 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Deep Learning-based Spatio Temporal Facial Feature Visual Speech Recognition
Apr 30, 2023
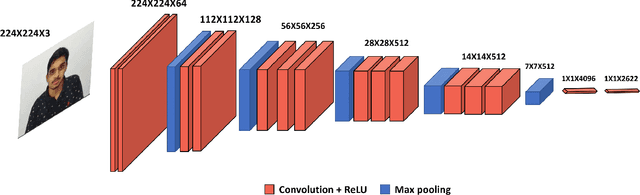
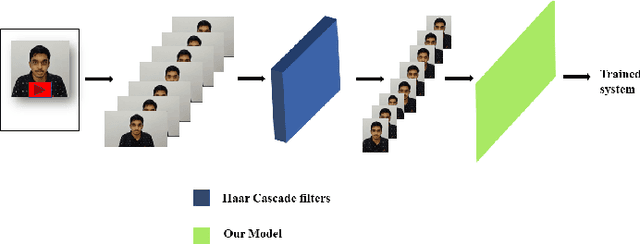

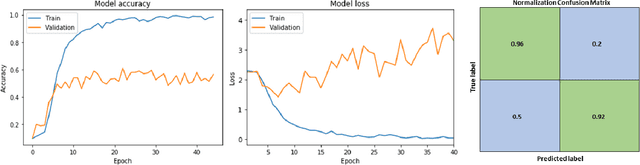
In low-resource computing contexts, such as smartphones and other tiny devices, Both deep learning and machine learning are being used in a lot of identification systems. as authentication techniques. The transparent, contactless, and non-invasive nature of these face recognition technologies driven by AI has led to their meteoric rise in popularity in recent years. While they are mostly successful, there are still methods to get inside without permission by utilising things like pictures, masks, glasses, etc. In this research, we present an alternate authentication process that makes use of both facial recognition and the individual's distinctive temporal facial feature motions while they speak a password. Because the suggested methodology allows for a password to be specified in any language, it is not limited by language. The suggested model attained an accuracy of 96.1% when tested on the industry-standard MIRACL-VC1 dataset, demonstrating its efficacy as a reliable and powerful solution. In addition to being data-efficient, the suggested technique shows promising outcomes with as little as 10 positive video examples for training the model. The effectiveness of the network's training is further proved via comparisons with other combined facial recognition and lip reading models.
A Two-Stage Deep Representation Learning-Based Speech Enhancement Method Using Variational Autoencoder and Adversarial Training
Nov 16, 2022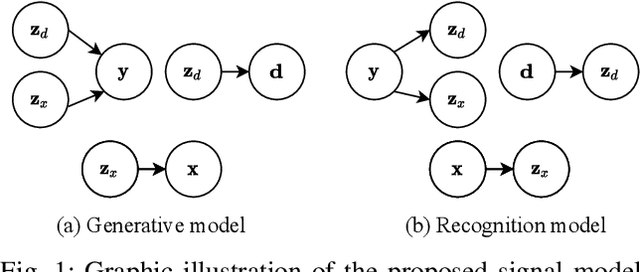
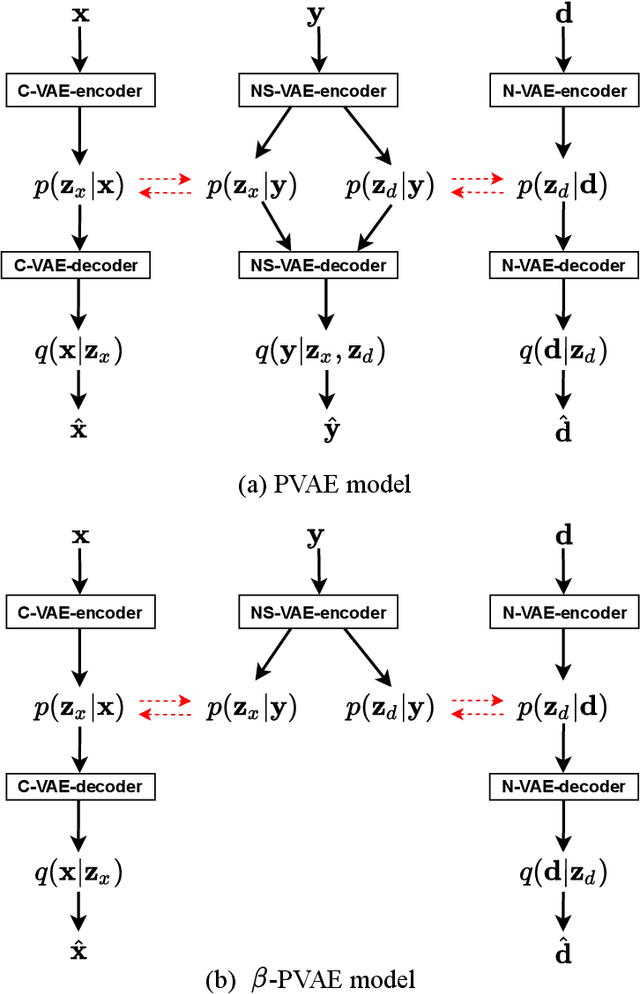
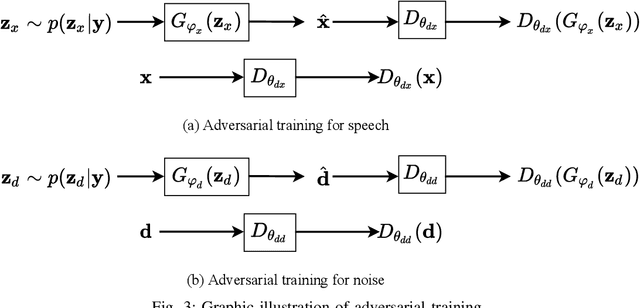
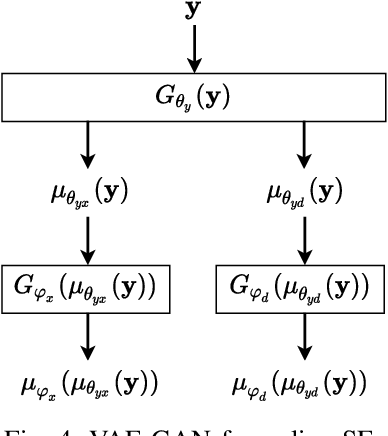
This paper focuses on leveraging deep representation learning (DRL) for speech enhancement (SE). In general, the performance of the deep neural network (DNN) is heavily dependent on the learning of data representation. However, the DRL's importance is often ignored in many DNN-based SE algorithms. To obtain a higher quality enhanced speech, we propose a two-stage DRL-based SE method through adversarial training. In the first stage, we disentangle different latent variables because disentangled representations can help DNN generate a better enhanced speech. Specifically, we use the $\beta$-variational autoencoder (VAE) algorithm to obtain the speech and noise posterior estimations and related representations from the observed signal. However, since the posteriors and representations are intractable and we can only apply a conditional assumption to estimate them, it is difficult to ensure that these estimations are always pretty accurate, which may potentially degrade the final accuracy of the signal estimation. To further improve the quality of enhanced speech, in the second stage, we introduce adversarial training to reduce the effect of the inaccurate posterior towards signal reconstruction and improve the signal estimation accuracy, making our algorithm more robust for the potentially inaccurate posterior estimations. As a result, better SE performance can be achieved. The experimental results indicate that the proposed strategy can help similar DNN-based SE algorithms achieve higher short-time objective intelligibility (STOI), perceptual evaluation of speech quality (PESQ), and scale-invariant signal-to-distortion ratio (SI-SDR) scores. Moreover, the proposed algorithm can also outperform recent competitive SE algorithms.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022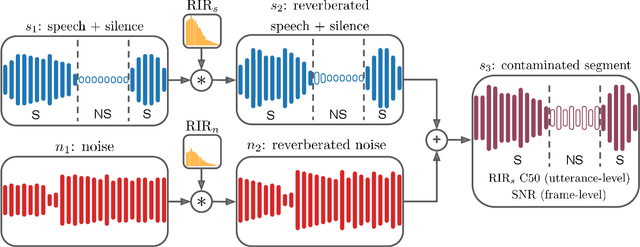
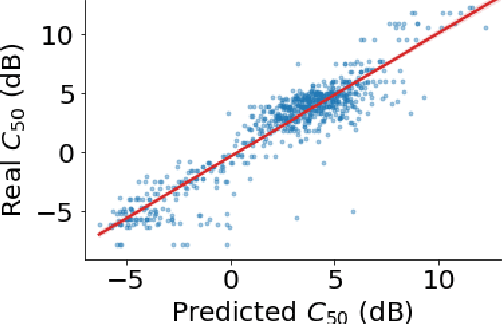
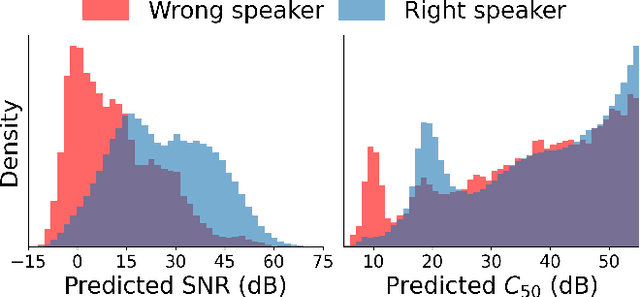
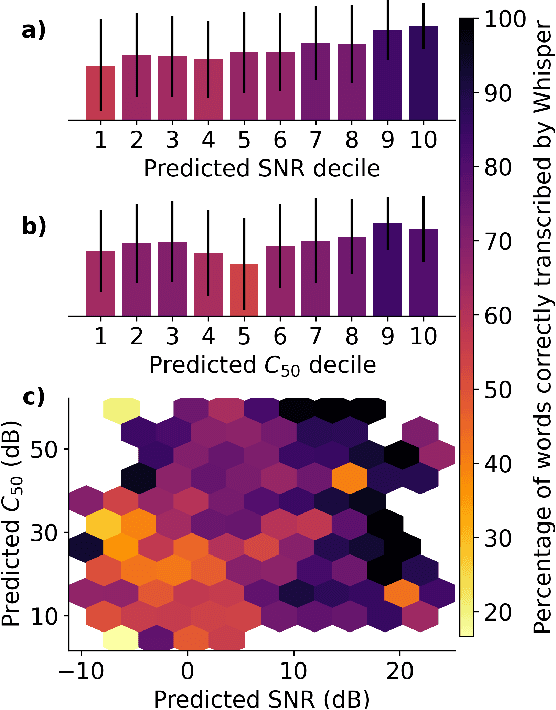
Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Avoid Overthinking in Self-Supervised Models for Speech Recognition
Nov 01, 2022
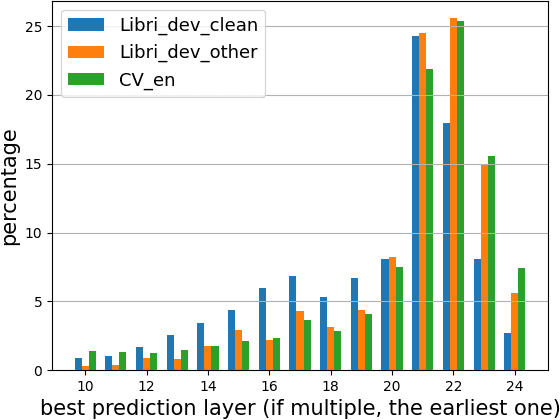
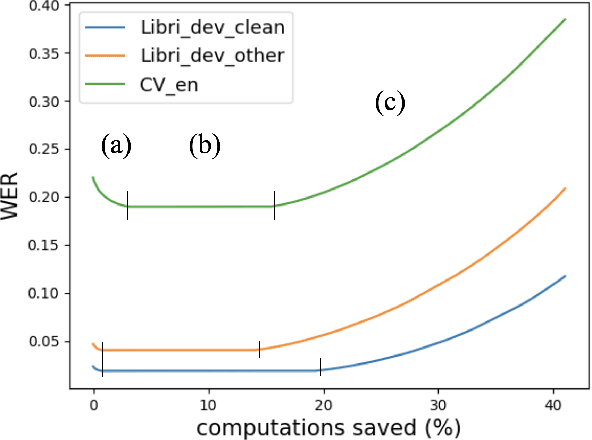

Self-supervised learning (SSL) models reshaped our approach to speech, language and vision. However their huge size and the opaque relations between their layers and tasks result in slow inference and network overthinking, where predictions made from the last layer of large models is worse than those made from intermediate layers. Early exit (EE) strategies can solve both issues by dynamically reducing computations at inference time for certain samples. Although popular for classification tasks in vision and language, EE has seen less use for sequence-to-sequence speech recognition (ASR) tasks where outputs from early layers are often degenerate. This challenge is further compounded when speech SSL models are applied on out-of-distribution (OOD) data. This paper first shows that SSL models do overthinking in ASR. We then motivate further research in EE by computing an optimal bound for performance versus speed trade-offs. To approach this bound we propose two new strategies for ASR: (1) we adapt the recently proposed patience strategy to ASR; and (2) we design a new EE strategy specific to ASR that performs better than all strategies previously introduced.
Puffin: pitch-synchronous neural waveform generation for fullband speech on modest devices
Nov 25, 2022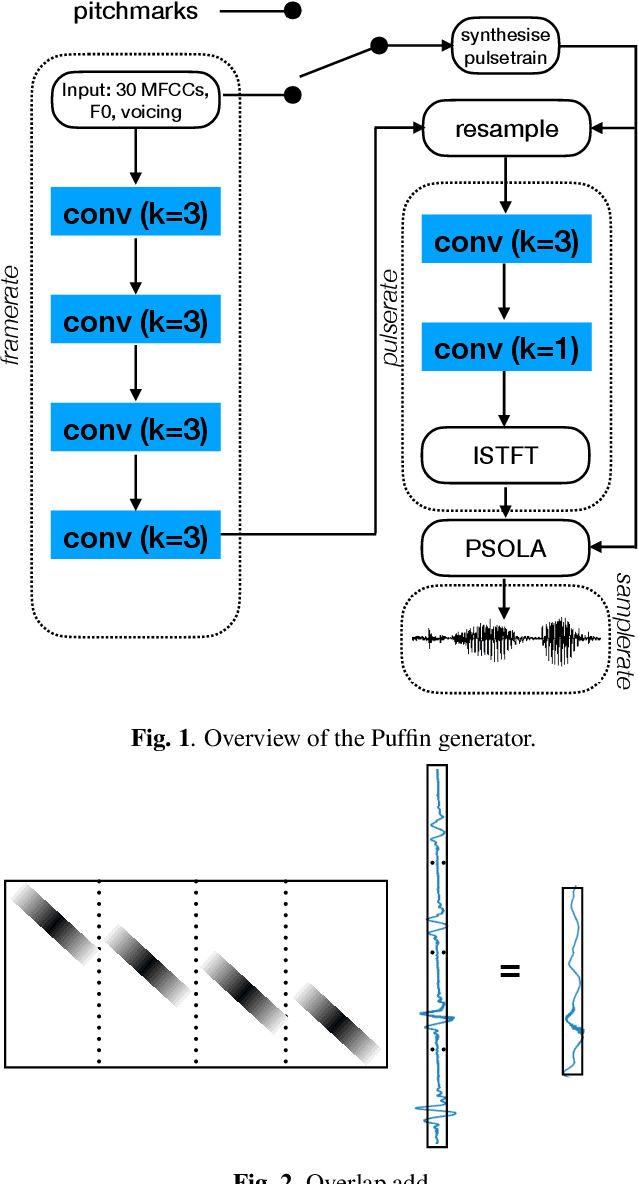
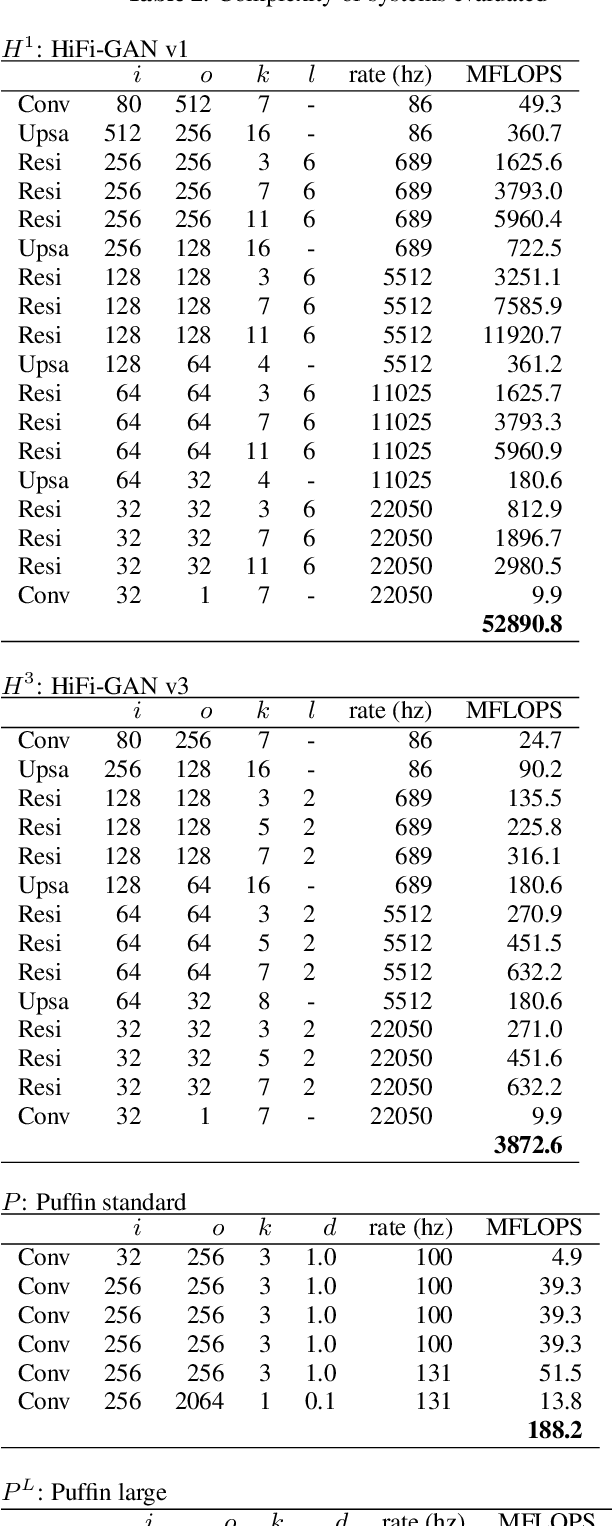
We present a neural vocoder designed with low-powered Alternative and Augmentative Communication devices in mind. By combining elements of successful modern vocoders with established ideas from an older generation of technology, our system is able to produce high quality synthetic speech at 48kHz on devices where neural vocoders are otherwise prohibitively complex. The system is trained adversarially using differentiable pitch synchronous overlap add, and reduces complexity by relying on pitch synchronous Inverse Short-Time Fourier Transform (ISTFT) to generate speech samples. Our system achieves comparable quality with a strong (HiFi-GAN) baseline while using only a fraction of the compute. We present results of a perceptual evaluation as well as an analysis of system complexity.
Can we hear physical and social space together through prosody?
May 22, 2023When human listeners try to guess the spatial position of a speech source, they are influenced by the speaker's production level, regardless of the intensity level reaching their ears. Because the perception of distance is a very difficult task, they rely on their own experience, which tells them that a whispering talker is close to them, and that a shouting talker is far away. This study aims to test if similar results could be obtained for prosodic variations produced by a human speaker in an everyday life environment. It consists in a localization task, during which blindfolded subjects had to estimate the incoming voice direction, speaker orientation and distance of a trained female speaker, who uttered single words, following instructions concerning intensity and social-affect to be performed. This protocol was implemented in two experiments. First, a complex pretext task was used in order to distract the subjects from the strange behavior of the speaker. On the contrary, during the second experiment, the subjects were fully aware of the prosodic variations, which allowed them to adapt their perception. Results show the importance of the pretext task, and suggest that the perception of the speaker's orientation can be influenced by voice intensity.
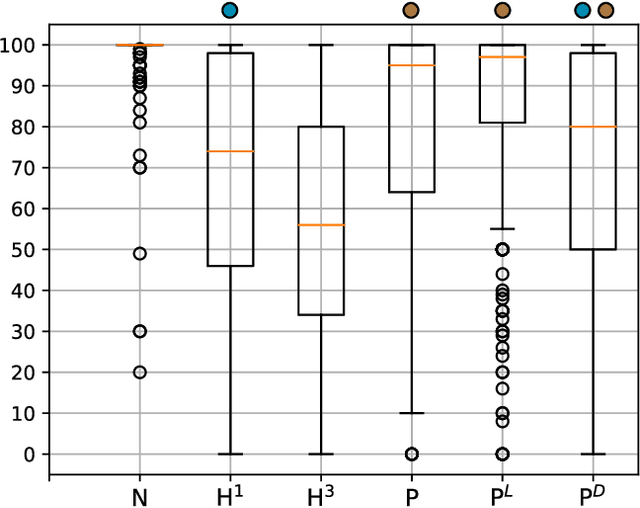
Iterative autoregression: a novel trick to improve your low-latency speech enhancement model
Nov 03, 2022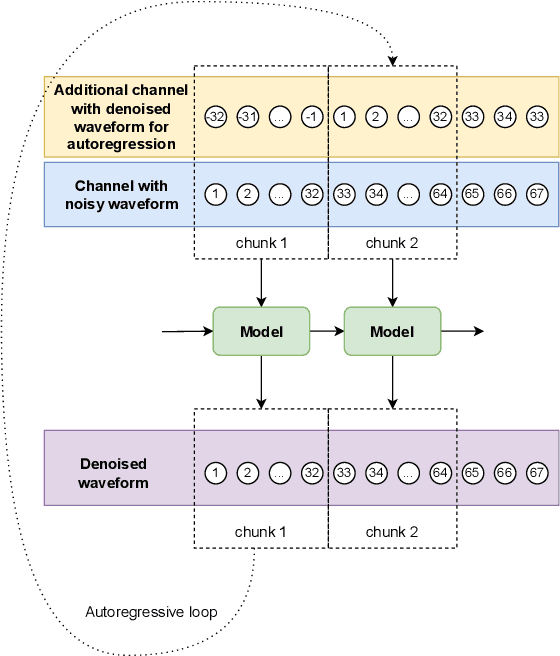
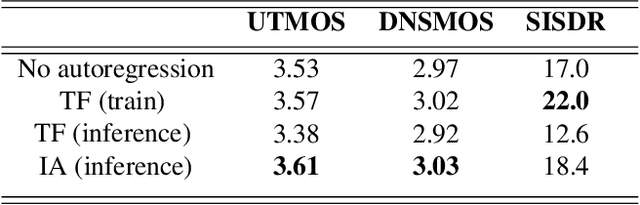
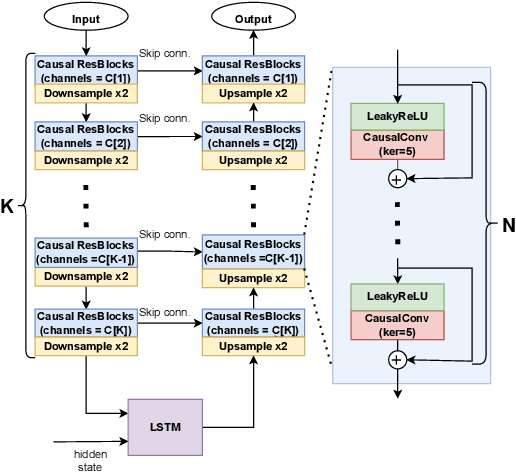
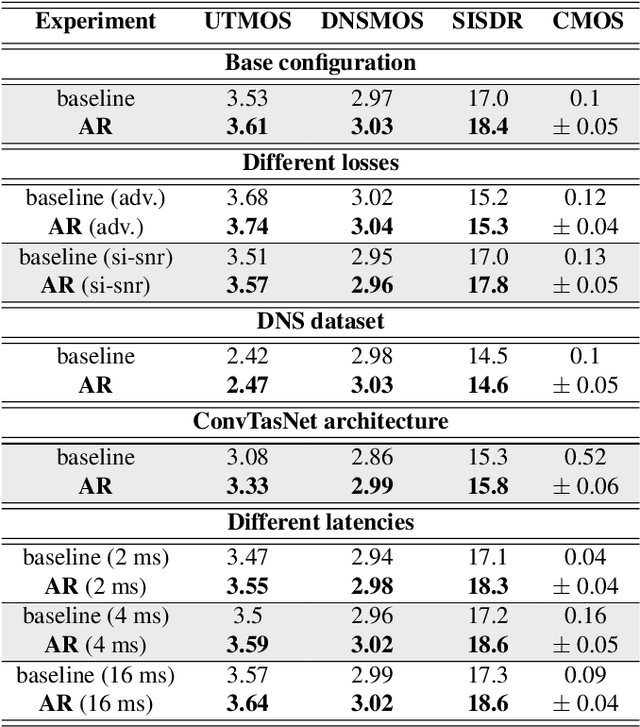
Streaming models are an essential component of real-time speech enhancement tools. The streaming regime constrains speech enhancement models to use only a tiny context of future information, thus, the low-latency streaming setup is generally assumed to be challenging and has a significant negative effect on the model quality. However, due to the sequential nature of streaming generation, it provides a natural possibility for autoregression, i.e., using previous predictions when making current ones. In this paper, we present a simple, yet effective trick for training of autoregressive low-latency speech enhancement models. We demonstrate that the proposed technique leads to stable improvement across different architectures and training scenarios.
Bengali Common Voice Speech Dataset for Automatic Speech Recognition
Jun 29, 2022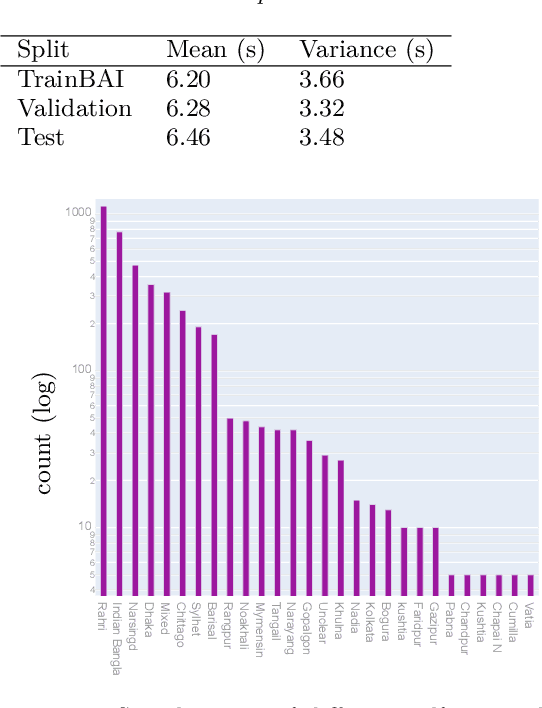
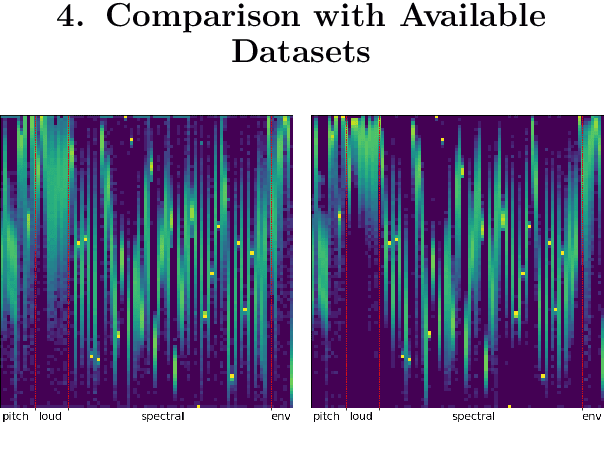

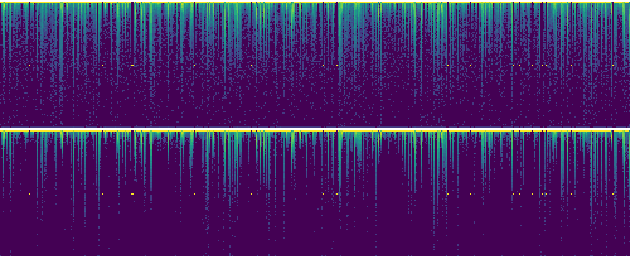
Bengali is one of the most spoken languages in the world with over 300 million speakers globally. Despite its popularity, research into the development of Bengali speech recognition systems is hindered due to the lack of diverse open-source datasets. As a way forward, we have crowdsourced the Bengali Common Voice Speech Dataset, which is a sentence-level automatic speech recognition corpus. Collected on the Mozilla Common Voice platform, the dataset is part of an ongoing campaign that has led to the collection of over 400 hours of data in 2 months and is growing rapidly. Our analysis shows that this dataset has more speaker, phoneme, and environmental diversity compared to the OpenSLR Bengali ASR dataset, the largest existing open-source Bengali speech dataset. We present insights obtained from the dataset and discuss key linguistic challenges that need to be addressed in future versions. Additionally, we report the current performance of a few Automatic Speech Recognition (ASR) algorithms and set a benchmark for future research.
Knowledge Transfer For On-Device Speech Emotion Recognition with Neural Structured Learning
Oct 26, 2022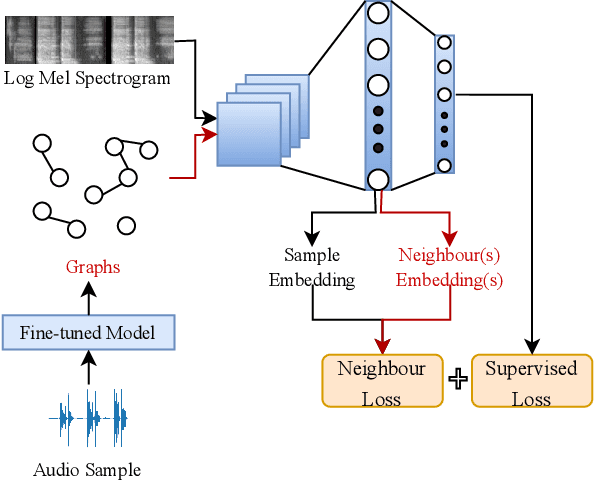

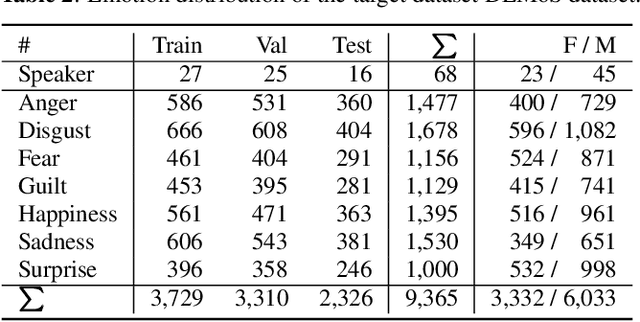
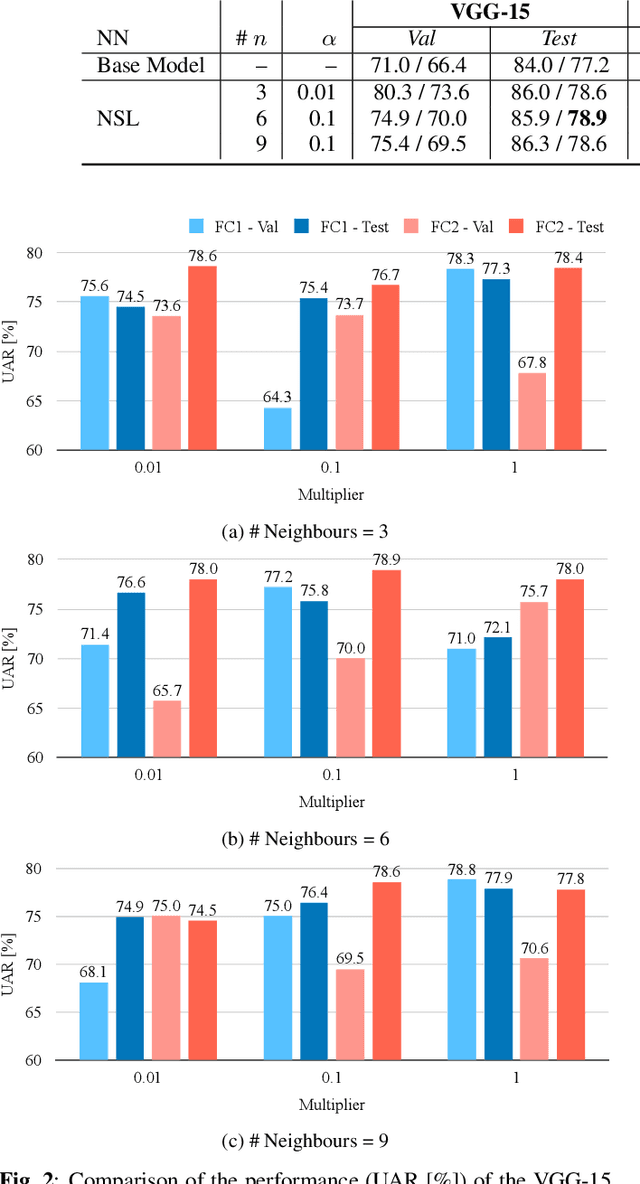
Speech emotion recognition (SER) has been a popular research topic in human-computer interaction (HCI). As edge devices are rapidly springing up, applying SER to edge devices is promising for a huge number of HCI applications. Although deep learning has been investigated to improve the performance of SER by training complex models, the memory space and computational capability of edge devices represents a constraint for embedding deep learning models. We propose a neural structured learning (NSL) framework through building synthesized graphs. An SER model is trained on a source dataset and used to build graphs on a target dataset. A lightweight model is then trained with the speech samples and graphs together as the input. Our experiments demonstrate that training a lightweight SER model on the target dataset with speech samples and graphs can not only produce small SER models, but also enhance the model performance over models with speech samples only.
VANI: Very-lightweight Accent-controllable TTS for Native and Non-native speakers with Identity Preservation
Mar 14, 2023
We introduce VANI, a very lightweight multi-lingual accent controllable speech synthesis system. Our model builds upon disentanglement strategies proposed in RADMMM and supports explicit control of accent, language, speaker and fine-grained $F_0$ and energy features for speech synthesis. We utilize the Indic languages dataset, released for LIMMITS 2023 as part of ICASSP Signal Processing Grand Challenge, to synthesize speech in 3 different languages. Our model supports transferring the language of a speaker while retaining their voice and the native accent of the target language. We utilize the large-parameter RADMMM model for Track $1$ and lightweight VANI model for Track $2$ and $3$ of the competition.