Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Sparse Filtering using Weighted Lehmer Mean for Blind Separation of Unbalanced Speech Mixtures
Paper and Code
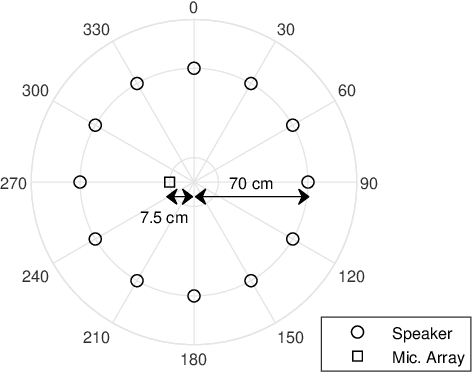
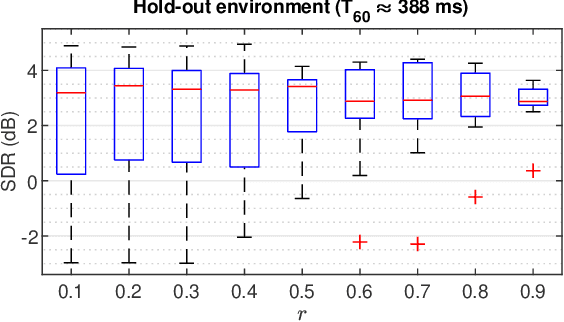
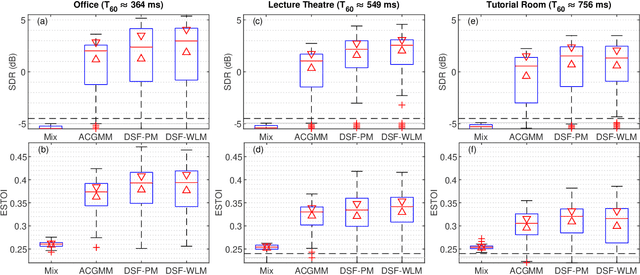
In blind source separation of speech signals, the inherent imbalance in the source spectrum poses a challenge for methods that rely on single-source dominance for the estimation of the mixing matrix. We propose an algorithm based on the directional sparse filtering (DSF) framework that utilizes the Lehmer mean with learnable weights to adaptively account for source imbalance. Performance evaluation in multiple real acoustic environments show improvements in source separation compared to the baseline methods.
* (c) 2021 IEEE. Personal use of this material is permitted. Permission
from IEEE must be obtained for all other uses, in any current or future
media, including reprinting/republishing this material for advertising or
promotional purposes, creating new collective works, for resale or
redistribution to servers or lists, or reuse of any copyrighted component of
this work in other works
View paper on