 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
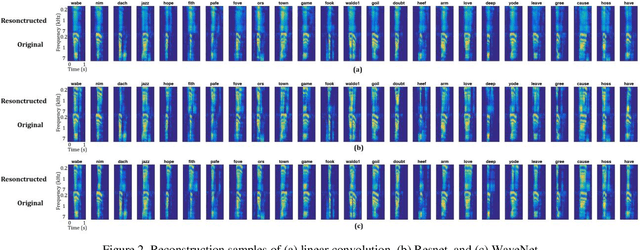
A deep complex network with multi-frame filtering for stereophonic acoustic echo cancellation
Feb 03, 2022
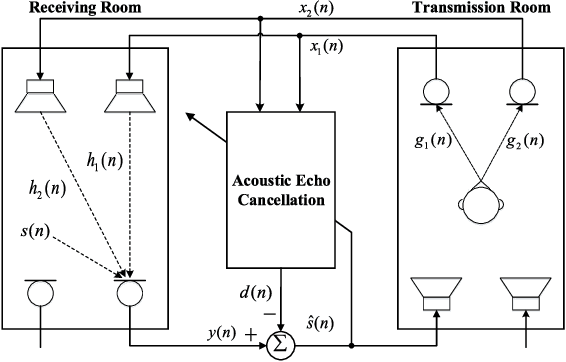
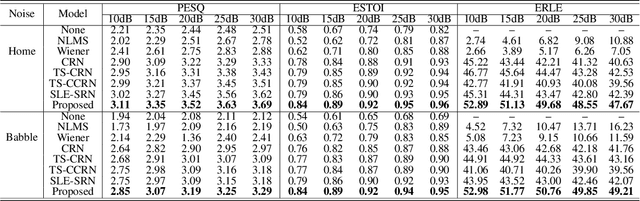
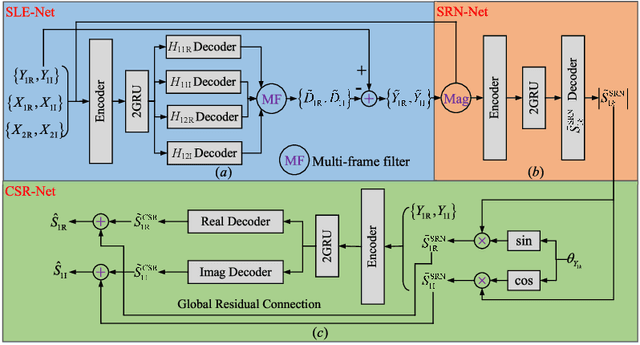
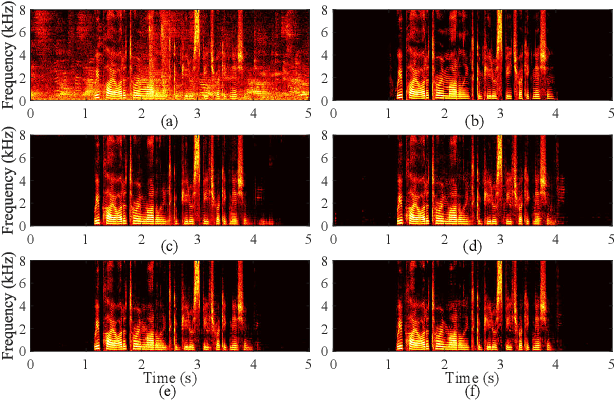
In hands-free communication system, the coupling between the loudspeaker and the microphone will generate echo signal, which can severely impair the quality of communication. Meanwhile, various types of noise in the communication environment further destroy the speech quality and intelligibility. It is hard to extract the near-end signal from the microphone input signal within one step, especially in low signal-to-noise ratios. In this paper, we propose a multi-stage approach to address this issue. On the one hand, we decompose the echo cancellation into two stages, including linear echo cancellation module and residual echo suppression module. A multi-frame filtering strategy is introduced to benefit estimating linear echo by utilizing more inter-frame information. On the other hand, we decouple the complex spectral mapping into magnitude estimation and complex spectra refine. Experimental results demonstrate that our proposed approach achieves stage-of-the-art performance over previous advanced algorithms under various conditions.
Voice Activity Detection for Transient Noisy Environment Based on Diffusion Nets
Jun 25, 2021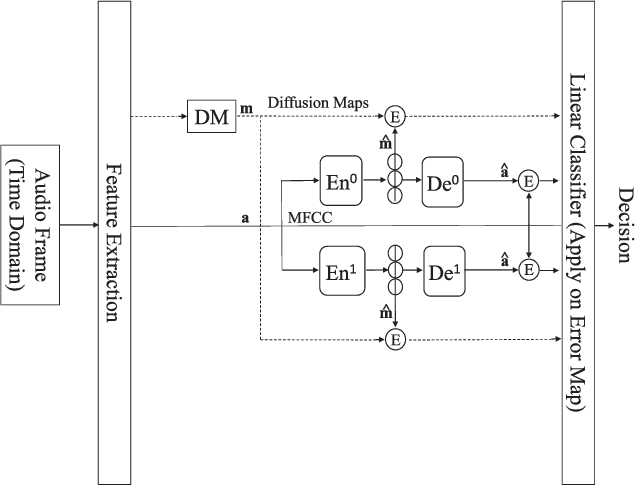
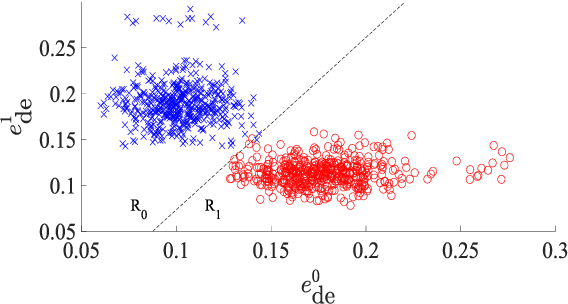
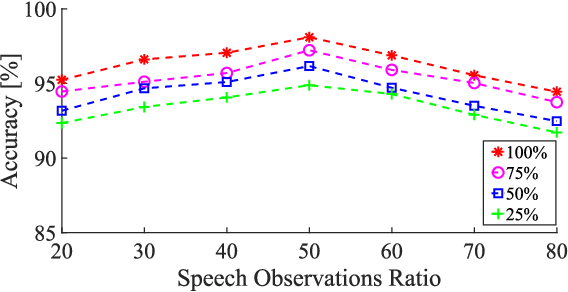
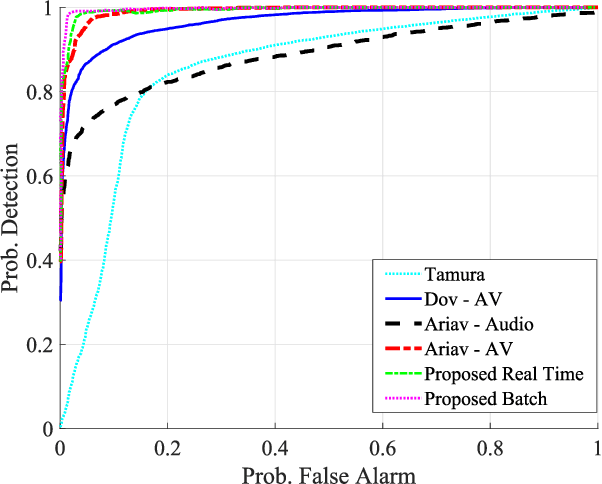
We address voice activity detection in acoustic environments of transients and stationary noises, which often occur in real life scenarios. We exploit unique spatial patterns of speech and non-speech audio frames by independently learning their underlying geometric structure. This process is done through a deep encoder-decoder based neural network architecture. This structure involves an encoder that maps spectral features with temporal information to their low-dimensional representations, which are generated by applying the diffusion maps method. The encoder feeds a decoder that maps the embedded data back into the high-dimensional space. A deep neural network, which is trained to separate speech from non-speech frames, is obtained by concatenating the decoder to the encoder, resembling the known Diffusion nets architecture. Experimental results show enhanced performance compared to competing voice activity detection methods. The improvement is achieved in both accuracy, robustness and generalization ability. Our model performs in a real-time manner and can be integrated into audio-based communication systems. We also present a batch algorithm which obtains an even higher accuracy for off-line applications.
* Accepted to IEEE journal of selected topics in signal processing 2019
Defining maximum acceptable latency of AI-enhanced CAI tools
Jan 08, 2022
Recent years have seen an increasing number of studies around the design of computer-assisted interpreting tools with integrated automatic speech processing and their use by trainees and professional interpreters. This paper discusses the role of system latency of such tools and presents the results of an experiment designed to investigate the maximum system latency that is cognitively acceptable for interpreters working in the simultaneous modality. The results show that interpreters can cope with a system latency of 3 seconds without any major impact in the rendition of the original text, both in terms of accuracy and fluency. This value is above the typical latency of available AI-based CAI tools and paves the way to experiment with larger context-based language models and higher latencies.
Unspeech: Unsupervised Speech Context Embeddings
Aug 23, 2018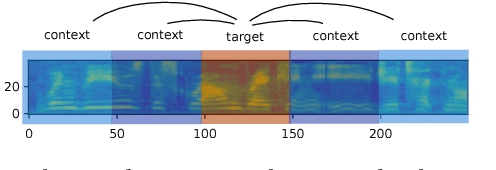
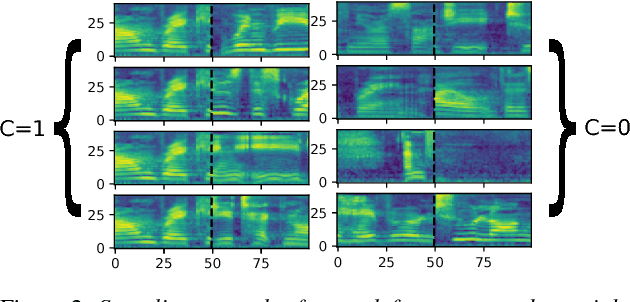
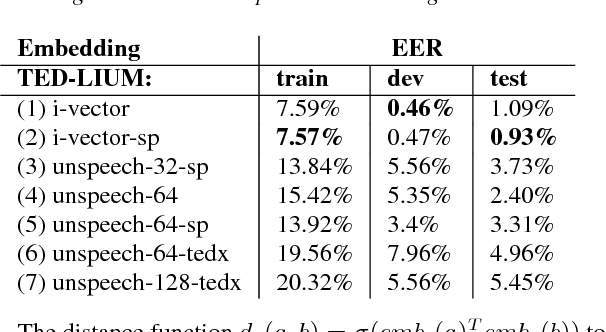
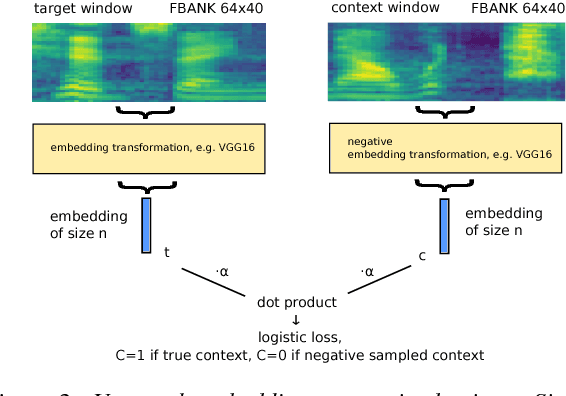
We introduce "Unspeech" embeddings, which are based on unsupervised learning of context feature representations for spoken language. The embeddings were trained on up to 9500 hours of crawled English speech data without transcriptions or speaker information, by using a straightforward learning objective based on context and non-context discrimination with negative sampling. We use a Siamese convolutional neural network architecture to train Unspeech embeddings and evaluate them on speaker comparison, utterance clustering and as a context feature in TDNN-HMM acoustic models trained on TED-LIUM, comparing it to i-vector baselines. Particularly decoding out-of-domain speech data from the recently released Common Voice corpus shows consistent WER reductions. We release our source code and pre-trained Unspeech models under a permissive open source license.
Oracle Linguistic Graphs Complement a Pretrained Transformer Language Model: A Cross-formalism Comparison
Dec 15, 2021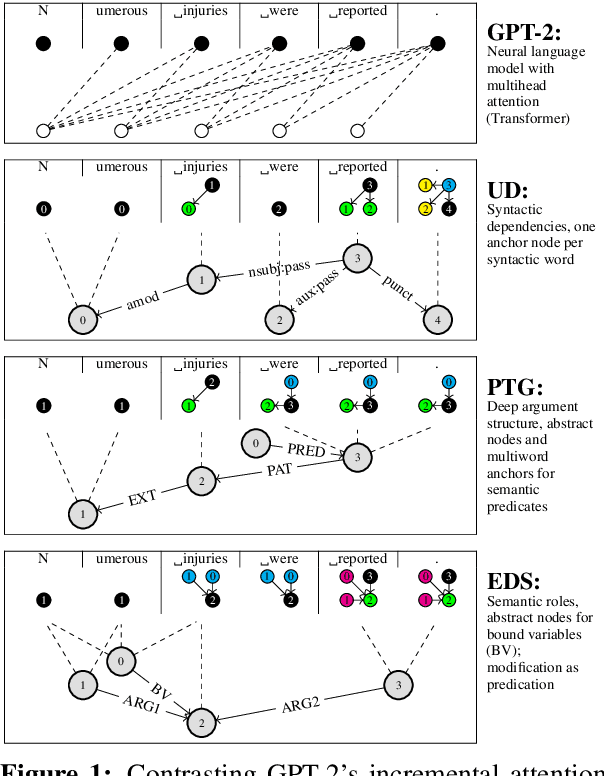

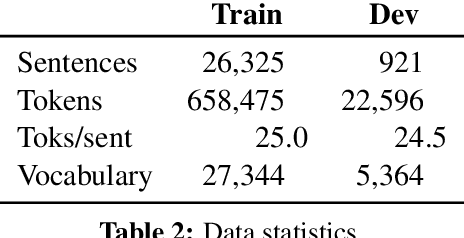
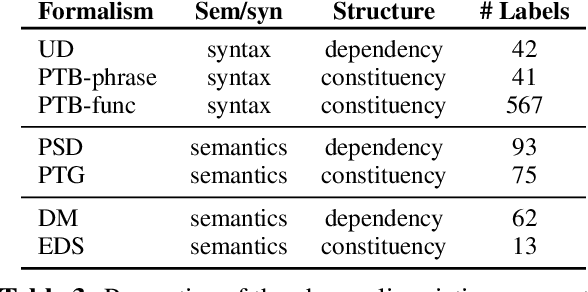
We examine the extent to which, in principle, linguistic graph representations can complement and improve neural language modeling. With an ensemble setup consisting of a pretrained Transformer and ground-truth graphs from one of 7 different formalisms, we find that, overall, semantic constituency structures are most useful to language modeling performance -- outpacing syntactic constituency structures as well as syntactic and semantic dependency structures. Further, effects vary greatly depending on part-of-speech class. In sum, our findings point to promising tendencies in neuro-symbolic language modeling and invite future research quantifying the design choices made by different formalisms.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019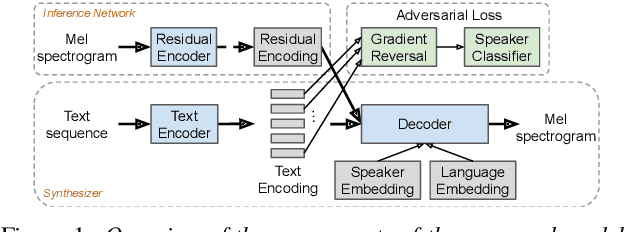
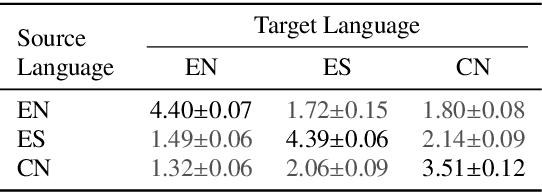
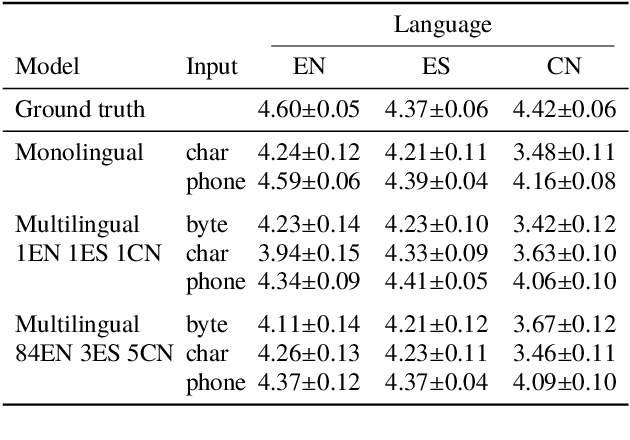
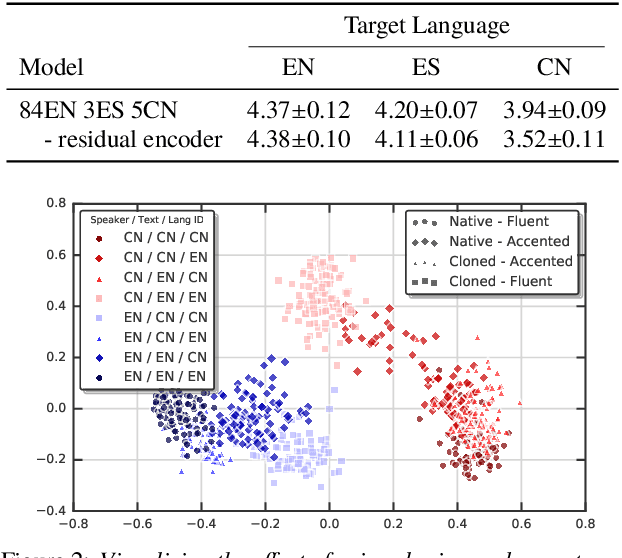
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Local and non-local dependency learning and emergence of rule-like representations in speech data by Deep Convolutional Generative Adversarial Networks
Sep 27, 2020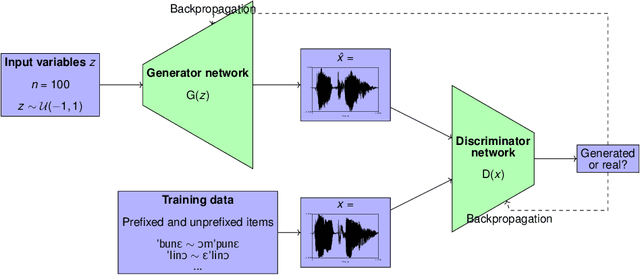
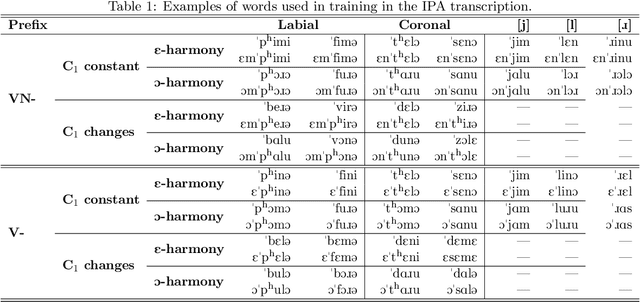
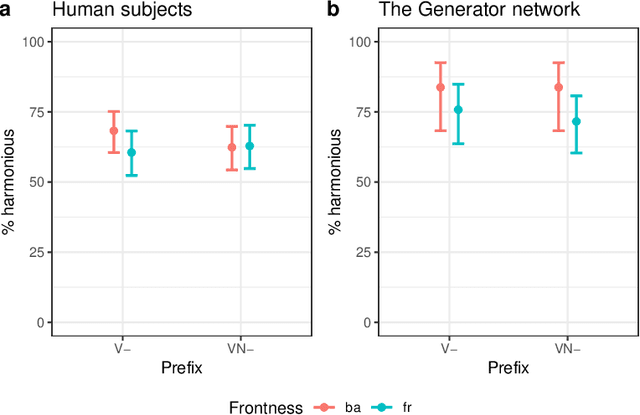
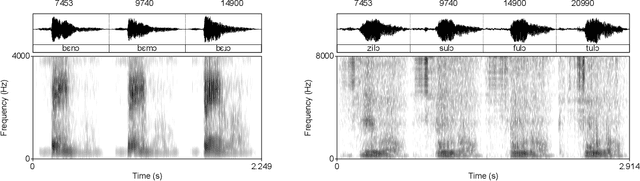
This paper argues that training GANs on local and non-local dependencies in speech data offers insights into how deep neural networks discretize continuous data and how symbolic-like rule-based morphophonological processes emerge in a deep convolutional architecture. Acquisition of speech has recently been modeled as a dependency between latent space and data generated by GANs in Begu\v{s} (arXiv:2006.03965), who models learning of a simple local allophonic distribution. We extend this approach to test learning of local and non-local phonological processes that include approximations of morphological processes. We further parallel outputs of the model to results of a behavioral experiment where human subjects are trained on the data used for training the GAN network. Four main conclusions emerge: (i) the networks provide useful information for computational models of language acquisition even if trained on a comparatively small dataset of an artificial grammar learning experiment; (ii) local processes are easier to learn than non-local processes, which matches both behavioral data in human subjects and typology in the world's languages. This paper also proposes (iii) how we can actively observe the network's progress in learning and explore the effect of training steps on learning representations by keeping latent space constant across different training steps. Finally, this paper shows that (iv) the network learns to encode the presence of a prefix with a single latent variable; by interpolating this variable, we can actively observe the operation of a non-local phonological process. The proposed technique for retrieving learning representations has general implications for our understanding of how GANs discretize continuous speech data and suggests that rule-like generalizations in the training data are represented as an interaction between variables in the network's latent space.
Personalized One-Shot Lipreading for an ALS Patient
Nov 02, 2021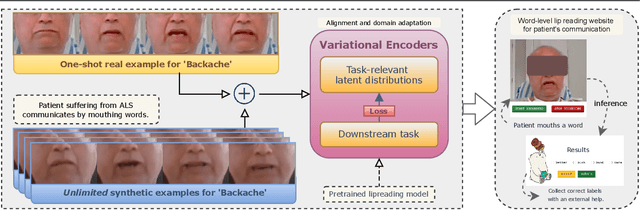
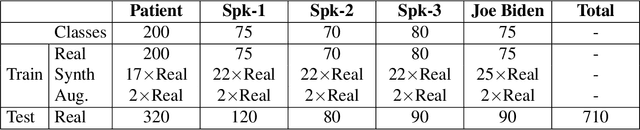
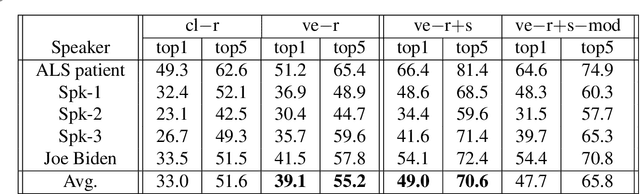
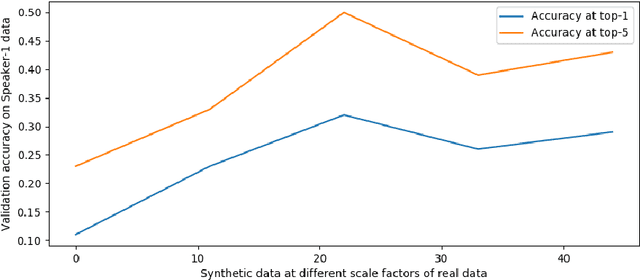
Lipreading or visually recognizing speech from the mouth movements of a speaker is a challenging and mentally taxing task. Unfortunately, multiple medical conditions force people to depend on this skill in their day-to-day lives for essential communication. Patients suffering from Amyotrophic Lateral Sclerosis (ALS) often lose muscle control, consequently their ability to generate speech and communicate via lip movements. Existing large datasets do not focus on medical patients or curate personalized vocabulary relevant to an individual. Collecting a large-scale dataset of a patient, needed to train mod-ern data-hungry deep learning models is, however, extremely challenging. In this work, we propose a personalized network to lipread an ALS patient using only one-shot examples. We depend on synthetically generated lip movements to augment the one-shot scenario. A Variational Encoder based domain adaptation technique is used to bridge the real-synthetic domain gap. Our approach significantly improves and achieves high top-5accuracy with 83.2% accuracy compared to 62.6% achieved by comparable methods for the patient. Apart from evaluating our approach on the ALS patient, we also extend it to people with hearing impairment relying extensively on lip movements to communicate.
Reconstructing Speech Stimuli From Human Auditory Cortex Activity Using a WaveNet Approach
Nov 08, 2018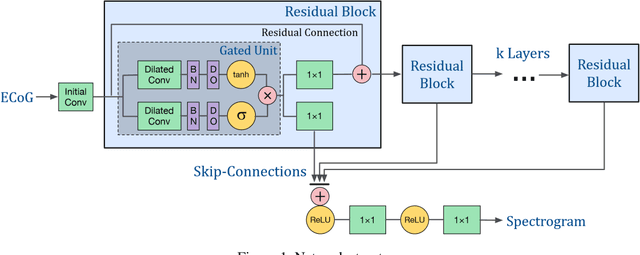
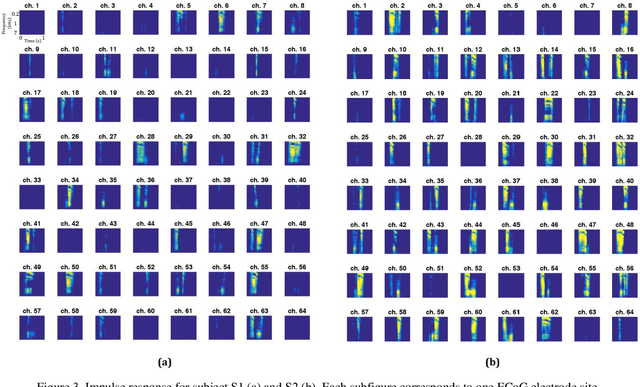

The superior temporal gyrus (STG) region of cortex critically contributes to speech recognition. In this work, we show that a proposed WaveNet, with limited available data, is able to reconstruct speech stimuli from STG intracranial recordings. We further investigate the impulse response of the fitted model for each recording electrode and observe phoneme level temporospectral tuning properties for the recorded area of cortex. This discovery is consistent with previous studies implicating the posterior STG (pSTG) in a phonetic representation of speech and provides detailed acoustic features that certain electrode sites possibly extract during speech recognition.
Author Profiling for Hate Speech Detection
Feb 14, 2019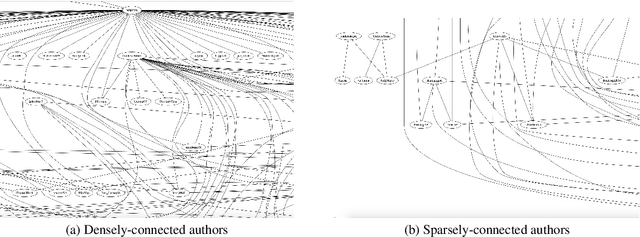
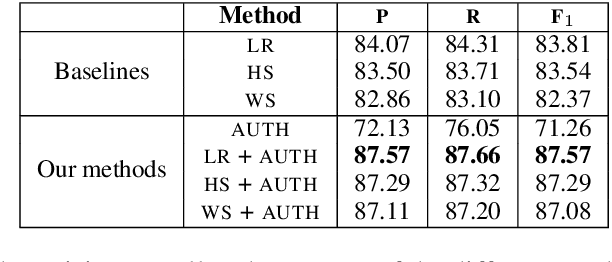
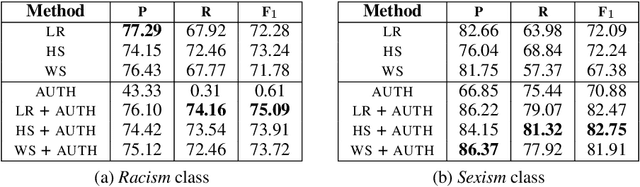

The rapid growth of social media in recent years has fed into some highly undesirable phenomena such as proliferation of abusive and offensive language on the Internet. Previous research suggests that such hateful content tends to come from users who share a set of common stereotypes and form communities around them. The current state-of-the-art approaches to hate speech detection are oblivious to user and community information and rely entirely on textual (i.e., lexical and semantic) cues. In this paper, we propose a novel approach to this problem that incorporates community-based profiling features of Twitter users. Experimenting with a dataset of 16k tweets, we show that our methods significantly outperform the current state of the art in hate speech detection. Further, we conduct a qualitative analysis of model characteristics. We release our code, pre-trained models and all the resources used in the public domain.