 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-VLM: Open-Vocabulary Object Detection upon Frozen Vision and Language Models
Sep 30, 2022
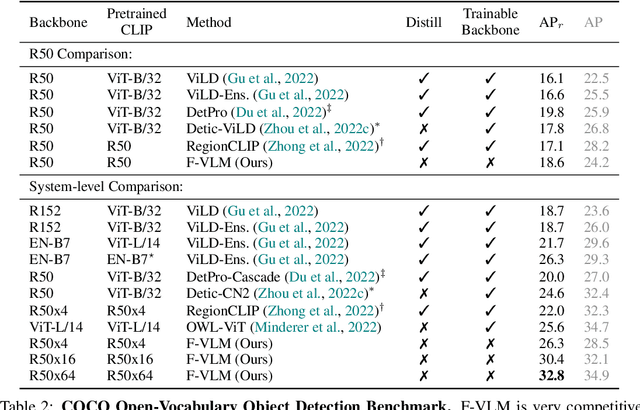
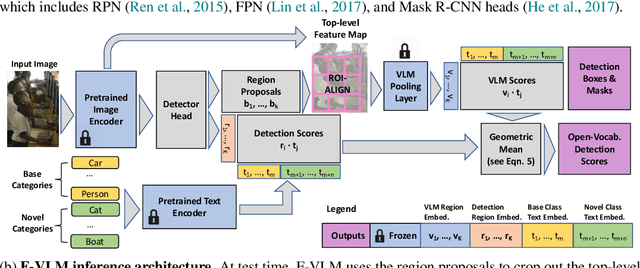
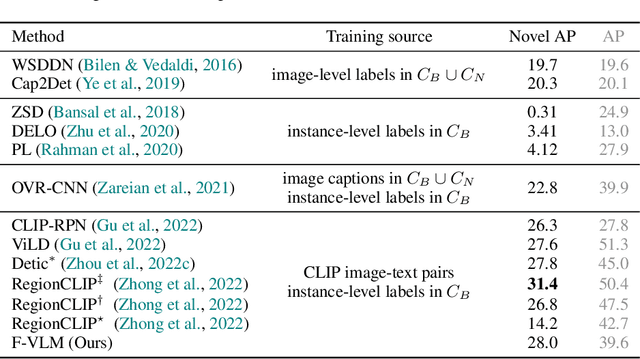
We present F-VLM, a simple open-vocabulary object detection method built upon Frozen Vision and Language Models. F-VLM simplifies the current multi-stage training pipeline by eliminating the need for knowledge distillation or detection-tailored pretraining. Surprisingly, we observe that a frozen VLM: 1) retains the locality-sensitive features necessary for detection, and 2) is a strong region classifier. We finetune only the detector head and combine the detector and VLM outputs for each region at inference time. F-VLM shows compelling scaling behavior and achieves +6.5 mask AP improvement over the previous state of the art on novel categories of LVIS open-vocabulary detection benchmark. In addition, we demonstrate very competitive results on COCO open-vocabulary detection benchmark and cross-dataset transfer detection, in addition to significant training speed-up and compute savings. Code will be released.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022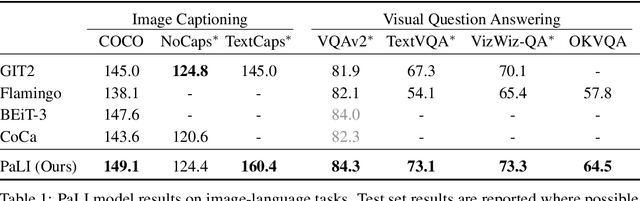

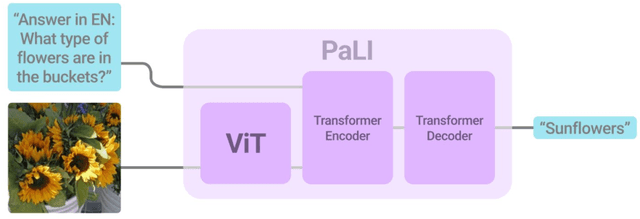

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
Pre-training image-language transformers for open-vocabulary tasks
Sep 09, 2022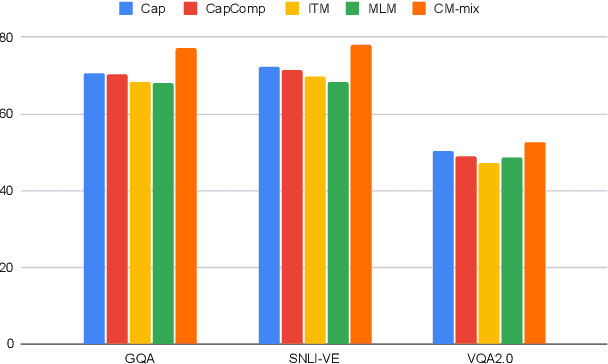
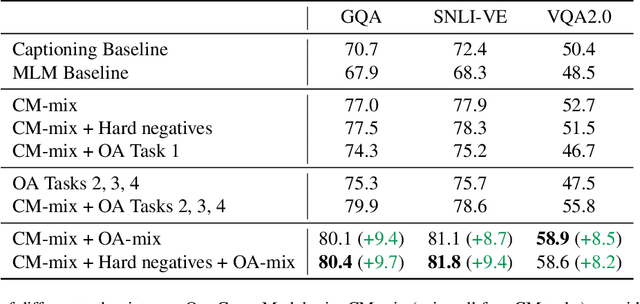
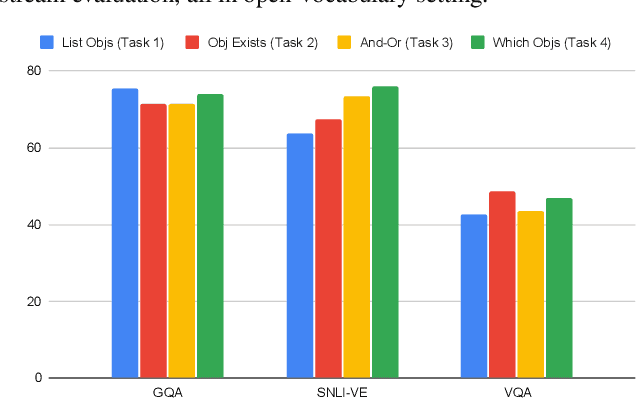

We present a pre-training approach for vision and language transformer models, which is based on a mixture of diverse tasks. We explore both the use of image-text captioning data in pre-training, which does not need additional supervision, as well as object-aware strategies to pre-train the model. We evaluate the method on a number of textgenerative vision+language tasks, such as Visual Question Answering, visual entailment and captioning, and demonstrate large gains over standard pre-training methods.
Video Question Answering with Iterative Video-Text Co-Tokenization
Aug 01, 2022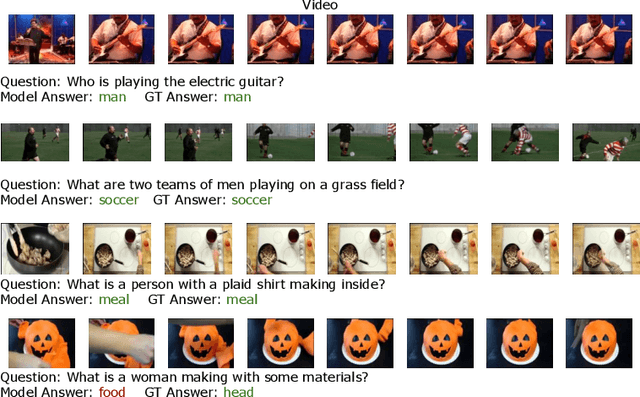
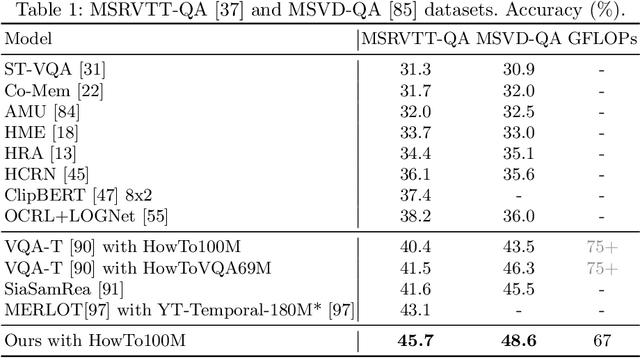
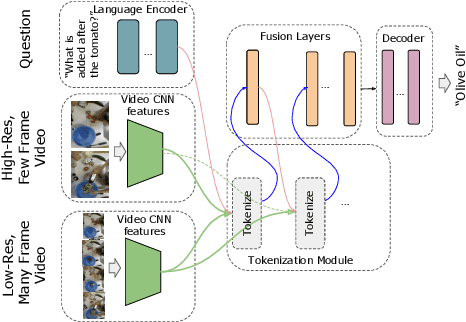

Video question answering is a challenging task that requires understanding jointly the language input, the visual information in individual video frames, as well as the temporal information about the events occurring in the video. In this paper, we propose a novel multi-stream video encoder for video question answering that uses multiple video inputs and a new video-text iterative co-tokenization approach to answer a variety of questions related to videos. We experimentally evaluate the model on several datasets, such as MSRVTT-QA, MSVD-QA, IVQA, outperforming the previous state-of-the-art by large margins. Simultaneously, our model reduces the required GFLOPs from 150-360 to only 67, producing a highly efficient video question answering model.
Answer-Me: Multi-Task Open-Vocabulary Visual Question Answering
May 02, 2022
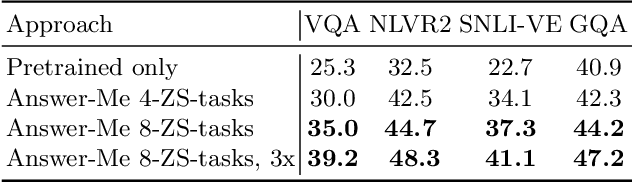
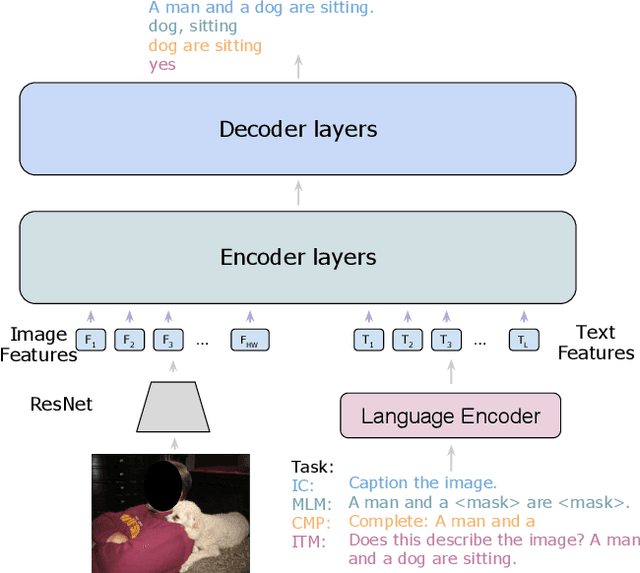
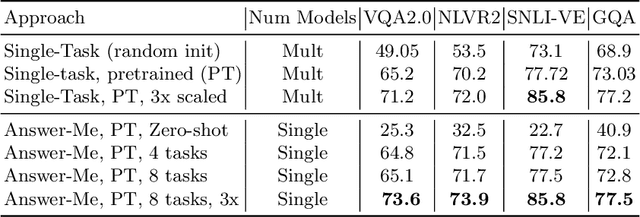
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.
FindIt: Generalized Localization with Natural Language Queries
Mar 31, 2022

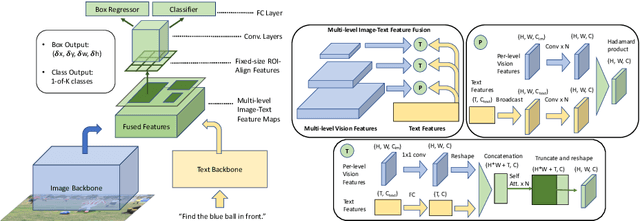
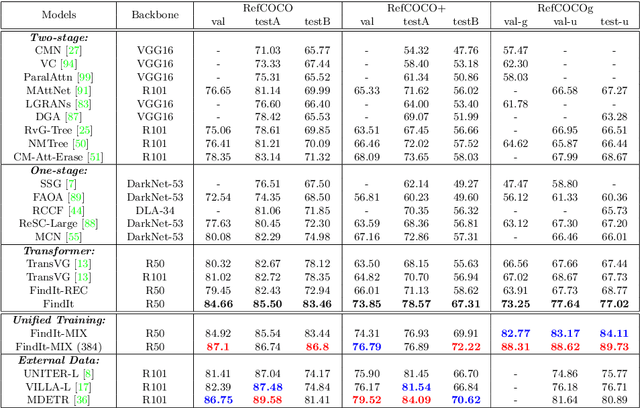
We propose FindIt, a simple and versatile framework that unifies a variety of visual grounding and localization tasks including referring expression comprehension, text-based localization, and object detection. Key to our architecture is an efficient multi-scale fusion module that unifies the disparate localization requirements across the tasks. In addition, we discover that a standard object detector is surprisingly effective in unifying these tasks without a need for task-specific design, losses, or pre-computed detections. Our end-to-end trainable framework responds flexibly and accurately to a wide range of referring expression, localization or detection queries for zero, one, or multiple objects. Jointly trained on these tasks, FindIt outperforms the state of the art on both referring expression and text-based localization, and shows competitive performance on object detection. Finally, FindIt generalizes better to out-of-distribution data and novel categories compared to strong single-task baselines. All of these are accomplished by a single, unified and efficient model. The code will be released.
4D-Net for Learned Multi-Modal Alignment
Sep 02, 2021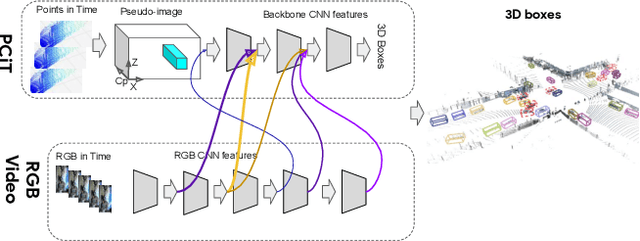
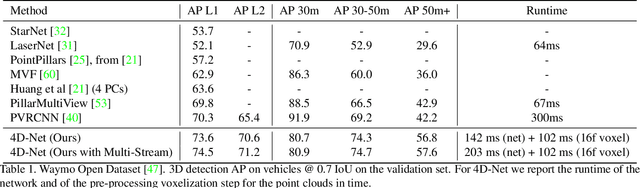
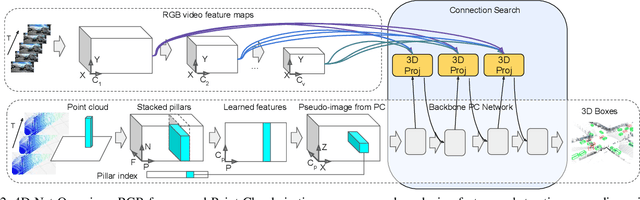
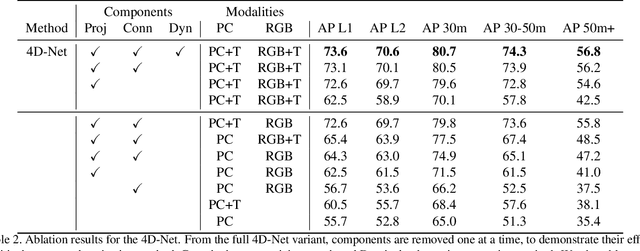
We present 4D-Net, a 3D object detection approach, which utilizes 3D Point Cloud and RGB sensing information, both in time. We are able to incorporate the 4D information by performing a novel dynamic connection learning across various feature representations and levels of abstraction, as well as by observing geometric constraints. Our approach outperforms the state-of-the-art and strong baselines on the Waymo Open Dataset. 4D-Net is better able to use motion cues and dense image information to detect distant objects more successfully.
Unsupervised Discovery of Actions in Instructional Videos
Jun 28, 2021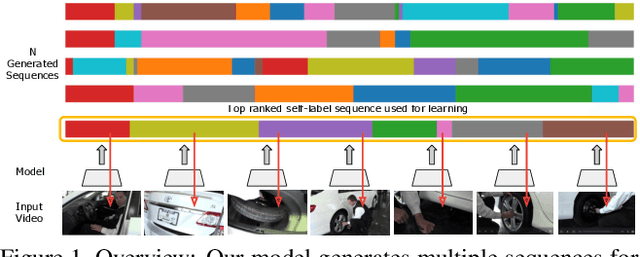
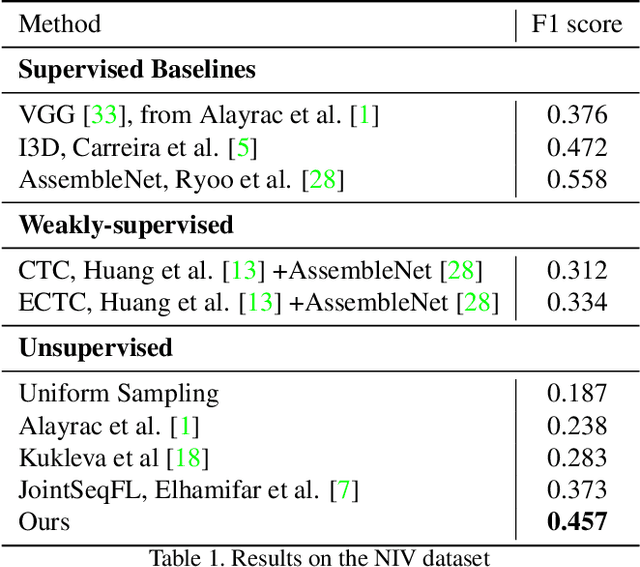
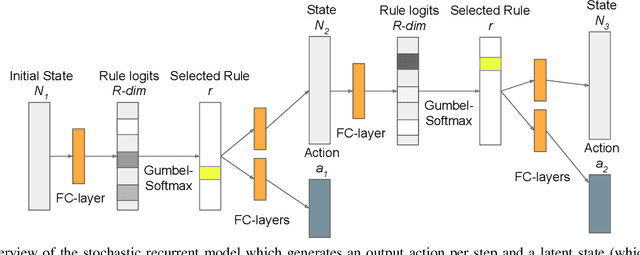
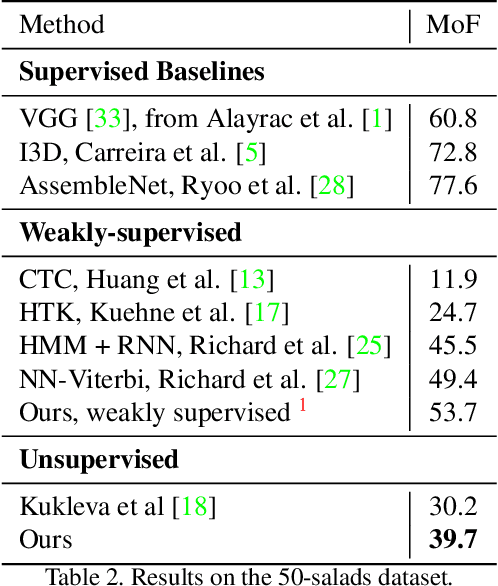
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos. Instructional videos contain complex activities and are a rich source of information for intelligent agents, such as, autonomous robots or virtual assistants, which can, for example, automatically `read' the steps from an instructional video and execute them. However, videos are rarely annotated with atomic activities, their boundaries or duration. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos. We propose a sequential stochastic autoregressive model for temporal segmentation of videos, which learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling for videos. Our approach outperforms the state-of-the-art unsupervised methods with large margins. We will open source the code.
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
Jun 21, 2021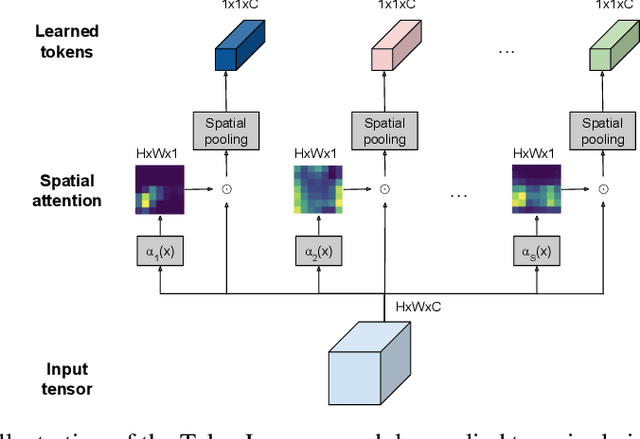
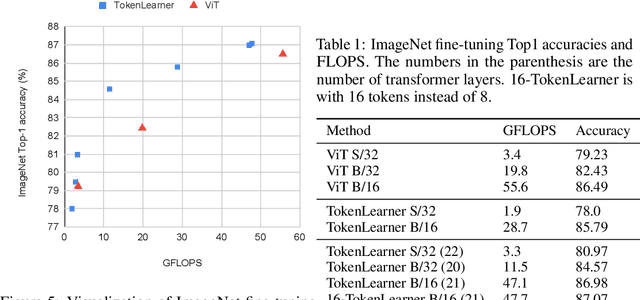
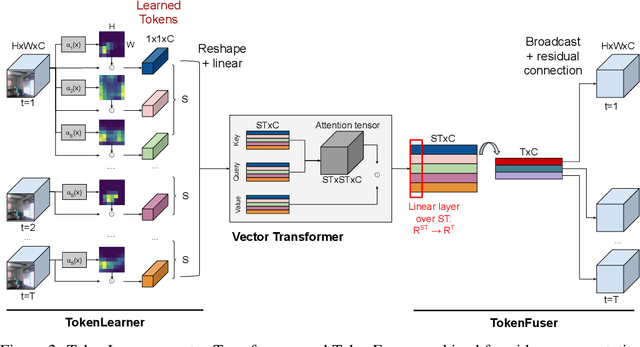

In this paper, we introduce a novel visual representation learning which relies on a handful of adaptively learned tokens, and which is applicable to both image and video understanding tasks. Instead of relying on hand-designed splitting strategies to obtain visual tokens and processing a large number of densely sampled patches for attention, our approach learns to mine important tokens in visual data. This results in efficiently and effectively finding a few important visual tokens and enables modeling of pairwise attention between such tokens, over a longer temporal horizon for videos, or the spatial content in images. Our experiments demonstrate strong performance on several challenging benchmarks for both image and video recognition tasks. Importantly, due to our tokens being adaptive, we accomplish competitive results at significantly reduced compute amount.
Unsupervised Action Segmentation for Instructional Videos
Jun 07, 2021
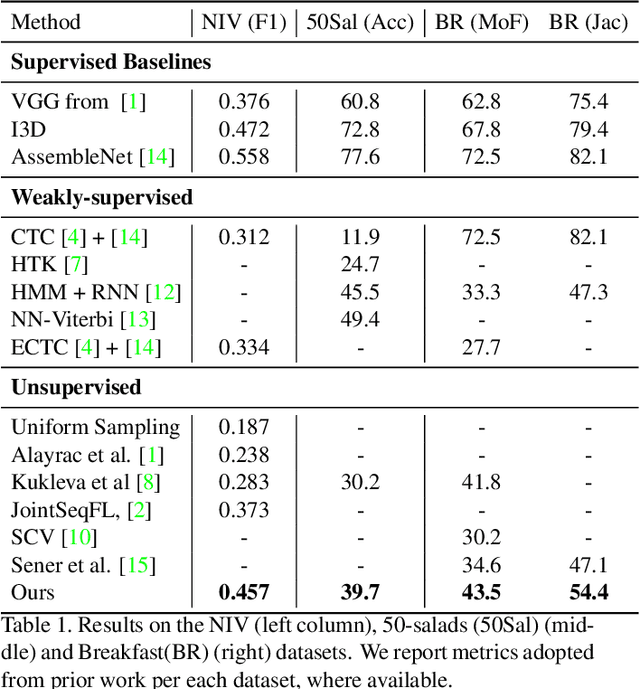
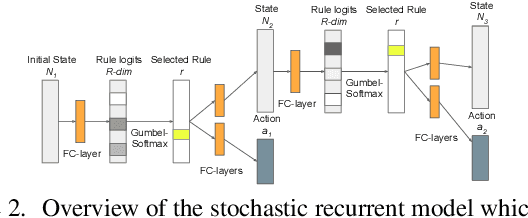
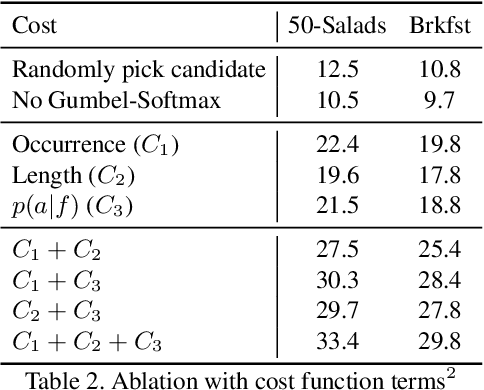
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos, which are rarely annotated with atomic actions. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos based on a sequential stochastic autoregressive model for temporal segmentation of videos. This learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling.