 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification
Mar 29, 2022

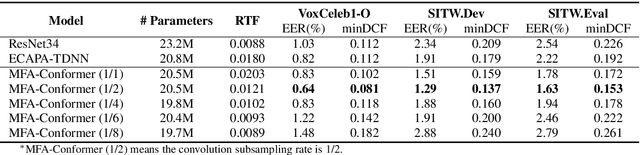
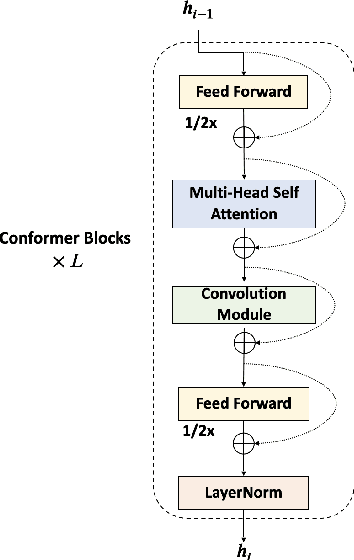
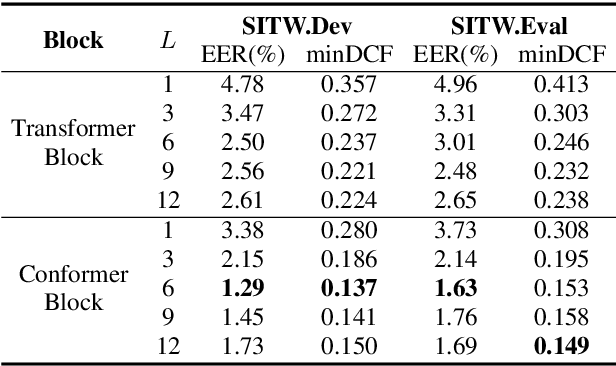
In this paper, we present Multi-scale Feature Aggregation Conformer (MFA-Conformer), an easy-to-implement, simple but effective backbone for automatic speaker verification based on the Convolution-augmented Transformer (Conformer). The architecture of the MFA-Conformer is inspired by recent state-of-the-art models in speech recognition and speaker verification. Firstly, we introduce a convolution sub-sampling layer to decrease the computational cost of the model. Secondly, we adopt Conformer blocks which combine Transformers and convolution neural networks (CNNs) to capture global and local features effectively. Finally, the output feature maps from all Conformer blocks are concatenated to aggregate multi-scale representations before final pooling. We evaluate the MFA-Conformer on the widely used benchmarks. The best system obtains 0.64%, 1.29% and 1.63% EER on VoxCeleb1-O, SITW.Dev, and SITW.Eval set, respectively. MFA-Conformer significantly outperforms the popular ECAPA-TDNN systems in both recognition performance and inference speed. Last but not the least, the ablation studies clearly demonstrate that the combination of global and local feature learning can lead to robust and accurate speaker embedding extraction. We will release the code for future works to do comparison.
Shifted Chunk Encoder for Transformer Based Streaming End-to-End ASR
Mar 29, 2022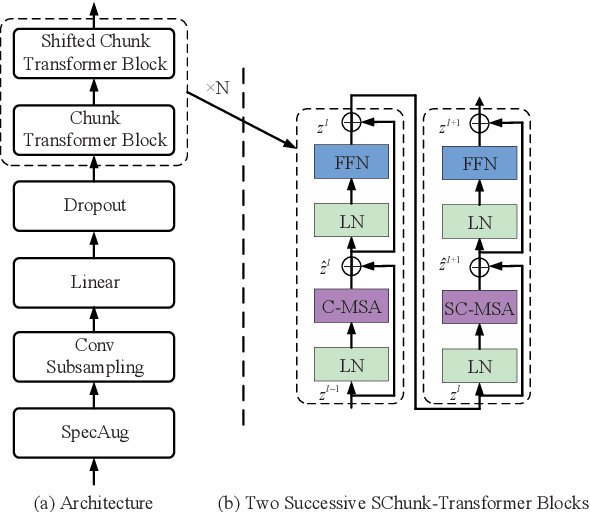
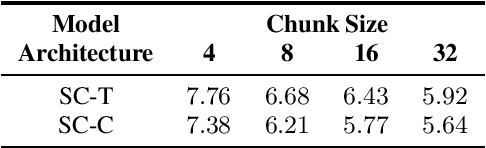
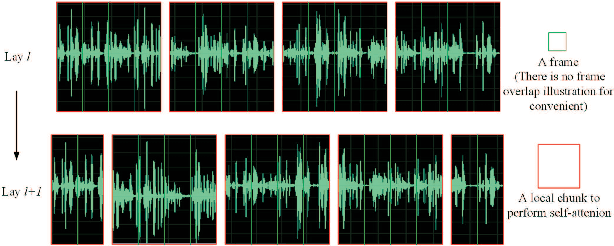

Currently, there are mainly three Transformer encoder based streaming End to End (E2E) Automatic Speech Recognition (ASR) approaches, namely time-restricted methods, chunk-wise methods, and memory based methods. However, all of them have some limitations in aspects of global context modeling, linear computational complexity, and model parallelism. In this work, we aim to build a single model to achieve the benefits of all the three aspects for streaming E2E ASR. Particularly, we propose to use a shifted chunk mechanism instead of the conventional chunk mechanism for streaming Transformer and Conformer. This shifted chunk mechanism can significantly enhance modeling power through allowing chunk self-attention to capture global context across local chunks, while keeping linear computational complexity and parallel trainable. We name the Shifted Chunk Transformer and Conformer as SChunk-Transofromer and SChunk-Conformer, respectively. And we verify their performance on the widely used AISHELL-1 benckmark. Experiments show that the SChunk-Transformer and SChunk-Conformer achieve CER 6.43% and 5.77%, respectively. That surpasses the existing chunk-wise and memory based methods by a large margin, and is competitive even compared with the state-of-the-art time-restricted methods which have quadratic computational complexity.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.
Focal Loss based Residual Convolutional Neural Network for Speech Emotion Recognition
Jun 11, 2019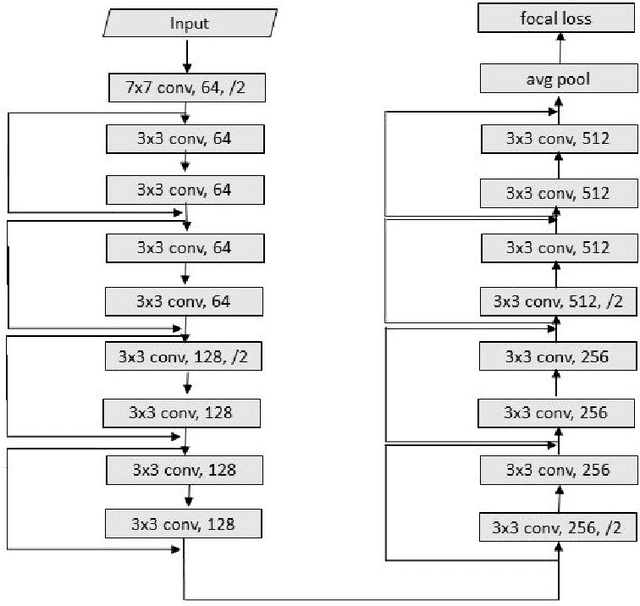
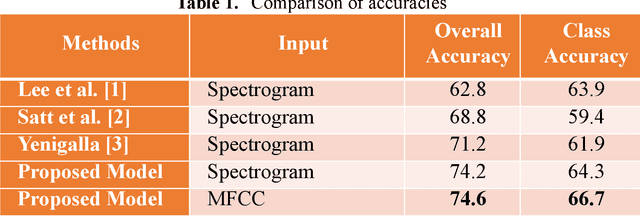
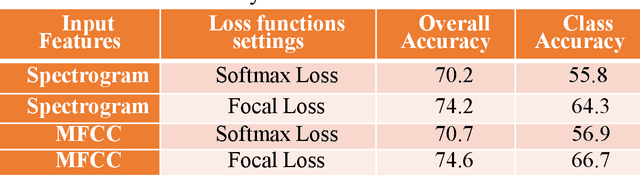
This paper proposes a Residual Convolutional Neural Network (ResNet) based on speech features and trained under Focal Loss to recognize emotion in speech. Speech features such as Spectrogram and Mel-frequency Cepstral Coefficients (MFCCs) have shown the ability to characterize emotion better than just plain text. Further Focal Loss, first used in One-Stage Object Detectors, has shown the ability to focus the training process more towards hard-examples and down-weight the loss assigned to well-classified examples, thus preventing the model from being overwhelmed by easily classifiable examples.
Worse WER, but Better BLEU? Leveraging Word Embedding as Intermediate in Multitask End-to-End Speech Translation
May 21, 2020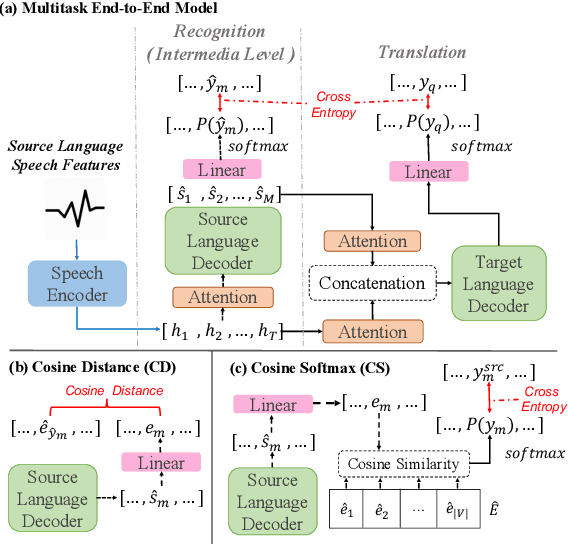
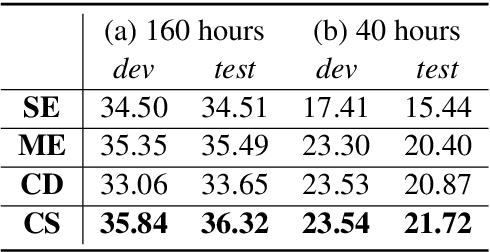
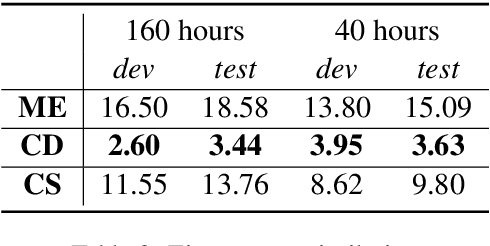
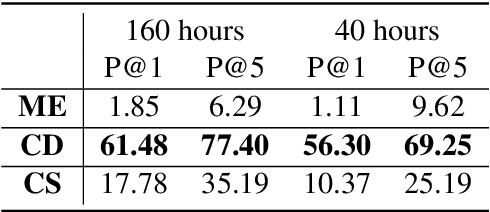
Speech translation (ST) aims to learn transformations from speech in the source language to the text in the target language. Previous works show that multitask learning improves the ST performance, in which the recognition decoder generates the text of the source language, and the translation decoder obtains the final translations based on the output of the recognition decoder. Because whether the output of the recognition decoder has the correct semantics is more critical than its accuracy, we propose to improve the multitask ST model by utilizing word embedding as the intermediate.
Computational bioacoustics with deep learning: a review and roadmap
Dec 13, 2021
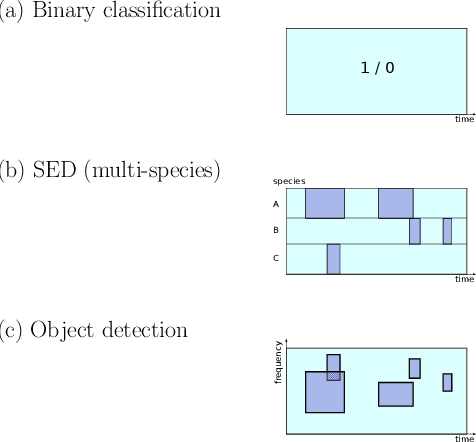
Animal vocalisations and natural soundscapes are fascinating objects of study, and contain valuable evidence about animal behaviours, populations and ecosystems. They are studied in bioacoustics and ecoacoustics, with signal processing and analysis an important component. Computational bioacoustics has accelerated in recent decades due to the growth of affordable digital sound recording devices, and to huge progress in informatics such as big data, signal processing and machine learning. Methods are inherited from the wider field of deep learning, including speech and image processing. However, the tasks, demands and data characteristics are often different from those addressed in speech or music analysis. There remain unsolved problems, and tasks for which evidence is surely present in many acoustic signals, but not yet realised. In this paper I perform a review of the state of the art in deep learning for computational bioacoustics, aiming to clarify key concepts and identify and analyse knowledge gaps. Based on this, I offer a subjective but principled roadmap for computational bioacoustics with deep learning: topics that the community should aim to address, in order to make the most of future developments in AI and informatics, and to use audio data in answering zoological and ecological questions.
Detecting Emotion Carriers by Combining Acoustic and Lexical Representations
Dec 13, 2021
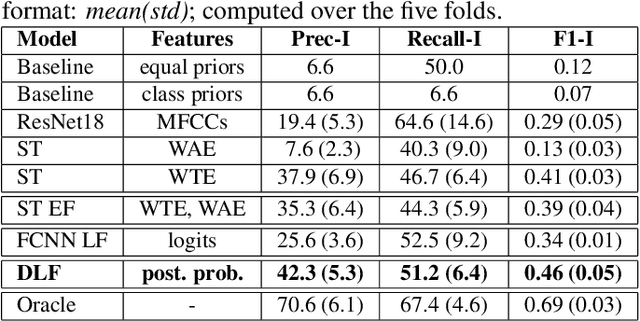
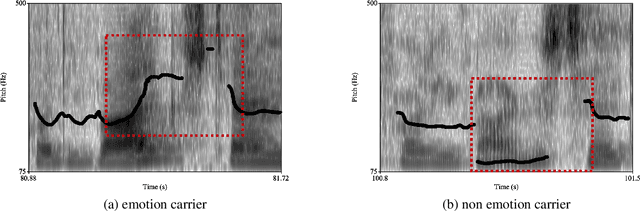
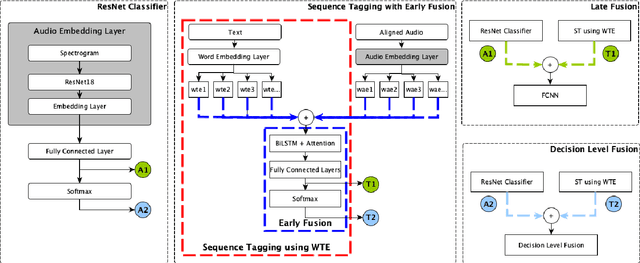
Personal narratives (PN) - spoken or written - are recollections of facts, people, events, and thoughts from one's own experience. Emotion recognition and sentiment analysis tasks are usually defined at the utterance or document level. However, in this work, we focus on Emotion Carriers (EC) defined as the segments (speech or text) that best explain the emotional state of the narrator ("loss of father", "made me choose"). Once extracted, such EC can provide a richer representation of the user state to improve natural language understanding and dialogue modeling. In previous work, it has been shown that EC can be identified using lexical features. However, spoken narratives should provide a richer description of the context and the users' emotional state. In this paper, we leverage word-based acoustic and textual embeddings as well as early and late fusion techniques for the detection of ECs in spoken narratives. For the acoustic word-level representations, we use Residual Neural Networks (ResNet) pretrained on separate speech emotion corpora and fine-tuned to detect EC. Experiments with different fusion and system combination strategies show that late fusion leads to significant improvements for this task.
Attacker Attribution of Audio Deepfakes
Mar 28, 2022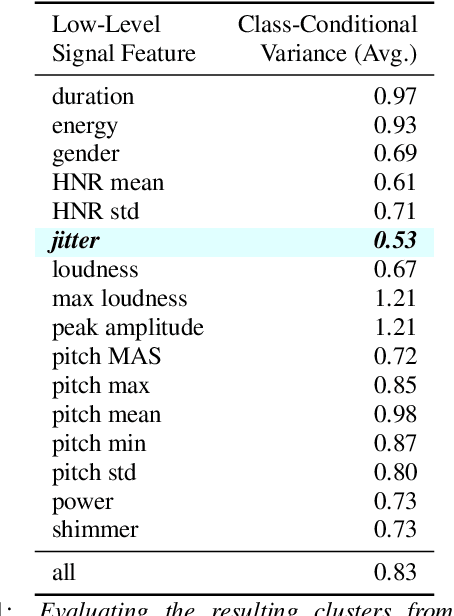
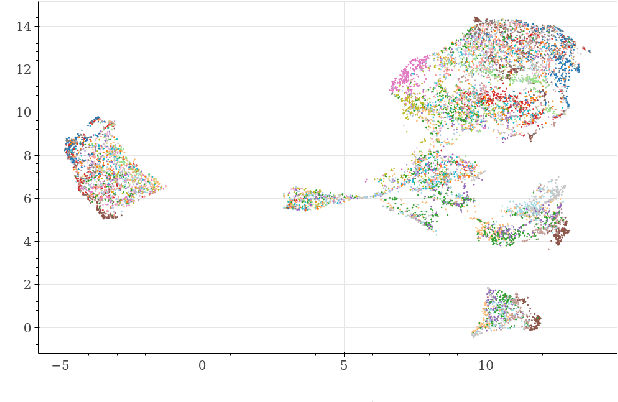
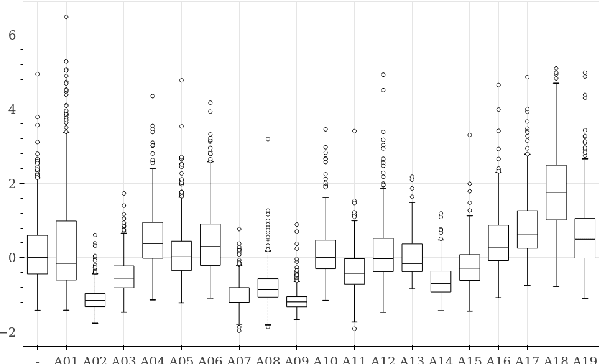
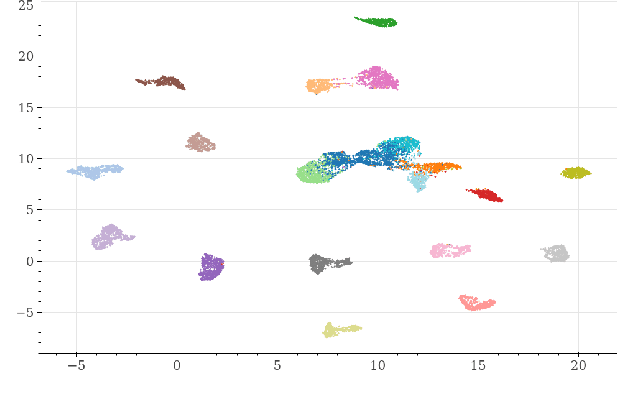
Deepfakes are synthetically generated media often devised with malicious intent. They have become increasingly more convincing with large training datasets advanced neural networks. These fakes are readily being misused for slander, misinformation and fraud. For this reason, intensive research for developing countermeasures is also expanding. However, recent work is almost exclusively limited to deepfake detection - predicting if audio is real or fake. This is despite the fact that attribution (who created which fake?) is an essential building block of a larger defense strategy, as practiced in the field of cybersecurity for a long time. This paper considers the problem of deepfake attacker attribution in the domain of audio. We present several methods for creating attacker signatures using low-level acoustic descriptors and machine learning embeddings. We show that speech signal features are inadequate for characterizing attacker signatures. However, we also demonstrate that embeddings from a recurrent neural network can successfully characterize attacks from both known and unknown attackers. Our attack signature embeddings result in distinct clusters, both for seen and unseen audio deepfakes. We show that these embeddings can be used in downstream-tasks to high-effect, scoring 97.10% accuracy in attacker-id classification.
Improved Prosodic Clustering for Multispeaker and Speaker-independent Phoneme-level Prosody Control
Nov 19, 2021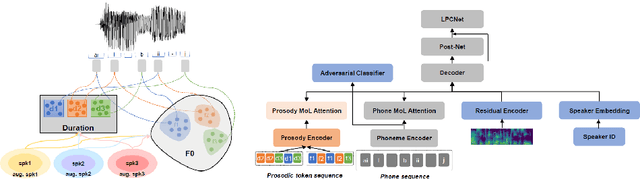
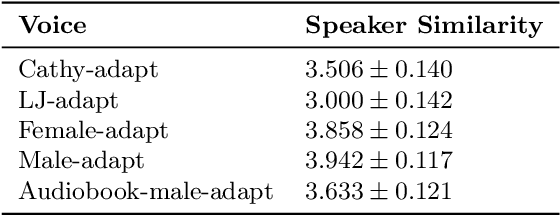
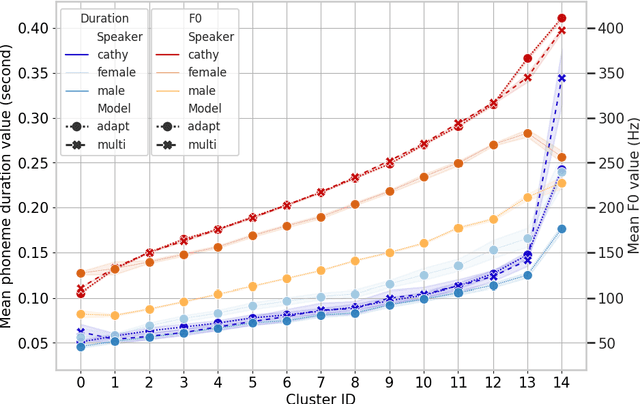
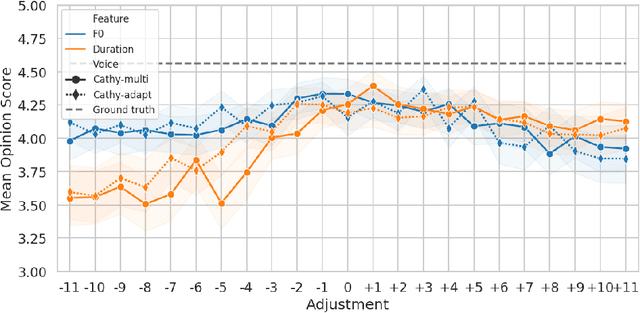
This paper presents a method for phoneme-level prosody control of F0 and duration on a multispeaker text-to-speech setup, which is based on prosodic clustering. An autoregressive attention-based model is used, incorporating multispeaker architecture modules in parallel to a prosody encoder. Several improvements over the basic single-speaker method are proposed that increase the prosodic control range and coverage. More specifically we employ data augmentation, F0 normalization, balanced clustering for duration, and speaker-independent prosodic clustering. These modifications enable fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. The model is also fine-tuned to unseen speakers with limited amounts of data and it is shown to maintain its prosody control capabilities, verifying that the speaker-independent prosodic clustering is effective. Experimental results verify that the model maintains high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.
Joint Spatio-Temporal Discretisation of Nonlinear Active Cochlear Models
Aug 12, 2021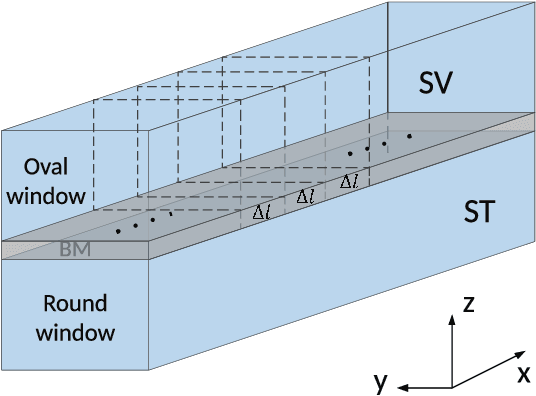
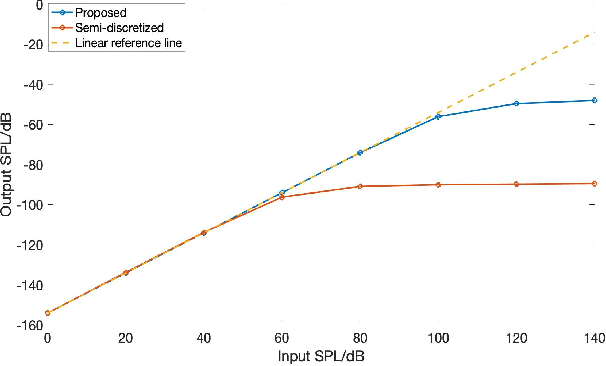
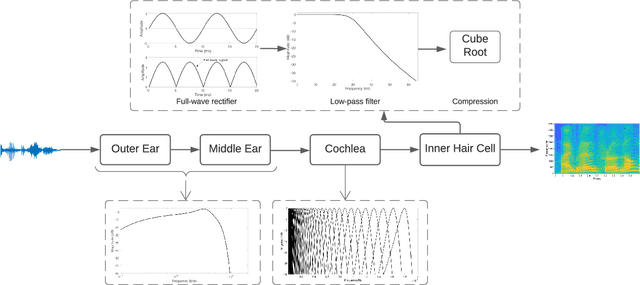
Biologically inspired auditory models play an important role in developing effective audio representations that can be tightly integrated into speech and audio processing systems. Current computational models of the cochlea are typically expressed in terms of systems of differential equations and do not directly lend themselves for use in computational speech processing systems. Specifically, these models are spatially discrete and temporally continuous. This paper presents a jointly discretised (spatially and temporally discrete) model of the cochlea which allows for processing at fixed time intervals suited to discrete time speech and audio processing systems. The proposed model takes into account the active feedback mechanism in the cochlea, a core characteristic lacking in traditional speech processing front-ends, which endows it with significant dynamic range compression capability. This model is derived by jointly discretising an established semi-discretised (spatially discrete and temporally continuous) cochlear model in a state space form. We then demonstrate that the proposed jointly discretised implementation matches the semi-discrete model in terms of its characteristics and finally present stability analyses of the proposed model.