 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Cepstrum: Pitch Modification for Mel-Based Neural Vocoders
Dec 18, 2025



This paper introduces a cepstrum-based pitch modification method that can be applied to any mel-spectrogram representation. As a result, this method is compatible with any mel-based vocoder without requiring any additional training or changes to the model. This is achieved by directly modifying the cepstrum feature space in order to shift the harmonic structure to the desired target. The spectrogram magnitude is computed via the pseudo-inverse mel transform, then converted to the cepstrum by applying DCT. In this domain, the cepstral peak is shifted without having to estimate its position and the modified mel is recomputed by applying IDCT and mel-filterbank. These pitch-shifted mel-spectrogram features can be converted to speech with any compatible vocoder. The proposed method is validated experimentally with objective and subjective metrics on various state-of-the-art neural vocoders as well as in comparison with traditional pitch modification methods.
Investigating Disentanglement in a Phoneme-level Speech Codec for Prosody Modeling
Sep 13, 2024



Most of the prevalent approaches in speech prosody modeling rely on learning global style representations in a continuous latent space which encode and transfer the attributes of reference speech. However, recent work on neural codecs which are based on Residual Vector Quantization (RVQ) already shows great potential offering distinct advantages. We investigate the prosody modeling capabilities of the discrete space of such an RVQ-VAE model, modifying it to operate on the phoneme-level. We condition both the encoder and decoder of the model on linguistic representations and apply a global speaker embedding in order to factor out both phonetic and speaker information. We conduct an extensive set of investigations based on subjective experiments and objective measures to show that the phoneme-level discrete latent representations obtained this way achieves a high degree of disentanglement, capturing fine-grained prosodic information that is robust and transferable. The latent space turns out to have interpretable structure with its principal components corresponding to pitch and energy.
Improved Text Emotion Prediction Using Combined Valence and Arousal Ordinal Classification
Apr 02, 2024



Emotion detection in textual data has received growing interest in recent years, as it is pivotal for developing empathetic human-computer interaction systems. This paper introduces a method for categorizing emotions from text, which acknowledges and differentiates between the diversified similarities and distinctions of various emotions. Initially, we establish a baseline by training a transformer-based model for standard emotion classification, achieving state-of-the-art performance. We argue that not all misclassifications are of the same importance, as there are perceptual similarities among emotional classes. We thus redefine the emotion labeling problem by shifting it from a traditional classification model to an ordinal classification one, where discrete emotions are arranged in a sequential order according to their valence levels. Finally, we propose a method that performs ordinal classification in the two-dimensional emotion space, considering both valence and arousal scales. The results show that our approach not only preserves high accuracy in emotion prediction but also significantly reduces the magnitude of errors in cases of misclassification.
Low-Resource Cross-Domain Singing Voice Synthesis via Reduced Self-Supervised Speech Representations
Feb 02, 2024



In this paper, we propose a singing voice synthesis model, Karaoker-SSL, that is trained only on text and speech data as a typical multi-speaker acoustic model. It is a low-resource pipeline that does not utilize any singing data end-to-end, since its vocoder is also trained on speech data. Karaoker-SSL is conditioned by self-supervised speech representations in an unsupervised manner. We preprocess these representations by selecting only a subset of their task-correlated dimensions. The conditioning module is indirectly guided to capture style information during training by multi-tasking. This is achieved with a Conformer-based module, which predicts the pitch from the acoustic model's output. Thus, Karaoker-SSL allows singing voice synthesis without reliance on hand-crafted and domain-specific features. There are also no requirements for text alignments or lyrics timestamps. To refine the voice quality, we employ a U-Net discriminator that is conditioned on the target speaker and follows a Diffusion GAN training scheme.
Controllable speech synthesis by learning discrete phoneme-level prosodic representations
Nov 29, 2022



In this paper, we present a novel method for phoneme-level prosody control of F0 and duration using intuitive discrete labels. We propose an unsupervised prosodic clustering process which is used to discretize phoneme-level F0 and duration features from a multispeaker speech dataset. These features are fed as an input sequence of prosodic labels to a prosody encoder module which augments an autoregressive attention-based text-to-speech model. We utilize various methods in order to improve prosodic control range and coverage, such as augmentation, F0 normalization, balanced clustering for duration and speaker-independent clustering. The final model enables fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. Instead of relying on reference utterances for inference, we introduce a prior prosody encoder which learns the style of each speaker and enables speech synthesis without the requirement of reference audio. We also fine-tune the multispeaker model to unseen speakers with limited amounts of data, as a realistic application scenario and show that the prosody control capabilities are maintained, verifying that the speaker-independent prosodic clustering is effective. Experimental results show that the model has high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.
Investigating Content-Aware Neural Text-To-Speech MOS Prediction Using Prosodic and Linguistic Features
Nov 01, 2022



Current state-of-the-art methods for automatic synthetic speech evaluation are based on MOS prediction neural models. Such MOS prediction models include MOSNet and LDNet that use spectral features as input, and SSL-MOS that relies on a pretrained self-supervised learning model that directly uses the speech signal as input. In modern high-quality neural TTS systems, prosodic appropriateness with regard to the spoken content is a decisive factor for speech naturalness. For this reason, we propose to include prosodic and linguistic features as additional inputs in MOS prediction systems, and evaluate their impact on the prediction outcome. We consider phoneme level F0 and duration features as prosodic inputs, as well as Tacotron encoder outputs, POS tags and BERT embeddings as higher-level linguistic inputs. All MOS prediction systems are trained on SOMOS, a neural TTS-only dataset with crowdsourced naturalness MOS evaluations. Results show that the proposed additional features are beneficial in the MOS prediction task, by improving the predicted MOS scores' correlation with the ground truths, both at utterance-level and system-level predictions.
SOMOS: The Samsung Open MOS Dataset for the Evaluation of Neural Text-to-Speech Synthesis
Apr 06, 2022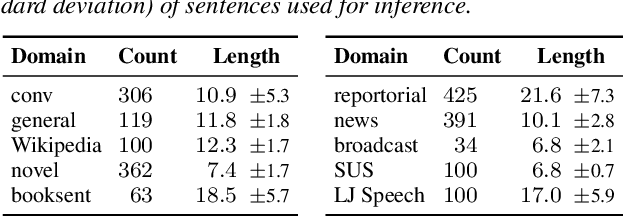
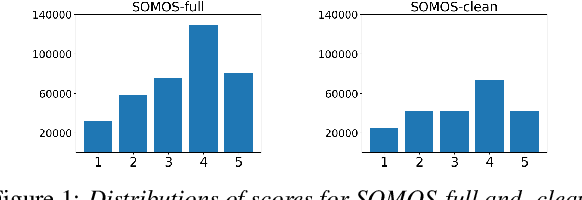
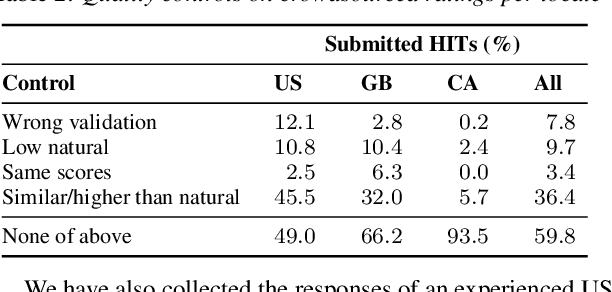
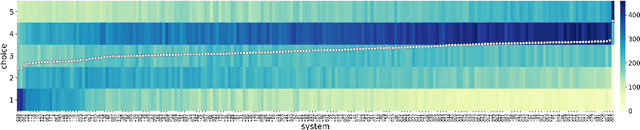
In this work, we present the SOMOS dataset, the first large-scale mean opinion scores (MOS) dataset consisting of solely neural text-to-speech (TTS) samples. It can be employed to train automatic MOS prediction systems focused on the assessment of modern synthesizers, and can stimulate advancements in acoustic model evaluation. It consists of 20K synthetic utterances of the LJ Speech voice, a public domain speech dataset which is a common benchmark for building neural acoustic models and vocoders. Utterances are generated from 200 TTS systems including vanilla neural acoustic models as well as models which allow prosodic variations. An LPCNet vocoder is used for all systems, so that the samples' variation depends only on the acoustic models. The synthesized utterances provide balanced and adequate domain and length coverage. We collect MOS naturalness evaluations on 3 English Amazon Mechanical Turk locales and share practices leading to reliable crowdsourced annotations for this task. Baseline results of state-of-the-art MOS prediction models on the SOMOS dataset are presented, while we show the challenges that such models face when assigned to evaluate synthetic utterances.
Prosodic Clustering for Phoneme-level Prosody Control in End-to-End Speech Synthesis
Nov 19, 2021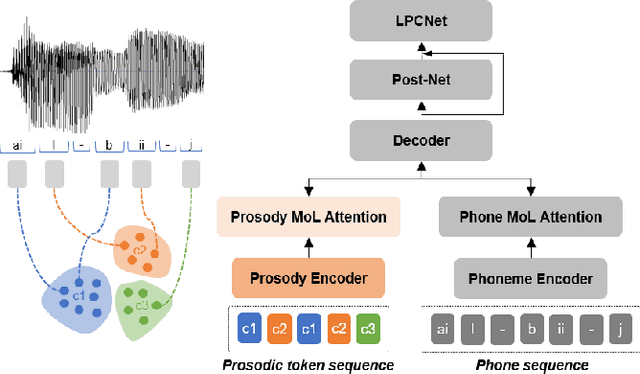
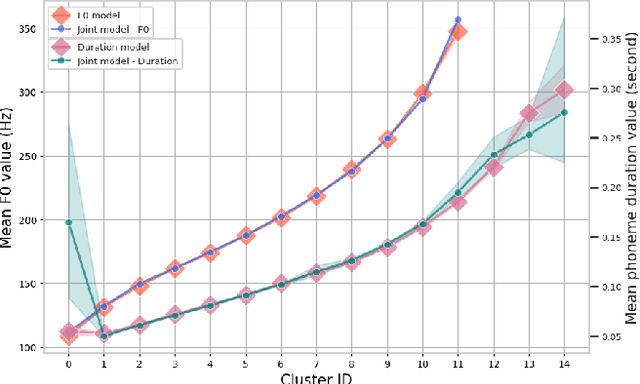
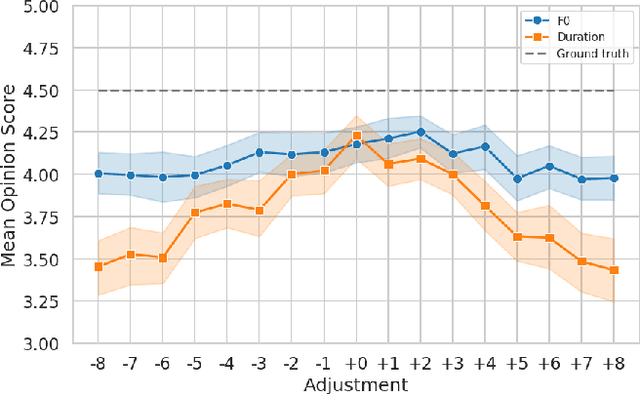
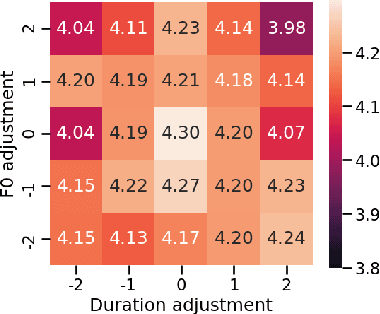
This paper presents a method for controlling the prosody at the phoneme level in an autoregressive attention-based text-to-speech system. Instead of learning latent prosodic features with a variational framework as is commonly done, we directly extract phoneme-level F0 and duration features from the speech data in the training set. Each prosodic feature is discretized using unsupervised clustering in order to produce a sequence of prosodic labels for each utterance. This sequence is used in parallel to the phoneme sequence in order to condition the decoder with the utilization of a prosodic encoder and a corresponding attention module. Experimental results show that the proposed method retains the high quality of generated speech, while allowing phoneme-level control of F0 and duration. By replacing the F0 cluster centroids with musical notes, the model can also provide control over the note and octave within the range of the speaker.
Improved Prosodic Clustering for Multispeaker and Speaker-independent Phoneme-level Prosody Control
Nov 19, 2021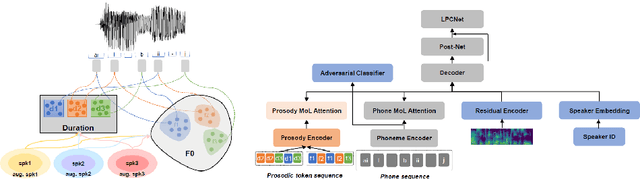
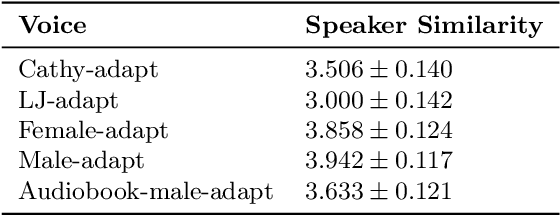
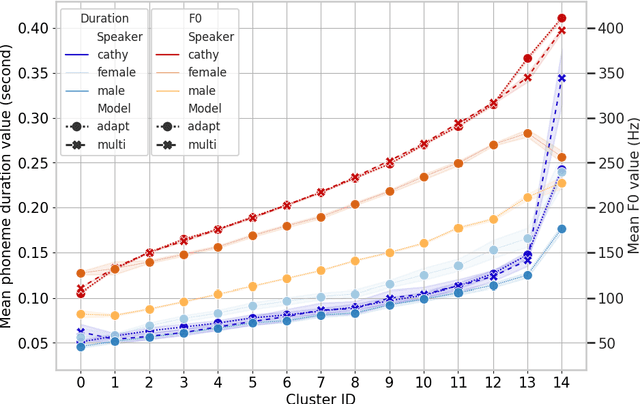
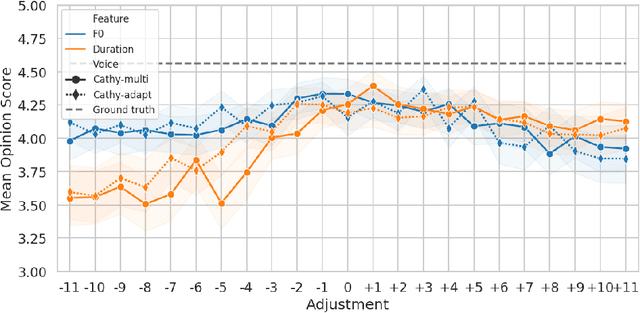
This paper presents a method for phoneme-level prosody control of F0 and duration on a multispeaker text-to-speech setup, which is based on prosodic clustering. An autoregressive attention-based model is used, incorporating multispeaker architecture modules in parallel to a prosody encoder. Several improvements over the basic single-speaker method are proposed that increase the prosodic control range and coverage. More specifically we employ data augmentation, F0 normalization, balanced clustering for duration, and speaker-independent prosodic clustering. These modifications enable fine-grained phoneme-level prosody control for all speakers contained in the training set, while maintaining the speaker identity. The model is also fine-tuned to unseen speakers with limited amounts of data and it is shown to maintain its prosody control capabilities, verifying that the speaker-independent prosodic clustering is effective. Experimental results verify that the model maintains high output speech quality and that the proposed method allows efficient prosody control within each speaker's range despite the variability that a multispeaker setting introduces.
Rapping-Singing Voice Synthesis based on Phoneme-level Prosody Control
Nov 17, 2021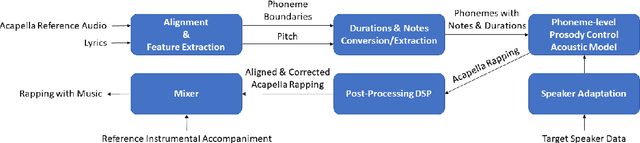
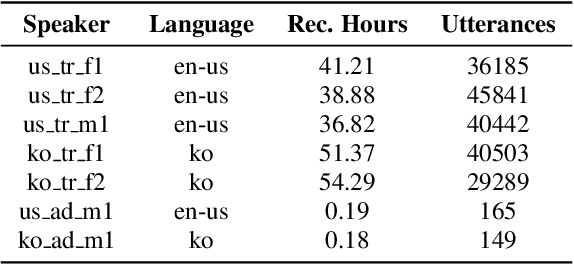
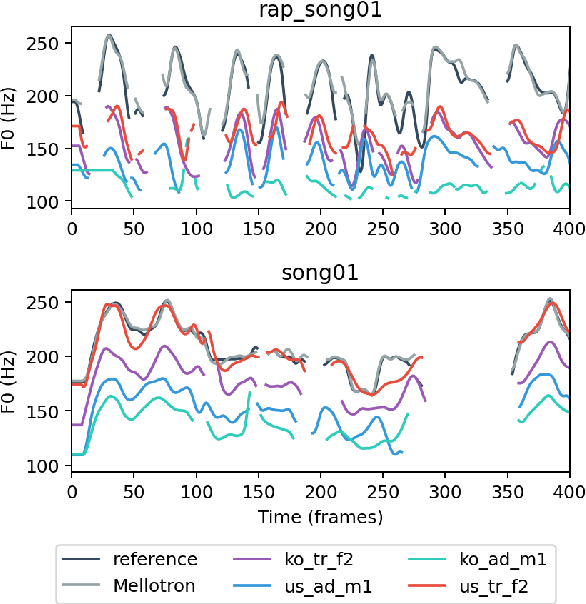
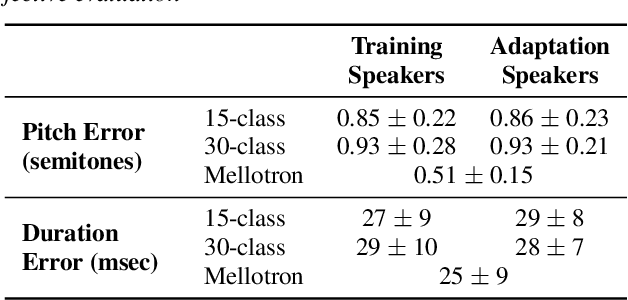
In this paper, a text-to-rapping/singing system is introduced, which can be adapted to any speaker's voice. It utilizes a Tacotron-based multispeaker acoustic model trained on read-only speech data and which provides prosody control at the phoneme level. Dataset augmentation and additional prosody manipulation based on traditional DSP algorithms are also investigated. The neural TTS model is fine-tuned to an unseen speaker's limited recordings, allowing rapping/singing synthesis with the target's speaker voice. The detailed pipeline of the system is described, which includes the extraction of the target pitch and duration values from an a capella song and their conversion into target speaker's valid range of notes before synthesis. An additional stage of prosodic manipulation of the output via WSOLA is also investigated for better matching the target duration values. The synthesized utterances can be mixed with an instrumental accompaniment track to produce a complete song. The proposed system is evaluated via subjective listening tests as well as in comparison to an available alternate system which also aims to produce synthetic singing voice from read-only training data. Results show that the proposed approach can produce high quality rapping/singing voice with increased naturalness.