 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-head Monotonic Chunkwise Attention For Online Speech Recognition
Paper and Code
May 01, 2020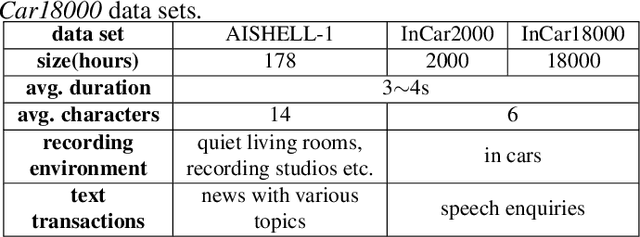
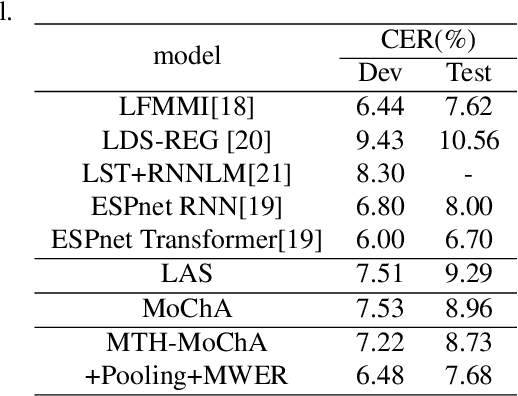
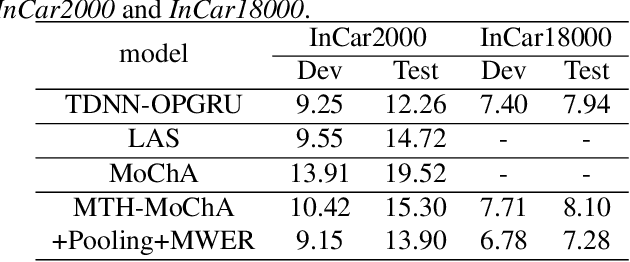
The attention mechanism of the Listen, Attend and Spell (LAS) model requires the whole input sequence to calculate the attention context and thus is not suitable for online speech recognition. To deal with this problem, we propose multi-head monotonic chunk-wise attention (MTH-MoChA), an improved version of MoChA. MTH-MoChA splits the input sequence into small chunks and computes multi-head attentions over the chunks. We also explore useful training strategies such as LSTM pooling, minimum world error rate training and SpecAugment to further improve the performance of MTH-MoChA. Experiments on AISHELL-1 data show that the proposed model, along with the training strategies, improve the character error rate (CER) of MoChA from 8.96% to 7.68% on test set. On another 18000 hours in-car speech data set, MTH-MoChA obtains 7.28% CER, which is significantly better than a state-of-the-art hybrid system.