 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
KazakhTTS: An Open-Source Kazakh Text-to-Speech Synthesis Dataset
Apr 26, 2021

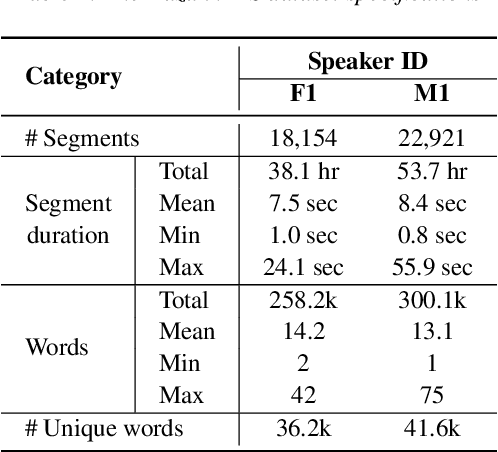
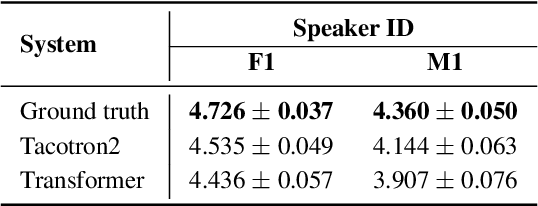
This paper introduces a high-quality open-source speech synthesis dataset for Kazakh, a low-resource language spoken by over 13 million people worldwide. The dataset consists of about 93 hours of transcribed audio recordings spoken by two professional speakers (female and male). It is the first publicly available large-scale dataset developed to promote Kazakh text-to-speech (TTS) applications in both academia and industry. In this paper, we share our experience by describing the dataset development procedures and faced challenges, and discuss important future directions. To demonstrate the reliability of our dataset, we built baseline end-to-end TTS models and evaluated them using the subjective mean opinion score (MOS) measure. Evaluation results show that the best TTS models trained on our dataset achieve MOS above 4 for both speakers, which makes them applicable for practical use. The dataset, training recipe, and pretrained TTS models are freely available.
Evaluating the reliability of acoustic speech embeddings
Jul 27, 2020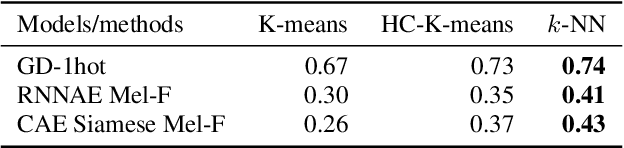
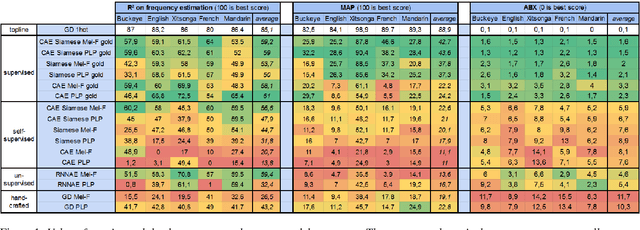

Speech embeddings are fixed-size acoustic representations of variable-length speech sequences. They are increasingly used for a variety of tasks ranging from information retrieval to unsupervised term discovery and speech segmentation. However, there is currently no clear methodology to compare or optimise the quality of these embeddings in a task-neutral way. Here, we systematically compare two popular metrics, ABX discrimination and Mean Average Precision (MAP), on 5 languages across 17 embedding methods, ranging from supervised to fully unsupervised, and using different loss functions (autoencoders, correspondence autoencoders, siamese). Then we use the ABX and MAP to predict performances on a new downstream task: the unsupervised estimation of the frequencies of speech segments in a given corpus. We find that overall, ABX and MAP correlate with one another and with frequency estimation. However, substantial discrepancies appear in the fine-grained distinctions across languages and/or embedding methods. This makes it unrealistic at present to propose a task-independent silver bullet method for computing the intrinsic quality of speech embeddings. There is a need for more detailed analysis of the metrics currently used to evaluate such embeddings.
Incremental Machine Speech Chain Towards Enabling Listening while Speaking in Real-time
Nov 04, 2020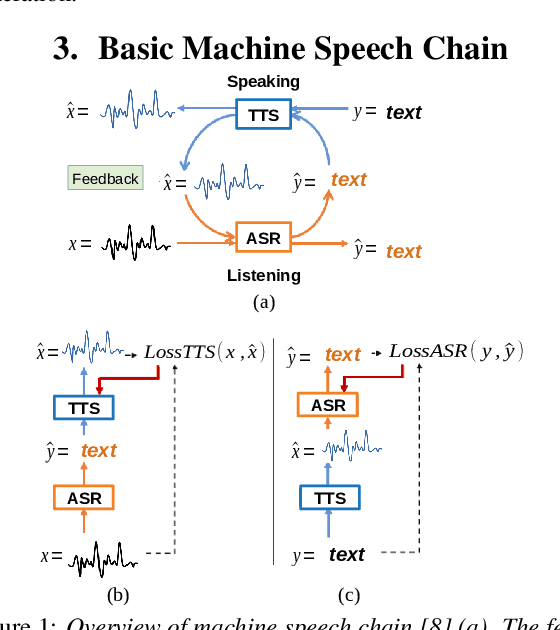
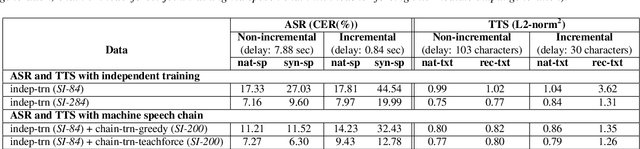
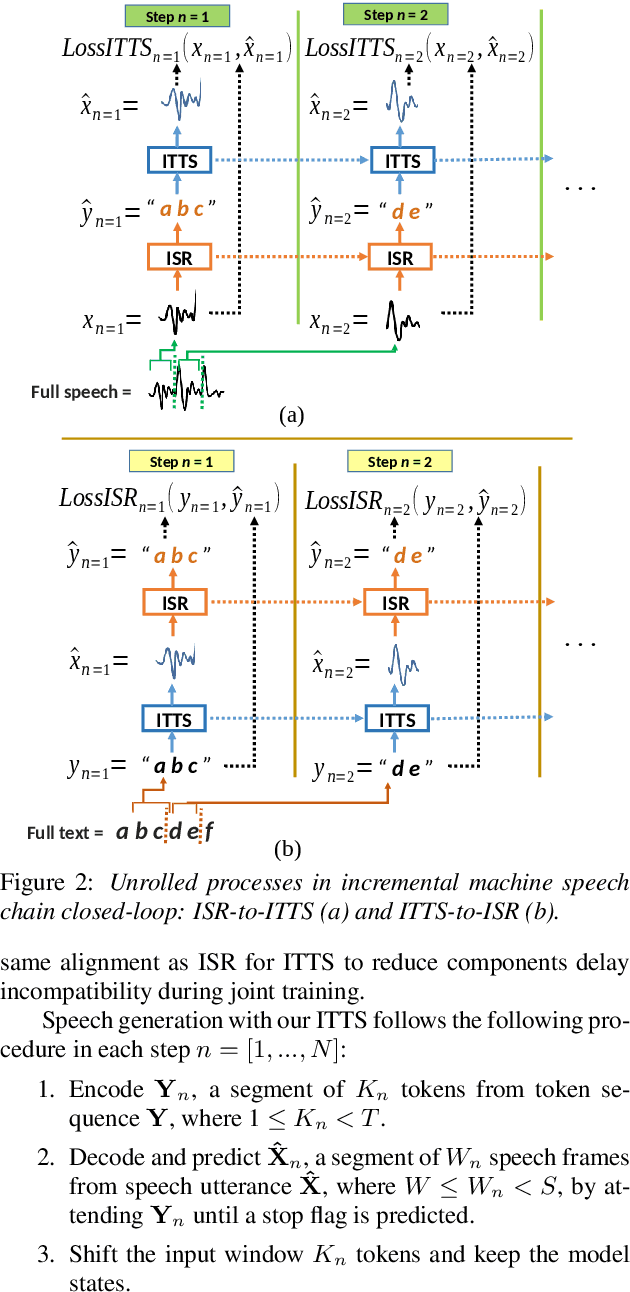
Inspired by a human speech chain mechanism, a machine speech chain framework based on deep learning was recently proposed for the semi-supervised development of automatic speech recognition (ASR) and text-to-speech synthesis TTS) systems. However, the mechanism to listen while speaking can be done only after receiving entire input sequences. Thus, there is a significant delay when encountering long utterances. By contrast, humans can listen to what hey speak in real-time, and if there is a delay in hearing, they won't be able to continue speaking. In this work, we propose an incremental machine speech chain towards enabling machine to listen while speaking in real-time. Specifically, we construct incremental ASR (ISR) and incremental TTS (ITTS) by letting both systems improve together through a short-term loop. Our experimental results reveal that our proposed framework is able to reduce delays due to long utterances while keeping a comparable performance to the non-incremental basic machine speech chain.
Speech enhancement guided by contextual articulatory information
Nov 15, 2020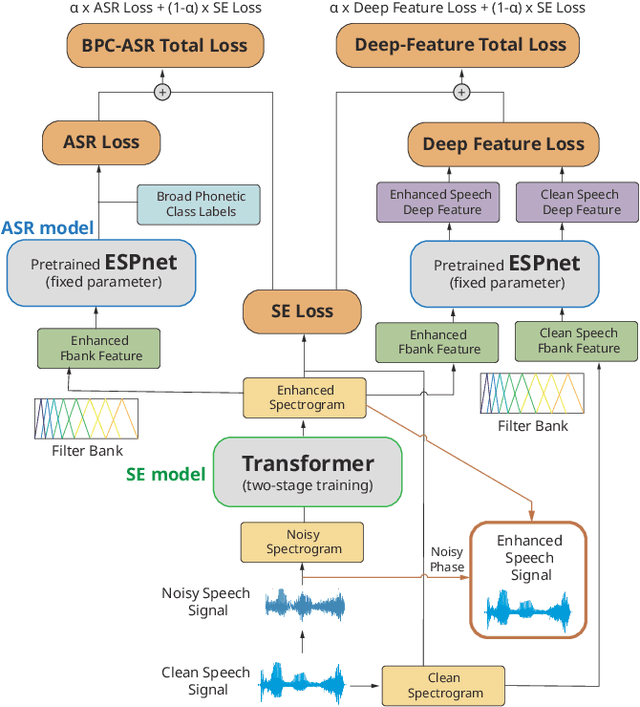
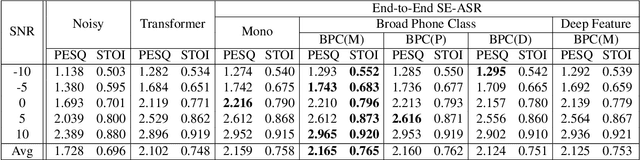
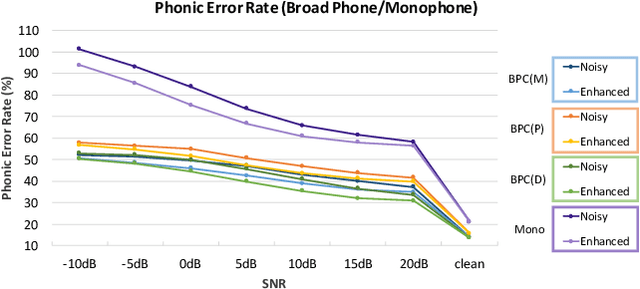
Previous studies have confirmed the effectiveness of leveraging articulatory information to attain improved speech enhancement (SE) performance. By augmenting the original acoustic features with the place/manner of articulatory features, the SE process can be guided to consider the articulatory properties of the input speech when performing enhancement. Hence, we believe that the contextual information of articulatory attributes should include useful information and can further benefit SE. In this study, we propose an SE system that incorporates contextual articulatory information; such information is obtained using broad phone class (BPC) end-to-end automatic speech recognition (ASR). Meanwhile, two training strategies are developed to train the SE system based on the BPC-based ASR: multitask-learning and deep-feature training strategies. Experimental results on the TIMIT dataset confirm that the contextual articulatory information facilitates an SE system in achieving better results. Moreover, in contrast to another SE system that is trained with monophonic ASR, the BPC-based ASR (providing contextual articulatory information) can improve the SE performance more effectively under different signal-to-noise ratios(SNR).
Oscillating Statistical Moments for Speech Polarity Detection
May 16, 2020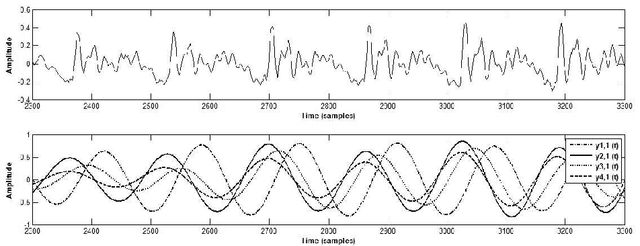
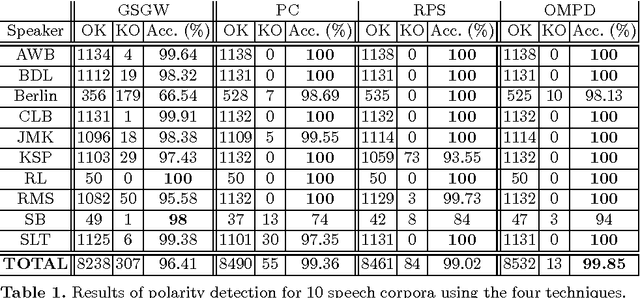
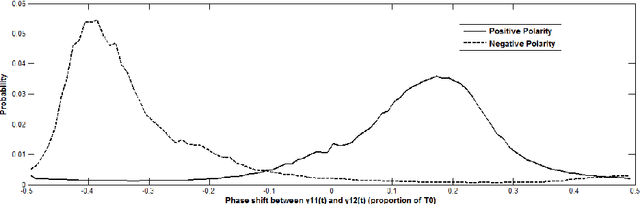
An inversion of the speech polarity may have a dramatic detrimental effect on the performance of various techniques of speech processing. An automatic method for determining the speech polarity (which is dependent upon the recording setup) is thus required as a preliminary step for ensuring the well-behaviour of such techniques. This paper proposes a new approach of polarity detection relying on oscillating statistical moments. These moments have the property to oscillate at the local fundamental frequency and to exhibit a phase shift which depends on the speech polarity. This dependency stems from the introduction of non-linearity or higher-order statistics in the moment calculation. The resulting method is shown on 10 speech corpora to provide a substantial improvement compared to state-of-the-art techniques.
Podcast Summary Assessment: A Resource for Evaluating Summary Assessment Methods
Aug 28, 2022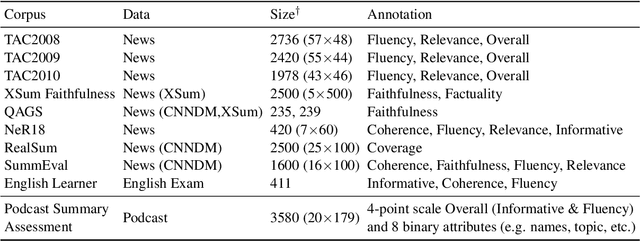
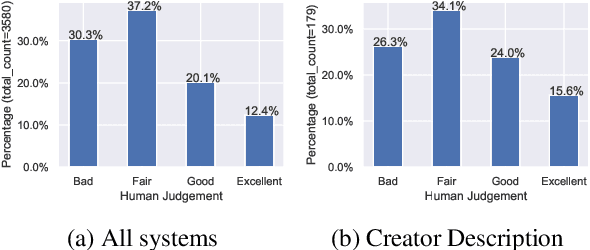
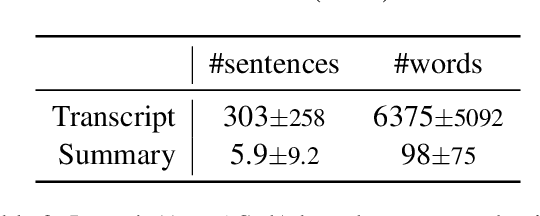
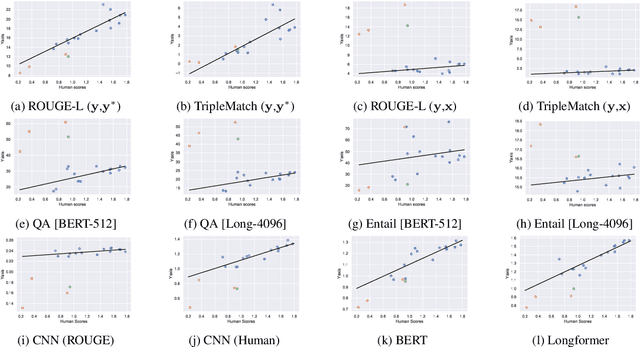
Automatic summary assessment is useful for both machine-generated and human-produced summaries. Automatically evaluating the summary text given the document enables, for example, summary generation system development and detection of inappropriate summaries. Summary assessment can be run in a number of modes: ranking summary generation systems; ranking summaries of a particular document; and estimating the quality of a document-summary pair on an absolute scale. Existing datasets with annotation for summary assessment are usually based on news summarization datasets such as CNN/DailyMail or XSum. In this work, we describe a new dataset, the podcast summary assessment corpus, a collection of podcast summaries that were evaluated by human experts at TREC2020. Compared to existing summary assessment data, this dataset has two unique aspects: (i) long-input, speech podcast based, documents; and (ii) an opportunity to detect inappropriate reference summaries in podcast corpus. First, we examine existing assessment methods, including model-free and model-based methods, and provide benchmark results for this long-input summary assessment dataset. Second, with the aim of filtering reference summary-document pairings for training, we apply summary assessment for data selection. The experimental results on these two aspects provide interesting insights on the summary assessment and generation tasks. The podcast summary assessment data is available.
Pretext Tasks selection for multitask self-supervised speech representation learning
Jul 01, 2021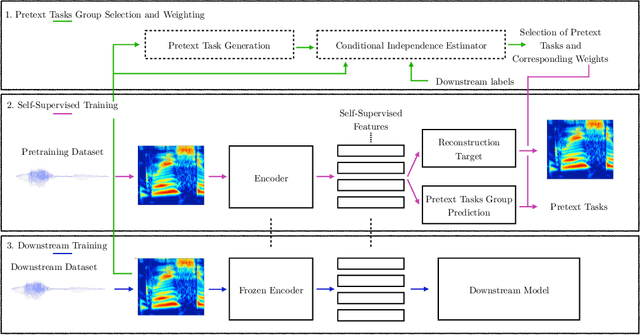
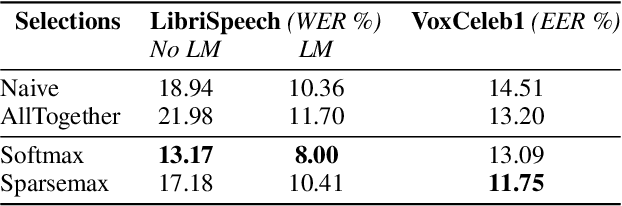
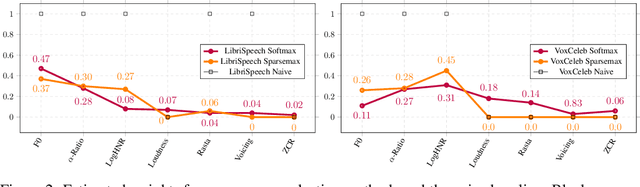
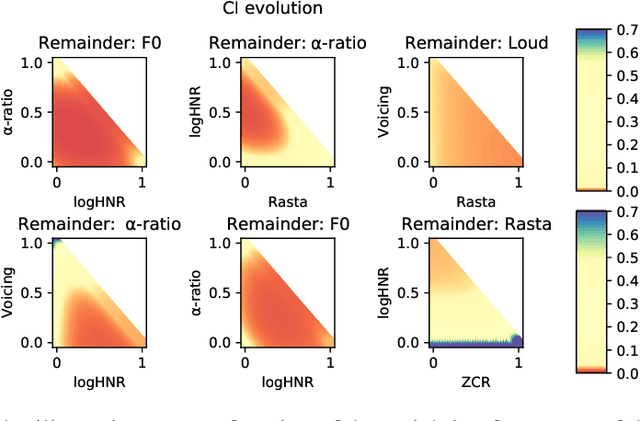
Through solving pretext tasks, self-supervised learning leverages unlabeled data to extract useful latent representations replacing traditional input features in the downstream task. In various application domains, including computer vision, natural language processing and audio/speech signal processing, a wide range of features where engineered through decades of research efforts. As it turns out, learning to predict such features has proven to be a particularly relevant pretext task leading to building useful self-supervised representations that prove to be effective for downstream tasks. However, methods and common practices for combining such pretext tasks, where each task targets a different group of features for better performance on the downstream task have not been explored and understood properly. In fact, the process relies almost exclusively on a computationally heavy experimental procedure, which becomes intractable with the increase of the number of pretext tasks. This paper introduces a method to select a group of pretext tasks among a set of candidates. The method we propose estimates properly calibrated weights for the partial losses corresponding to the considered pretext tasks during the self-supervised training process. The experiments conducted on speaker recognition and automatic speech recognition validate our approach, as the groups selected and weighted with our method perform better than classic baselines, thus facilitating the selection and combination of relevant pseudo-labels for self-supervised representation learning.
Which one is more toxic? Findings from Jigsaw Rate Severity of Toxic Comments
Jun 27, 2022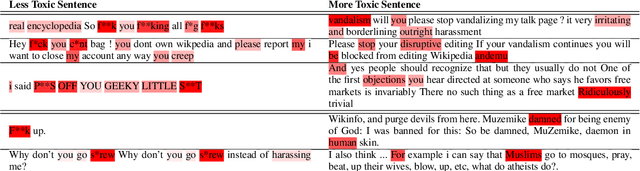
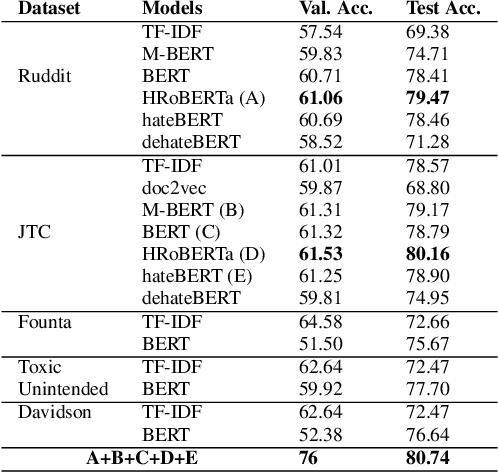
The proliferation of online hate speech has necessitated the creation of algorithms which can detect toxicity. Most of the past research focuses on this detection as a classification task, but assigning an absolute toxicity label is often tricky. Hence, few of the past works transform the same task into a regression. This paper shows the comparative evaluation of different transformers and traditional machine learning models on a recently released toxicity severity measurement dataset by Jigsaw. We further demonstrate the issues with the model predictions using explainability analysis.
Transformer-Transducers for Code-Switched Speech Recognition
Nov 30, 2020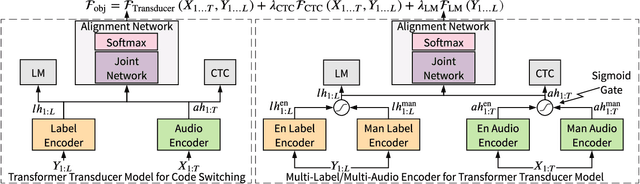
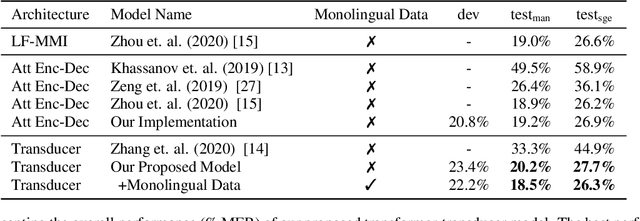


We live in a world where 60% of the population can speak two or more languages fluently. Members of these communities constantly switch between languages when having a conversation. As automatic speech recognition (ASR) systems are being deployed to the real-world, there is a need for practical systems that can handle multiple languages both within an utterance or across utterances. In this paper, we present an end-to-end ASR system using a transformer-transducer model architecture for code-switched speech recognition. We propose three modifications over the vanilla model in order to handle various aspects of code-switching. First, we introduce two auxiliary loss functions to handle the low-resource scenario of code-switching. Second, we propose a novel mask-based training strategy with language ID information to improve the label encoder training towards intra-sentential code-switching. Finally, we propose a multi-label/multi-audio encoder structure to leverage the vast monolingual speech corpora towards code-switching. We demonstrate the efficacy of our proposed approaches on the SEAME dataset, a public Mandarin-English code-switching corpus, achieving a mixed error rate of 18.5% and 26.3% on test_man and test_sge sets respectively.
Unsupervised Domain Adaptation for Dysarthric Speech Detection via Domain Adversarial Training and Mutual Information Minimization
Jun 18, 2021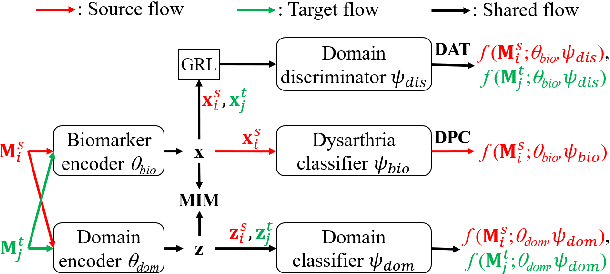

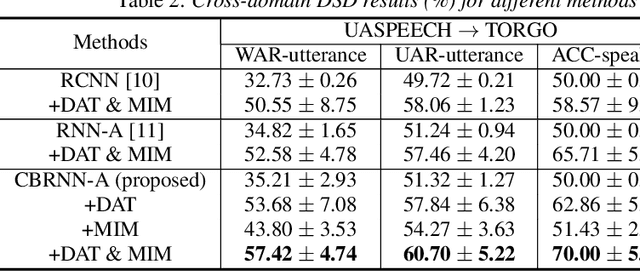
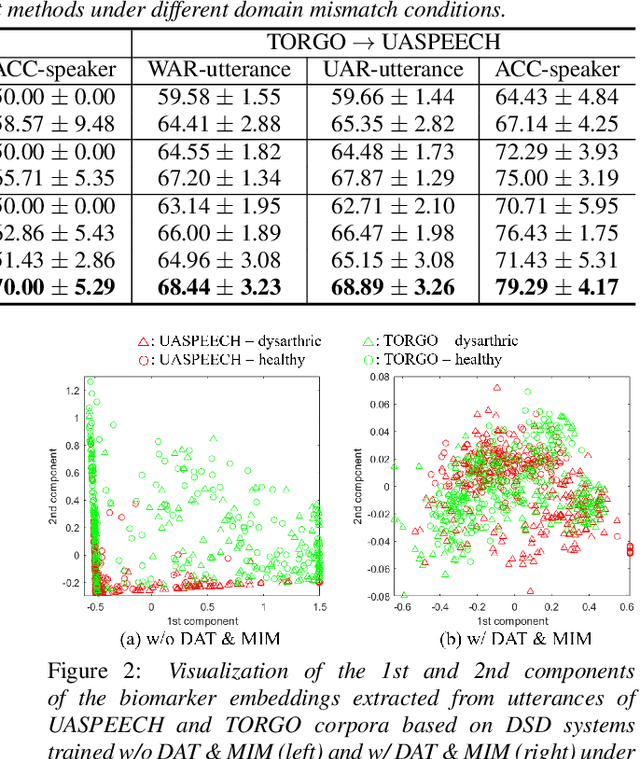
Dysarthric speech detection (DSD) systems aim to detect characteristics of the neuromotor disorder from speech. Such systems are particularly susceptible to domain mismatch where the training and testing data come from the source and target domains respectively, but the two domains may differ in terms of speech stimuli, disease etiology, etc. It is hard to acquire labelled data in the target domain, due to high costs of annotating sizeable datasets. This paper makes a first attempt to formulate cross-domain DSD as an unsupervised domain adaptation (UDA) problem. We use labelled source-domain data and unlabelled target-domain data, and propose a multi-task learning strategy, including dysarthria presence classification (DPC), domain adversarial training (DAT) and mutual information minimization (MIM), which aim to learn dysarthria-discriminative and domain-invariant biomarker embeddings. Specifically, DPC helps biomarker embeddings capture critical indicators of dysarthria; DAT forces biomarker embeddings to be indistinguishable in source and target domains; and MIM further reduces the correlation between biomarker embeddings and domain-related cues. By treating the UASPEECH and TORGO corpora respectively as the source and target domains, experiments show that the incorporation of UDA attains absolute increases of 22.2% and 20.0% respectively in utterance-level weighted average recall and speaker-level accuracy.