 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Decoding Imagined Speech and Computer Control using Brain Waves
Nov 08, 2019
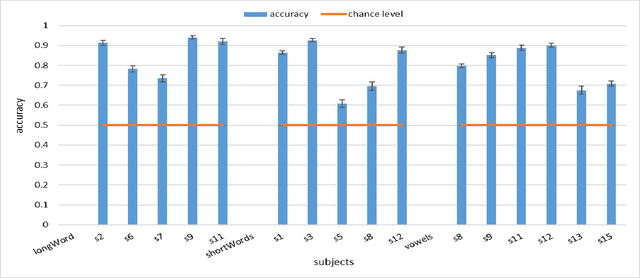
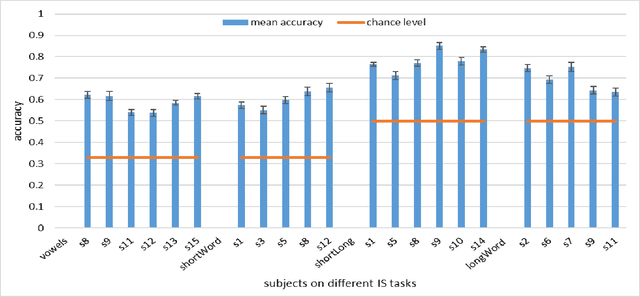
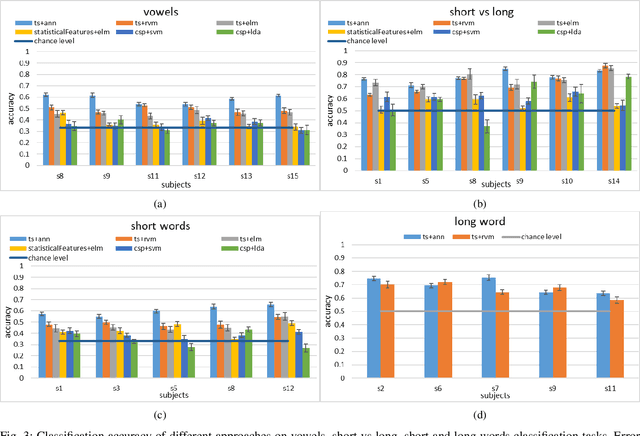
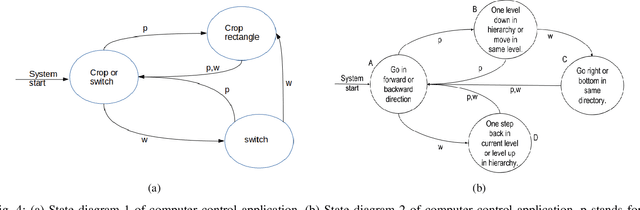
In this work, we explore the possibility of decoding Imagined Speech brain waves using machine learning techniques. We propose a covariance matrix of Electroencephalogram channels as input features, projection to tangent space of covariance matrices for obtaining vectors from covariance matrices, principal component analysis for dimension reduction of vectors, an artificial feed-forward neural network as a classification model and bootstrap aggregation for creating an ensemble of neural network models. After the classification, two different Finite State Machines are designed that create an interface for controlling a computer system using an Imagined Speech-based BCI system. The proposed approach is able to decode the Imagined Speech signal with a maximum mean classification accuracy of 85% on binary classification task of one long word and a short word. We also show that our proposed approach is able to differentiate between imagined speech brain signals and rest state brain signals with maximum mean classification accuracy of 94%. We compared our proposed method with other approaches for decoding imagined speech and show that our approach performs equivalent to the state of the art approach on decoding long vs. short words and outperforms it significantly on the other two tasks of decoding three short words and three vowels with an average margin of 11% and 9%, respectively. We also obtain an information transfer rate of 21-bits-per-minute when using an IS based system to operate a computer. These results show that the proposed approach is able to decode a wide variety of imagined speech signals without any human-designed features.
Optimizing Tandem Speaker Verification and Anti-Spoofing Systems
Jan 24, 2022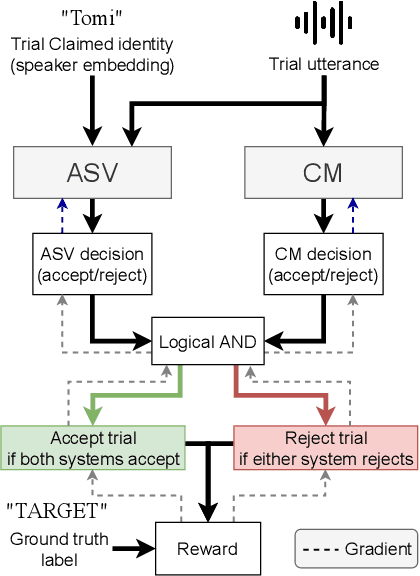
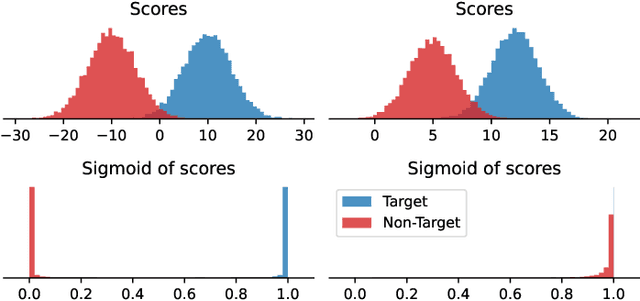
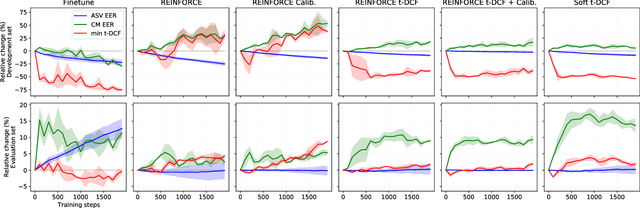

As automatic speaker verification (ASV) systems are vulnerable to spoofing attacks, they are typically used in conjunction with spoofing countermeasure (CM) systems to improve security. For example, the CM can first determine whether the input is human speech, then the ASV can determine whether this speech matches the speaker's identity. The performance of such a tandem system can be measured with a tandem detection cost function (t-DCF). However, ASV and CM systems are usually trained separately, using different metrics and data, which does not optimize their combined performance. In this work, we propose to optimize the tandem system directly by creating a differentiable version of t-DCF and employing techniques from reinforcement learning. The results indicate that these approaches offer better outcomes than finetuning, with our method providing a 20% relative improvement in the t-DCF in the ASVSpoof19 dataset in a constrained setting.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing. Published version available at: https://ieeexplore.ieee.org/document/9664367
An evaluation of word-level confidence estimation for end-to-end automatic speech recognition
Jan 14, 2021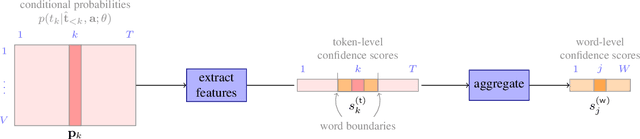
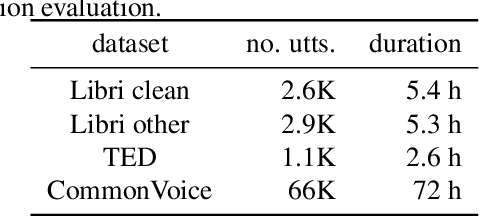
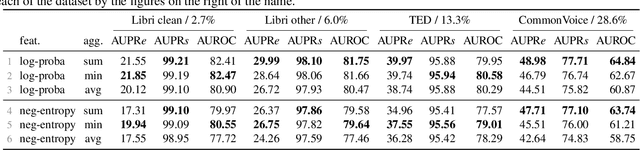
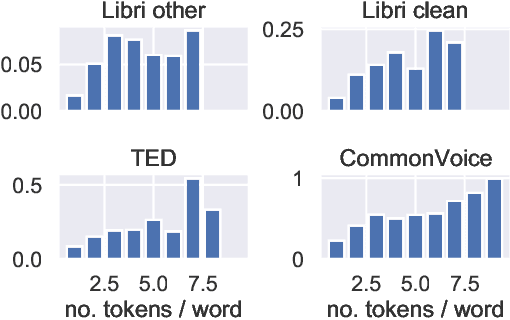
Quantifying the confidence (or conversely the uncertainty) of a prediction is a highly desirable trait of an automatic system, as it improves the robustness and usefulness in downstream tasks. In this paper we investigate confidence estimation for end-to-end automatic speech recognition (ASR). Previous work has addressed confidence measures for lattice-based ASR, while current machine learning research mostly focuses on confidence measures for unstructured deep learning. However, as the ASR systems are increasingly being built upon deep end-to-end methods, there is little work that tries to develop confidence measures in this context. We fill this gap by providing an extensive benchmark of popular confidence methods on four well-known speech datasets. There are two challenges we overcome in adapting existing methods: working on structured data (sequences) and obtaining confidences at a coarser level than the predictions (words instead of tokens). Our results suggest that a strong baseline can be obtained by scaling the logits by a learnt temperature, followed by estimating the confidence as the negative entropy of the predictive distribution and, finally, sum pooling to aggregate at word level.
GAN-Aimbots: Using Machine Learning for Cheating in First Person Shooters
May 14, 2022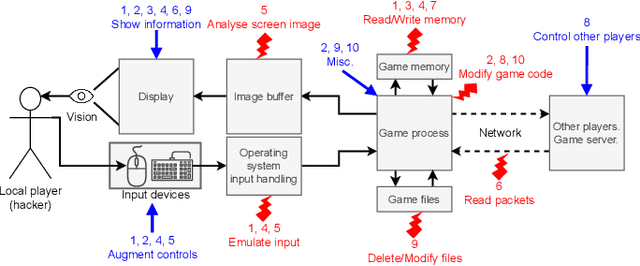
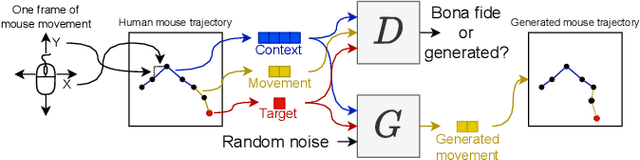
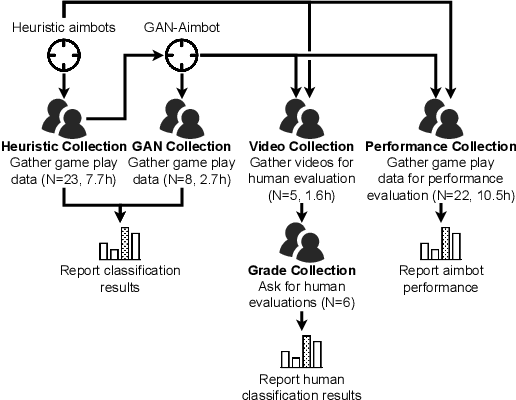
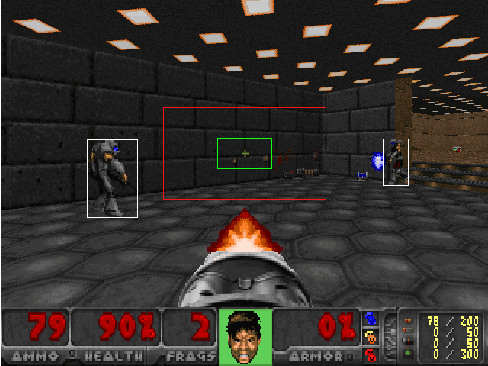
Playing games with cheaters is not fun, and in a multi-billion-dollar video game industry with hundreds of millions of players, game developers aim to improve the security and, consequently, the user experience of their games by preventing cheating. Both traditional software-based methods and statistical systems have been successful in protecting against cheating, but recent advances in the automatic generation of content, such as images or speech, threaten the video game industry; they could be used to generate artificial gameplay indistinguishable from that of legitimate human players. To better understand this threat, we begin by reviewing the current state of multiplayer video game cheating, and then proceed to build a proof-of-concept method, GAN-Aimbot. By gathering data from various players in a first-person shooter game we show that the method improves players' performance while remaining hidden from automatic and manual protection mechanisms. By sharing this work we hope to raise awareness on this issue and encourage further research into protecting the gaming communities.
Assem-VC: Realistic Voice Conversion by Assembling Modern Speech Synthesis Techniques
Apr 02, 2021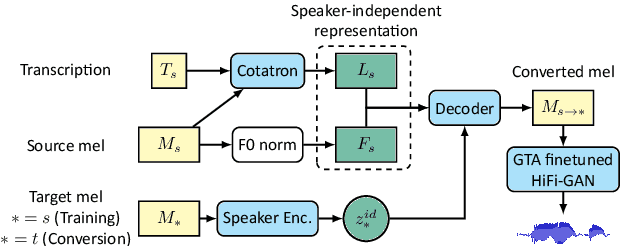
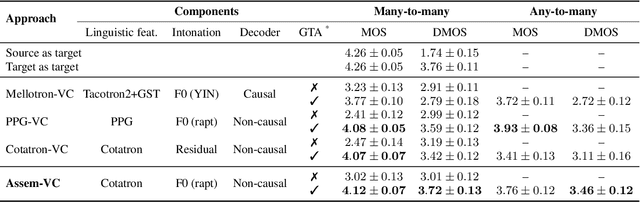
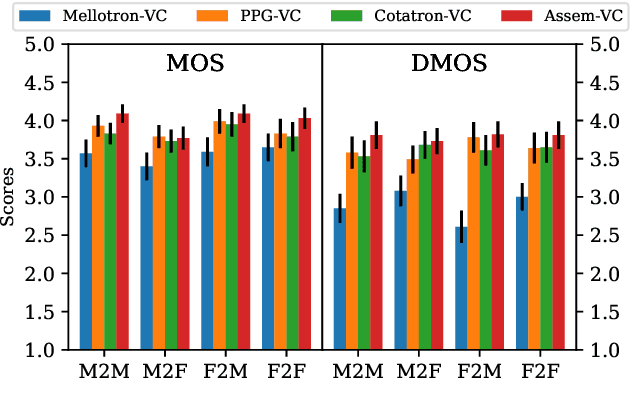

In this paper, we pose the current state-of-the-art voice conversion (VC) systems as two-encoder-one-decoder models. After comparing these models, we combine the best features and propose Assem-VC, a new state-of-the-art any-to-many non-parallel VC system. This paper also introduces the GTA finetuning in VC, which significantly improves the quality and the speaker similarity of the outputs. Assem-VC outperforms the previous state-of-the-art approaches in both the naturalness and the speaker similarity on the VCTK dataset. As an objective result, the degree of speaker disentanglement of features such as phonetic posteriorgrams (PPG) is also explored. Our investigation indicates that many-to-many VC results are no longer distinct from human speech and similar quality can be achieved with any-to-many models. Audio samples are available at https://mindslab-ai.github.io/assem-vc/
Directional Sparse Filtering using Weighted Lehmer Mean for Blind Separation of Unbalanced Speech Mixtures
Feb 02, 2021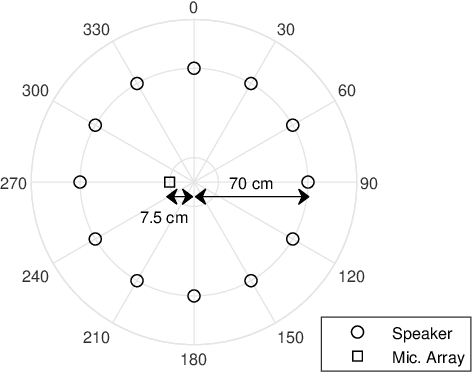
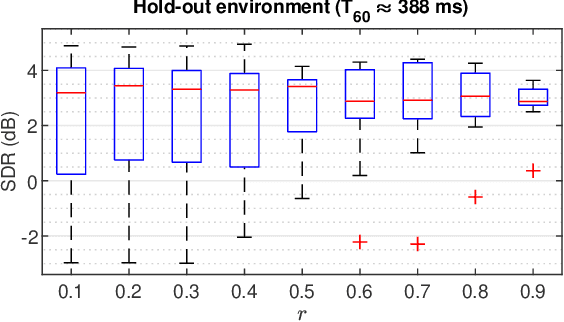
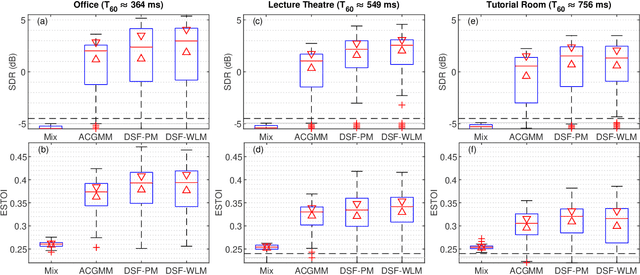
In blind source separation of speech signals, the inherent imbalance in the source spectrum poses a challenge for methods that rely on single-source dominance for the estimation of the mixing matrix. We propose an algorithm based on the directional sparse filtering (DSF) framework that utilizes the Lehmer mean with learnable weights to adaptively account for source imbalance. Performance evaluation in multiple real acoustic environments show improvements in source separation compared to the baseline methods.
Exploring Transformers for Large-Scale Speech Recognition
May 19, 2020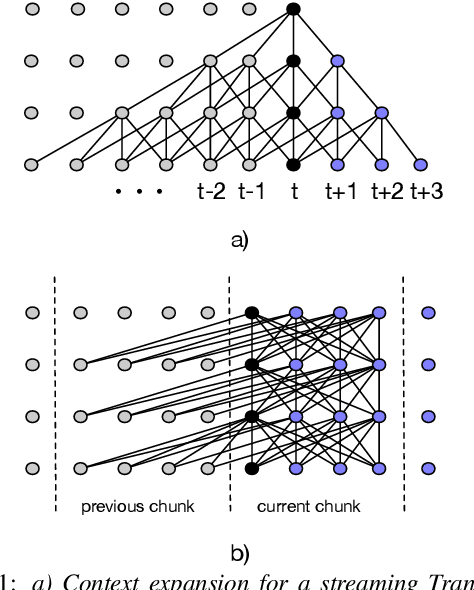
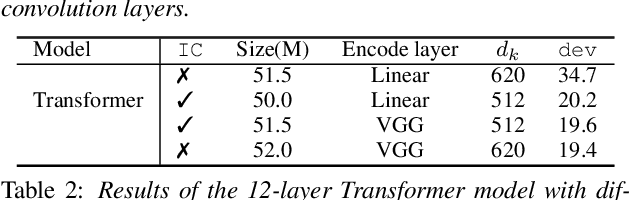
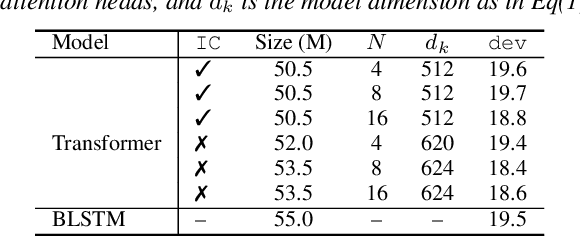
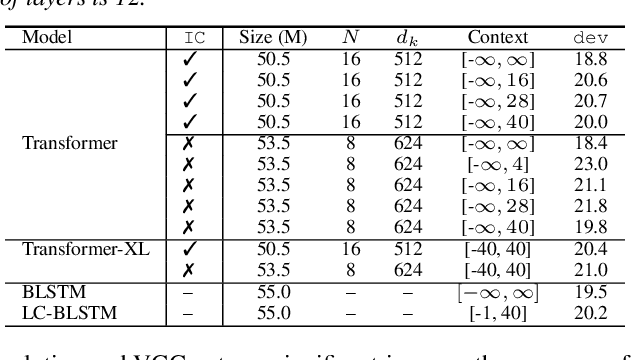
While recurrent neural networks still largely define state-of-the-art speech recognition systems, the Transformer network has been proven to be a competitive alternative, especially in the offline condition. Most studies with Transformers have been constrained in a relatively small scale setting, and some forms of data argumentation approaches are usually applied to combat the data sparsity issue. In this paper, we aim at understanding the behaviors of Transformers in the large-scale speech recognition setting, where we have used around 65,000 hours of training data. We investigated various aspects on scaling up Transformers, including model initialization, warmup training as well as different Layer Normalization strategies. In the streaming condition, we compared the widely used attention mask based future context lookahead approach to the Transformer-XL network. From our experiments, we show that Transformers can achieve around 6% relative word error rate (WER) reduction compared to the BLSTM baseline in the offline fashion, while in the streaming fashion, Transformer-XL is comparable to LC-BLSTM with 800 millisecond latency constraint.
Prosody Transfer in Neural Text to Speech Using Global Pitch and Loudness Features
Nov 21, 2019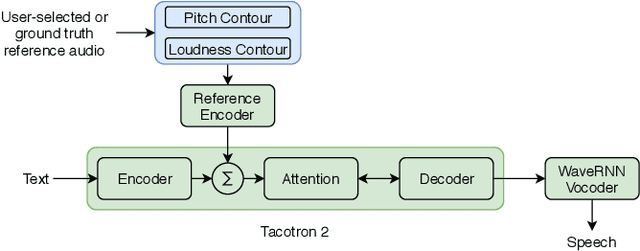
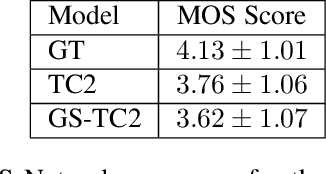

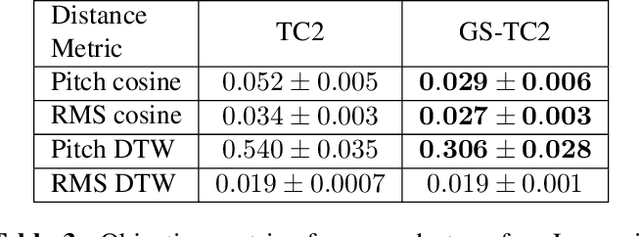
This paper presents a simple yet effective method to achieve prosody transfer from a reference speech signal to synthesized speech. The main idea is to incorporate well-known acoustic correlates of prosody such as pitch and loudness contours of the reference speech into a modern neural text-to-speech (TTS) synthesizer such as Tacotron2 (TC2). More specifically, a small set of acoustic features are extracted from the reference audio and then used to condition a TC2 synthesizer. The trained model is evaluated using subjective listening tests and novel objective evaluations of prosody transfer are proposed. Listening tests show that the synthesized speech is rated as highly natural and that prosody is successfully transferred from the reference speech signal to the synthesized signal.
Convolutional Speech Recognition with Pitch and Voice Quality Features
Sep 02, 2020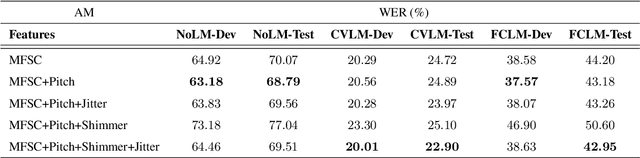
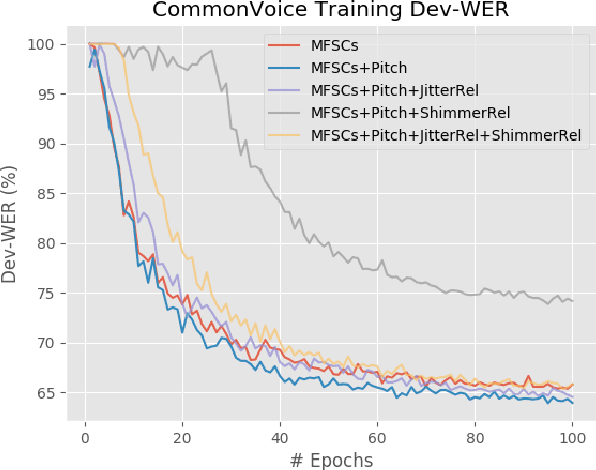
The effects of adding pitch and voice quality features such as jitter and shimmer to a state-of-the-art CNN model for Automatic Speech Recognition are studied in this work. Pitch features have been previously used for improving classical HMM and DNN baselines, while jitter and shimmer parameters have proven to be useful for tasks like speaker or emotion recognition. Up to our knowledge, this is the first work combining such pitch and voice quality features with modern convolutional architectures, showing improvements up to 2% absolute WER points, for the publicly available Spanish Common Voice dataset. Particularly, our work combines these features with mel-frequency spectral coefficients (MFSCs) to train a convolutional architecture with Gated Linear Units (Conv GLUs). Such models have shown to yield small word error rates, while being very suitable for parallel processing for online streaming recognition use cases. We have added pitch and voice quality functionality to Facebook's wav2letter speech recognition framework, and we provide with such code and recipes to the community, to carry on with further experiments. Besides, to the best of our knowledge, our Spanish Common Voice recipe is the first public Spanish recipe for wav2letter.
The Theory behind Controllable Expressive Speech Synthesis: a Cross-disciplinary Approach
Oct 14, 2019
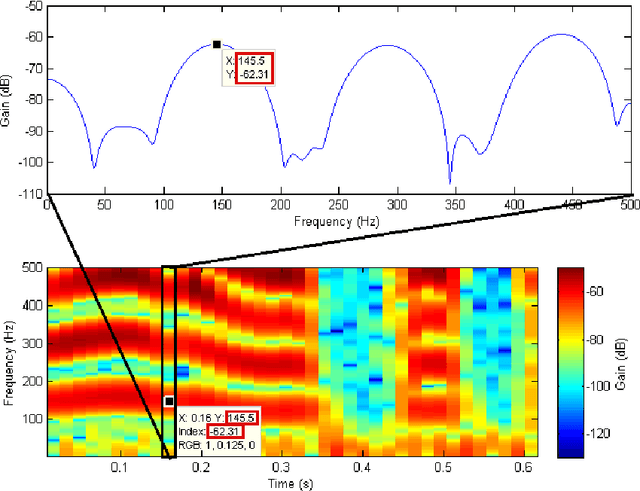
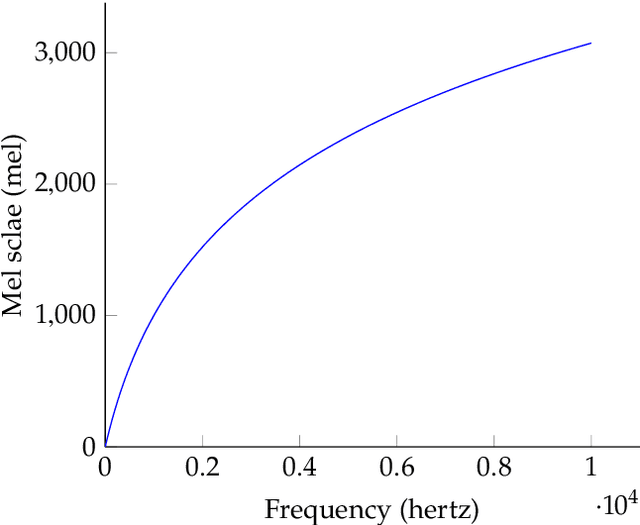
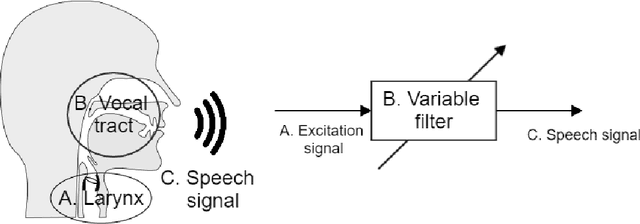
As part of the Human-Computer Interaction field, Expressive speech synthesis is a very rich domain as it requires knowledge in areas such as machine learning, signal processing, sociology, psychology. In this Chapter, we will focus mostly on the technical side. From the recording of expressive speech to its modeling, the reader will have an overview of the main paradigms used in this field, through some of the most prominent systems and methods. We explain how speech can be represented and encoded with audio features. We present a history of the main methods of Text-to-Speech synthesis: concatenative, parametric and statistical parametric speech synthesis. Finally, we focus on the last one, with the last techniques modeling Text-to-Speech synthesis as a sequence-to-sequence problem. This enables the use of Deep Learning blocks such as Convolutional and Recurrent Neural Networks as well as Attention Mechanism. The last part of the Chapter intends to assemble the different aspects of the theory and summarize the concepts.