 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Aug 29, 2024



Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
The ADAIO System at the BEA-2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues
Jun 08, 2023This paper presents the ADAIO team's system entry in the Building Educational Applications (BEA) 2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues. The task aims to assess the performance of state-of-the-art generative models as AI teachers in producing suitable responses within a student-teacher dialogue. Our system comprises evaluating various baseline models using OpenAI GPT-3 and designing diverse prompts to prompt the OpenAI models for teacher response generation. After the challenge, our system achieved second place by employing a few-shot prompt-based approach with the OpenAI text-davinci-003 model. The results highlight the few-shot learning capabilities of large-language models, particularly OpenAI's GPT-3, in the role of AI teachers.
Data-augmented cross-lingual synthesis in a teacher-student framework
Mar 31, 2022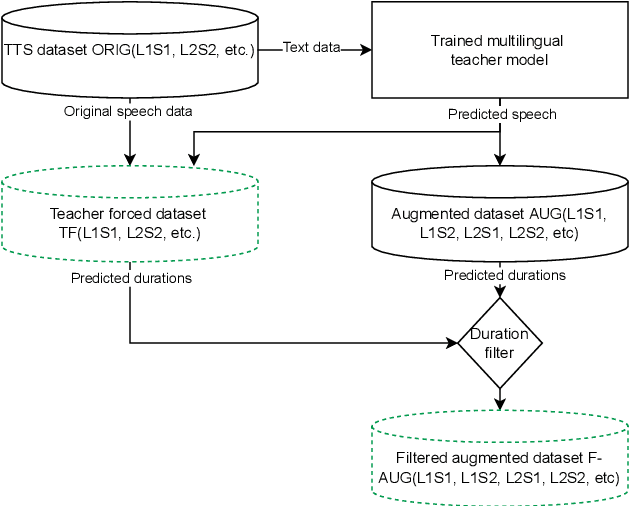
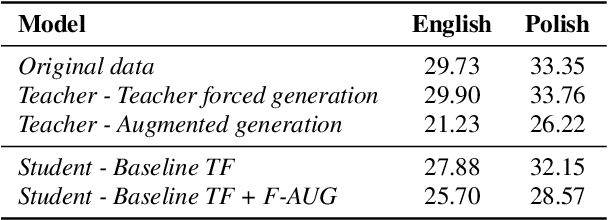
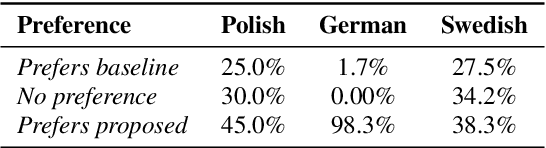
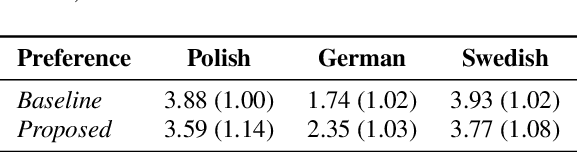
Cross-lingual synthesis can be defined as the task of letting a speaker generate fluent synthetic speech in another language. This is a challenging task, and resulting speech can suffer from reduced naturalness, accented speech, and/or loss of essential voice characteristics. Previous research shows that many models appear to have insufficient generalization capabilities to perform well on every of these cross-lingual aspects. To overcome these generalization problems, we propose to apply the teacher-student paradigm to cross-lingual synthesis. While a teacher model is commonly used to produce teacher forced data, we propose to also use it to produce augmented data of unseen speaker-language pairs, where the aim is to retain essential speaker characteristics. Both sets of data are then used for student model training, which is trained to retain the naturalness and prosodic variation present in the teacher forced data, while learning the speaker identity from the augmented data. Some modifications to the student model are proposed to make the separation of teacher forced and augmented data more straightforward. Results show that the proposed approach improves the retention of speaker characteristics in the speech, while managing to retain high levels of naturalness and prosodic variation.
The Emotional Voices Database: Towards Controlling the Emotion Dimension in Voice Generation Systems
Jun 25, 2018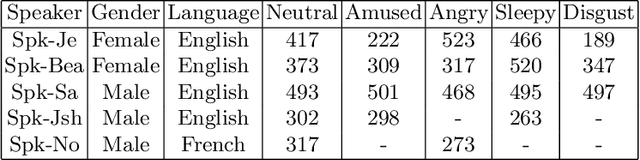
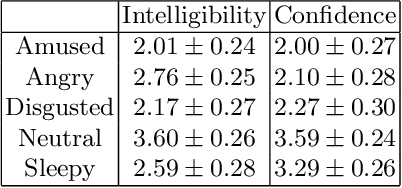
In this paper, we present a database of emotional speech intended to be open-sourced and used for synthesis and generation purpose. It contains data for male and female actors in English and a male actor in French. The database covers 5 emotion classes so it could be suitable to build synthesis and voice transformation systems with the potential to control the emotional dimension in a continuous way. We show the data's efficiency by building a simple MLP system converting neutral to angry speech style and evaluate it via a CMOS perception test. Even though the system is a very simple one, the test show the efficiency of the data which is promising for future work.