 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdered Neurons: Integrating Tree Structures into Recurrent Neural Networks
Oct 22, 2018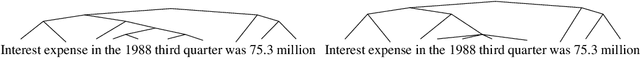
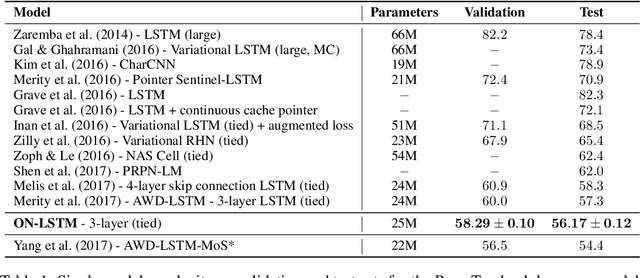
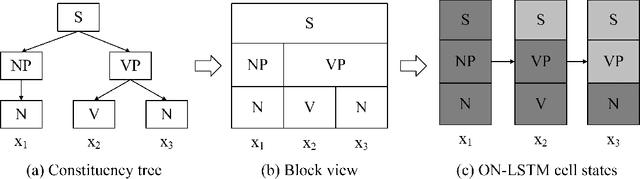
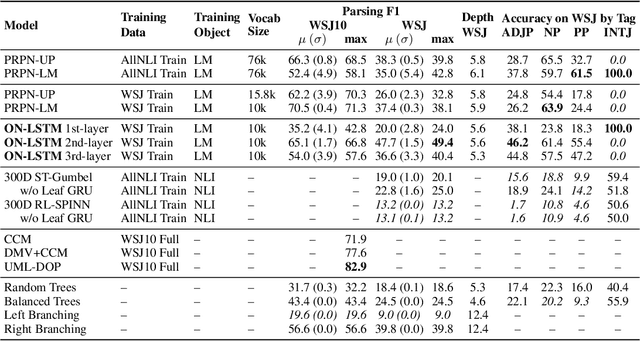
Recurrent neural network (RNN) models are widely used for processing sequential data governed by a latent tree structure. Previous work shows that RNN models (especially Long Short-Term Memory (LSTM) based models) could learn to exploit the underlying tree structure. However, its performance consistently lags behind that of tree-based models. This work proposes a new inductive bias Ordered Neurons, which enforces an order of updating frequencies between hidden state neurons. We show that the ordered neurons could explicitly integrate the latent tree structure into recurrent models. To this end, we propose a new RNN unit: ON-LSTM, which achieve good performances on four different tasks: language modeling, unsupervised parsing, targeted syntactic evaluation, and logical inference.
On the Spectral Bias of Neural Networks
Oct 17, 2018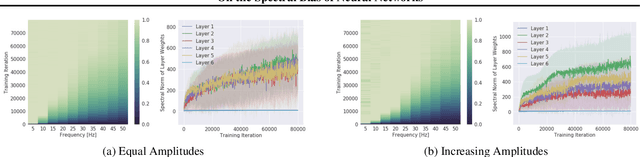
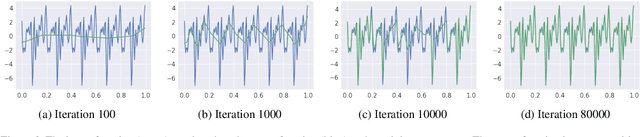
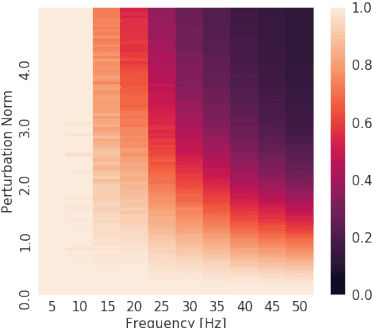
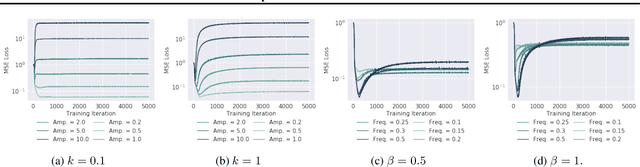
Neural networks are known to be a class of highly expressive functions able to fit even random input-output mappings with $100\%$ accuracy. In this work, we present properties of neural networks that complement this aspect of expressivity. By using tools from Fourier analysis, we show that deep ReLU networks are biased towards low frequency functions, meaning that they cannot have local fluctuations without affecting their global behavior. Intuitively, this property is in line with the observation that over-parameterized networks find simple patterns that generalize across data samples. We also investigate how the shape of the data manifold affects expressivity by showing evidence that learning high frequencies gets \emph{easier} with increasing manifold complexity, and present a theoretical understanding of this behavior. Finally, we study the robustness of the frequency components with respect to parameter perturbation, to develop the intuition that the parameters must be finely tuned to express high frequency functions.
Visual Reasoning with Multi-hop Feature Modulation
Oct 12, 2018
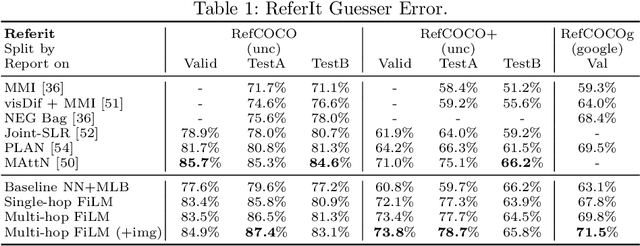
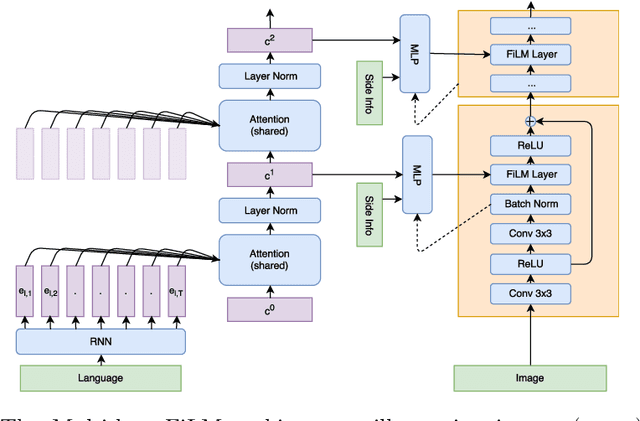
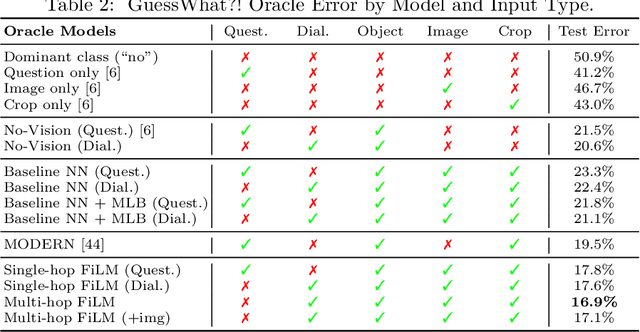
Recent breakthroughs in computer vision and natural language processing have spurred interest in challenging multi-modal tasks such as visual question-answering and visual dialogue. For such tasks, one successful approach is to condition image-based convolutional network computation on language via Feature-wise Linear Modulation (FiLM) layers, i.e., per-channel scaling and shifting. We propose to generate the parameters of FiLM layers going up the hierarchy of a convolutional network in a multi-hop fashion rather than all at once, as in prior work. By alternating between attending to the language input and generating FiLM layer parameters, this approach is better able to scale to settings with longer input sequences such as dialogue. We demonstrate that multi-hop FiLM generation achieves state-of-the-art for the short input sequence task ReferIt --- on-par with single-hop FiLM generation --- while also significantly outperforming prior state-of-the-art and single-hop FiLM generation on the GuessWhat?! visual dialogue task.
Manifold Mixup: Learning Better Representations by Interpolating Hidden States
Oct 04, 2018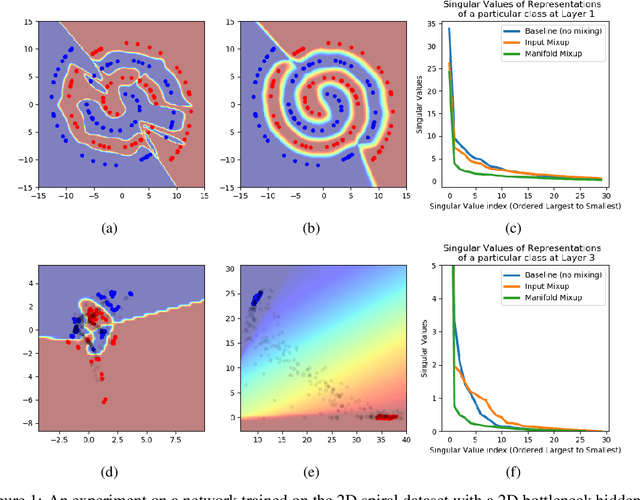
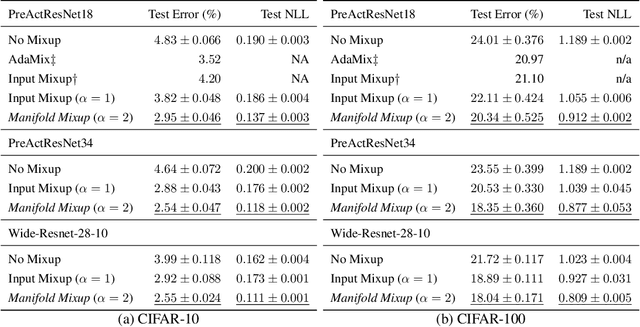
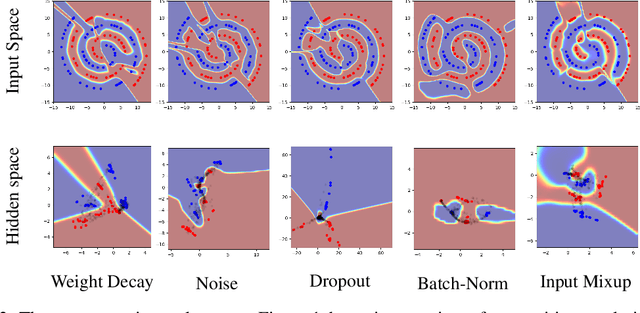
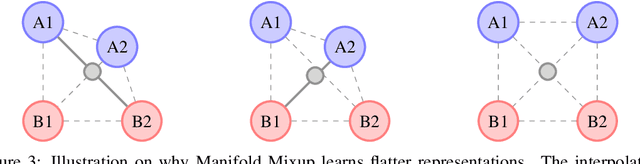
Deep networks often perform well on the data distribution on which they are trained, yet give incorrect (and often very confident) answers when evaluated on points from off of the training distribution. This is exemplified by the adversarial examples phenomenon but can also be seen in terms of model generalization and domain shift. Ideally, a model would assign lower confidence to points unlike those from the training distribution. We propose a regularizer which addresses this issue by training with interpolated hidden states and encouraging the classifier to be less confident at these points. Because the hidden states are learned, this has an important effect of encouraging the hidden states for a class to be concentrated in such a way so that interpolations within the same class or between two different classes do not intersect with the real data points from other classes. This has a major advantage in that it avoids the underfitting which can result from interpolating in the input space. We prove that the exact condition for this problem of underfitting to be avoided by Manifold Mixup is that the dimensionality of the hidden states exceeds the number of classes, which is often the case in practice. Additionally, this concentration can be seen as making the features in earlier layers more discriminative. We show that despite requiring no significant additional computation, Manifold Mixup achieves large improvements over strong baselines in supervised learning, robustness to single-step adversarial attacks, semi-supervised learning, and Negative Log-Likelihood on held out samples.
On the Learning Dynamics of Deep Neural Networks
Sep 18, 2018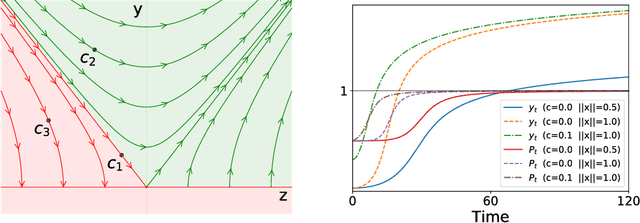
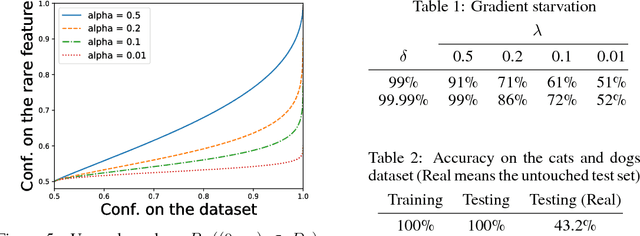
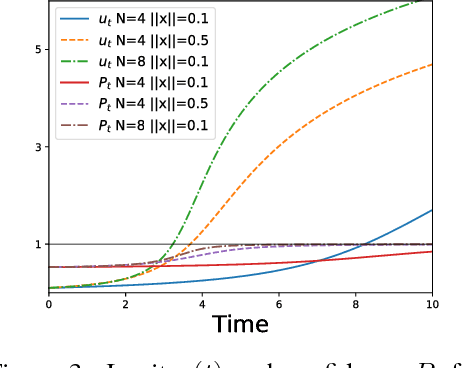
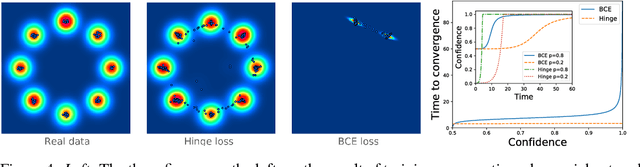
While a lot of progress has been made in recent years, the dynamics of learning in deep nonlinear neural networks remain to this day largely misunderstood. In this work, we study the case of binary classification and prove various properties of learning in such networks under strong assumptions such as linear separability of the data. Extending existing results from the linear case, we confirm empirical observations by proving that the classification error also follows a sigmoidal shape in nonlinear architectures. We show that given proper initialization, learning expounds parallel independent modes and that certain regions of parameter space might lead to failed training. We also demonstrate that input norm and features' frequency in the dataset lead to distinct convergence speeds which might shed some light on the generalization capabilities of deep neural networks. We provide a comparison between the dynamics of learning with cross-entropy and hinge losses, which could prove useful to understand recent progress in the training of generative adversarial networks. Finally, we identify a phenomenon that we baptize gradient starvation where the most frequent features in a dataset prevent the learning of other less frequent but equally informative features.
Approximate Exploration through State Abstraction
Aug 29, 2018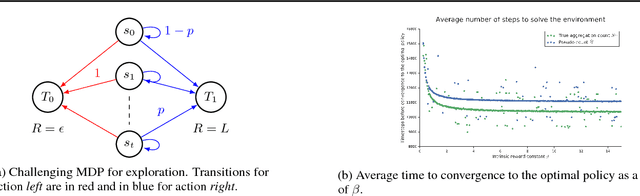

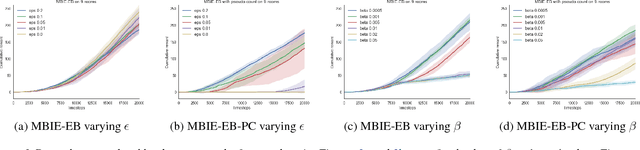
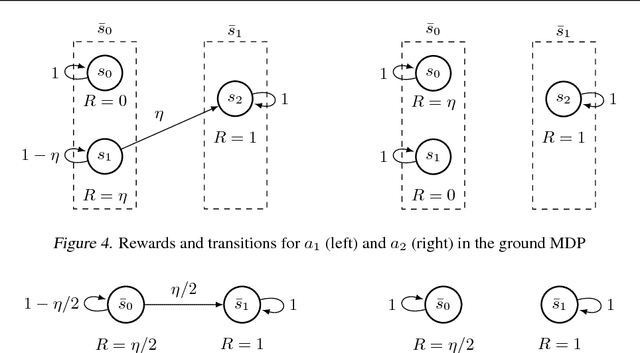
Although exploration in reinforcement learning is well understood from a theoretical point of view, provably correct methods remain impractical. In this paper we study the interplay between exploration and approximation, what we call \emph{approximate exploration}. We first provide results when the approximation is explicit, quantifying the performance of an exploration algorithm, MBIE-EB \citep{strehl2008analysis}, when combined with state aggregation. In particular, we show that this allows the agent to trade off between learning speed and quality of the policy learned. We then turn to a successful exploration scheme in practical, pseudo-count based exploration bonuses \citep{bellemare2016unifying}. We show that choosing a density model implicitly defines an abstraction and that the pseudo-count bonus incentivizes the agent to explore using this abstraction. We find, however, that implicit exploration may result in a mismatch between the approximated value function and exploration bonus, leading to either under- or over-exploration.
Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
Jun 18, 2018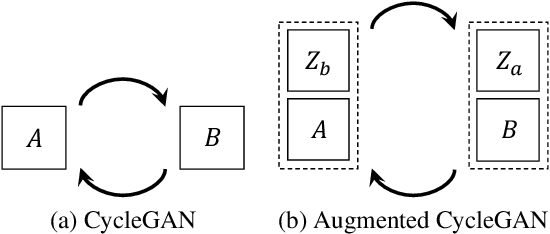

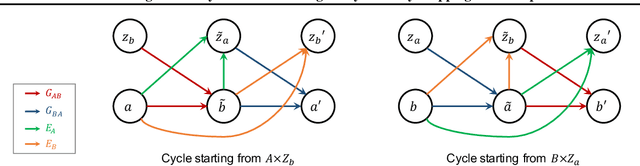

Learning inter-domain mappings from unpaired data can improve performance in structured prediction tasks, such as image segmentation, by reducing the need for paired data. CycleGAN was recently proposed for this problem, but critically assumes the underlying inter-domain mapping is approximately deterministic and one-to-one. This assumption renders the model ineffective for tasks requiring flexible, many-to-many mappings. We propose a new model, called Augmented CycleGAN, which learns many-to-many mappings between domains. We examine Augmented CycleGAN qualitatively and quantitatively on several image datasets.
Learning Distributed Representations from Reviews for Collaborative Filtering
Jun 18, 2018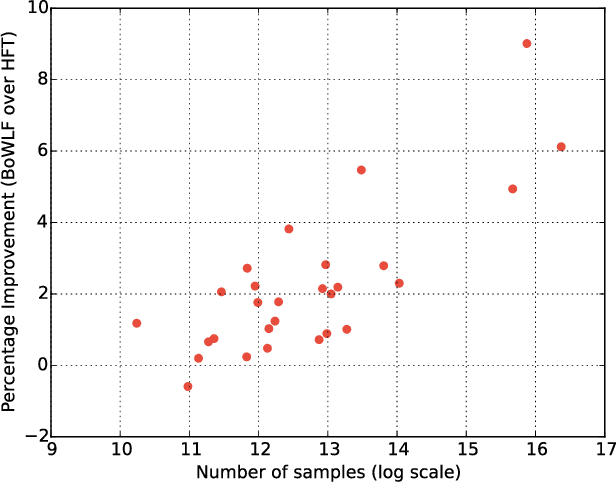
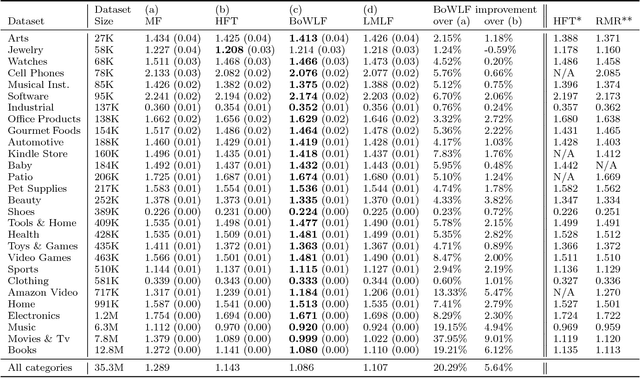
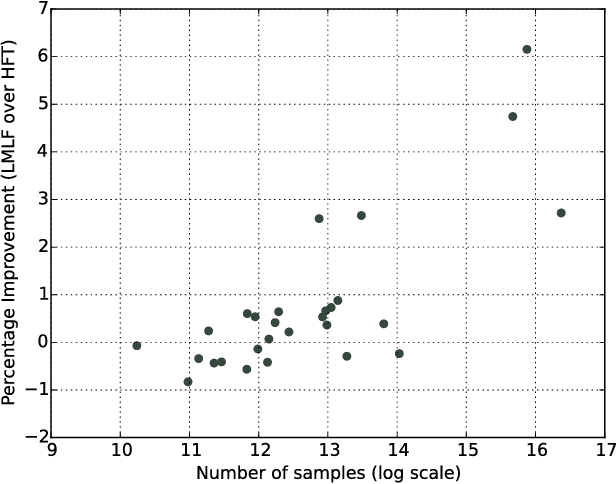
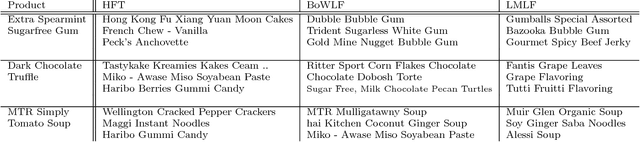
Recent work has shown that collaborative filter-based recommender systems can be improved by incorporating side information, such as natural language reviews, as a way of regularizing the derived product representations. Motivated by the success of this approach, we introduce two different models of reviews and study their effect on collaborative filtering performance. While the previous state-of-the-art approach is based on a latent Dirichlet allocation (LDA) model of reviews, the models we explore are neural network based: a bag-of-words product-of-experts model and a recurrent neural network. We demonstrate that the increased flexibility offered by the product-of-experts model allowed it to achieve state-of-the-art performance on the Amazon review dataset, outperforming the LDA-based approach. However, interestingly, the greater modeling power offered by the recurrent neural network appears to undermine the model's ability to act as a regularizer of the product representations.
Straight to the Tree: Constituency Parsing with Neural Syntactic Distance
Jun 11, 2018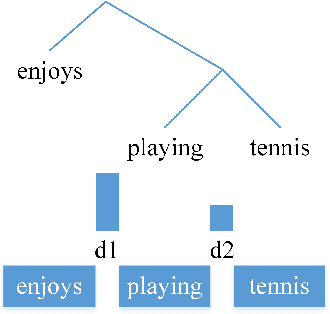
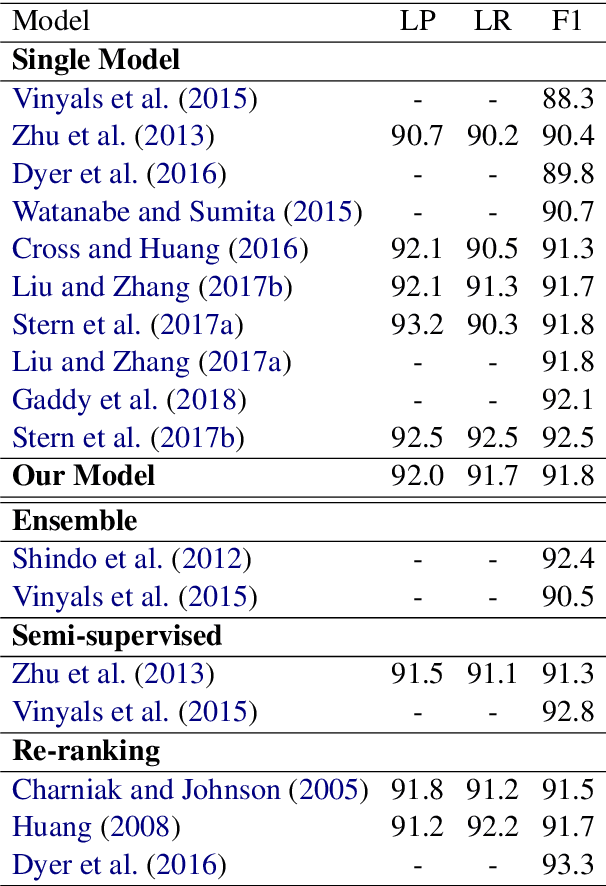

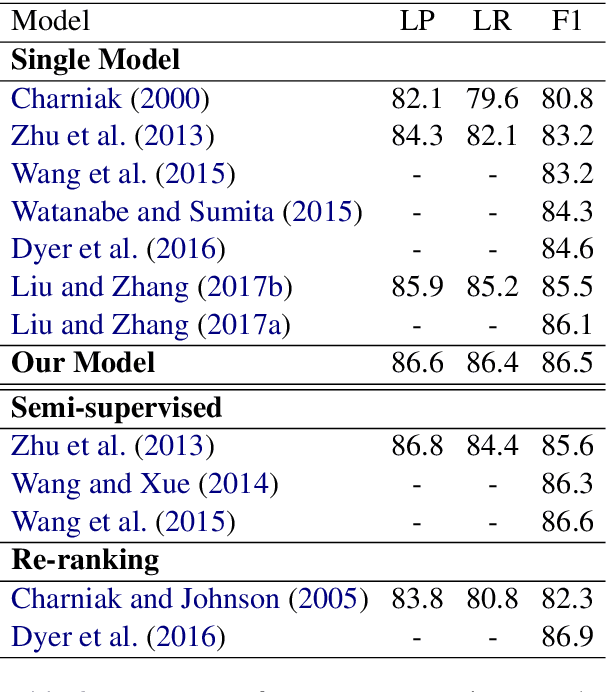
In this work, we propose a novel constituency parsing scheme. The model predicts a vector of real-valued scalars, named syntactic distances, for each split position in the input sentence. The syntactic distances specify the order in which the split points will be selected, recursively partitioning the input, in a top-down fashion. Compared to traditional shift-reduce parsing schemes, our approach is free from the potential problem of compounding errors, while being faster and easier to parallelize. Our model achieves competitive performance amongst single model, discriminative parsers in the PTB dataset and outperforms previous models in the CTB dataset.
MINE: Mutual Information Neural Estimation
Jun 07, 2018


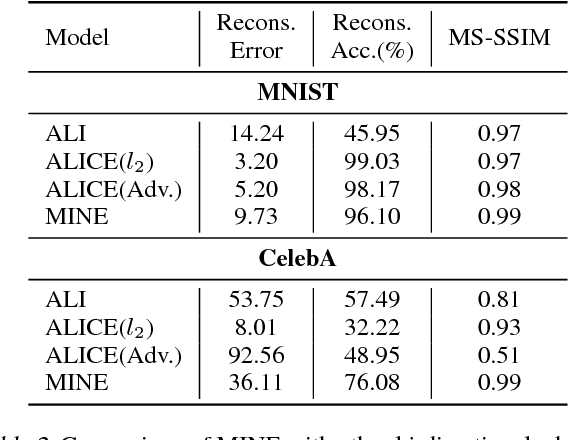
We argue that the estimation of mutual information between high dimensional continuous random variables can be achieved by gradient descent over neural networks. We present a Mutual Information Neural Estimator (MINE) that is linearly scalable in dimensionality as well as in sample size, trainable through back-prop, and strongly consistent. We present a handful of applications on which MINE can be used to minimize or maximize mutual information. We apply MINE to improve adversarially trained generative models. We also use MINE to implement Information Bottleneck, applying it to supervised classification; our results demonstrate substantial improvement in flexibility and performance in these settings.
* 19 pages, 6 figures