 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Guided Variational Autoencoder for Speech Enhancement With a Supervised Classifier
Feb 12, 2021
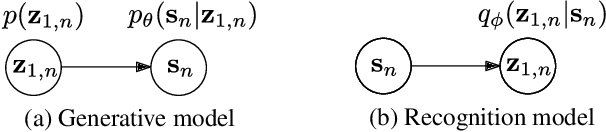
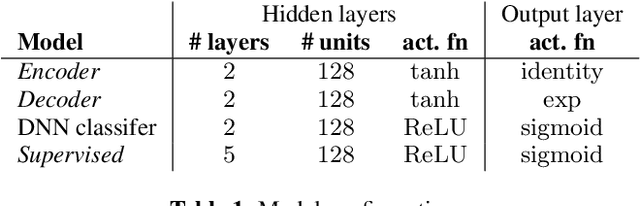
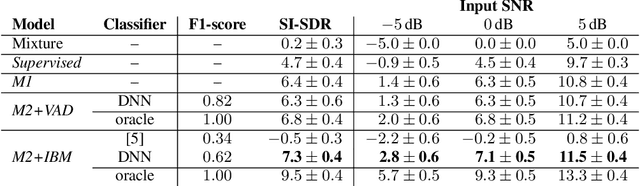
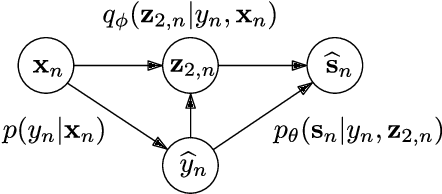
Recently, variational autoencoders have been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. However, variational autoencoders are trained on clean speech only, which results in a limited ability of extracting the speech signal from noisy speech compared to supervised approaches. In this paper, we propose to guide the variational autoencoder with a supervised classifier separately trained on noisy speech. The estimated label is a high-level categorical variable describing the speech signal (e.g. speech activity) allowing for a more informed latent distribution compared to the standard variational autoencoder. We evaluate our method with different types of labels on real recordings of different noisy environments. Provided that the label better informs the latent distribution and that the classifier achieves good performance, the proposed approach outperforms the standard variational autoencoder and a conventional neural network-based supervised approach.
Building an ASR Error Robust Spoken Virtual Patient System in a Highly Class-Imbalanced Scenario Without Speech Data
Apr 11, 2022
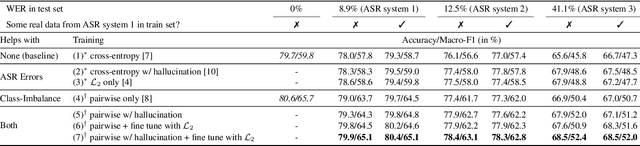
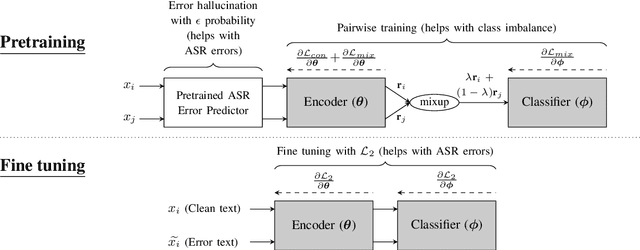

A Virtual Patient (VP) is a powerful tool for training medical students to take patient histories, where responding to a diverse set of spoken questions is essential to simulate natural conversations with a student. The performance of such a Spoken Language Understanding system (SLU) can be adversely affected by both the presence of Automatic Speech Recognition (ASR) errors in the test data and a high degree of class imbalance in the SLU training data. While these two issues have been addressed separately in prior work, we develop a novel two-step training methodology that tackles both these issues effectively in a single dialog agent. As it is difficult to collect spoken data from users without a functioning SLU system, our method does not rely on spoken data for training, rather we use an ASR error predictor to "speechify" the text data. Our method shows significant improvements over strong baselines on the VP intent classification task at various word error rate settings.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022
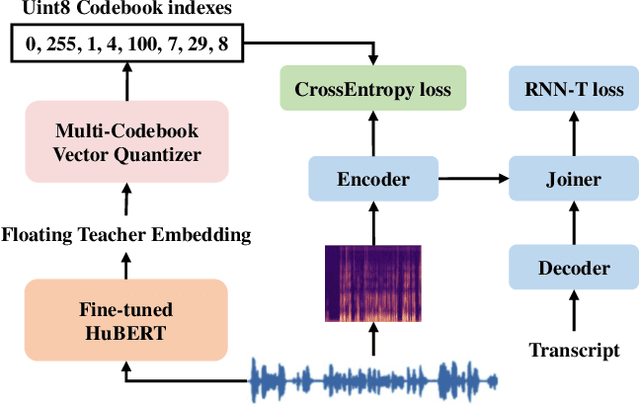

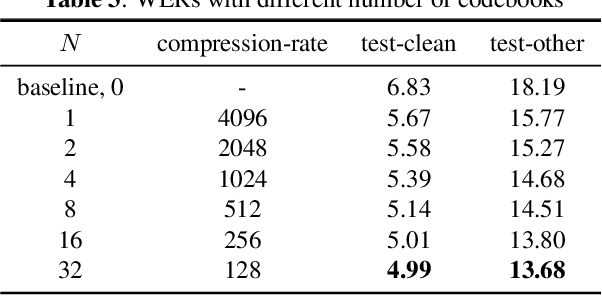
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Three-class Overlapped Speech Detection using a Convolutional Recurrent Neural Network
Apr 07, 2021
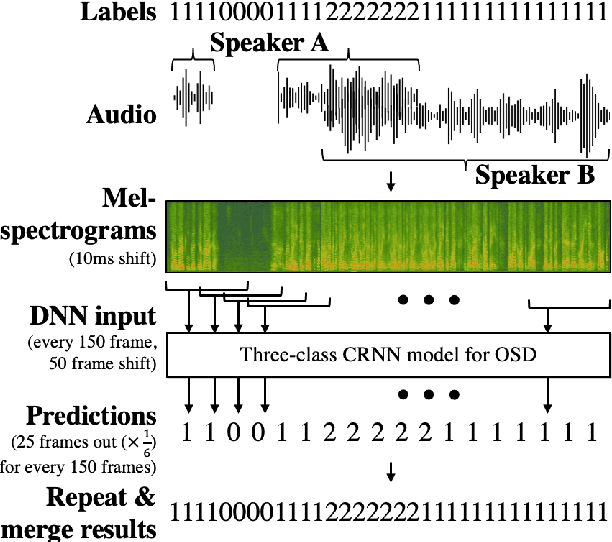
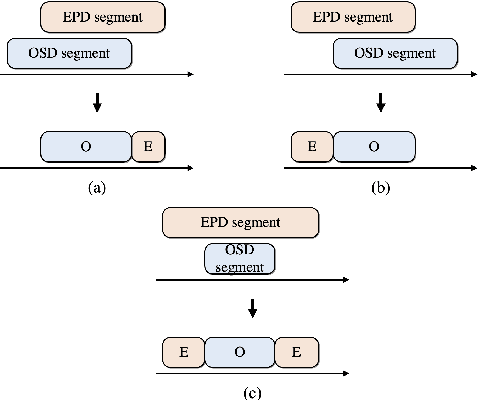
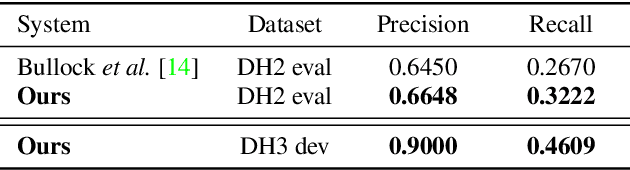
In this work, we propose an overlapped speech detection system trained as a three-class classifier. Unlike conventional systems that perform binary classification as to whether or not a frame contains overlapped speech, the proposed approach classifies into three classes: non-speech, single speaker speech, and overlapped speech. By training a network with the more detailed label definition, the model can learn a better notion on deciding the number of speakers included in a given frame. A convolutional recurrent neural network architecture is explored to benefit from both convolutional layer's capability to model local patterns and recurrent layer's ability to model sequential information. The proposed overlapped speech detection model establishes a state-of-the-art performance with a precision of 0.6648 and a recall of 0.3222 on the DIHARD II evaluation set, showing a 20% increase in recall along with higher precision. In addition, we also introduce a simple approach to utilize the proposed overlapped speech detection model for speaker diarization which ranked third place in the Track 1 of the DIHARD III challenge.
Improving Speech Recognition Accuracy of Local POI Using Geographical Models
Jul 07, 2021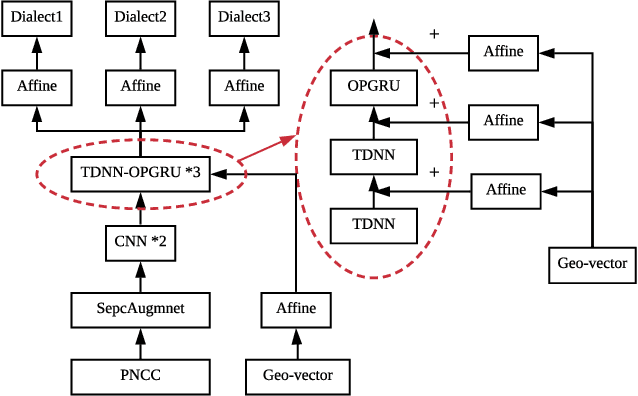
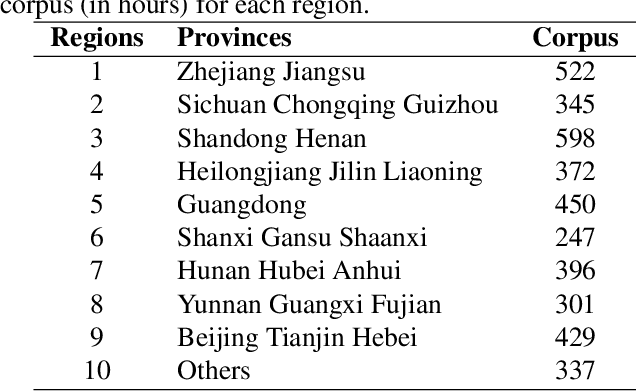
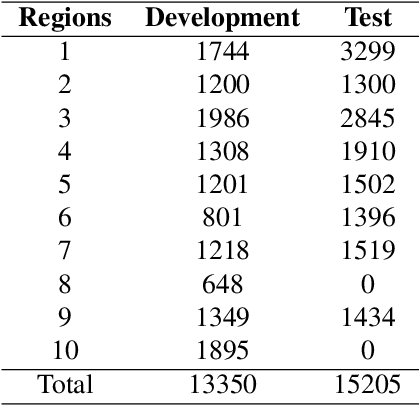
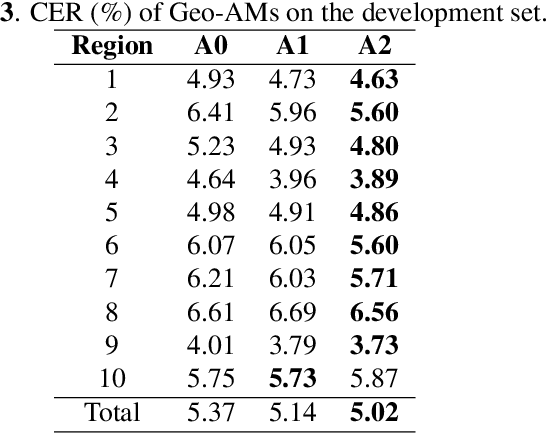
Nowadays voice search for points of interest (POI) is becoming increasingly popular. However, speech recognition for local POI has remained to be a challenge due to multi-dialect and massive POI. This paper improves speech recognition accuracy for local POI from two aspects. Firstly, a geographic acoustic model (Geo-AM) is proposed. The Geo-AM deals with multi-dialect problem using dialect-specific input feature and dialect-specific top layer. Secondly, a group of geo-specific language models (Geo-LMs) are integrated into our speech recognition system to improve recognition accuracy of long tail and homophone POI. During decoding, specific language models are selected on demand according to users' geographic location. Experiments show that the proposed Geo-AM achieves 6.5%$\sim$10.1% relative character error rate (CER) reduction on an accent testset and the proposed Geo-AM and Geo-LM totally achieve over 18.7% relative CER reduction on Tencent Map task.
Continuous Speech Separation with Ad Hoc Microphone Arrays
Mar 03, 2021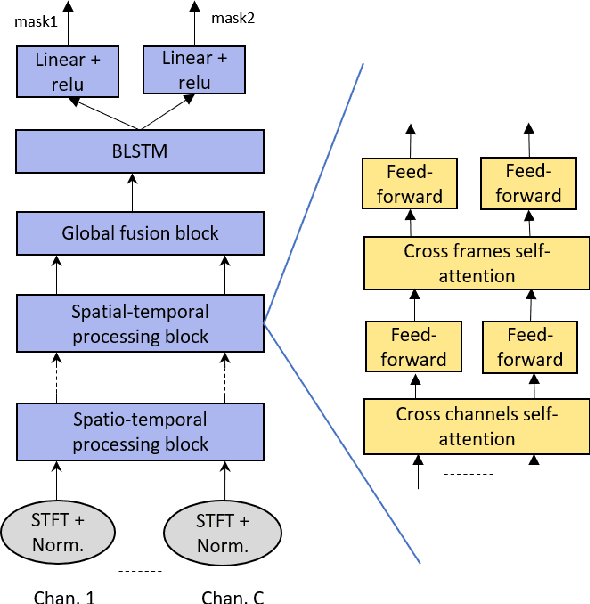

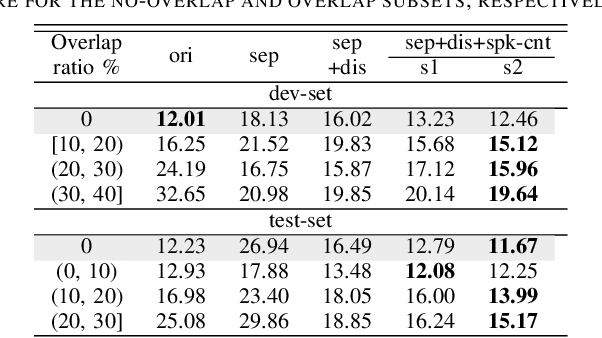
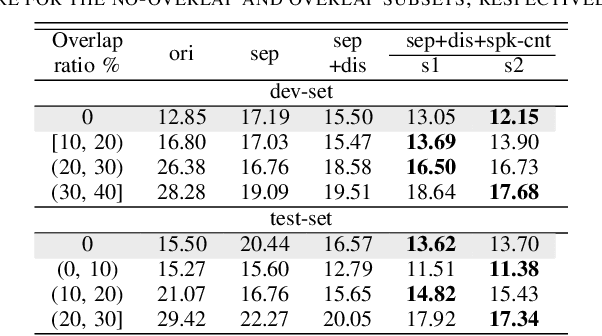
Speech separation has been shown effective for multi-talker speech recognition. Under the ad hoc microphone array setup where the array consists of spatially distributed asynchronous microphones, additional challenges must be overcome as the geometry and number of microphones are unknown beforehand. Prior studies show, with a spatial-temporalinterleaving structure, neural networks can efficiently utilize the multi-channel signals of the ad hoc array. In this paper, we further extend this approach to continuous speech separation. Several techniques are introduced to enable speech separation for real continuous recordings. First, we apply a transformer-based network for spatio-temporal modeling of the ad hoc array signals. In addition, two methods are proposed to mitigate a speech duplication problem during single talker segments, which seems more severe in the ad hoc array scenarios. One method is device distortion simulation for reducing the acoustic mismatch between simulated training data and real recordings. The other is speaker counting to detect the single speaker segments and merge the output signal channels. Experimental results for AdHoc-LibiCSS, a new dataset consisting of continuous recordings of concatenated LibriSpeech utterances obtained by multiple different devices, show the proposed separation method can significantly improve the ASR accuracy for overlapped speech with little performance degradation for single talker segments.
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
Oct 26, 2022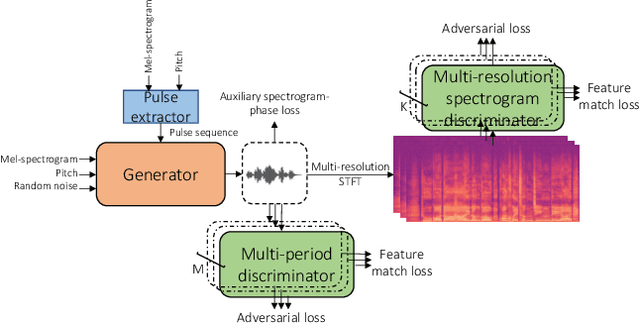
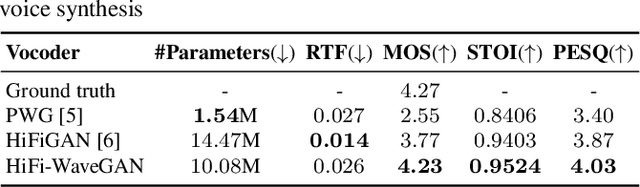
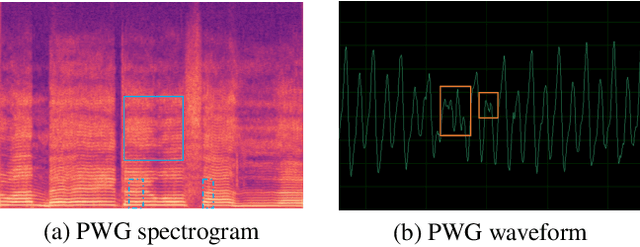
Entertainment-oriented singing voice synthesis (SVS) requires a vocoder to generate high-fidelity (e.g. 48kHz) audio. However, most text-to-speech (TTS) vocoders cannot work well in this scenario even if the neural vocoder for TTS has achieved significant progress. In this paper, we propose HiFi-WaveGAN which is designed for synthesizing the 48kHz high-quality singing voices from the full-band mel-spectrogram in real-time. Specifically, it consists of a generator improved from WaveNet, a multi-period discriminator same to HiFiGAN, and a multi-resolution spectrogram discriminator borrowed from UnivNet. To better reconstruct the high-frequency part from the full-band mel-spectrogram, we design a novel auxiliary spectrogram-phase loss to train the neural network, which can also accelerate the training process. The experimental result shows that our proposed HiFi-WaveGAN significantly outperforms other neural vocoders such as Parallel WaveGAN (PWG) and HiFiGAN in the mean opinion score (MOS) metric for the 48kHz SVS task. And a comparative study of HiFi-WaveGAN with/without phase loss term proves that phase loss indeed improves the training speed. Besides, we also compare the spectrogram generated by our HiFi-WaveGAN and PWG, which shows our HiFi-WaveGAN has a more powerful ability to model the high-frequency parts.
Time-domain Speech Enhancement with Generative Adversarial Learning
Mar 30, 2021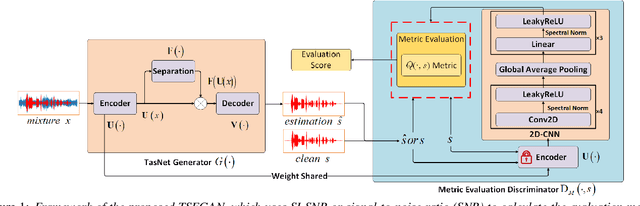
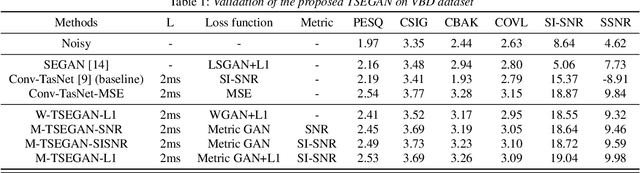
Speech enhancement aims to obtain speech signals with high intelligibility and quality from noisy speech. Recent work has demonstrated the excellent performance of time-domain deep learning methods, such as Conv-TasNet. However, these methods can be degraded by the arbitrary scales of the waveform induced by the scale-invariant signal-to-noise ratio (SI-SNR) loss. This paper proposes a new framework called Time-domain Speech Enhancement Generative Adversarial Network (TSEGAN), which is an extension of the generative adversarial network (GAN) in time-domain with metric evaluation to mitigate the scaling problem, and provide model training stability, thus achieving performance improvement. In addition, we provide a new method based on objective function mapping for the theoretical analysis of the performance of Metric GAN, and explain why it is better than the Wasserstein GAN. Experiments conducted demonstrate the effectiveness of our proposed method, and illustrate the advantage of Metric GAN.
Towards Transferable Speech Emotion Representation: On loss functions for cross-lingual latent representations
Mar 28, 2022

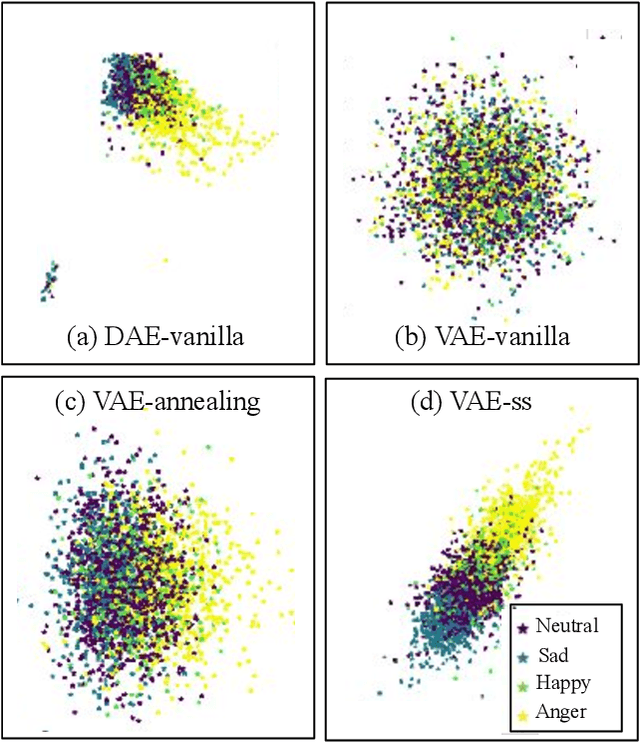
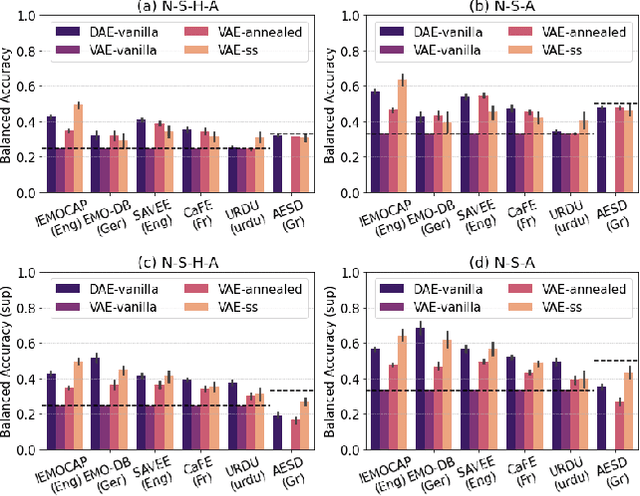
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques which provide transfer learning possibilities. However, generalizing over languages, corpora and recording conditions is still an open challenge. In this work we address this gap by exploring loss functions that aid in transferability, specifically to non-tonal languages. We propose a variational autoencoder (VAE) with KL annealing and a semi-supervised VAE to obtain more consistent latent embedding distributions across data sets. To ensure transferability, the distribution of the latent embedding should be similar across non-tonal languages (data sets). We start by presenting a low-complexity SER based on a denoising-autoencoder, which achieves an unweighted classification accuracy of over 52.09% for four-class emotion classification. This performance is comparable to that of similar baseline methods. Following this, we employ a VAE, the semi-supervised VAE and the VAE with KL annealing to obtain a more regularized latent space. We show that while the DAE has the highest classification accuracy among the methods, the semi-supervised VAE has a comparable classification accuracy and a more consistent latent embedding distribution over data sets.
Simple and Effective Multi-sentence TTS with Expressive and Coherent Prosody
Jun 29, 2022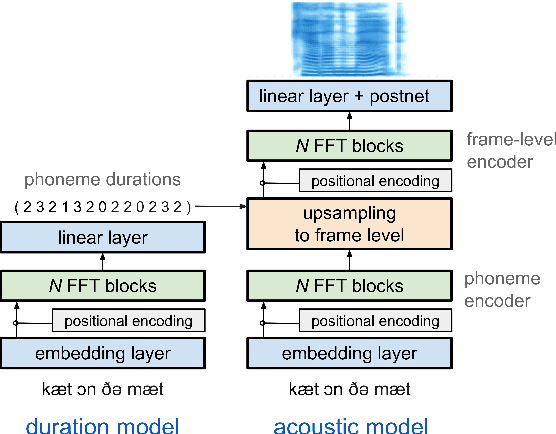

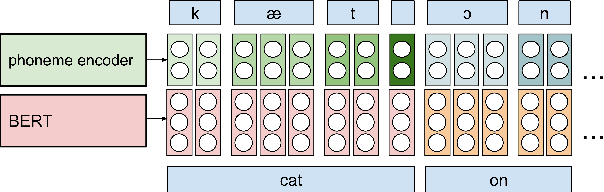
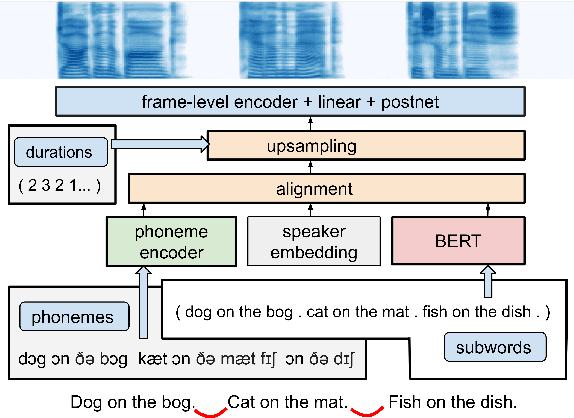
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.