 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Dependencies of Discrete Speech Representations with Neural Hidden Markov Models
Oct 29, 2022
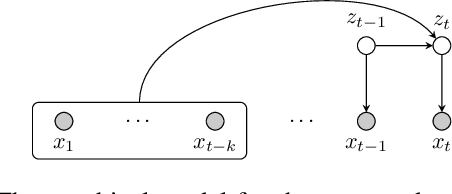
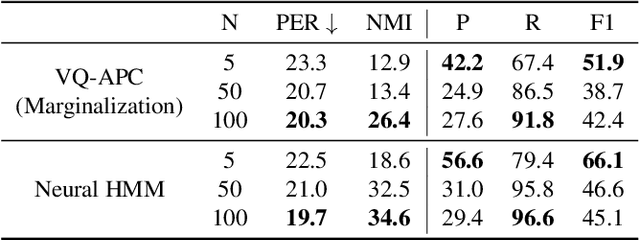
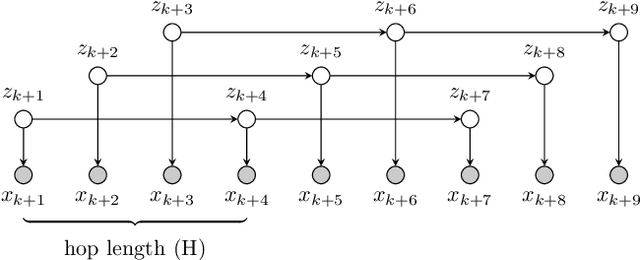
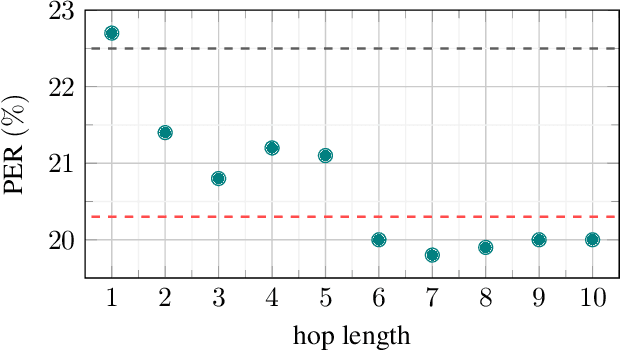
While discrete latent variable models have had great success in self-supervised learning, most models assume that frames are independent. Due to the segmental nature of phonemes in speech perception, modeling dependencies among latent variables at the frame level can potentially improve the learned representations on phonetic-related tasks. In this work, we assume Markovian dependencies among latent variables, and propose to learn speech representations with neural hidden Markov models. Our general framework allows us to compare to self-supervised models that assume independence, while keeping the number of parameters fixed. The added dependencies improve the accessibility of phonetic information, phonetic segmentation, and the cluster purity of phones, showcasing the benefit of the assumed dependencies.
LibriS2S: A German-English Speech-to-Speech Translation Corpus
Apr 22, 2022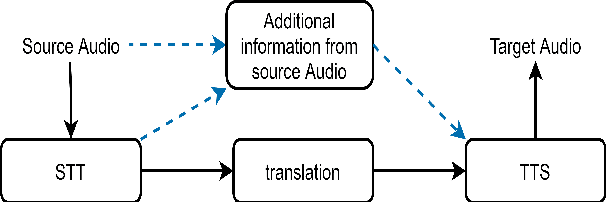
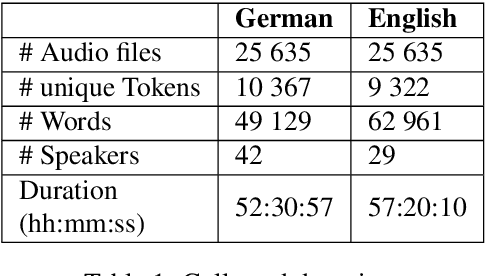
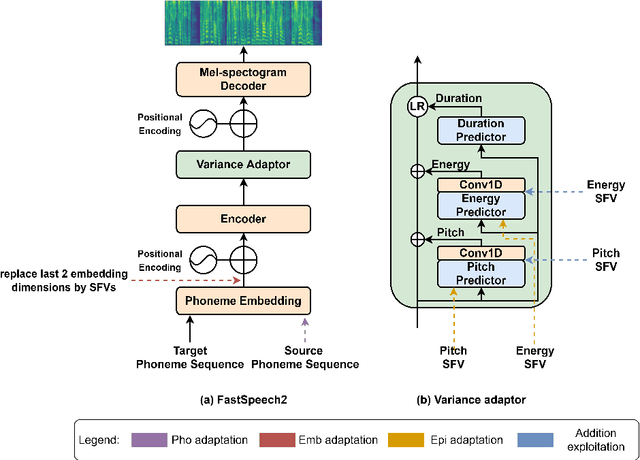
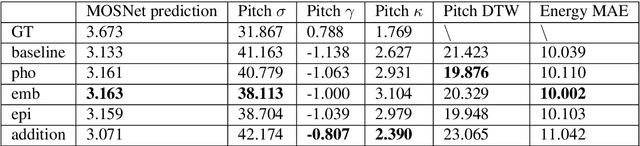
Recently, we have seen an increasing interest in the area of speech-to-text translation. This has led to astonishing improvements in this area. In contrast, the activities in the area of speech-to-speech translation is still limited, although it is essential to overcome the language barrier. We believe that one of the limiting factors is the availability of appropriate training data. We address this issue by creating LibriS2S, to our knowledge the first publicly available speech-to-speech training corpus between German and English. For this corpus, we used independently created audio for German and English leading to an unbiased pronunciation of the text in both languages. This allows the creation of a new text-to-speech and speech-to-speech translation model that directly learns to generate the speech signal based on the pronunciation of the source language. Using this created corpus, we propose Text-to-Speech models based on the example of the recently proposed FastSpeech 2 model that integrates source language information. We do this by adapting the model to take information such as the pitch, energy or transcript from the source speech as additional input.
TorchDIVA: An Extensible Computational Model of Speech Production built on an Open-Source Machine Learning Library
Oct 17, 2022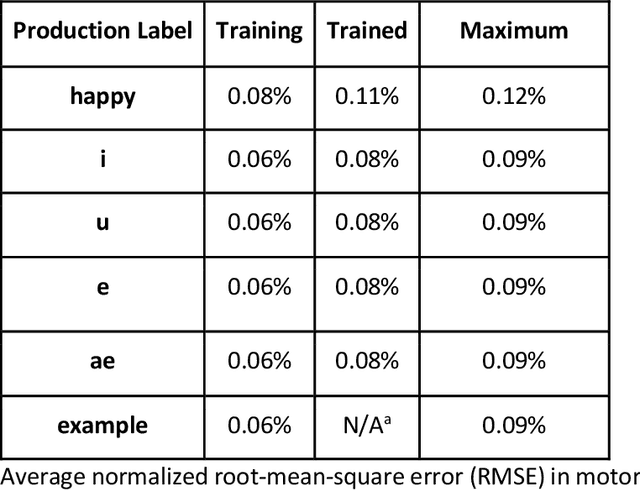
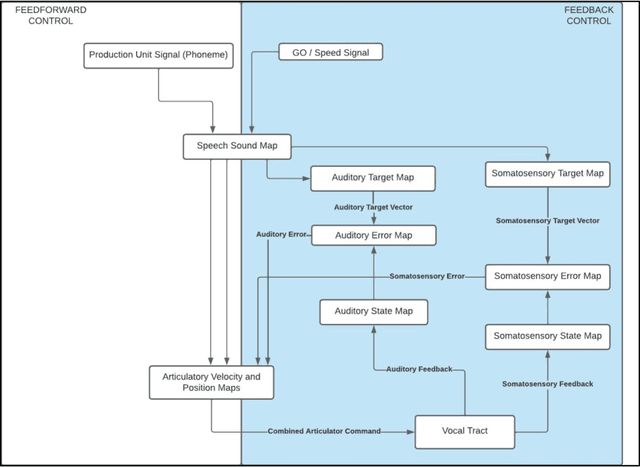
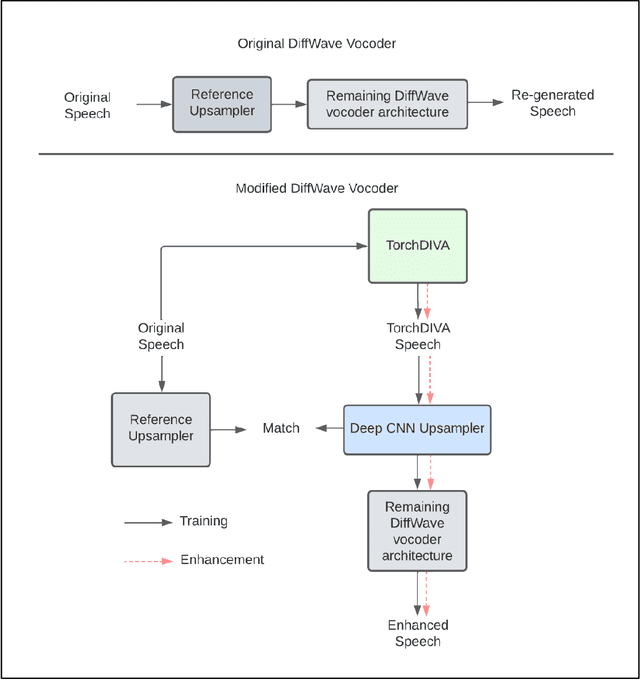
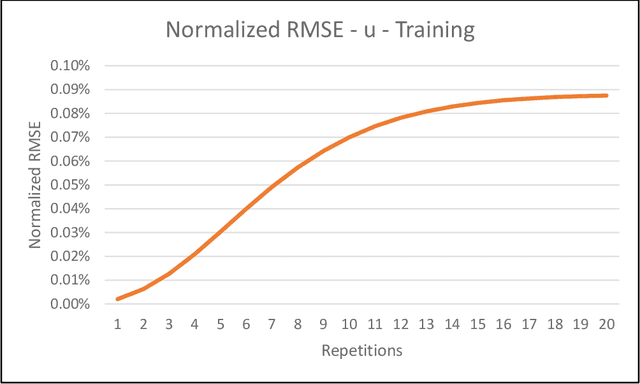
The DIVA model is a computational model of speech motor control that combines a simulation of the brain regions responsible for speech production with a model of the human vocal tract. The model is currently implemented in Matlab Simulink; however, this is less than ideal as most of the development in speech technology research is done in Python. This means there is a wealth of machine learning tools which are freely available in the Python ecosystem that cannot be easily integrated with DIVA. We present TorchDIVA, a full rebuild of DIVA in Python using PyTorch tensors. DIVA source code was directly translated from Matlab to Python, and built-in Simulink signal blocks were implemented from scratch. After implementation, the accuracy of each module was evaluated via systematic block-by-block validation. The TorchDIVA model is shown to produce outputs that closely match those of the original DIVA model, with a negligible difference between the two. We additionally present an example of the extensibility of TorchDIVA as a research platform. Speech quality enhancement in TorchDIVA is achieved through an integration with an existing PyTorch generative vocoder called DiffWave. A modified DiffWave mel-spectrum upsampler was trained on human speech waveforms and conditioned on the TorchDIVA speech production. The results indicate improved speech quality metrics in the DiffWave-enhanced output as compared to the baseline. This enhancement would have been difficult or impossible to accomplish in the original Matlab implementation. This proof-of-concept demonstrates the value TorchDIVA will bring to the research community. Researchers can download the new implementation at: https://github.com/skinahan/DIVA_PyTorch
Multilingual analysis of intelligibility classification using English, Korean, and Tamil dysarthric speech datasets
Sep 27, 2022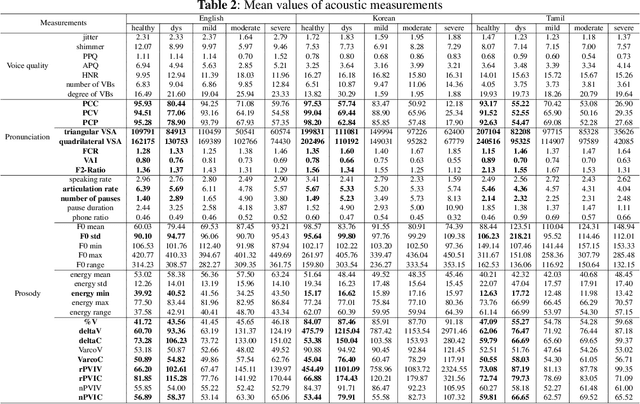
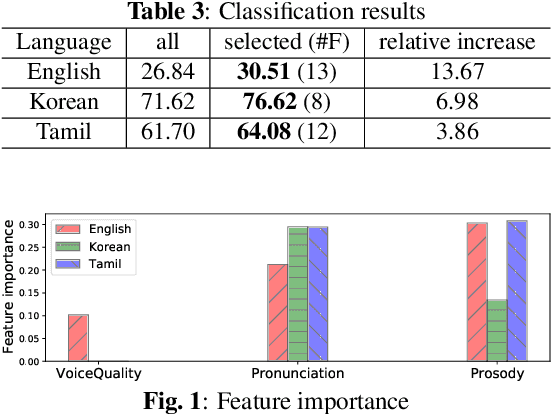
This paper analyzes dysarthric speech datasets from three languages with different prosodic systems: English, Korean, and Tamil. We inspect 39 acoustic measurements which reflect three speech dimensions including voice quality, pronunciation, and prosody. As multilingual analysis, examination on the mean values of acoustic measurements by intelligibility levels is conducted. Further, automatic intelligibility classification is performed to scrutinize the optimal feature set by languages. Analyses suggest pronunciation features, such as Percentage of Correct Consonants, Percentage of Correct Vowels, and Percentage of Correct Phonemes to be language-independent measurements. Voice quality and prosody features, however, generally present different aspects by languages. Experimental results additionally show that different speech dimension play a greater role for different languages: prosody for English, pronunciation for Korean, both prosody and pronunciation for Tamil. This paper contributes to speech pathology in that it differentiates between language-independent and language-dependent measurements in intelligibility classification for English, Korean, and Tamil dysarthric speech.
Multi-Speaker Multi-Style Speech Synthesis with Timbre and Style Disentanglement
Nov 02, 2022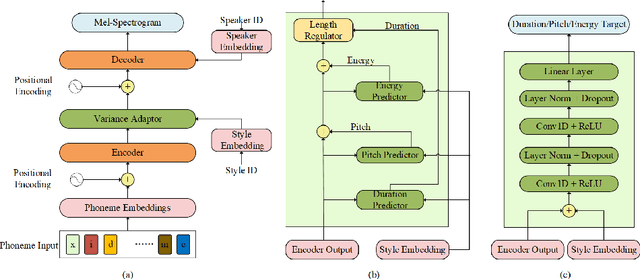
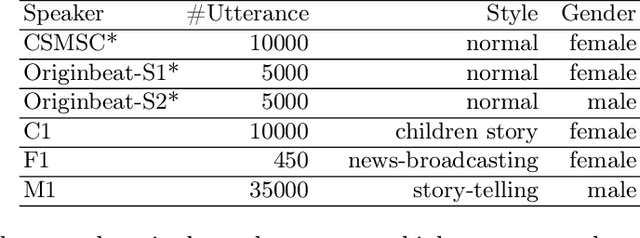

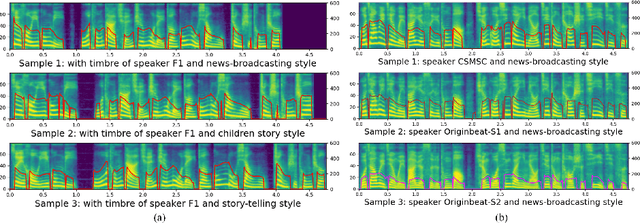
Disentanglement of a speaker's timbre and style is very important for style transfer in multi-speaker multi-style text-to-speech (TTS) scenarios. With the disentanglement of timbres and styles, TTS systems could synthesize expressive speech for a given speaker with any style which has been seen in the training corpus. However, there are still some shortcomings with the current research on timbre and style disentanglement. The current method either requires single-speaker multi-style recordings, which are difficult and expensive to collect, or uses a complex network and complicated training method, which is difficult to reproduce and control the style transfer behavior. To improve the disentanglement effectiveness of timbres and styles, and to remove the reliance on single-speaker multi-style corpus, a simple but effective timbre and style disentanglement method is proposed in this paper. The FastSpeech2 network is employed as the backbone network, with explicit duration, pitch, and energy trajectory to represent the style. Each speaker's data is considered as a separate and isolated style, then a speaker embedding and a style embedding are added to the FastSpeech2 network to learn disentangled representations. Utterance level pitch and energy normalization are utilized to improve the decoupling effect. Experimental results demonstrate that the proposed model could synthesize speech with any style seen during training with high style similarity while maintaining very high speaker similarity.
Advancing Stuttering Detection via Data Augmentation, Class-Balanced Loss and Multi-Contextual Deep Learning
Feb 21, 2023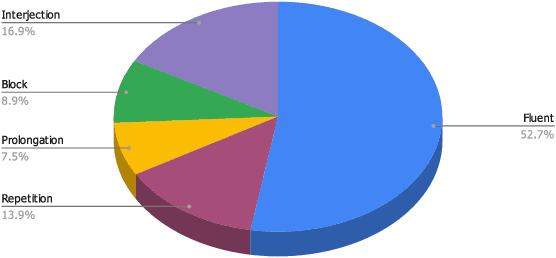
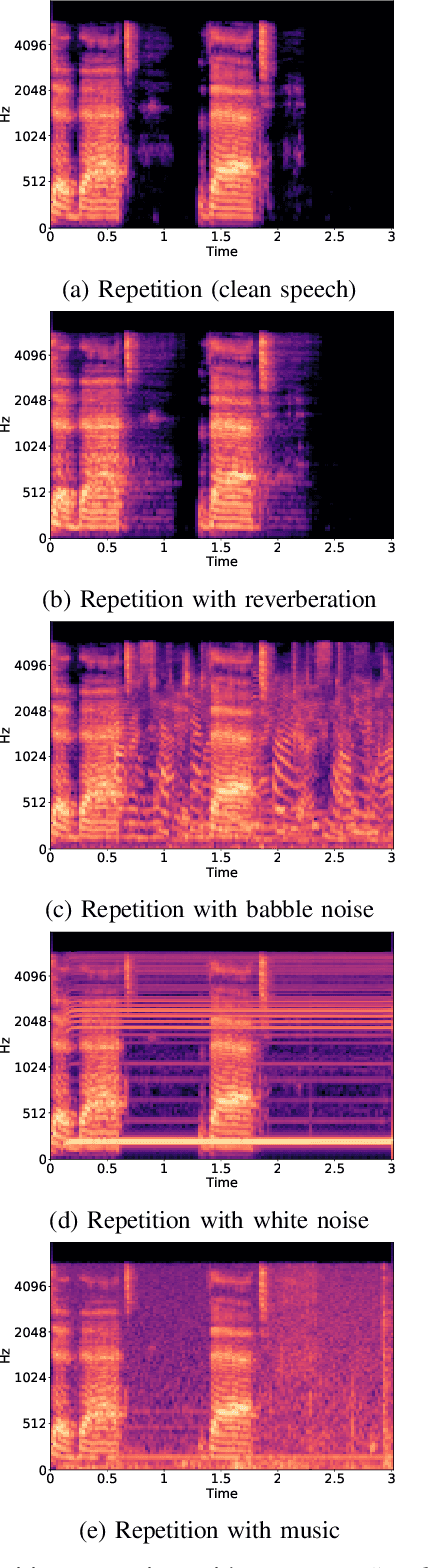
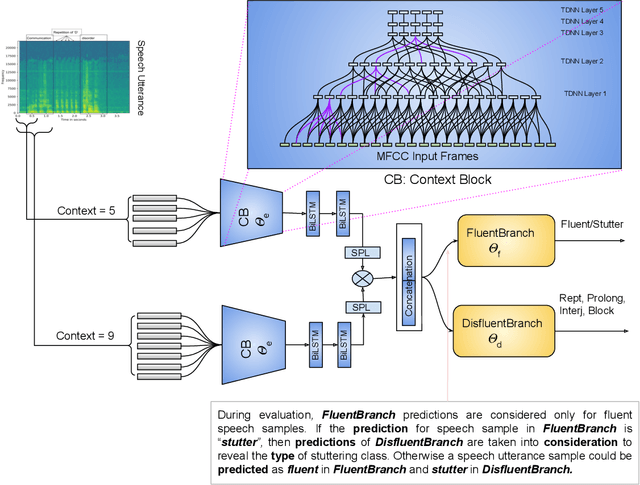
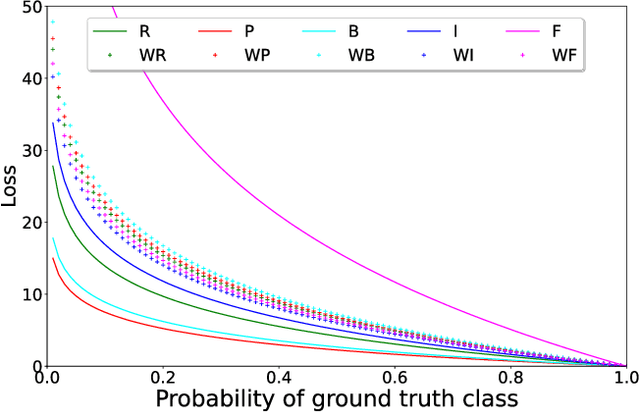
Stuttering is a neuro-developmental speech impairment characterized by uncontrolled utterances (interjections) and core behaviors (blocks, repetitions, and prolongations), and is caused by the failure of speech sensorimotors. Due to its complex nature, stuttering detection (SD) is a difficult task. If detected at an early stage, it could facilitate speech therapists to observe and rectify the speech patterns of persons who stutter (PWS). The stuttered speech of PWS is usually available in limited amounts and is highly imbalanced. To this end, we address the class imbalance problem in the SD domain via a multibranching (MB) scheme and by weighting the contribution of classes in the overall loss function, resulting in a huge improvement in stuttering classes on the SEP-28k dataset over the baseline (StutterNet). To tackle data scarcity, we investigate the effectiveness of data augmentation on top of a multi-branched training scheme. The augmented training outperforms the MB StutterNet (clean) by a relative margin of 4.18% in macro F1-score (F1). In addition, we propose a multi-contextual (MC) StutterNet, which exploits different contexts of the stuttered speech, resulting in an overall improvement of 4.48% in F 1 over the single context based MB StutterNet. Finally, we have shown that applying data augmentation in the cross-corpora scenario can improve the overall SD performance by a relative margin of 13.23% in F1 over the clean training.
EBEN: Extreme bandwidth extension network applied to speech signals captured with noise-resilient microphones
Oct 25, 2022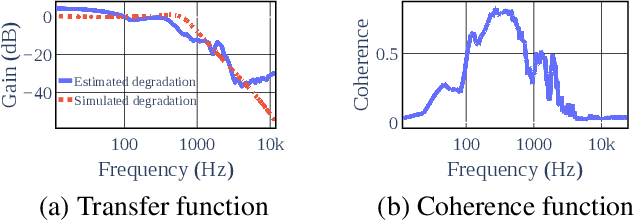
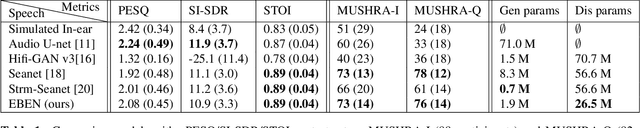
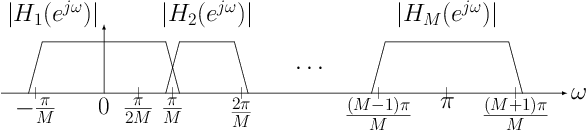
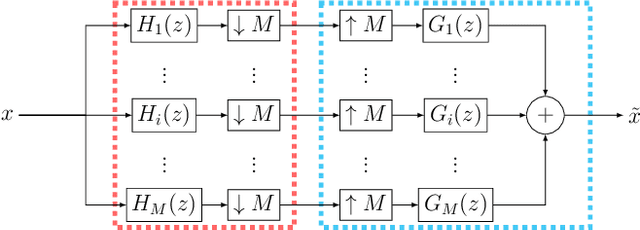
In this paper, we present Extreme Bandwidth Extension Network (EBEN), a generative adversarial network (GAN) that enhances audio measured with noise-resilient microphones. This type of capture equipment suppresses ambient noise at the expense of speech bandwidth, thereby requiring signal enhancement techniques to recover the wideband speech signal. EBEN leverages a multiband decomposition of the raw captured speech to decrease the data time-domain dimensions, and give better control over the full-band signal. This multiband representation is fed to a U-Net-like model, which adopts a combination of feature and adversarial losses to recover an enhanced audio signal. We also benefit from this original representation in the proposed discriminator architecture. Our approach can achieve state-of-the-art results with a lightweight generator and real-time compatible operation.
Decoding speech from non-invasive brain recordings
Aug 25, 2022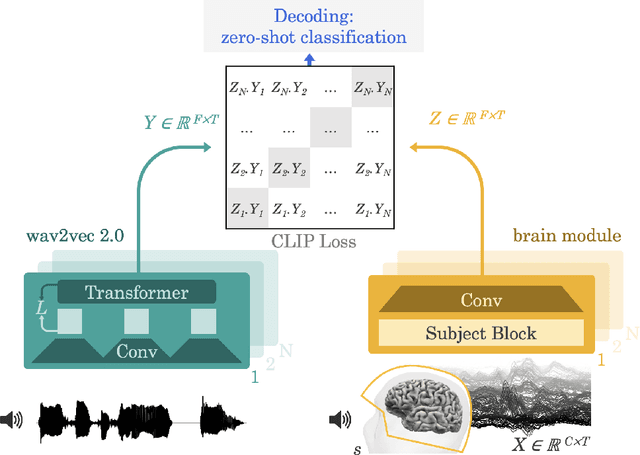

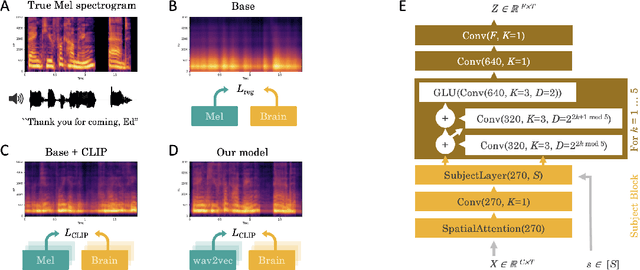

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Feb 20, 2023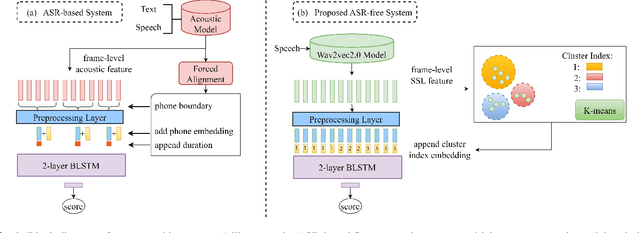
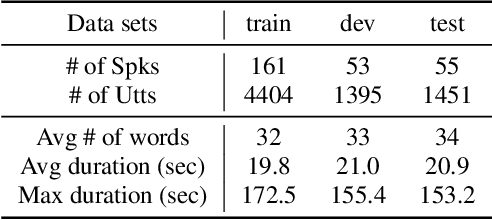
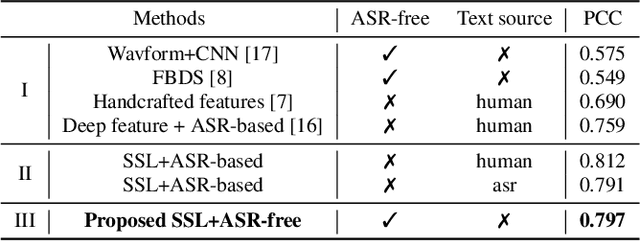
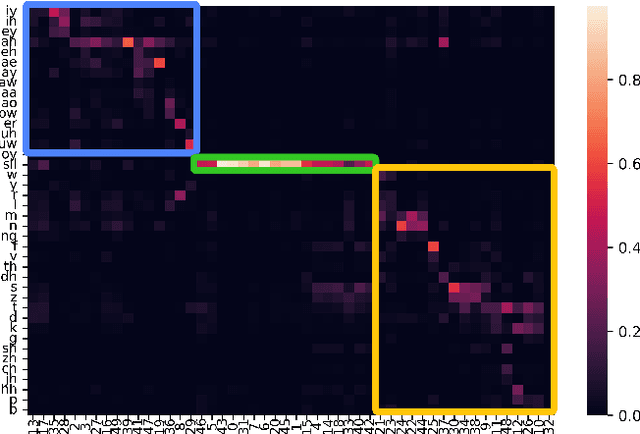
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022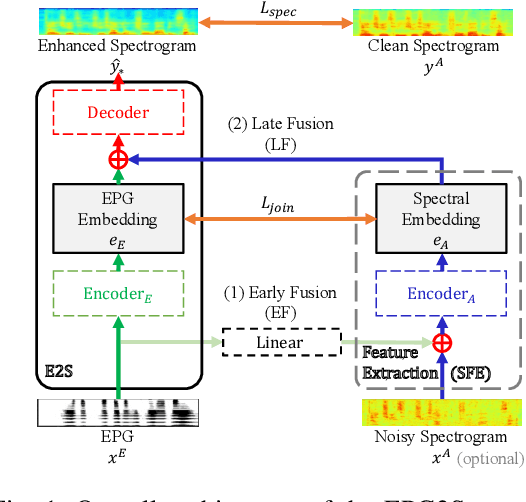
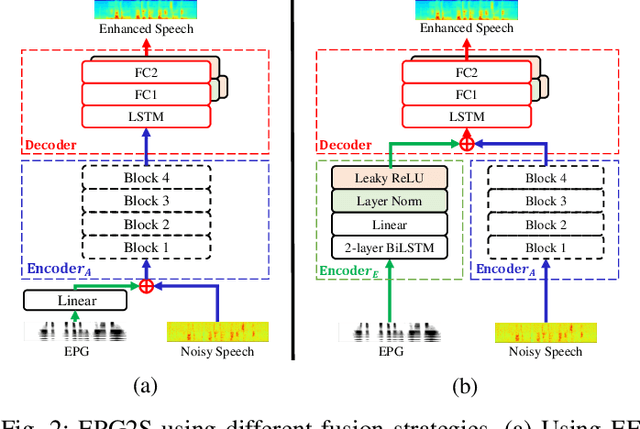
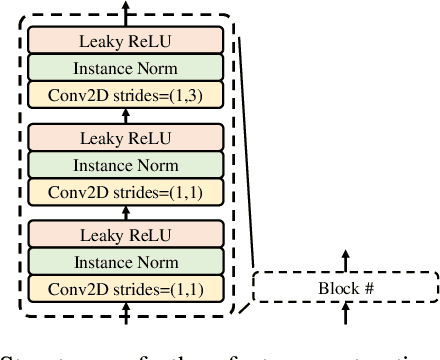
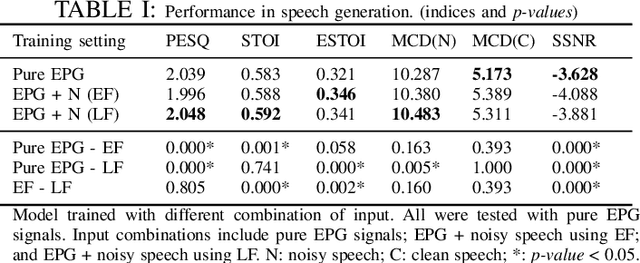
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.