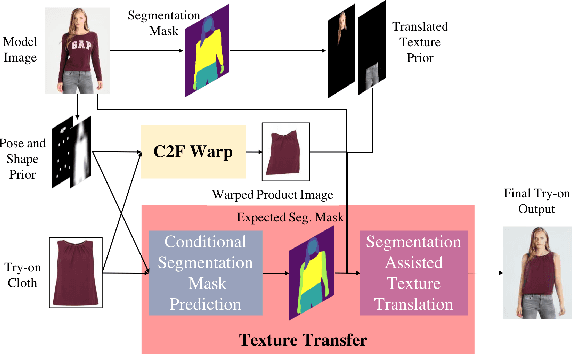
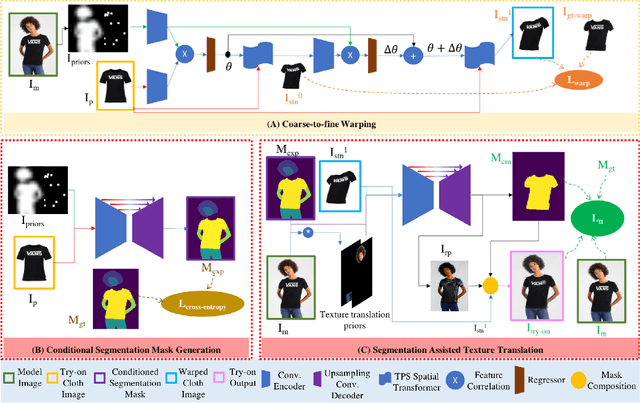
Image-based virtual try-on for fashion has gained considerable attention recently. The task requires trying on a clothing item on a target model image. An efficient framework for this is composed of two stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer module to seamlessly integrate the warped try-on cloth onto the target model image. Existing methods suffer from artifacts and distortions in their try-on output. In this work, we present SieveNet, a framework for robust image-based virtual try-on. Firstly, we introduce a multi-stage coarse-to-fine warping network to better model fine-grained intricacies (while transforming the try-on cloth) and train it with a novel perceptual geometric matching loss. Next, we introduce a try-on cloth conditioned segmentation mask prior to improve the texture transfer network. Finally, we also introduce a dueling triplet loss strategy for training the texture translation network which further improves the quality of the generated try-on results. We present extensive qualitative and quantitative evaluations of each component of the proposed pipeline and show significant performance improvements against the current state-of-the-art method.