 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications
Mar 31, 2022
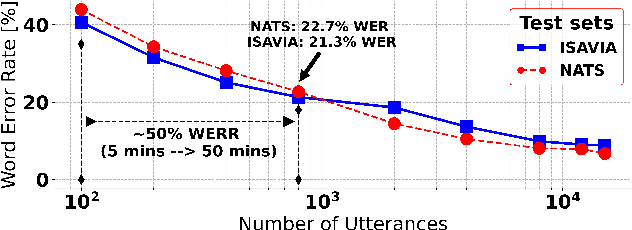
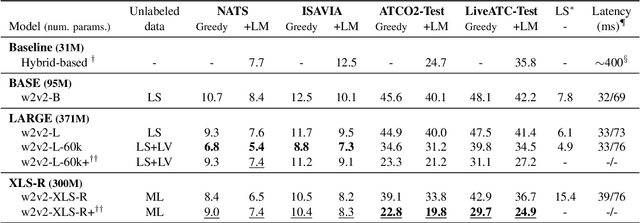
Recent work on self-supervised pre-training focus on leveraging large-scale unlabeled speech data to build robust end-to-end (E2E) acoustic models (AM) that can be later fine-tuned on downstream tasks e.g., automatic speech recognition (ASR). Yet, few works investigated the impact on performance when the data substantially differs between the pre-training and downstream fine-tuning phases (i.e., domain shift). We target this scenario by analyzing the robustness of Wav2Vec2.0 and XLS-R models on downstream ASR for a completely unseen domain, i.e., air traffic control (ATC) communications. We benchmark the proposed models on four challenging ATC test sets (signal-to-noise ratio varies between 5 to 20 dB). Relative word error rate (WER) reduction between 20% to 40% are obtained in comparison to hybrid-based state-of-the-art ASR baselines by fine-tuning E2E acoustic models with a small fraction of labeled data. We also study the impact of fine-tuning data size on WERs, going from 5 minutes (few-shot) to 15 hours.
Knowledge Authoring with Factual English
Aug 05, 2022
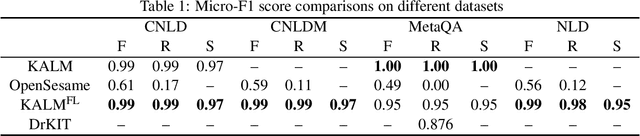

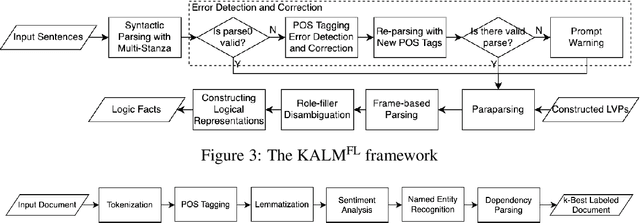
Knowledge representation and reasoning (KRR) systems represent knowledge as collections of facts and rules. Like databases, KRR systems contain information about domains of human activities like industrial enterprises, science, and business. KRRs can represent complex concepts and relations, and they can query and manipulate information in sophisticated ways. Unfortunately, the KRR technology has been hindered by the fact that specifying the requisite knowledge requires skills that most domain experts do not have, and professional knowledge engineers are hard to find. One solution could be to extract knowledge from English text, and a number of works have attempted to do so (OpenSesame, Google's Sling, etc.). Unfortunately, at present, extraction of logical facts from unrestricted natural language is still too inaccurate to be used for reasoning, while restricting the grammar of the language (so-called controlled natural language, or CNL) is hard for the users to learn and use. Nevertheless, some recent CNL-based approaches, such as the Knowledge Authoring Logic Machine (KALM), have shown to have very high accuracy compared to others, and a natural question is to what extent the CNL restrictions can be lifted. In this paper, we address this issue by transplanting the KALM framework to a neural natural language parser, mStanza. Here we limit our attention to authoring facts and queries and therefore our focus is what we call factual English statements. Authoring other types of knowledge, such as rules, will be considered in our followup work. As it turns out, neural network based parsers have problems of their own and the mistakes they make range from part-of-speech tagging to lemmatization to dependency errors. We present a number of techniques for combating these problems and test the new system, KALMFL (i.e., KALM for factual language), on a number of benchmarks, which show KALMFL achieves correctness in excess of 95%.
* In Proceedings ICLP 2022, arXiv:2208.02685
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020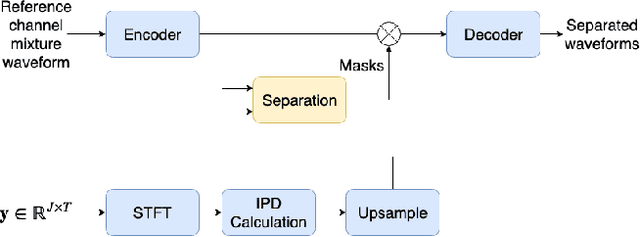

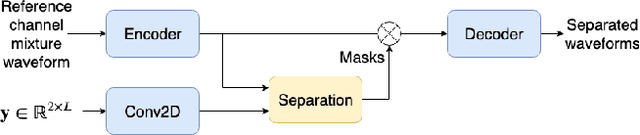
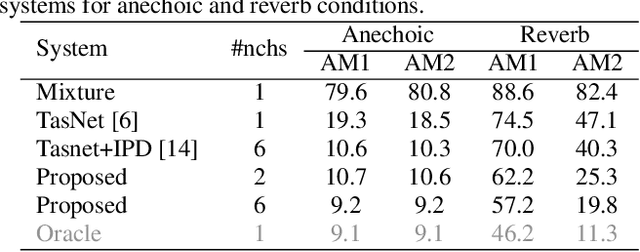
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020
Dialog+ in Broadcasting: First Field Tests Using Deep-Learning-Based Dialogue Enhancement
Dec 17, 2021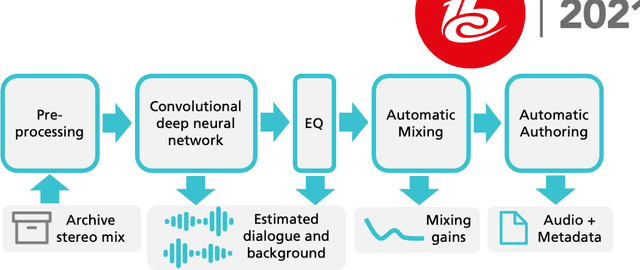
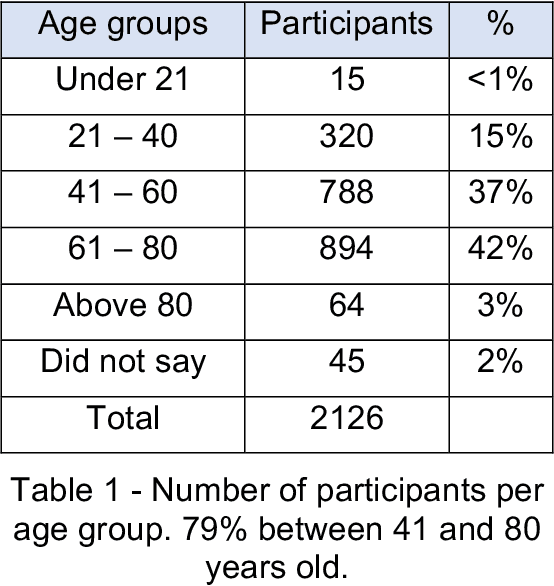


Difficulties in following speech due to loud background sounds are common in broadcasting. Object-based audio, e.g., MPEG-H Audio solves this problem by providing a user-adjustable speech level. While object-based audio is gaining momentum, transitioning to it requires time and effort. Also, lots of content exists, produced and archived outside the object-based workflows. To address this, Fraunhofer IIS has developed a deep-learning solution called Dialog+, capable of enabling speech level personalization also for content with only the final audio tracks available. This paper reports on public field tests evaluating Dialog+, conducted together with Westdeutscher Rundfunk (WDR) and Bayerischer Rundfunk (BR), starting from September 2020. To our knowledge, these are the first large-scale tests of this kind. As part of one of these, a survey with more than 2,000 participants showed that 90% of the people above 60 years old have problems in understanding speech in TV "often" or "very often". Overall, 83% of the participants liked the possibility to switch to Dialog+, including those who do not normally struggle with speech intelligibility. Dialog+ introduces a clear benefit for the audience, filling the gap between object-based broadcasting and traditionally produced material.
Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition
Jun 16, 2021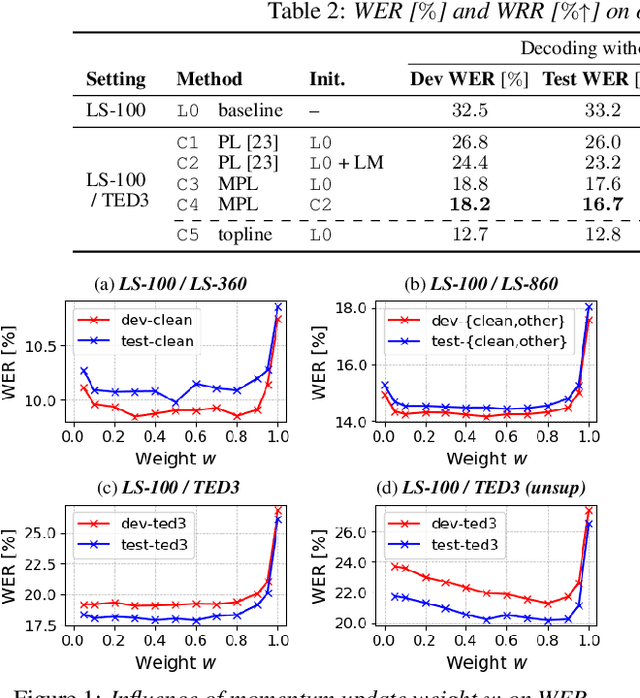
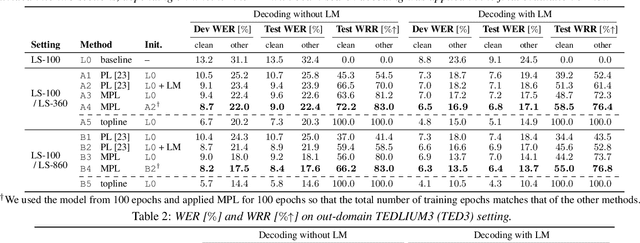
Pseudo-labeling (PL) has been shown to be effective in semi-supervised automatic speech recognition (ASR), where a base model is self-trained with pseudo-labels generated from unlabeled data. While PL can be further improved by iteratively updating pseudo-labels as the model evolves, most of the previous approaches involve inefficient retraining of the model or intricate control of the label update. We present momentum pseudo-labeling (MPL), a simple yet effective strategy for semi-supervised ASR. MPL consists of a pair of online and offline models that interact and learn from each other, inspired by the mean teacher method. The online model is trained to predict pseudo-labels generated on the fly by the offline model. The offline model maintains a momentum-based moving average of the online model. MPL is performed in a single training process and the interaction between the two models effectively helps them reinforce each other to improve the ASR performance. We apply MPL to an end-to-end ASR model based on the connectionist temporal classification. The experimental results demonstrate that MPL effectively improves over the base model and is scalable to different semi-supervised scenarios with varying amounts of data or domain mismatch.
Multiple-hypothesis CTC-based semi-supervised adaptation of end-to-end speech recognition
Mar 31, 2021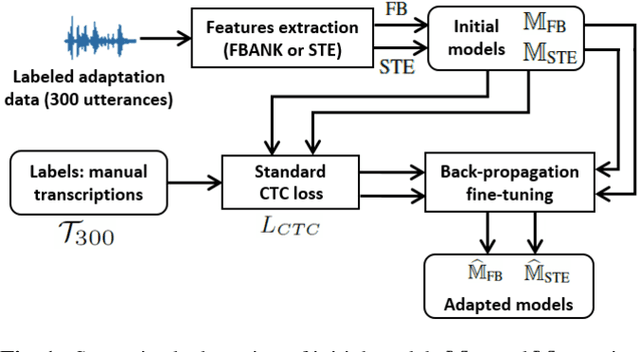

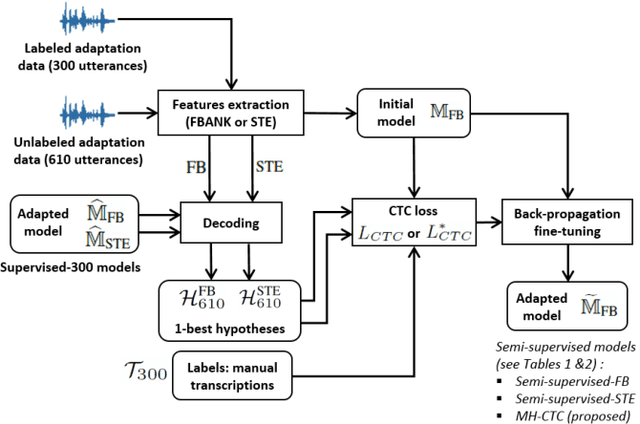
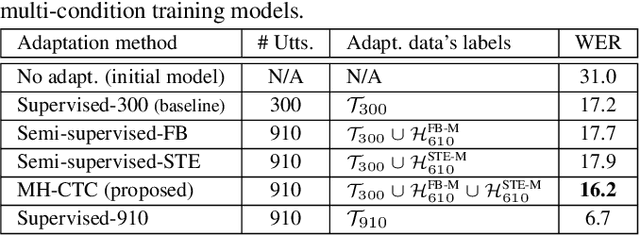
This paper proposes an adaptation method for end-to-end speech recognition. In this method, multiple automatic speech recognition (ASR) 1-best hypotheses are integrated in the computation of the connectionist temporal classification (CTC) loss function. The integration of multiple ASR hypotheses helps alleviating the impact of errors in the ASR hypotheses to the computation of the CTC loss when ASR hypotheses are used. When being applied in semi-supervised adaptation scenarios where part of the adaptation data do not have labels, the CTC loss of the proposed method is computed from different ASR 1-best hypotheses obtained by decoding the unlabeled adaptation data. Experiments are performed in clean and multi-condition training scenarios where the CTC-based end-to-end ASR systems are trained on Wall Street Journal (WSJ) clean training data and CHiME-4 multi-condition training data, respectively, and tested on Aurora-4 test data. The proposed adaptation method yields 6.6% and 5.8% relative word error rate (WER) reductions in clean and multi-condition training scenarios, respectively, compared to a baseline system which is adapted with part of the adaptation data having manual transcriptions using back-propagation fine-tuning.
Detecting Hate Speech in Multi-modal Memes
Dec 29, 2020

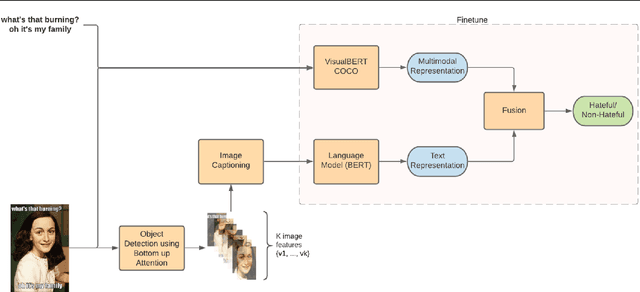
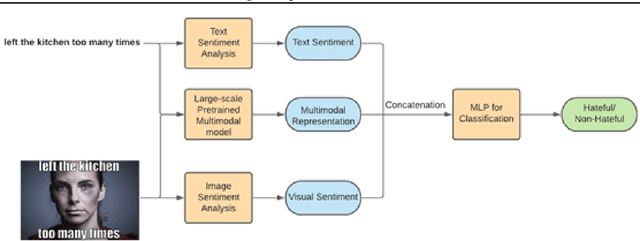
In the past few years, there has been a surge of interest in multi-modal problems, from image captioning to visual question answering and beyond. In this paper, we focus on hate speech detection in multi-modal memes wherein memes pose an interesting multi-modal fusion problem. We aim to solve the Facebook Meme Challenge \cite{kiela2020hateful} which aims to solve a binary classification problem of predicting whether a meme is hateful or not. A crucial characteristic of the challenge is that it includes "benign confounders" to counter the possibility of models exploiting unimodal priors. The challenge states that the state-of-the-art models perform poorly compared to humans. During the analysis of the dataset, we realized that majority of the data points which are originally hateful are turned into benign just be describing the image of the meme. Also, majority of the multi-modal baselines give more preference to the hate speech (language modality). To tackle these problems, we explore the visual modality using object detection and image captioning models to fetch the "actual caption" and then combine it with the multi-modal representation to perform binary classification. This approach tackles the benign text confounders present in the dataset to improve the performance. Another approach we experiment with is to improve the prediction with sentiment analysis. Instead of only using multi-modal representations obtained from pre-trained neural networks, we also include the unimodal sentiment to enrich the features. We perform a detailed analysis of the above two approaches, providing compelling reasons in favor of the methodologies used.
Polyphone disambiguation and accent prediction using pre-trained language models in Japanese TTS front-end
Jan 24, 2022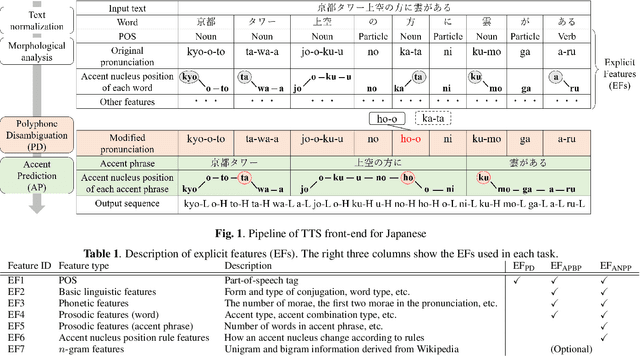



Although end-to-end text-to-speech (TTS) models can generate natural speech, challenges still remain when it comes to estimating sentence-level phonetic and prosodic information from raw text in Japanese TTS systems. In this paper, we propose a method for polyphone disambiguation (PD) and accent prediction (AP). The proposed method incorporates explicit features extracted from morphological analysis and implicit features extracted from pre-trained language models (PLMs). We use BERT and Flair embeddings as implicit features and examine how to combine them with explicit features. Our objective evaluation results showed that the proposed method improved the accuracy by 5.7 points in PD and 6.0 points in AP. Moreover, the perceptual listening test results confirmed that a TTS system employing our proposed model as a front-end achieved a mean opinion score close to that of synthesized speech with ground-truth pronunciation and accent in terms of naturalness.
End-to-End Adversarial Text-to-Speech
Jun 05, 2020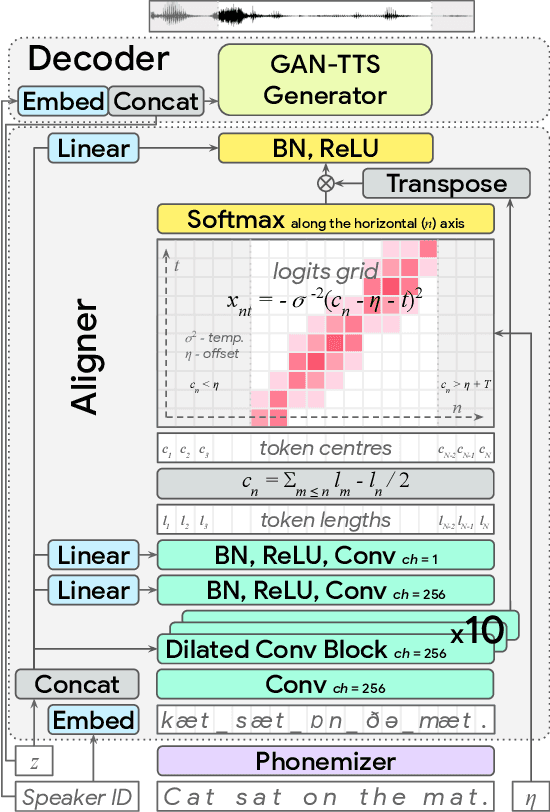
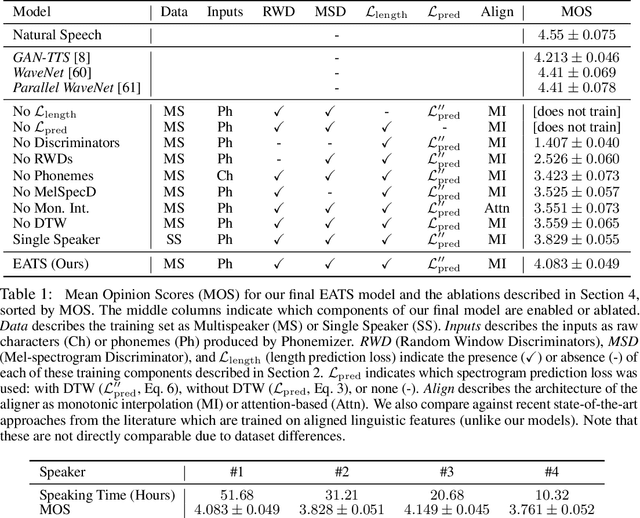

Modern text-to-speech synthesis pipelines typically involve multiple processing stages, each of which is designed or learnt independently from the rest. In this work, we take on the challenging task of learning to synthesise speech from normalised text or phonemes in an end-to-end manner, resulting in models which operate directly on character or phoneme input sequences and produce raw speech audio outputs. Our proposed generator is feed-forward and thus efficient for both training and inference, using a differentiable monotonic interpolation scheme to predict the duration of each input token. It learns to produce high fidelity audio through a combination of adversarial feedback and prediction losses constraining the generated audio to roughly match the ground truth in terms of its total duration and mel-spectrogram. To allow the model to capture temporal variation in the generated audio, we employ soft dynamic time warping in the spectrogram-based prediction loss. The resulting model achieves a mean opinion score exceeding 4 on a 5 point scale, which is comparable to the state-of-the-art models relying on multi-stage training and additional supervision.
RF-Next: Efficient Receptive Field Search for Convolutional Neural Networks
Jun 15, 2022



Temporal/spatial receptive fields of models play an important role in sequential/spatial tasks. Large receptive fields facilitate long-term relations, while small receptive fields help to capture the local details. Existing methods construct models with hand-designed receptive fields in layers. Can we effectively search for receptive field combinations to replace hand-designed patterns? To answer this question, we propose to find better receptive field combinations through a global-to-local search scheme. Our search scheme exploits both global search to find the coarse combinations and local search to get the refined receptive field combinations further. The global search finds possible coarse combinations other than human-designed patterns. On top of the global search, we propose an expectation-guided iterative local search scheme to refine combinations effectively. Our RF-Next models, plugging receptive field search to various models, boost the performance on many tasks, e.g., temporal action segmentation, object detection, instance segmentation, and speech synthesis. The source code is publicly available on http://mmcheng.net/rfnext.