 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
May 30, 2022
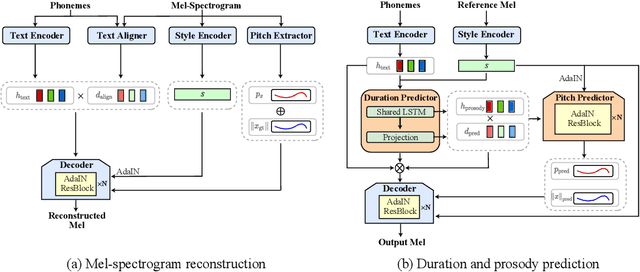


Text-to-Speech (TTS) has recently seen great progress in synthesizing high-quality speech owing to the rapid development of parallel TTS systems, but producing speech with naturalistic prosodic variations, speaking styles and emotional tones remains challenging. Moreover, since duration and speech are generated separately, parallel TTS models still have problems finding the best monotonic alignments that are crucial for naturalistic speech synthesis. Here, we propose StyleTTS, a style-based generative model for parallel TTS that can synthesize diverse speech with natural prosody from a reference speech utterance. With novel Transferable Monotonic Aligner (TMA) and duration-invariant data augmentation schemes, our method significantly outperforms state-of-the-art models on both single and multi-speaker datasets in subjective tests of speech naturalness and speaker similarity. Through self-supervised learning of the speaking styles, our model can synthesize speech with the same prosodic and emotional tone as any given reference speech without the need for explicitly labeling these categories.
Joint Audio/Text Training for Transformer Rescorer of Streaming Speech Recognition
Oct 31, 2022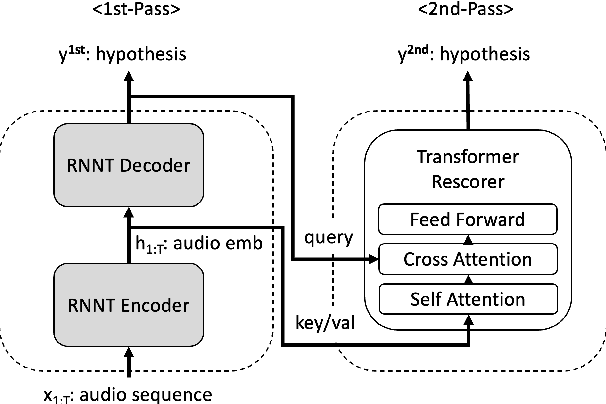

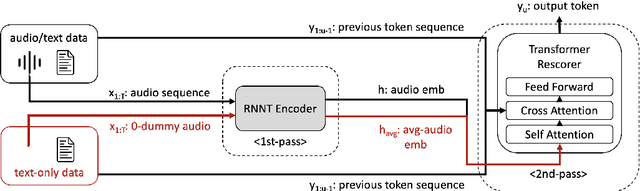
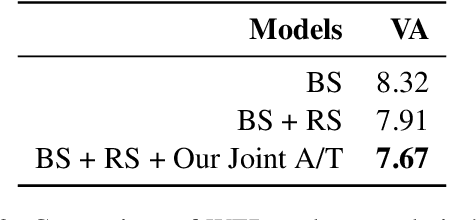
Recently, there has been an increasing interest in two-pass streaming end-to-end speech recognition (ASR) that incorporates a 2nd-pass rescoring model on top of the conventional 1st-pass streaming ASR model to improve recognition accuracy while keeping latency low. One of the latest 2nd-pass rescoring model, Transformer Rescorer, takes the n-best initial outputs and audio embeddings from the 1st-pass model, and then choose the best output by re-scoring the n-best initial outputs. However, training this Transformer Rescorer requires expensive paired audio-text training data because the model uses audio embeddings as input. In this work, we present our Joint Audio/Text training method for Transformer Rescorer, to leverage unpaired text-only data which is relatively cheaper than paired audio-text data. We evaluate Transformer Rescorer with our Joint Audio/Text training on Librispeech dataset as well as our large-scale in-house dataset and show that our training method can improve word error rate (WER) significantly compared to standard Transformer Rescorer without requiring any extra model parameters or latency.
Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis
May 09, 2022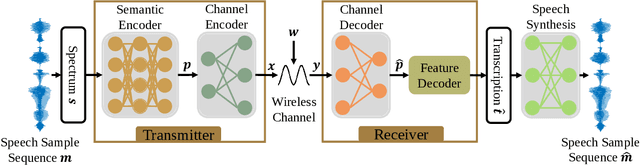
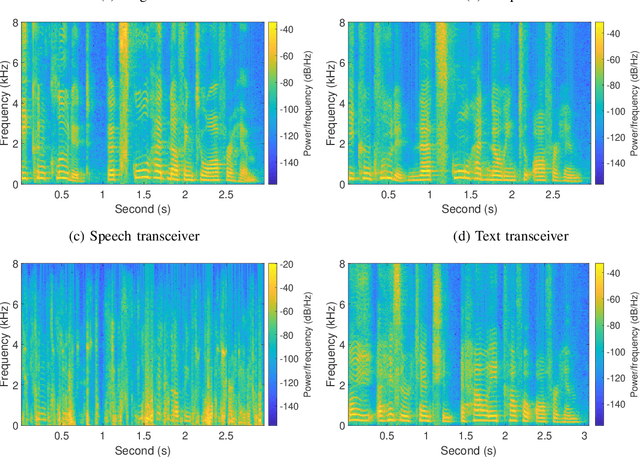
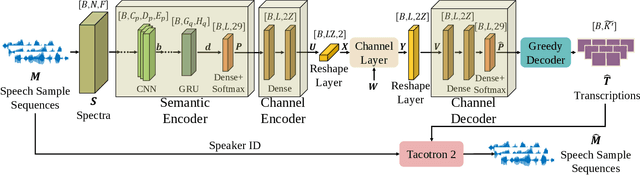
In this paper, we develop a deep learning based semantic communication system for speech transmission, named DeepSC-ST. We take the speech recognition and speech synthesis as the transmission tasks of the communication system, respectively. First, the speech recognition-related semantic features are extracted for transmission by a joint semantic-channel encoder and the text is recovered at the receiver based on the received semantic features, which significantly reduces the required amount of data transmission without performance degradation. Then, we perform speech synthesis at the receiver, which dedicates to re-generate the speech signals by feeding the recognized text transcription into a neural network based speech synthesis module. To enable the DeepSC-ST adaptive to dynamic channel environments, we identify a robust model to cope with different channel conditions. According to the simulation results, the proposed DeepSC-ST significantly outperforms conventional communication systems, especially in the low signal-to-noise ratio (SNR) regime. A demonstration is further developed as a proof-of-concept of the DeepSC-ST.
Recycling an anechoic pre-trained speech separation deep neural network for binaural dereverberation of a single source
Aug 09, 2022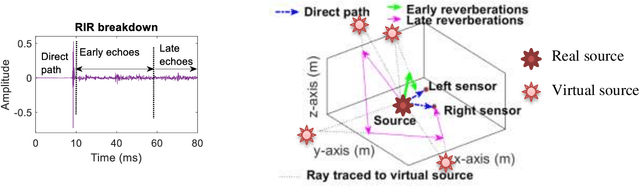

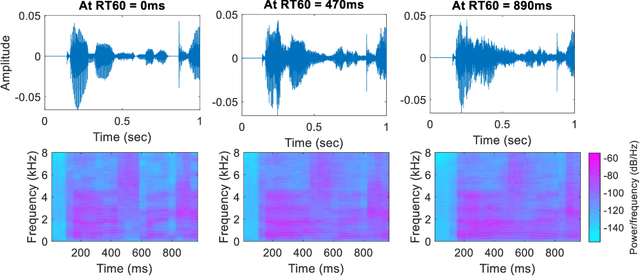

Reverberation results in reduced intelligibility for both normal and hearing-impaired listeners. This paper presents a novel psychoacoustic approach of dereverberation of a single speech source by recycling a pre-trained binaural anechoic speech separation neural network. As training the deep neural network (DNN) is a lengthy and computationally expensive process, the advantage of using a pre-trained separation network for dereverberation is that the network does not need to be retrained, saving both time and computational resources. The interaural cues of a reverberant source are given to this pretrained neural network to discriminate between the direct path signal and the reverberant speech. The results show an average improvement of 1.3% in signal intelligibility, 0.83 dB in SRMR (signal to reverberation energy ratio) and 0.16 points in perceptual evaluation of speech quality (PESQ) over other state-of-the-art signal processing dereverberation algorithms and 14% in intelligibility and 0.35 points in quality over orthogonal matching pursuit with spectral subtraction (OSS), a machine learning based dereverberation algorithm.
Text-only domain adaptation for end-to-end ASR using integrated text-to-mel-spectrogram generator
Feb 27, 2023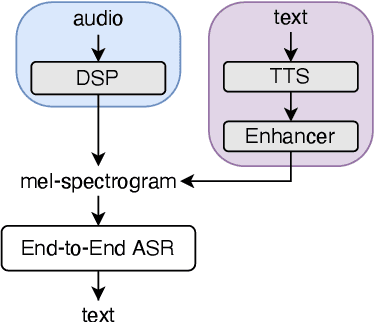

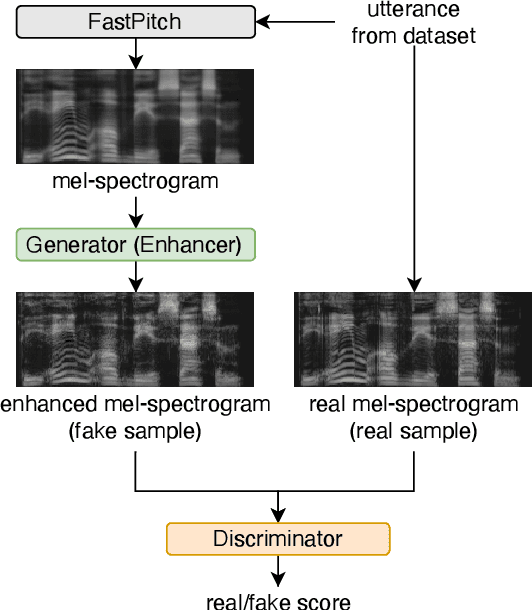
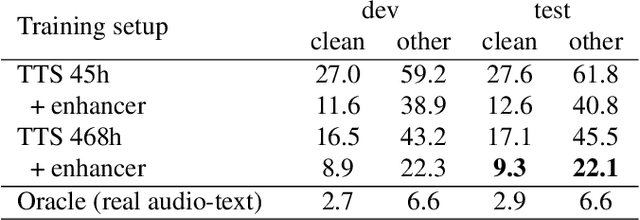
We propose an end-to-end ASR system that can be trained on transcribed speech data, text data, or a mixture of both. For text-only training, our extended ASR model uses an integrated auxiliary TTS block that creates mel spectrograms from the text. This block contains a conventional non-autoregressive text-to-mel-spectrogram generator augmented with a GAN enhancer to improve the spectrogram quality. The proposed system can improve the accuracy of the ASR model on a new domain by using text-only data, and allows to significantly surpass conventional audio-text training by using large text corpora.
Tokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems
Apr 11, 2022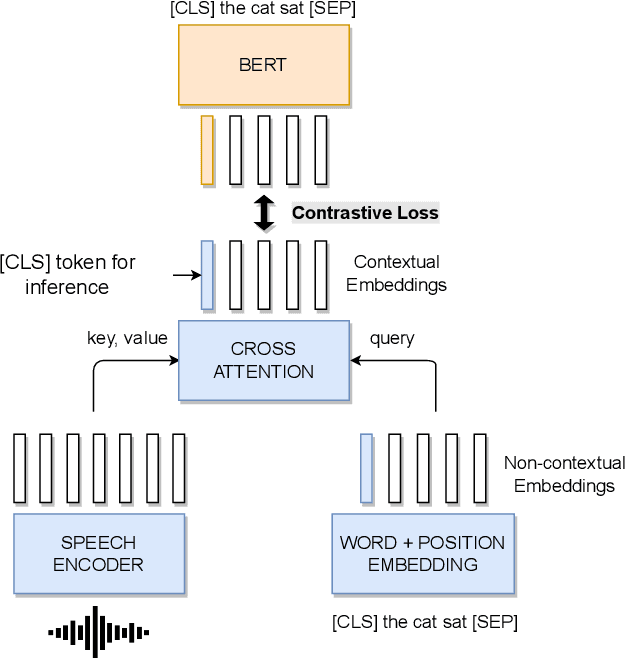
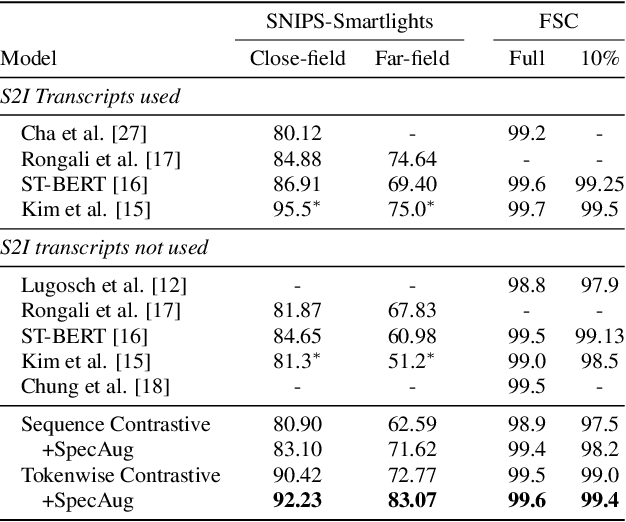
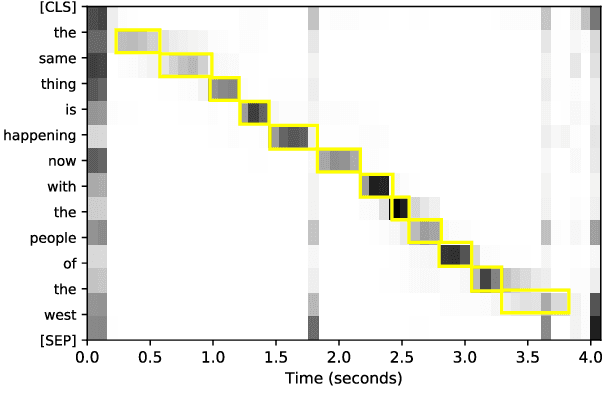
Recent advances in End-to-End (E2E) Spoken Language Understanding (SLU) have been primarily due to effective pretraining of speech representations. One such pretraining paradigm is the distillation of semantic knowledge from state-of-the-art text-based models like BERT to speech encoder neural networks. This work is a step towards doing the same in a much more efficient and fine-grained manner where we align speech embeddings and BERT embeddings on a token-by-token basis. We introduce a simple yet novel technique that uses a cross-modal attention mechanism to extract token-level contextual embeddings from a speech encoder such that these can be directly compared and aligned with BERT based contextual embeddings. This alignment is performed using a novel tokenwise contrastive loss. Fine-tuning such a pretrained model to perform intent recognition using speech directly yields state-of-the-art performance on two widely used SLU datasets. Our model improves further when fine-tuned with additional regularization using SpecAugment especially when speech is noisy, giving an absolute improvement as high as 8% over previous results.
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition
May 17, 2022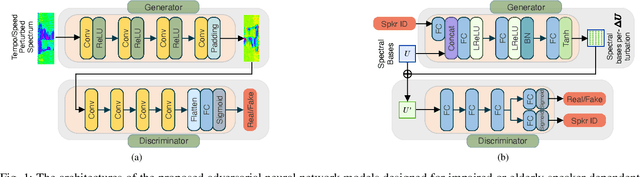
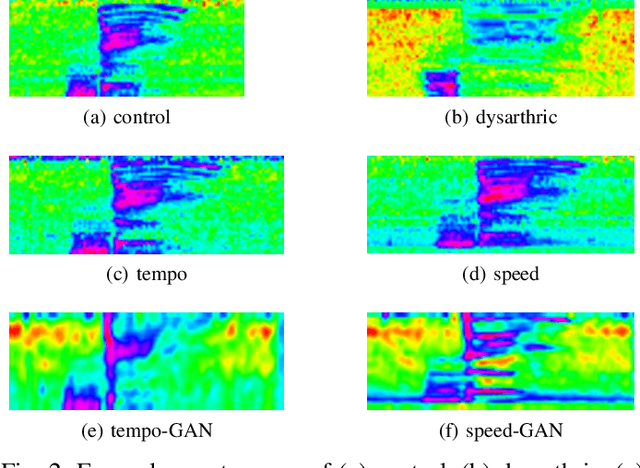
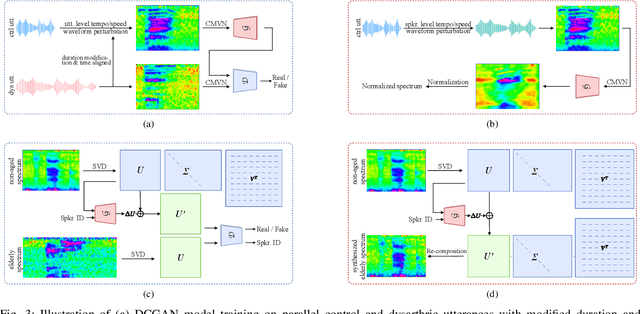
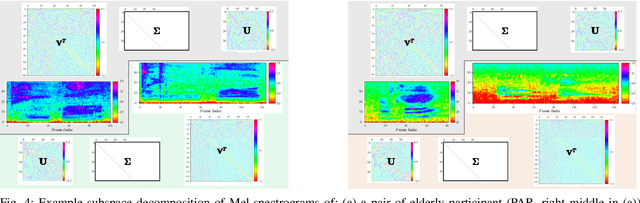
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. It is difficult to collect large quantities of such data for ASR system development due to the mobility issues often found among these users. To this end, data augmentation techniques play a vital role. In contrast to existing data augmentation techniques only modifying the speaking rate or overall shape of spectral contour, fine-grained spectro-temporal differences between dysarthric, elderly and normal speech are modelled using a novel set of speaker dependent (SD) generative adversarial networks (GAN) based data augmentation approaches in this paper. These flexibly allow both: a) temporal or speed perturbed normal speech spectra to be modified and closer to those of an impaired speaker when parallel speech data is available; and b) for non-parallel data, the SVD decomposed normal speech spectral basis features to be transformed into those of a target elderly speaker before being re-composed with the temporal bases to produce the augmented data for state-of-the-art TDNN and Conformer ASR system training. Experiments are conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed GAN based data augmentation approaches consistently outperform the baseline speed perturbation method by up to 0.91% and 3.0% absolute (9.61% and 6.4% relative) WER reduction on the TORGO and DementiaBank data respectively. Consistent performance improvements are retained after applying LHUC based speaker adaptation.
Improving Target Speaker Extraction with Sparse LDA-transformed Speaker Embeddings
Jan 16, 2023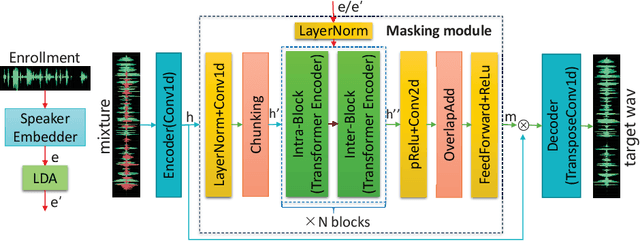

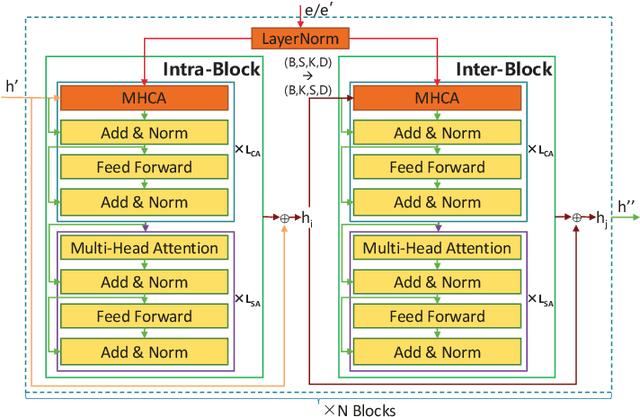
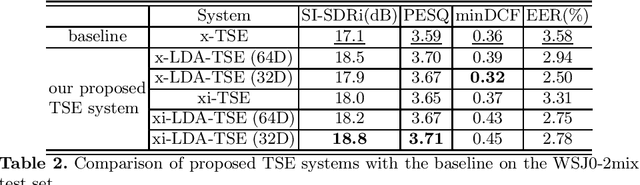
As a practical alternative of speech separation, target speaker extraction (TSE) aims to extract the speech from the desired speaker using additional speaker cue extracted from the speaker. Its main challenge lies in how to properly extract and leverage the speaker cue to benefit the extracted speech quality. The cue extraction method adopted in majority existing TSE studies is to directly utilize discriminative speaker embedding, which is extracted from the pre-trained models for speaker verification. Although the high speaker discriminability is a most desirable property for speaker verification task, we argue that it may be too sophisticated for TSE. In this study, we propose that a simplified speaker cue with clear class separability might be preferred for TSE. To verify our proposal, we introduce several forms of speaker cues, including naive speaker embedding (such as, x-vector and xi-vector) and new speaker embeddings produced from sparse LDA-transform. Corresponding TSE models are built by integrating these speaker cues with SepFormer (one SOTA speech separation model). Performances of these TSE models are examined on the benchmark WSJ0-2mix dataset. Experimental results validate the effectiveness and generalizability of our proposal, showing up to 9.9% relative improvement in SI-SDRi. Moreover, with SI-SDRi of 19.4 dB and PESQ of 3.78, our best TSE system significantly outperforms the current SOTA systems and offers the top TSE results reported till date on the WSJ0-2mix.
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
Mar 16, 2023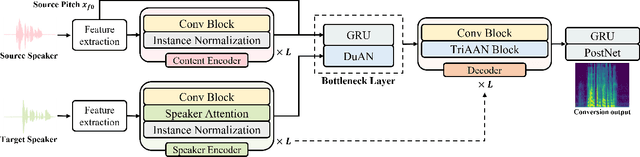
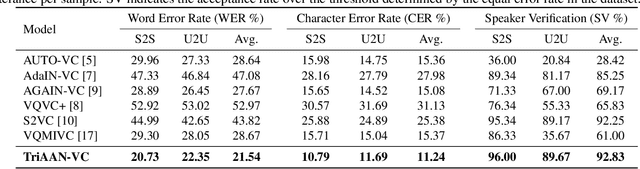
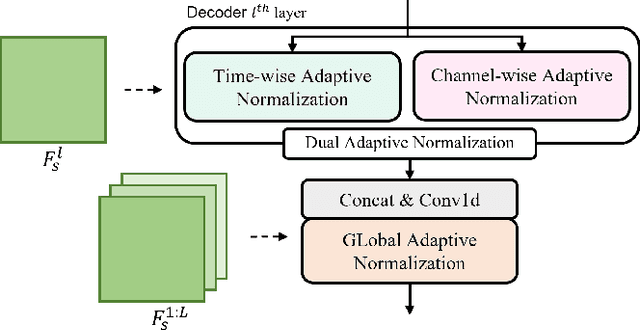
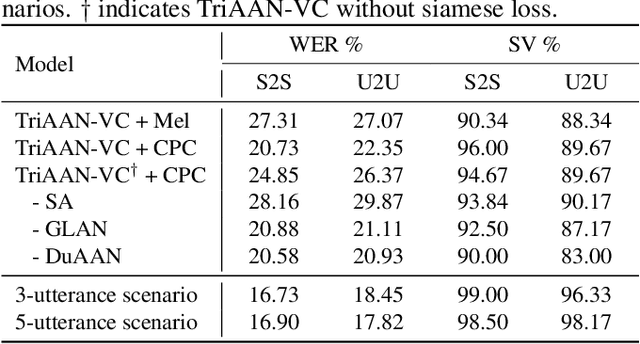
Voice Conversion (VC) must be achieved while maintaining the content of the source speech and representing the characteristics of the target speaker. The existing methods do not simultaneously satisfy the above two aspects of VC, and their conversion outputs suffer from a trade-off problem between maintaining source contents and target characteristics. In this study, we propose Triple Adaptive Attention Normalization VC (TriAAN-VC), comprising an encoder-decoder and an attention-based adaptive normalization block, that can be applied to non-parallel any-to-any VC. The proposed adaptive normalization block extracts target speaker representations and achieves conversion while minimizing the loss of the source content with siamese loss. We evaluated TriAAN-VC on the VCTK dataset in terms of the maintenance of the source content and target speaker similarity. Experimental results for one-shot VC suggest that TriAAN-VC achieves state-of-the-art performance while mitigating the trade-off problem encountered in the existing VC methods.
DistillW2V2: A Small and Streaming Wav2vec 2.0 Based ASR Model
Mar 16, 2023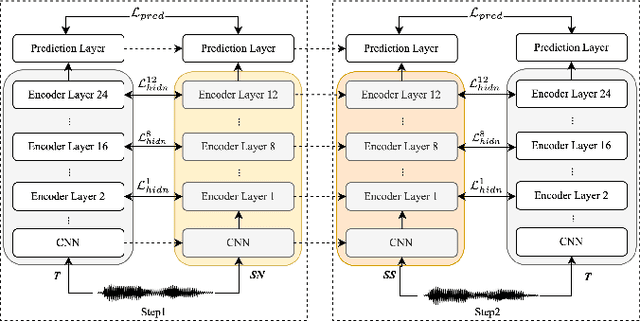
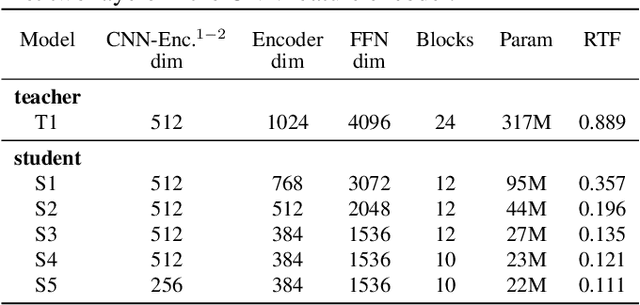
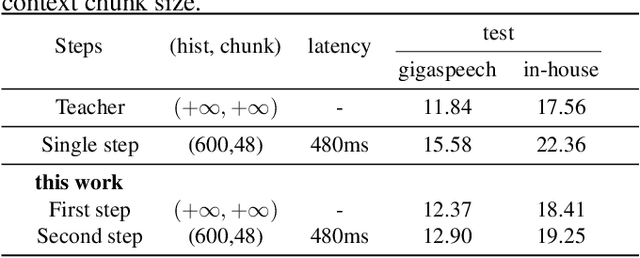
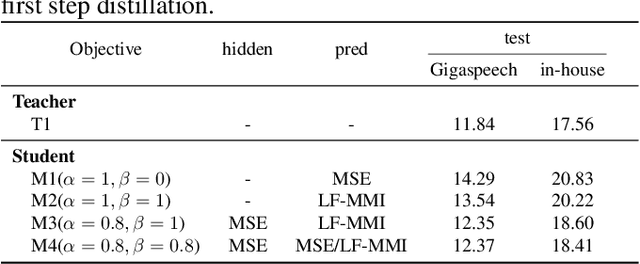
Wav2vec 2.0 (W2V2) has shown impressive performance in automatic speech recognition (ASR). However, the large model size and the non-streaming architecture make it hard to be used under low-resource or streaming scenarios. In this work, we propose a two-stage knowledge distillation method to solve these two problems: the first step is to make the big and non-streaming teacher model smaller, and the second step is to make it streaming. Specially, we adopt the MSE loss for the distillation of hidden layers and the modified LF-MMI loss for the distillation of the prediction layer. Experiments are conducted on Gigaspeech, Librispeech, and an in-house dataset. The results show that the distilled student model (DistillW2V2) we finally get is 8x faster and 12x smaller than the original teacher model. For the 480ms latency setup, the DistillW2V2's relative word error rate (WER) degradation varies from 9% to 23.4% on test sets, which reveals a promising way to extend the W2V2's application scope.