 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAx-Prover: A Deep Reasoning Agentic Framework for Theorem Proving in Mathematics and Quantum Physics
Oct 14, 2025We present Ax-Prover, a multi-agent system for automated theorem proving in Lean that can solve problems across diverse scientific domains and operate either autonomously or collaboratively with human experts. To achieve this, Ax-Prover approaches scientific problem solving through formal proof generation, a process that demands both creative reasoning and strict syntactic rigor. Ax-Prover meets this challenge by equipping Large Language Models (LLMs), which provide knowledge and reasoning, with Lean tools via the Model Context Protocol (MCP), which ensure formal correctness. To evaluate its performance as an autonomous prover, we benchmark our approach against frontier LLMs and specialized prover models on two public math benchmarks and on two Lean benchmarks we introduce in the fields of abstract algebra and quantum theory. On public datasets, Ax-Prover is competitive with state-of-the-art provers, while it largely outperform them on the new benchmarks. This shows that, unlike specialized systems that struggle to generalize, our tool-based agentic theorem prover approach offers a generalizable methodology for formal verification across diverse scientific domains. Furthermore, we demonstrate Ax-Prover's assistant capabilities in a practical use case, showing how it enabled an expert mathematician to formalize the proof of a complex cryptography theorem.
From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions
Feb 19, 2025



Large Language Models (LLMs) are increasingly used in working environments for a wide range of tasks, excelling at solving individual problems in isolation. However, are they also able to effectively collaborate over long-term interactions? To investigate this, we introduce MemoryCode, a synthetic multi-session dataset designed to test LLMs' ability to track and execute simple coding instructions amid irrelevant information, simulating a realistic setting. While all the models we tested handle isolated instructions well, even the performance of state-of-the-art models like GPT-4o deteriorates when instructions are spread across sessions. Our analysis suggests this is due to their failure to retrieve and integrate information over long instruction chains. Our results highlight a fundamental limitation of current LLMs, restricting their ability to collaborate effectively in long interactions.
From Rewriting to Remembering: Common Ground for Conversational QA Models
Apr 08, 2022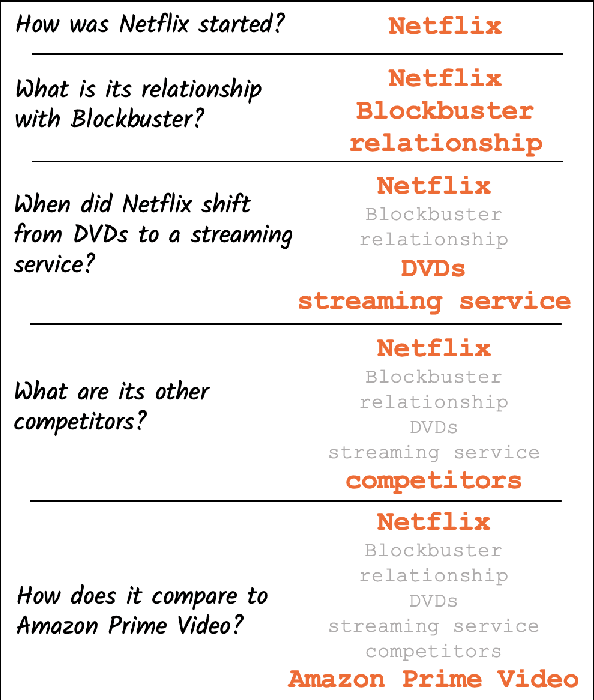
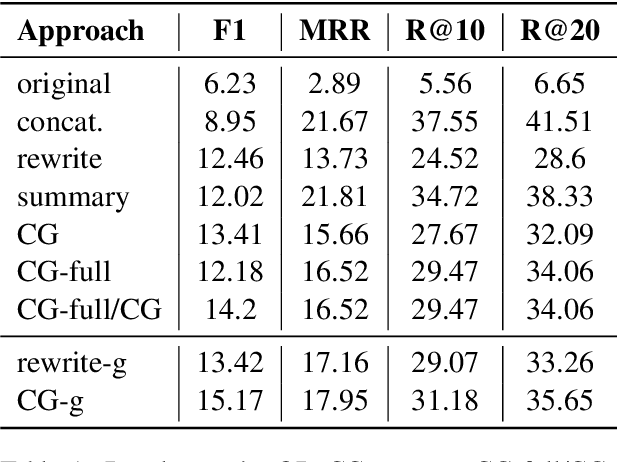


In conversational QA, models have to leverage information in previous turns to answer upcoming questions. Current approaches, such as Question Rewriting, struggle to extract relevant information as the conversation unwinds. We introduce the Common Ground (CG), an approach to accumulate conversational information as it emerges and select the relevant information at every turn. We show that CG offers a more efficient and human-like way to exploit conversational information compared to existing approaches, leading to improvements on Open Domain Conversational QA.
Words are the Window to the Soul: Language-based User Representations for Fake News Detection
Nov 14, 2020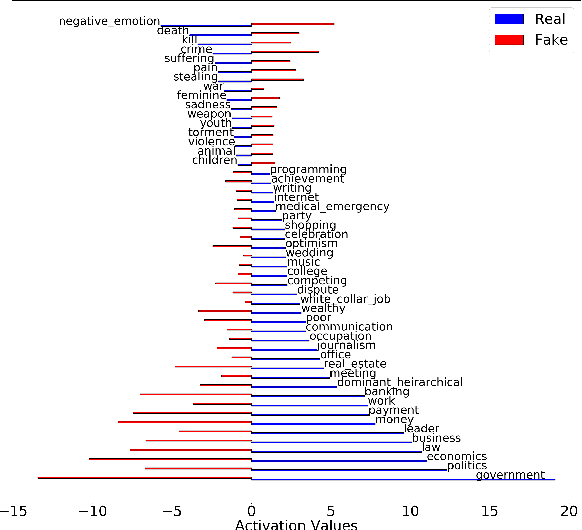
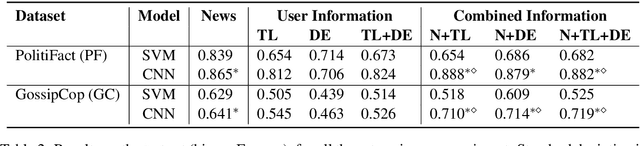
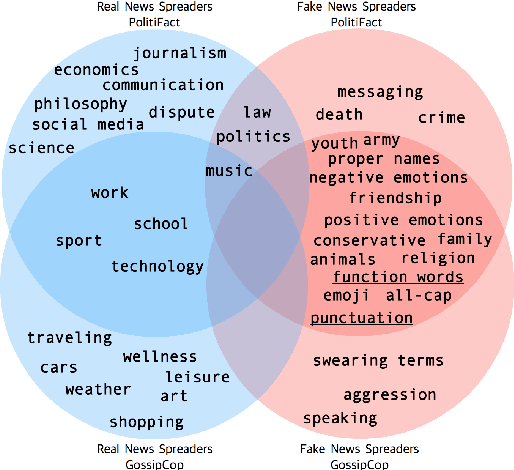
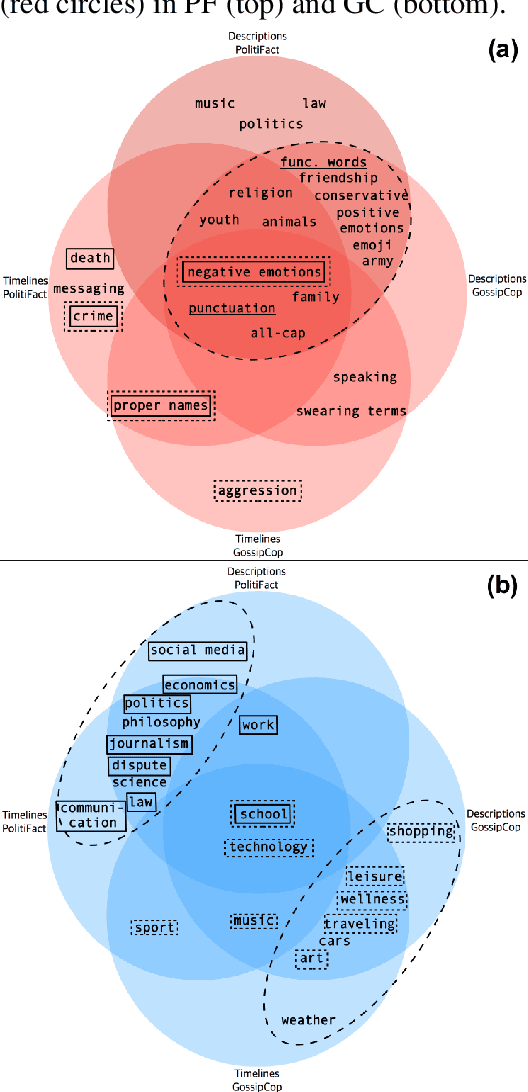
Cognitive and social traits of individuals are reflected in language use. Moreover, individuals who are prone to spread fake news online often share common traits. Building on these ideas, we introduce a model that creates representations of individuals on social media based only on the language they produce, and use them to detect fake news. We show that language-based user representations are beneficial for this task. We also present an extended analysis of the language of fake news spreaders, showing that its main features are mostly domain independent and consistent across two English datasets. Finally, we exploit the relation between language use and connections in the social graph to assess the presence of the Echo Chamber effect in our data.
Analysing Lexical Semantic Change with Contextualised Word Representations
Apr 29, 2020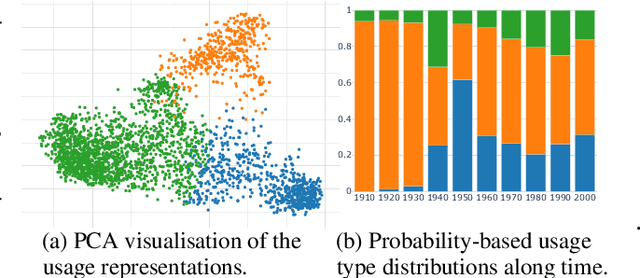

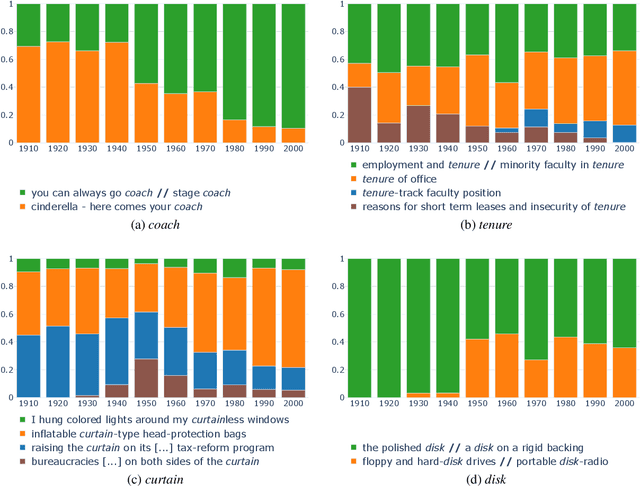

This paper presents the first unsupervised approach to lexical semantic change that makes use of contextualised word representations. We propose a novel method that exploits the BERT neural language model to obtain representations of word usages, clusters these representations into usage types, and measures change along time with three proposed metrics. We create a new evaluation dataset and show that the model representations and the detected semantic shifts are positively correlated with human judgements. Our extensive qualitative analysis demonstrates that our method captures a variety of synchronic and diachronic linguistic phenomena. We expect our work to inspire further research in this direction.
You Shall Know a User by the Company It Keeps: Dynamic Representations for Social Media Users in NLP
Sep 01, 2019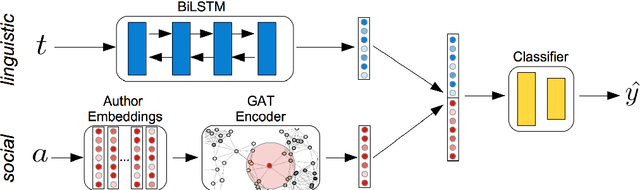
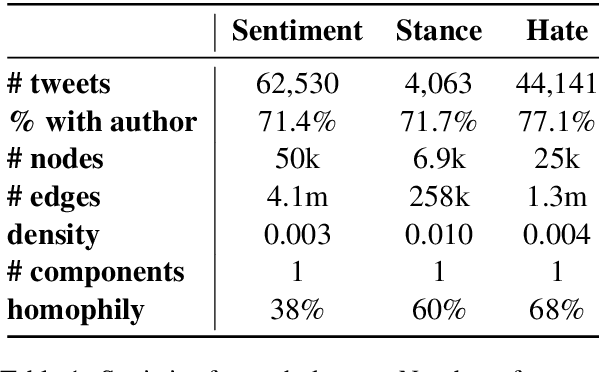
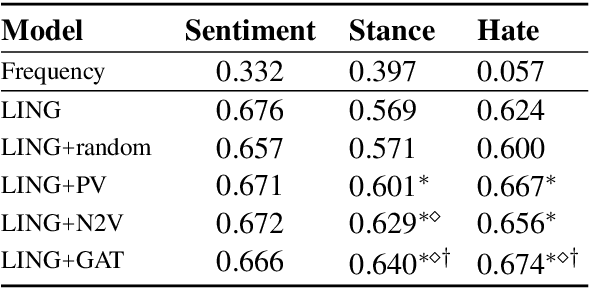
Information about individuals can help to better understand what they say, particularly in social media where texts are short. Current approaches to modelling social media users pay attention to their social connections, but exploit this information in a static way, treating all connections uniformly. This ignores the fact, well known in sociolinguistics, that an individual may be part of several communities which are not equally relevant in all communicative situations. We present a model based on Graph Attention Networks that captures this observation. It dynamically explores the social graph of a user, computes a user representation given the most relevant connections for a target task, and combines it with linguistic information to make a prediction. We apply our model to three different tasks, evaluate it against alternative models, and analyse the results extensively, showing that it significantly outperforms other current methods.
Abusive Language Detection with Graph Convolutional Networks
Apr 05, 2019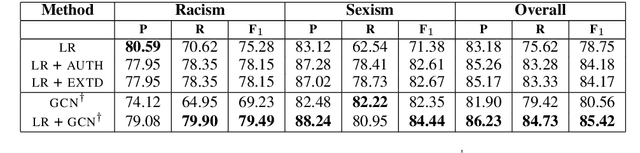


Abuse on the Internet represents a significant societal problem of our time. Previous research on automated abusive language detection in Twitter has shown that community-based profiling of users is a promising technique for this task. However, existing approaches only capture shallow properties of online communities by modeling follower-following relationships. In contrast, working with graph convolutional networks (GCNs), we present the first approach that captures not only the structure of online communities but also the linguistic behavior of the users within them. We show that such a heterogeneous graph-structured modeling of communities significantly advances the current state of the art in abusive language detection.
Author Profiling for Hate Speech Detection
Feb 14, 2019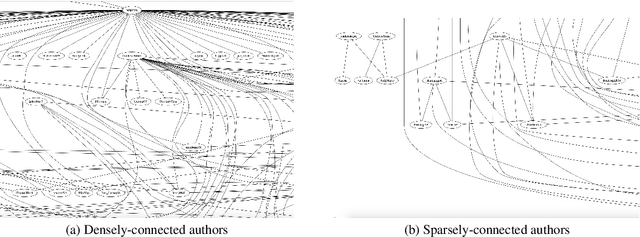
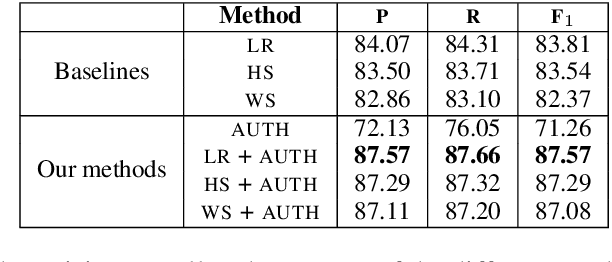
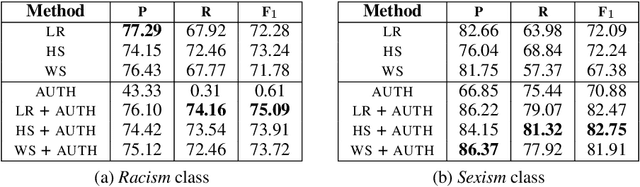

The rapid growth of social media in recent years has fed into some highly undesirable phenomena such as proliferation of abusive and offensive language on the Internet. Previous research suggests that such hateful content tends to come from users who share a set of common stereotypes and form communities around them. The current state-of-the-art approaches to hate speech detection are oblivious to user and community information and rely entirely on textual (i.e., lexical and semantic) cues. In this paper, we propose a novel approach to this problem that incorporates community-based profiling features of Twitter users. Experimenting with a dataset of 16k tweets, we show that our methods significantly outperform the current state of the art in hate speech detection. Further, we conduct a qualitative analysis of model characteristics. We release our code, pre-trained models and all the resources used in the public domain.
Short-term meaning shift: an exploratory distributional analysis
Sep 10, 2018
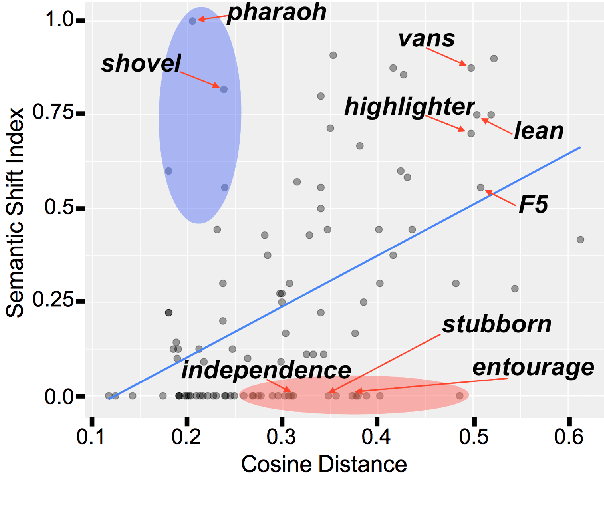
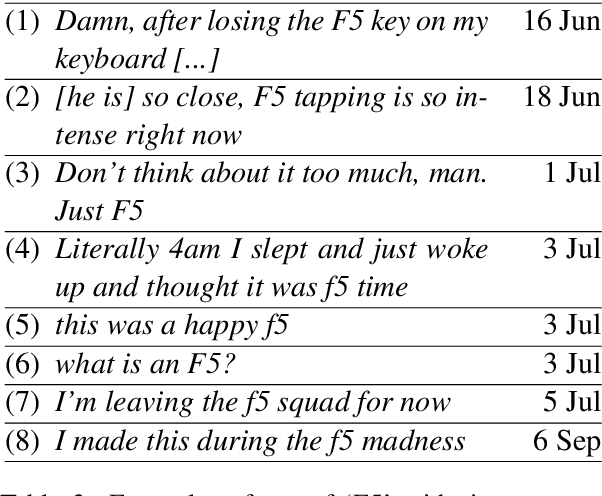
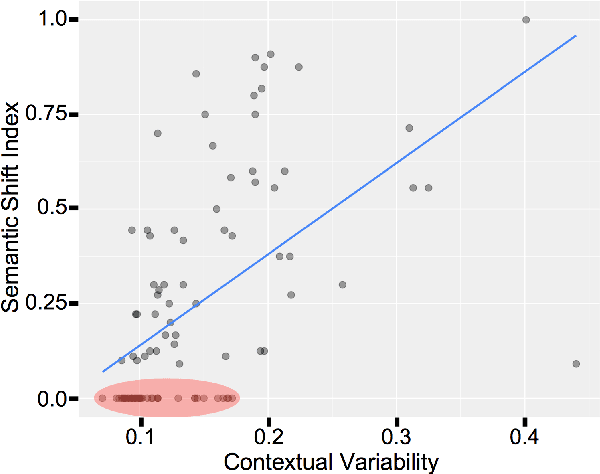
We investigate diachronic meaning shift that takes place in short periods of time (short-term meaning shift) and in an online community of speakers. We create a small dataset and use it to assess the performance of a standard model for meaning shift detection on short-term meaning shift, and find that this phenomenon poses specific difficulties for models based on the Distributional Hypothesis.
Semantic Variation in Online Communities of Practice
Jun 15, 2018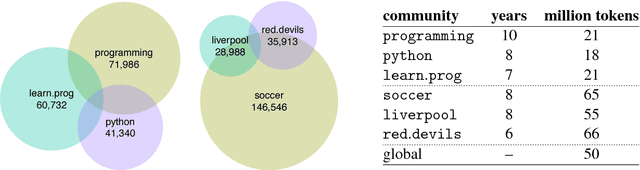
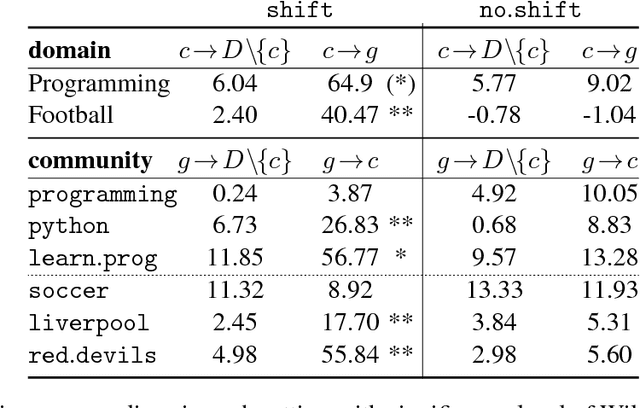
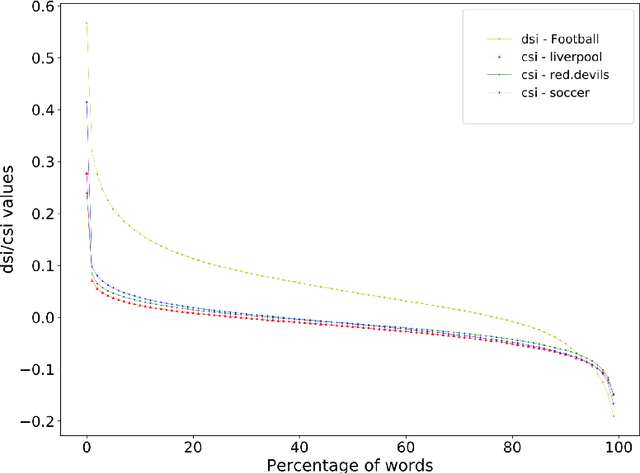
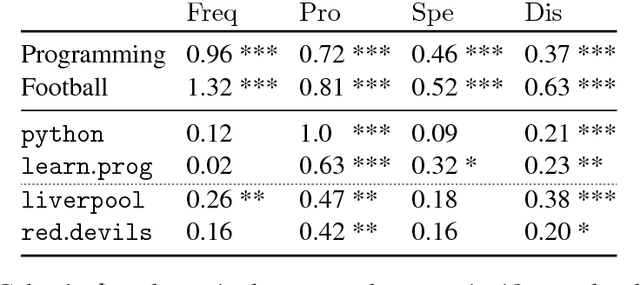
We introduce a framework for quantifying semantic variation of common words in Communities of Practice and in sets of topic-related communities. We show that while some meaning shifts are shared across related communities, others are community-specific, and therefore independent from the discussed topic. We propose such findings as evidence in favour of sociolinguistic theories of socially-driven semantic variation. Results are evaluated using an independent language modelling task. Furthermore, we investigate extralinguistic features and show that factors such as prominence and dissemination of words are related to semantic variation.