 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
HAIDA: Biometric technological therapy tools for neurorehabilitation of Cognitive Impairment
Mar 09, 2022
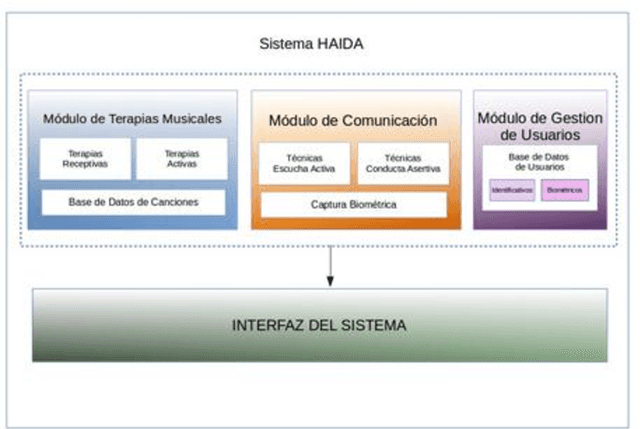
Dementia, and specially Alzheimer s disease (AD) and Mild Cognitive Impairment (MCI) are one of the most important diseases suffered by elderly population. Music therapy is one of the most widely used non-pharmacological treatment in the field of cognitive impairments, given that music influences their mood, behavior, the decrease of anxiety, as well as facilitating reminiscence, emotional expressions and movement. In this work we present HAIDA, a multi-platform support system for Musical Therapy oriented to cognitive impairment, which includes not only therapy tools but also non-invasive biometric analysis, speech, activity and hand activity. At this moment the system is on use and recording the first sets of data.
* 2 pages
3M: Multi-loss, Multi-path and Multi-level Neural Networks for speech recognition
Apr 07, 2022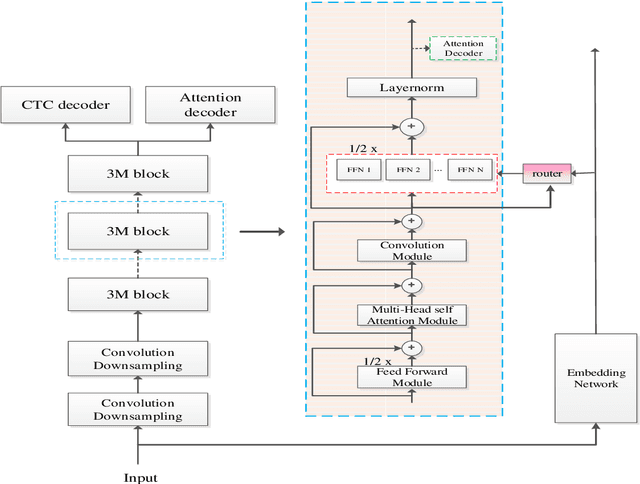
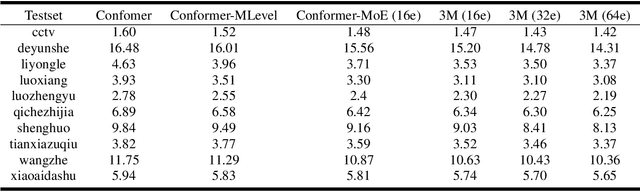
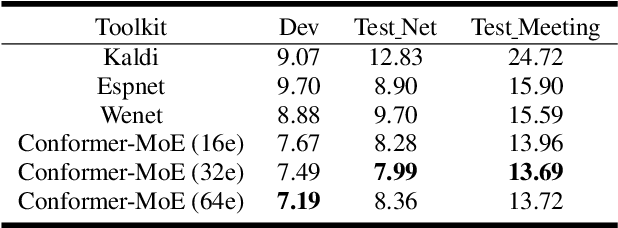
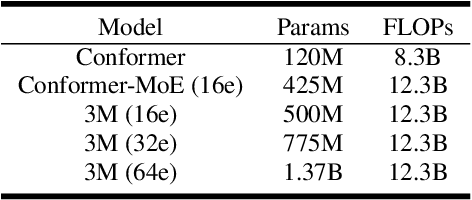
Recently, Conformer based CTC/AED model has become a mainstream architecture for ASR. In this paper, based on our prior work, we identify and integrate several approaches to achieve further improvements for ASR tasks, which we denote as multi-loss, multi-path and multi-level, summarized as "3M" model. Specifically, multi-loss refers to the joint CTC/AED loss and multi-path denotes the Mixture-of-Experts(MoE) architecture which can effectively increase the model capacity without remarkably increasing computation cost. Multi-level means that we introduce auxiliary loss at multiple level of a deep model to help training. We evaluate our proposed method on the public WenetSpeech dataset and experimental results show that the proposed method provides 12.2%-17.6% relative CER improvement over the baseline model trained by Wenet toolkit. On our large scale dataset of 150k hours corpus, the 3M model has also shown obvious superiority over the baseline Conformer model.
Do face masks introduce bias in speech technologies? The case of automated scoring of speaking proficiency
Aug 17, 2020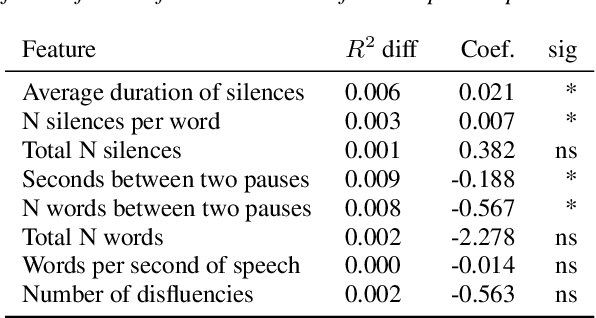
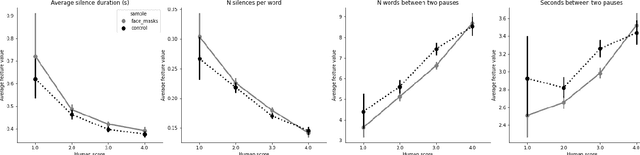
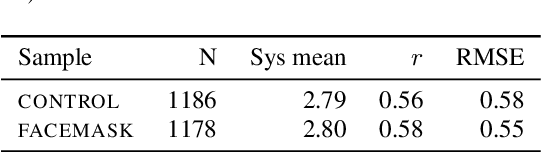
The COVID-19 pandemic has led to a dramatic increase in the use of face masks worldwide. Face coverings can affect both acoustic properties of the signal as well as speech patterns and have unintended effects if the person wearing the mask attempts to use speech processing technologies. In this paper we explore the impact of wearing face masks on the automated assessment of English language proficiency. We use a dataset from a large-scale speaking test for which test-takers were required to wear face masks during the test administration, and we compare it to a matched control sample of test-takers who took the same test before the mask requirements were put in place. We find that the two samples differ across a range of acoustic measures and also show a small but significant difference in speech patterns. However, these differences do not lead to differences in human or automated scores of English language proficiency. Several measures of bias showed no differences in scores between the two groups.
Multi-head Monotonic Chunkwise Attention For Online Speech Recognition
May 01, 2020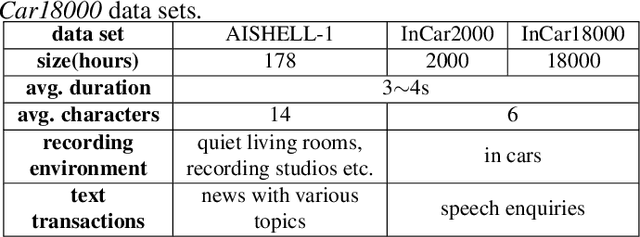
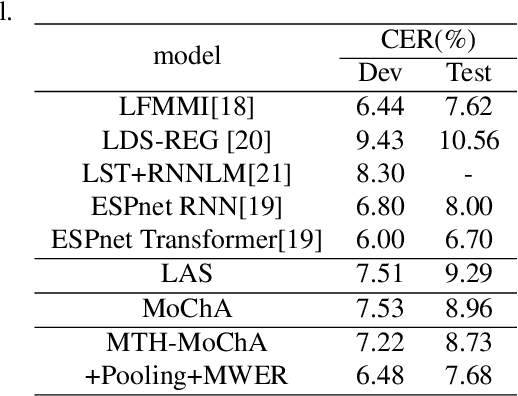
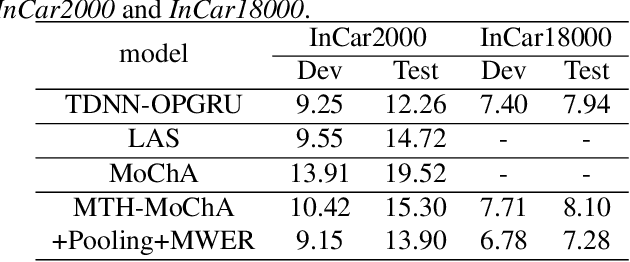
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.
End-to-End Multi-Speaker Speech Recognition using Speaker Embeddings and Transfer Learning
Aug 13, 2019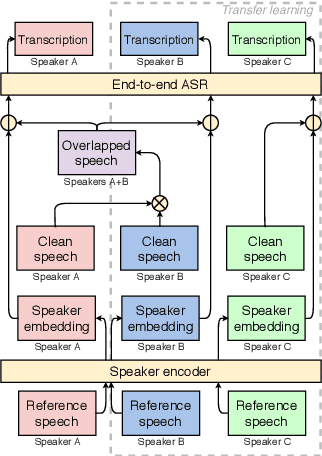

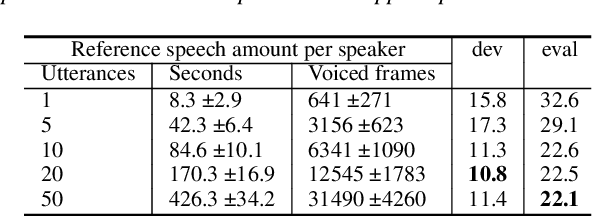
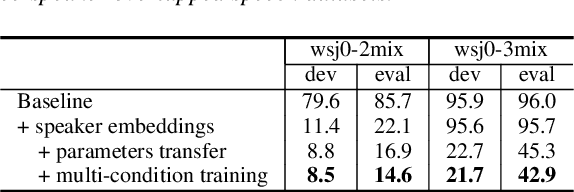
This paper presents our latest investigation on end-to-end automatic speech recognition (ASR) for overlapped speech. We propose to train an end-to-end system conditioned on speaker embeddings and further improved by transfer learning from clean speech. This proposed framework does not require any parallel non-overlapped speech materials and is independent of the number of speakers. Our experimental results on overlapped speech datasets show that joint conditioning on speaker embeddings and transfer learning significantly improves the ASR performance.
Transformer-based Online CTC/attention End-to-End Speech Recognition Architecture
Jan 15, 2020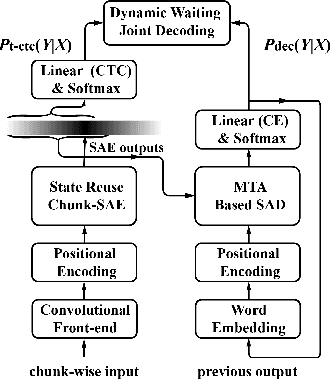

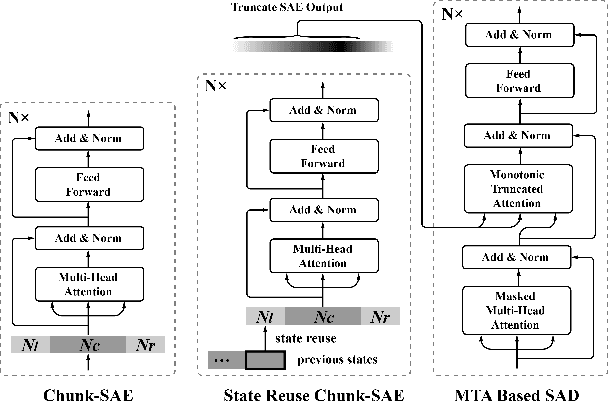
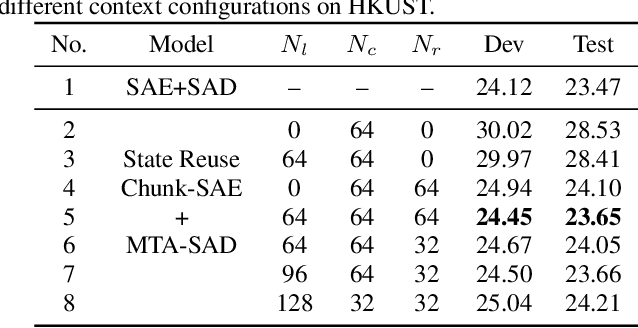
Recently, Transformer has gained success in automatic speech recognition (ASR) field. However, it is challenging to deploy a Transformer-based end-to-end (E2E) model for online speech recognition. In this paper, we propose the Transformer-based online CTC/attention E2E ASR architecture, which contains the chunk self-attention encoder (chunk-SAE) and the monotonic truncated attention (MTA) based self-attention decoder (SAD). Firstly, the chunk-SAE splits the speech into isolated chunks. To reduce the computational cost and improve the performance, we propose the state reuse chunk-SAE. Sencondly, the MTA based SAD truncates the speech features monotonically and performs attention on the truncated features. To support the online recognition, we integrate the state reuse chunk-SAE and the MTA based SAD into online CTC/attention architecture. We evaluate the proposed online models on the HKUST Mandarin ASR benchmark and achieve a 23.66% character error rate (CER) with a 320 ms latency. Our online model yields as little as $0.19\%$ absolute CER degradation compared with the offline baseline, and achieves significant improvement over our prior work on Long Short-Term Memory (LSTM) based online E2E models.
Looking Enhances Listening: Recovering Missing Speech Using Images
Feb 13, 2020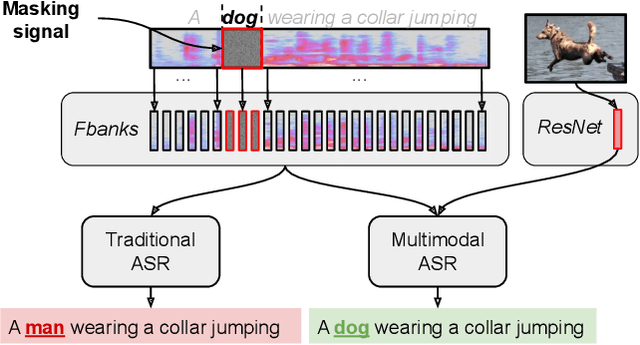
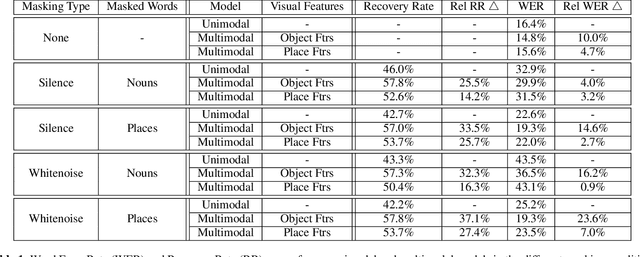
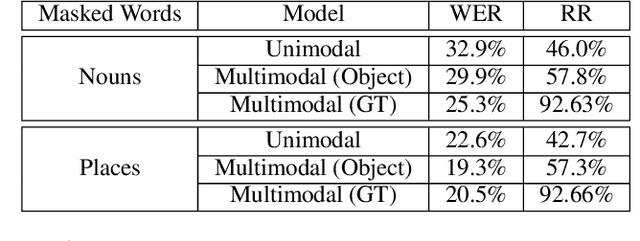

Speech is understood better by using visual context; for this reason, there have been many attempts to use images to adapt automatic speech recognition (ASR) systems. Current work, however, has shown that visually adapted ASR models only use images as a regularization signal, while completely ignoring their semantic content. In this paper, we present a set of experiments where we show the utility of the visual modality under noisy conditions. Our results show that multimodal ASR models can recover words which are masked in the input acoustic signal, by grounding its transcriptions using the visual representations. We observe that integrating visual context can result in up to 35% relative improvement in masked word recovery. These results demonstrate that end-to-end multimodal ASR systems can become more robust to noise by leveraging the visual context.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022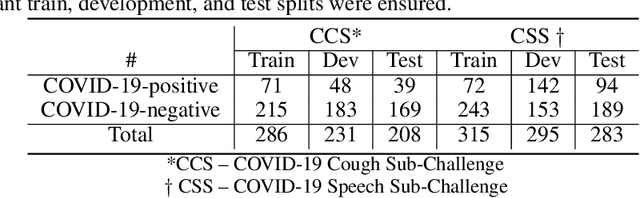
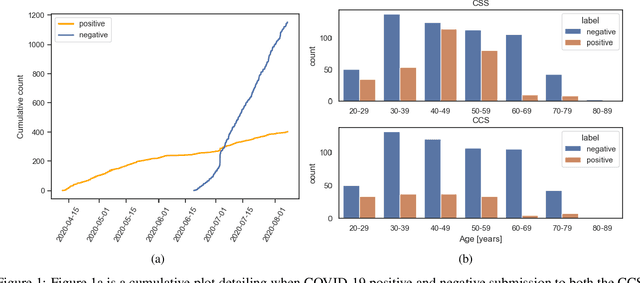
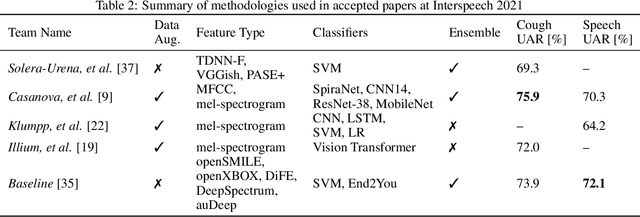
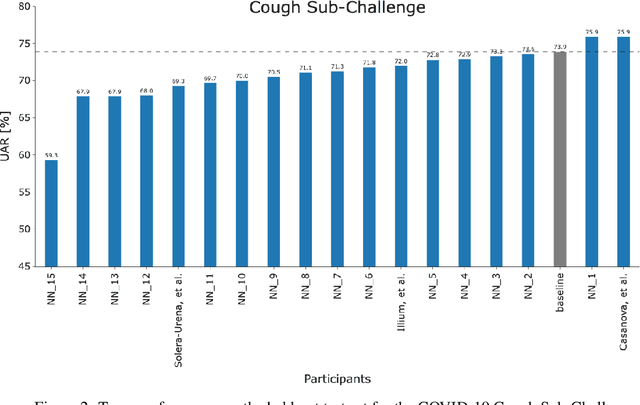
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
A 14uJ/Decision Keyword Spotting Accelerator with In-SRAM-Computing and On Chip Learning for Customization
May 10, 2022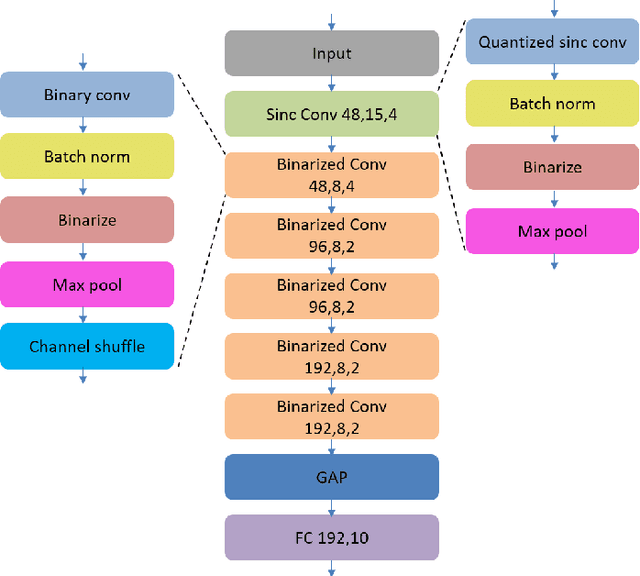
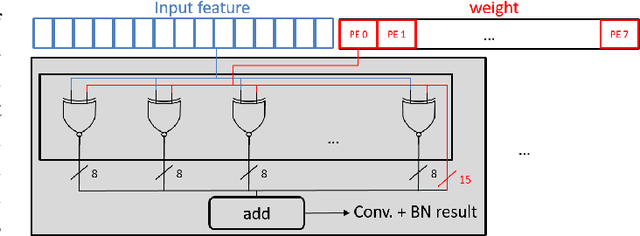
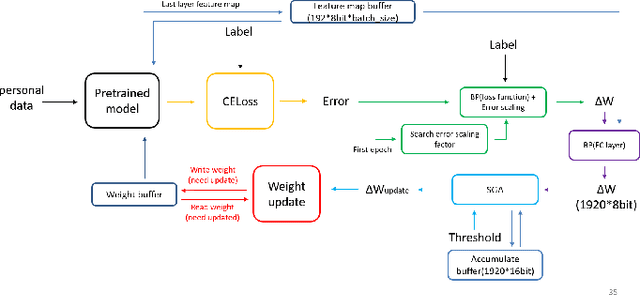
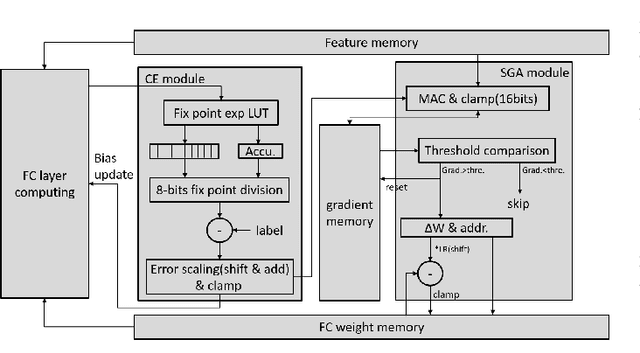
Keyword spotting has gained popularity as a natural way to interact with consumer devices in recent years. However, because of its always-on nature and the variety of speech, it necessitates a low-power design as well as user customization. This paper describes a low-power, energy-efficient keyword spotting accelerator with SRAM based in-memory computing (IMC) and on-chip learning for user customization. However, IMC is constrained by macro size, limited precision, and non-ideal effects. To address the issues mentioned above, this paper proposes bias compensation and fine-tuning using an IMC-aware model design. Furthermore, because learning with low-precision edge devices results in zero error and gradient values due to quantization, this paper proposes error scaling and small gradient accumulation to achieve the same accuracy as ideal model training. The simulation results show that with user customization, we can recover the accuracy loss from 51.08\% to 89.76\% with compensation and fine-tuning and further improve to 96.71\% with customization. The chip implementation can successfully run the model with only 14$uJ$ per decision. When compared to the state-of-the-art works, the presented design has higher energy efficiency with additional on-chip model customization capabilities for higher accuracy.
Low Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019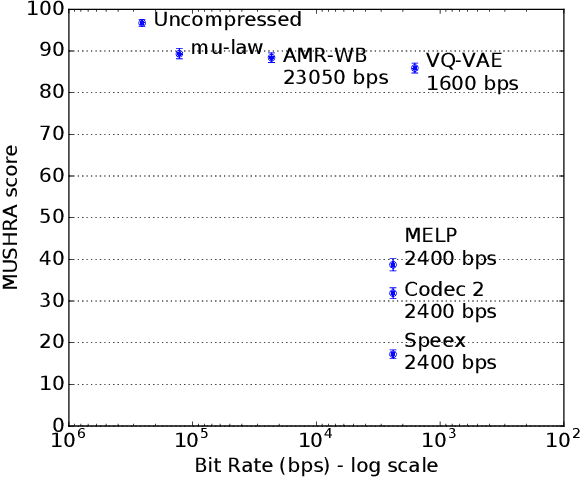
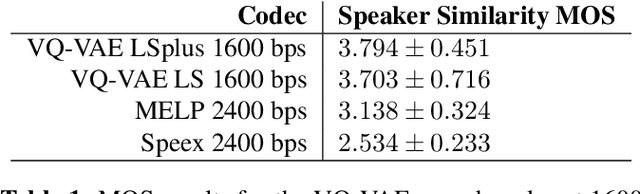
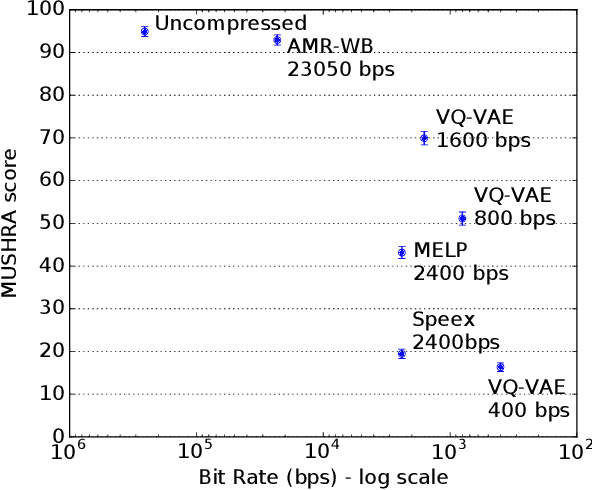
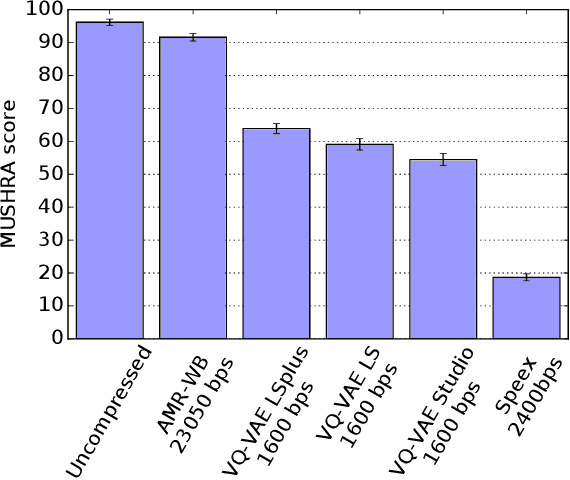
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019