 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Data-augmented cross-lingual synthesis in a teacher-student framework
Mar 31, 2022
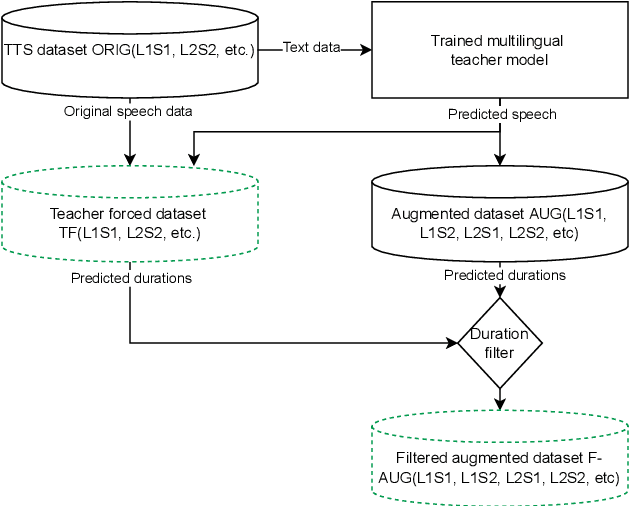
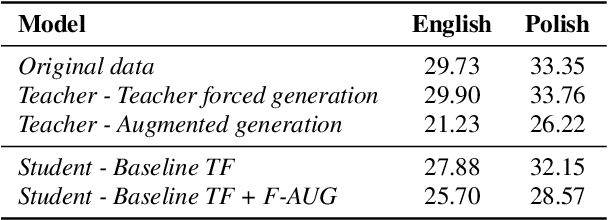
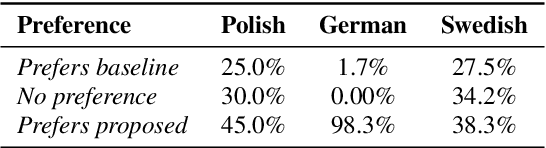
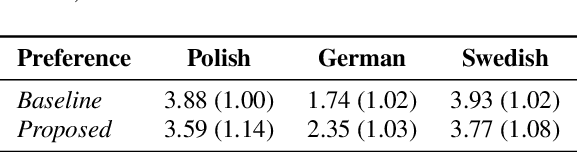
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.
Federated Acoustic Modeling For Automatic Speech Recognition
Feb 08, 2021


Data privacy and protection is a crucial issue for any automatic speech recognition (ASR) service provider when dealing with clients. In this paper, we investigate federated acoustic modeling using data from multiple clients. A client's data is stored on a local data server and the clients communicate only model parameters with a central server, and not their data. The communication happens infrequently to reduce the communication cost. To mitigate the non-iid issue, client adaptive federated training (CAFT) is proposed to canonicalize data across clients. The experiments are carried out on 1,150 hours of speech data from multiple domains. Hybrid LSTM acoustic models are trained via federated learning and their performance is compared to traditional centralized acoustic model training. The experimental results demonstrate the effectiveness of the proposed federated acoustic modeling strategy. We also show that CAFT can further improve the performance of the federated acoustic model.
Compact Graph Architecture for Speech Emotion Recognition
Aug 06, 2020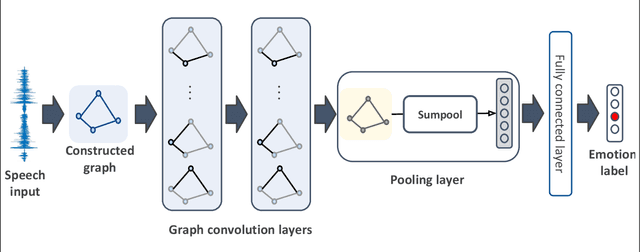
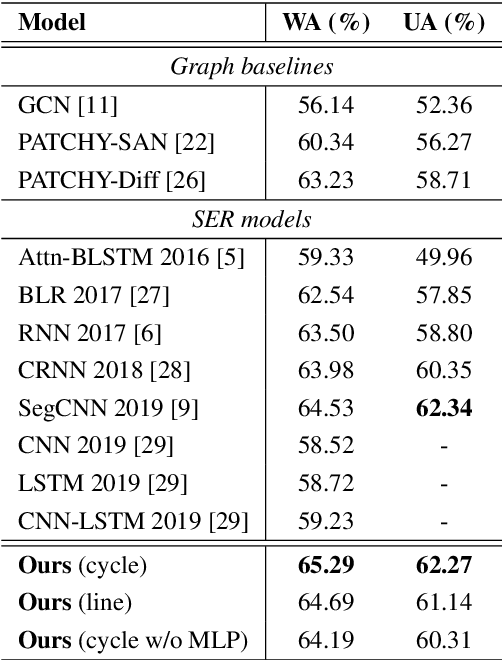
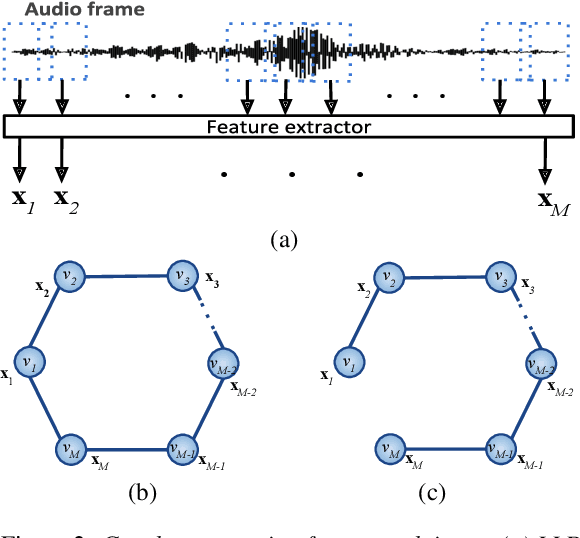

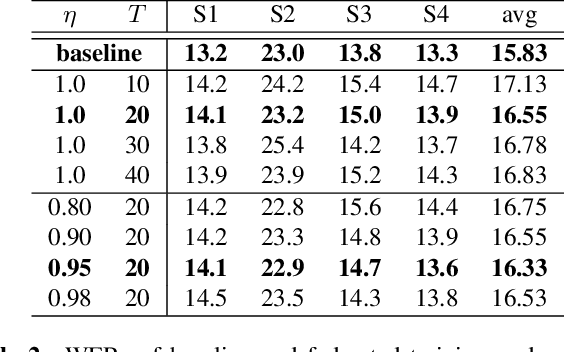
We propose a deep graph approach to address the task of speech emotion recognition. A compact, efficient and scalable way to represent data is in the form of graphs. Following the theory of graph signal processing, we propose to model speech signal as a cycle graph or a line graph. Such graph structure enables us to construct a graph convolution network (GCN)-based architecture that can perform an \emph{accurate} graph convolution in contrast to the approximate convolution used in standard GCNs. We evaluated the performance of our model for speech emotion recognition on the popular IEMOCAP database. Our model outperforms standard GCN and other relevant deep graph architectures indicating the effectiveness of our approach. When compared with existing speech emotion recognition methods, our model achieves state-of-the-art performance (4-class, $65.29\%$) with significantly fewer learnable parameters.
Toward Zero Oracle Word Error Rate on the Switchboard Benchmark
Jun 13, 2022



The "Switchboard benchmark" is a very well-known test set in automatic speech recognition (ASR) research, establishing record-setting performance for systems that claim human-level transcription accuracy. This work highlights lesser-known practical considerations of this evaluation, demonstrating major improvements in word error rate (WER) by correcting the reference transcriptions and deviating from the official scoring methodology. In this more detailed and reproducible scheme, even commercial ASR systems can score below 5\% WER and the established record for a research system is lowered to 2.3%. An alternative metric of transcript precision is proposed, which does not penalize deletions and appears to be more discriminating for human vs. machine performance. While commercial ASR systems are still below this threshold, a research system is shown to clearly surpass the accuracy of commercial human speech recognition. This work also explores using standardized scoring tools to compute oracle WER by selecting the best among a list of alternatives. A phrase alternatives representation is compared to utterance-level N-best lists and word-level data structures; using dense lattices and adding out-of-vocabulary words, this achieves an oracle WER of 0.18%.
Noise-robust voice conversion with domain adversarial training
Jan 26, 2022
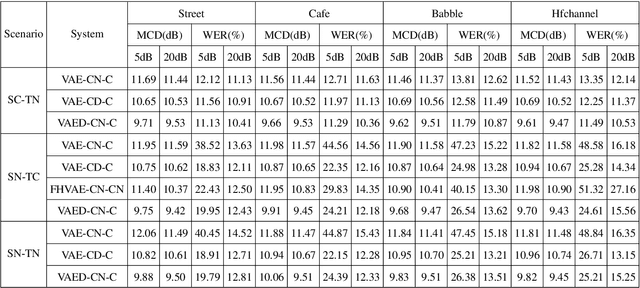
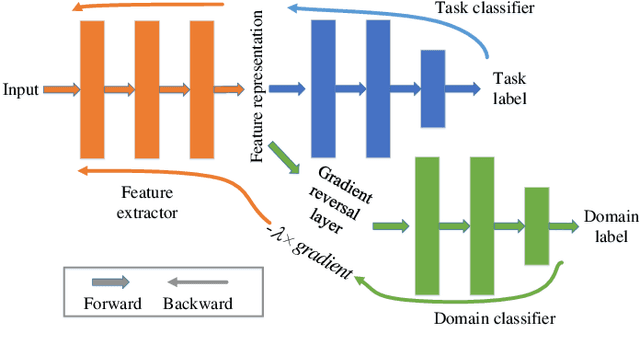
Voice conversion has made great progress in the past few years under the studio-quality test scenario in terms of speech quality and speaker similarity. However, in real applications, test speech from source speaker or target speaker can be corrupted by various environment noises, which seriously degrade the speech quality and speaker similarity. In this paper, we propose a novel encoder-decoder based noise-robust voice conversion framework, which consists of a speaker encoder, a content encoder, a decoder, and two domain adversarial neural networks. Specifically, we integrate disentangling speaker and content representation technique with domain adversarial training technique. Domain adversarial training makes speaker representations and content representations extracted by speaker encoder and content encoder from clean speech and noisy speech in the same space, respectively. In this way, the learned speaker and content representations are noise-invariant. Therefore, the two noise-invariant representations can be taken as input by the decoder to predict the clean converted spectrum. The experimental results demonstrate that our proposed method can synthesize clean converted speech under noisy test scenarios, where the source speech and target speech can be corrupted by seen or unseen noise types during the training process. Additionally, both speech quality and speaker similarity are improved.
A Neural-Network Framework for the Design of Individualised Hearing-Loss Compensation
Jul 14, 2022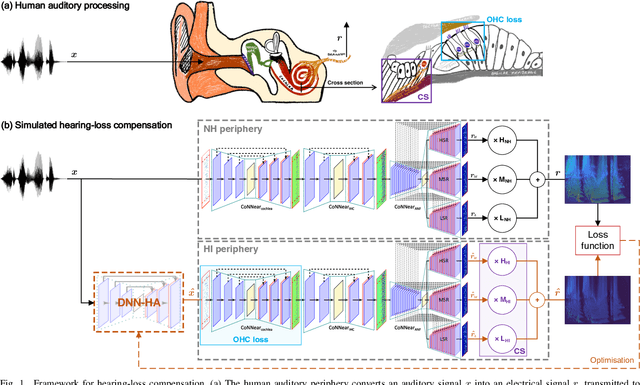
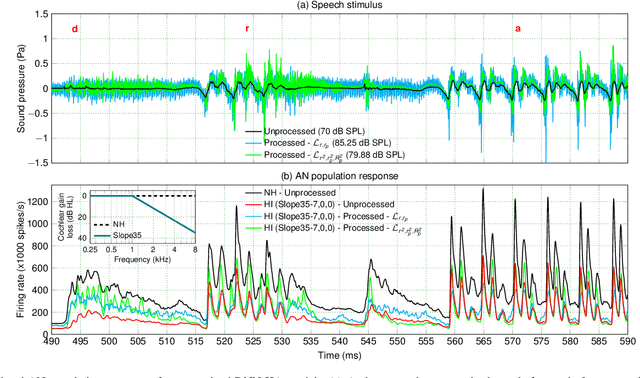
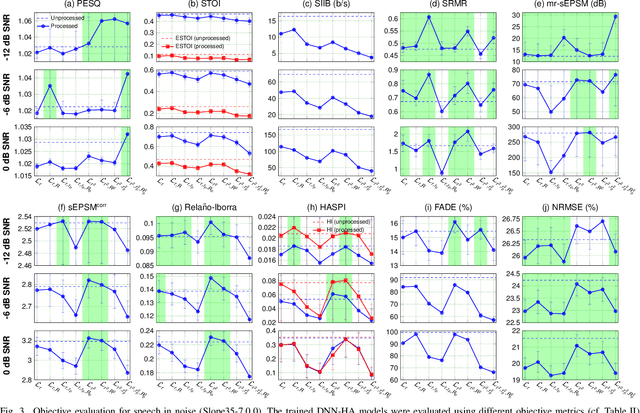
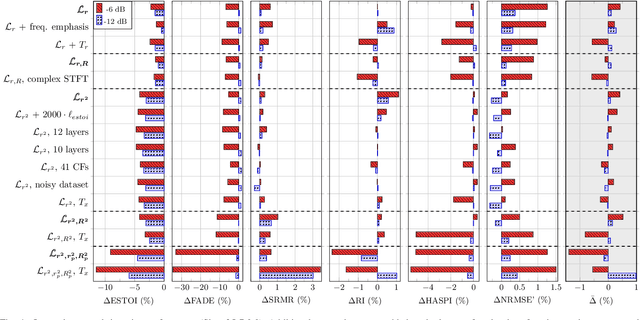
Even though sound processing in the human auditory system is complex and highly non-linear, hearing aids (HAs) still rely on simplified descriptions of auditory processing or hearing loss to restore hearing. Standard HA amplification strategies succeed in restoring inaudibility of faint sounds, but fall short of providing targetted treatments for complex sensorineural deficits. To address this challenge, biophysically realistic models of human auditory processing can be adopted in the design of individualised HA strategies, but these are typically non-differentiable and computationally expensive. Therefore, this study proposes a differentiable DNN framework that can be used to train DNN-based HA models based on biophysical auditory-processing differences between normal-hearing and hearing-impaired models. We investigate the restoration capabilities of our DNN-based hearing-loss compensation for different loss functions, to optimally compensate for a mixed outer-hair-cell (OHC) loss and cochlear-synaptopathy (CS) impairment. After evaluating which trained DNN-HA model yields the best restoration outcomes on simulated auditory responses and speech intelligibility, we applied the same training procedure to two milder hearing-loss profiles with OHC loss or CS alone. Our results show that auditory-processing restoration was possible for all considered hearing-loss cases, with OHC loss proving easier to compensate than CS. Several objective metrics were considered to estimate the expected perceptual benefit after processing, and these simulations hold promise in yielding improved understanding of speech-in-noise for hearing-impaired listeners who use our DNN-HA processing. Since our framework can be tuned to the hearing-loss profiles of individual listeners, we enter an era where truly individualised and DNN-based hearing-restoration strategies can be developed and be tested experimentally.
Multiclass ASMA vs Targeted PGD Attack in Image Segmentation
Aug 03, 2022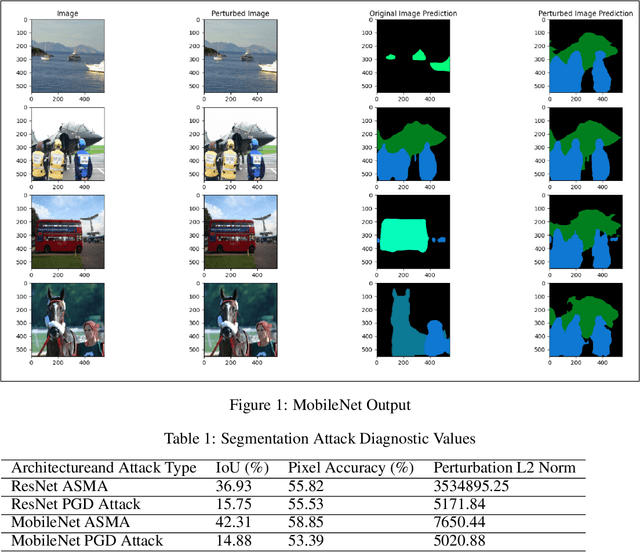
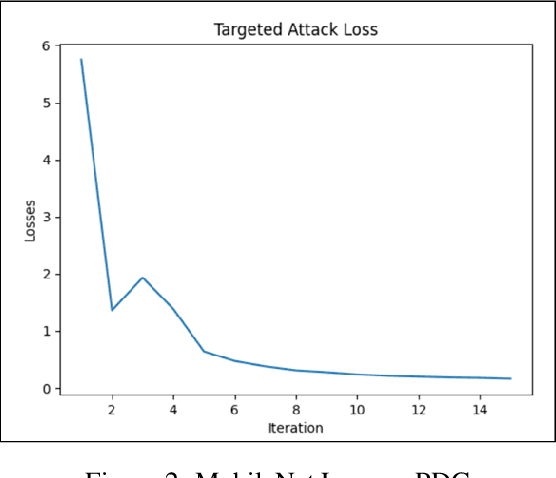


Deep learning networks have demonstrated high performance in a large variety of applications, such as image classification, speech recognition, and natural language processing. However, there exists a major vulnerability exploited by the use of adversarial attacks. An adversarial attack imputes images by altering the input image very slightly, making it nearly undetectable to the naked eye, but results in a very different classification by the network. This paper explores the projected gradient descent (PGD) attack and the Adaptive Mask Segmentation Attack (ASMA) on the image segmentation DeepLabV3 model using two types of architectures: MobileNetV3 and ResNet50, It was found that PGD was very consistent in changing the segmentation to be its target while the generalization of ASMA to a multiclass target was not as effective. The existence of such attack however puts all of image classification deep learning networks in danger of exploitation.
Learning Lip-Based Audio-Visual Speaker Embeddings with AV-HuBERT
May 15, 2022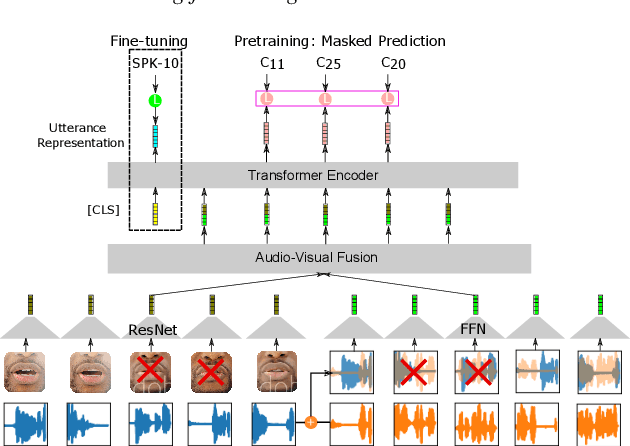
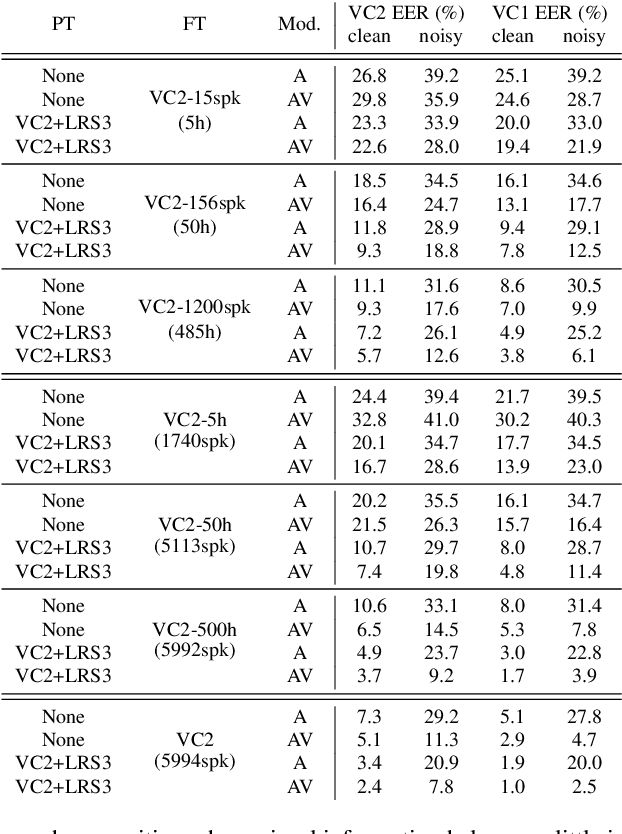
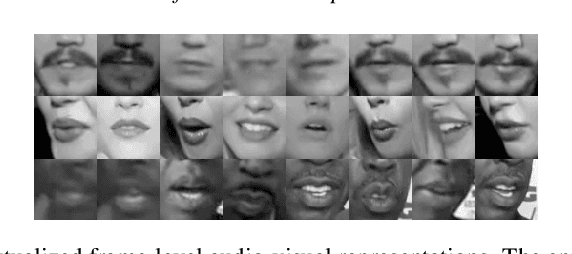
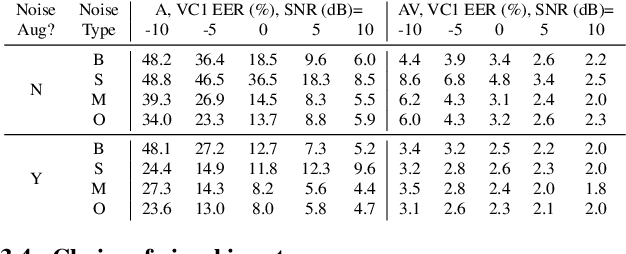
This paper investigates self-supervised pre-training for audio-visual speaker representation learning where a visual stream showing the speaker's mouth area is used alongside speech as inputs. Our study focuses on the Audio-Visual Hidden Unit BERT (AV-HuBERT) approach, a recently developed general-purpose audio-visual speech pre-training framework. We conducted extensive experiments probing the effectiveness of pre-training and visual modality. Experimental results suggest that AV-HuBERT generalizes decently to speaker related downstream tasks, improving label efficiency by roughly ten fold for both audio-only and audio-visual speaker verification. We also show that incorporating visual information, even just the lip area, greatly improves the performance and noise robustness, reducing EER by 38% in the clean condition and 75% in noisy conditions. Our code and models will be publicly available.
A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images
Feb 16, 2021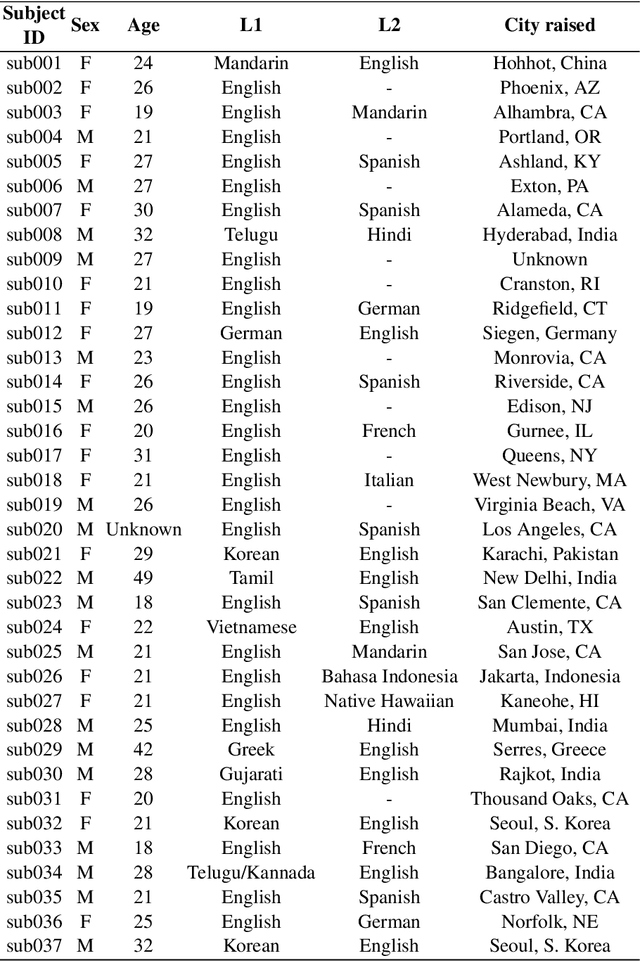
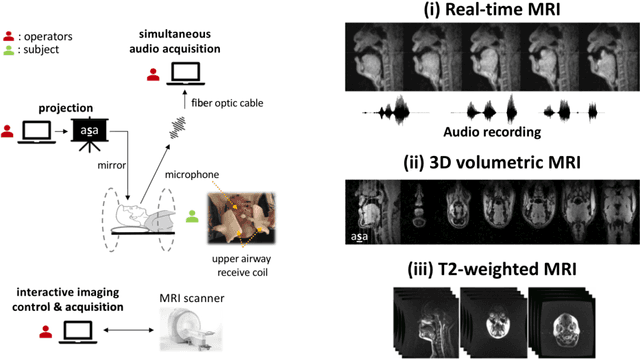
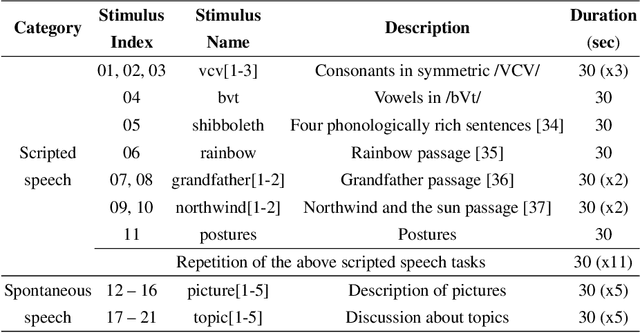
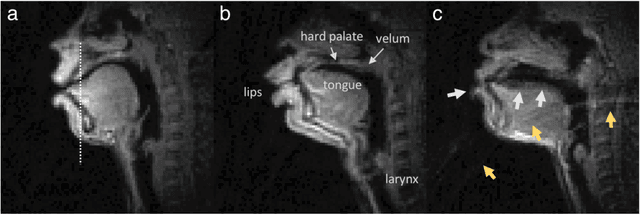
Real-time magnetic resonance imaging (RT-MRI) of human speech production is enabling significant advances in speech science, linguistics, bio-inspired speech technology development, and clinical applications. Easy access to RT-MRI is however limited, and comprehensive datasets with broad access are needed to catalyze research across numerous domains. The imaging of the rapidly moving articulators and dynamic airway shaping during speech demands high spatio-temporal resolution and robust reconstruction methods. Further, while reconstructed images have been published, to-date there is no open dataset providing raw multi-coil RT-MRI data from an optimized speech production experimental setup. Such datasets could enable new and improved methods for dynamic image reconstruction, artifact correction, feature extraction, and direct extraction of linguistically-relevant biomarkers. The present dataset offers a unique corpus of 2D sagittal-view RT-MRI videos along with synchronized audio for 75 subjects performing linguistically motivated speech tasks, alongside the corresponding first-ever public domain raw RT-MRI data. The dataset also includes 3D volumetric vocal tract MRI during sustained speech sounds and high-resolution static anatomical T2-weighted upper airway MRI for each subject.
UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Jan 19, 2021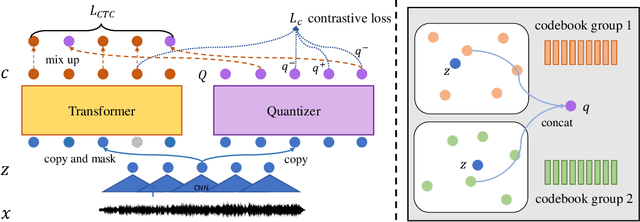
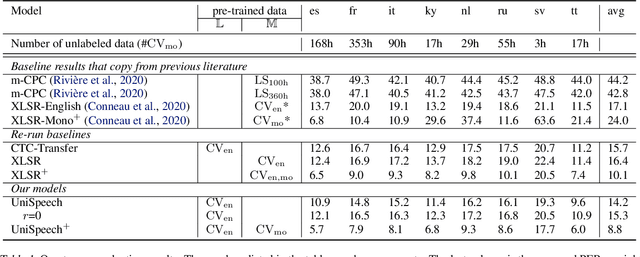

In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.