 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
AutoAD II: The Sequel -- Who, When, and What in Movie Audio Description
Oct 10, 2023

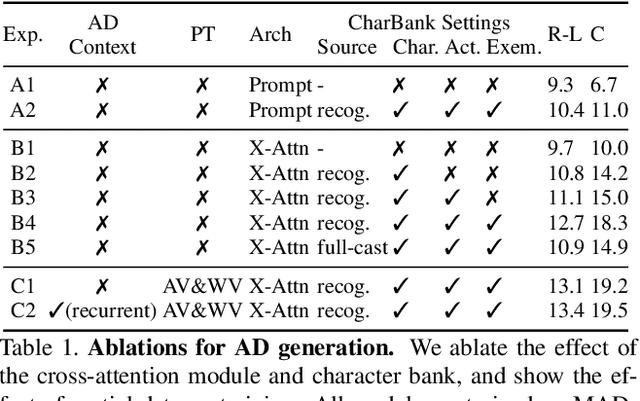
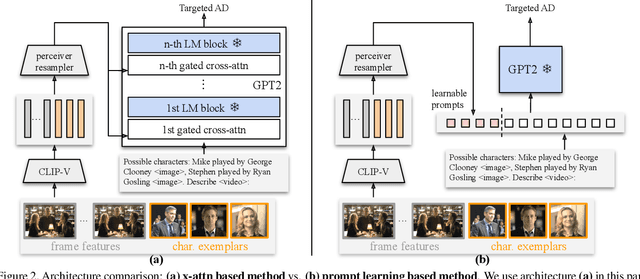

Audio Description (AD) is the task of generating descriptions of visual content, at suitable time intervals, for the benefit of visually impaired audiences. For movies, this presents notable challenges -- AD must occur only during existing pauses in dialogue, should refer to characters by name, and ought to aid understanding of the storyline as a whole. To this end, we develop a new model for automatically generating movie AD, given CLIP visual features of the frames, the cast list, and the temporal locations of the speech; addressing all three of the 'who', 'when', and 'what' questions: (i) who -- we introduce a character bank consisting of the character's name, the actor that played the part, and a CLIP feature of their face, for the principal cast of each movie, and demonstrate how this can be used to improve naming in the generated AD; (ii) when -- we investigate several models for determining whether an AD should be generated for a time interval or not, based on the visual content of the interval and its neighbours; and (iii) what -- we implement a new vision-language model for this task, that can ingest the proposals from the character bank, whilst conditioning on the visual features using cross-attention, and demonstrate how this improves over previous architectures for AD text generation in an apples-to-apples comparison.
A Novel Scheme to classify Read and Spontaneous Speech
Jun 13, 2023
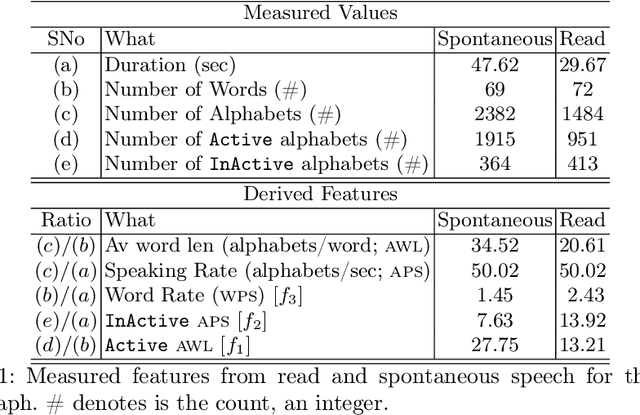
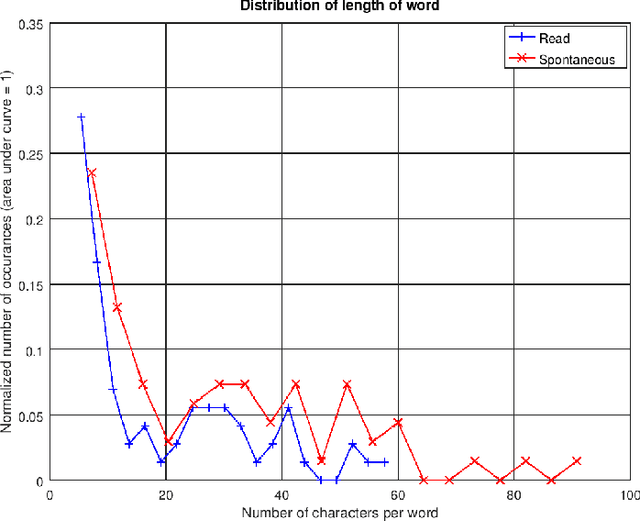
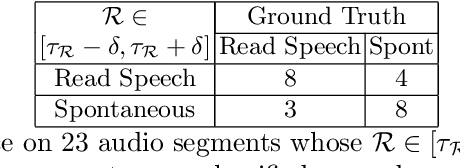
The COVID-19 pandemic has led to an increased use of remote telephonic interviews, making it important to distinguish between scripted and spontaneous speech in audio recordings. In this paper, we propose a novel scheme for identifying read and spontaneous speech. Our approach uses a pre-trained DeepSpeech audio-to-alphabet recognition engine to generate a sequence of alphabets from the audio. From these alphabets, we derive features that allow us to discriminate between read and spontaneous speech. Our experimental results show that even a small set of self-explanatory features can effectively classify the two types of speech very effectively.
A comparative study of Grid and Natural sentences effects on Normal-to-Lombard conversion
Sep 19, 2023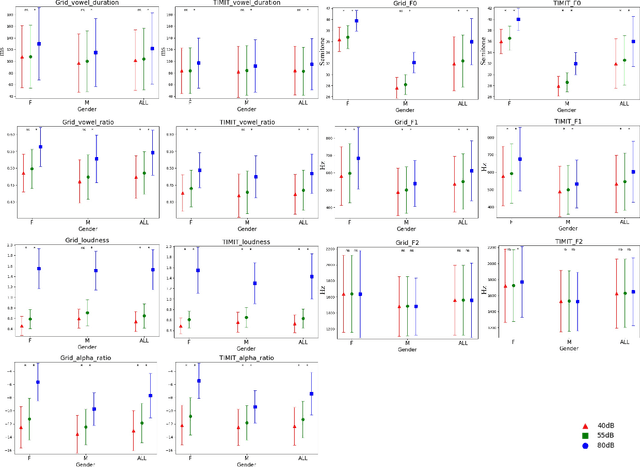

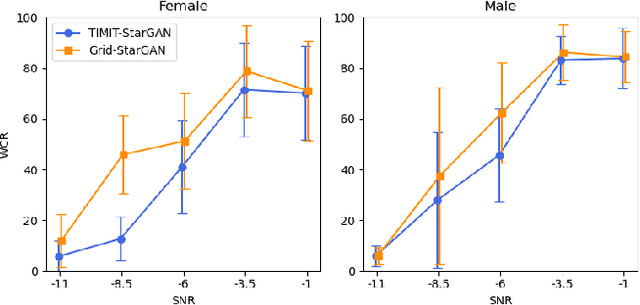
Grid sentence is commonly used for studying the Lombard effect and Normal-to-Lombard conversion. However, it's unclear if Normal-to-Lombard models trained on grid sentences are sufficient for improving natural speech intelligibility in real-world applications. This paper presents the recording of a parallel Lombard corpus (called Lombard Chinese TIMIT, LCT) extracting natural sentences from Chinese TIMIT. Then We compare natural and grid sentences in terms of Lombard effect and Normal-to-Lombard conversion using LCT and Enhanced MAndarin Lombard Grid corpus (EMALG). Through a parametric analysis of the Lombard effect, We find that as the noise level increases, both natural sentences and grid sentences exhibit similar changes in parameters, but in terms of the increase of the alpha ratio, grid sentences show a greater increase. Following a subjective intelligibility assessment across genders and Signal-to-Noise Ratios, the StarGAN model trained on EMALG consistently outperforms the model trained on LCT in terms of improving intelligibility. This superior performance may be attributed to EMALG's larger alpha ratio increase from normal to Lombard speech.
Zambezi Voice: A Multilingual Speech Corpus for Zambian Languages
Jun 07, 2023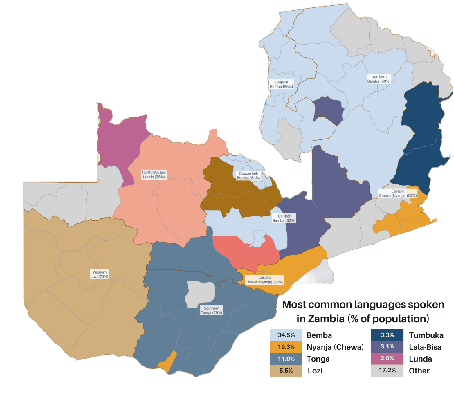
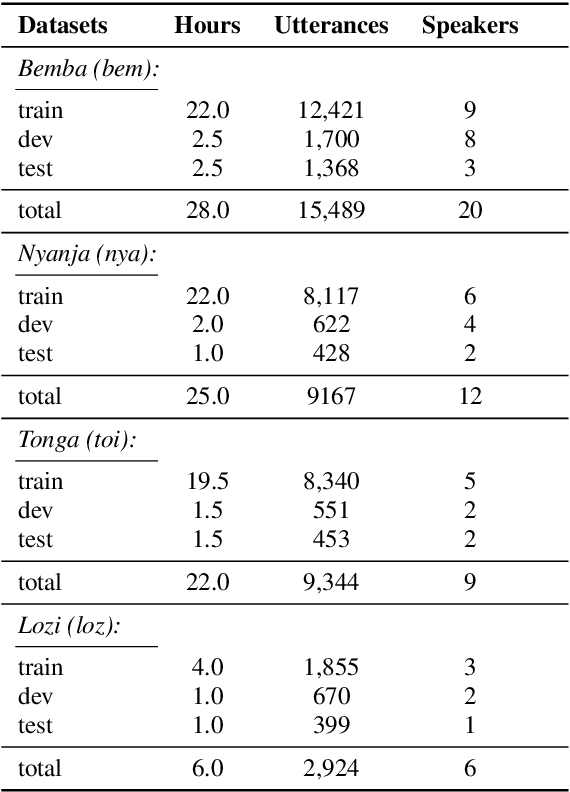
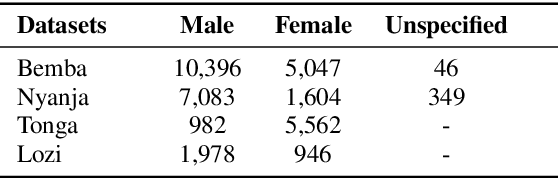
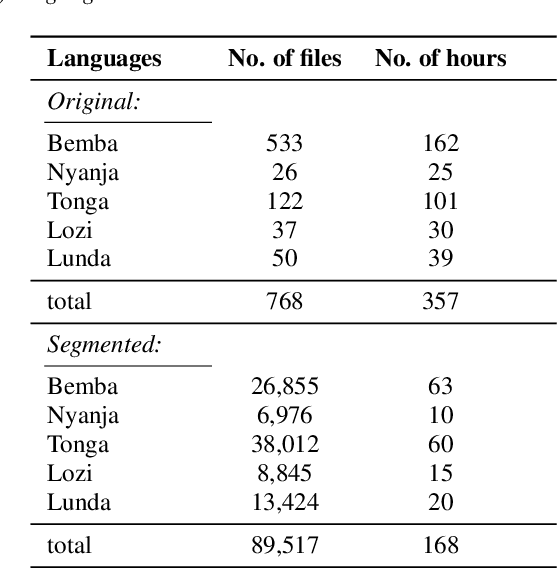
This work introduces Zambezi Voice, an open-source multilingual speech resource for Zambian languages. It contains two collections of datasets: unlabelled audio recordings of radio news and talk shows programs (160 hours) and labelled data (over 80 hours) consisting of read speech recorded from text sourced from publicly available literature books. The dataset is created for speech recognition but can be extended to multilingual speech processing research for both supervised and unsupervised learning approaches. To our knowledge, this is the first multilingual speech dataset created for Zambian languages. We exploit pretraining and cross-lingual transfer learning by finetuning the Wav2Vec2.0 large-scale multilingual pre-trained model to build end-to-end (E2E) speech recognition models for our baseline models. The dataset is released publicly under a Creative Commons BY-NC-ND 4.0 license and can be accessed through the project repository. See https://github.com/unza-speech-lab/zambezi-voice
Mandarin Electrolaryngeal Speech Voice Conversion using Cross-domain Features
Jun 11, 2023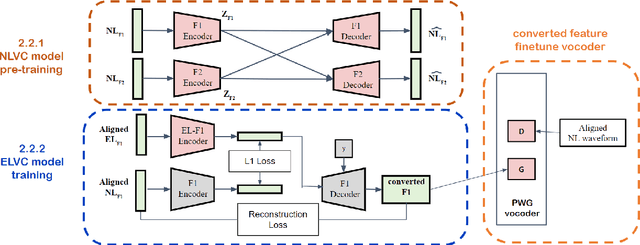

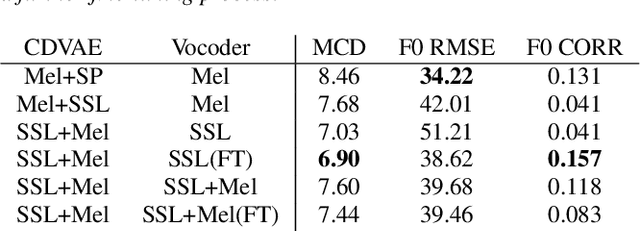
Patients who have had their entire larynx removed, including the vocal folds, owing to throat cancer may experience difficulties in speaking. In such cases, electrolarynx devices are often prescribed to produce speech, which is commonly referred to as electrolaryngeal speech (EL speech). However, the quality and intelligibility of EL speech are poor. To address this problem, EL voice conversion (ELVC) is a method used to improve the intelligibility and quality of EL speech. In this paper, we propose a novel ELVC system that incorporates cross-domain features, specifically spectral features and self-supervised learning (SSL) embeddings. The experimental results show that applying cross-domain features can notably improve the conversion performance for the ELVC task compared with utilizing only traditional spectral features.
Arabic Dysarthric Speech Recognition Using Adversarial and Signal-Based Augmentation
Jun 07, 2023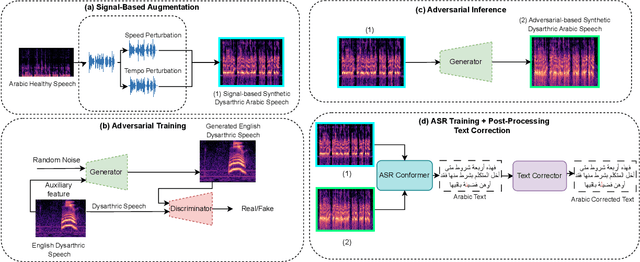
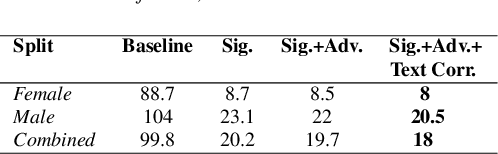
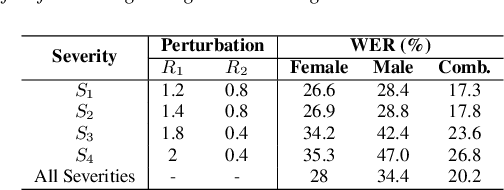
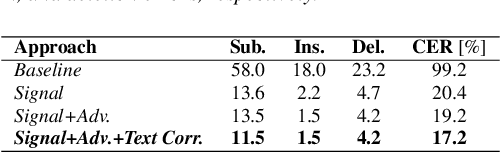
Despite major advancements in Automatic Speech Recognition (ASR), the state-of-the-art ASR systems struggle to deal with impaired speech even with high-resource languages. In Arabic, this challenge gets amplified, with added complexities in collecting data from dysarthric speakers. In this paper, we aim to improve the performance of Arabic dysarthric automatic speech recognition through a multi-stage augmentation approach. To this effect, we first propose a signal-based approach to generate dysarthric Arabic speech from healthy Arabic speech by modifying its speed and tempo. We also propose a second stage Parallel Wave Generative (PWG) adversarial model that is trained on an English dysarthric dataset to capture language-independant dysarthric speech patterns and further augment the signal-adjusted speech samples. Furthermore, we propose a fine-tuning and text-correction strategies for Arabic Conformer at different dysarthric speech severity levels. Our fine-tuned Conformer achieved 18% Word Error Rate (WER) and 17.2% Character Error Rate (CER) on synthetically generated dysarthric speech from the Arabic commonvoice speech dataset. This shows significant WER improvement of 81.8% compared to the baseline model trained solely on healthy data. We perform further validation on real English dysarthric speech showing a WER improvement of 124% compared to the baseline trained only on healthy English LJSpeech dataset.
BeAts: Bengali Speech Acts Recognition using Multimodal Attention Fusion
Jun 05, 2023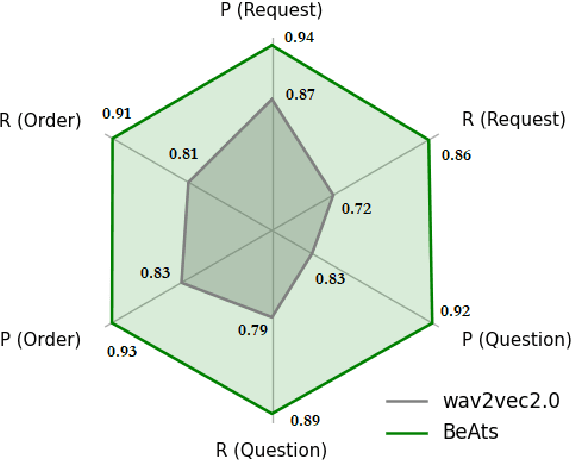
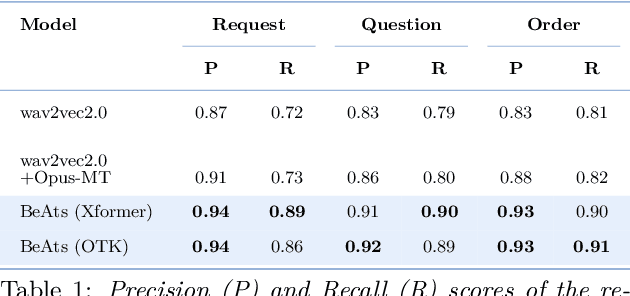
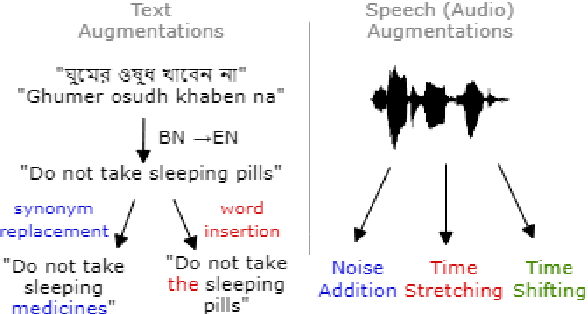
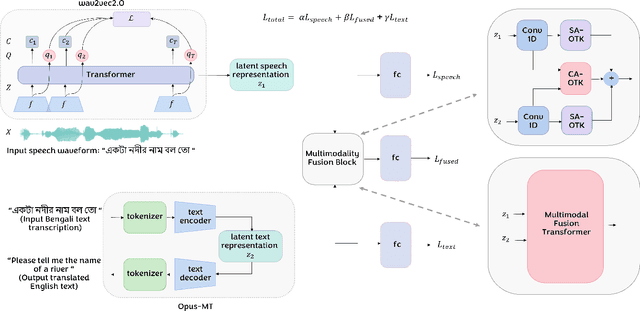
Spoken languages often utilise intonation, rhythm, intensity, and structure, to communicate intention, which can be interpreted differently depending on the rhythm of speech of their utterance. These speech acts provide the foundation of communication and are unique in expression to the language. Recent advancements in attention-based models, demonstrating their ability to learn powerful representations from multilingual datasets, have performed well in speech tasks and are ideal to model specific tasks in low resource languages. Here, we develop a novel multimodal approach combining two models, wav2vec2.0 for audio and MarianMT for text translation, by using multimodal attention fusion to predict speech acts in our prepared Bengali speech corpus. We also show that our model BeAts ($\underline{\textbf{Be}}$ngali speech acts recognition using Multimodal $\underline{\textbf{At}}$tention Fu$\underline{\textbf{s}}$ion) significantly outperforms both the unimodal baseline using only speech data and a simpler bimodal fusion using both speech and text data. Project page: https://soumitri2001.github.io/BeAts
StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
Jun 13, 2023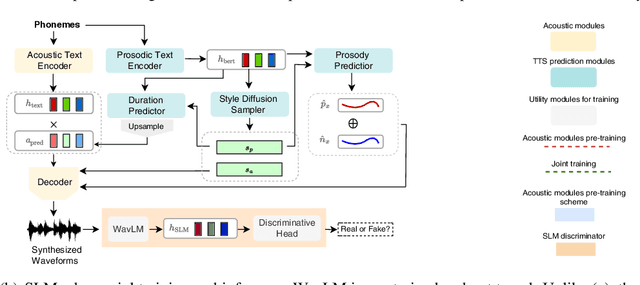

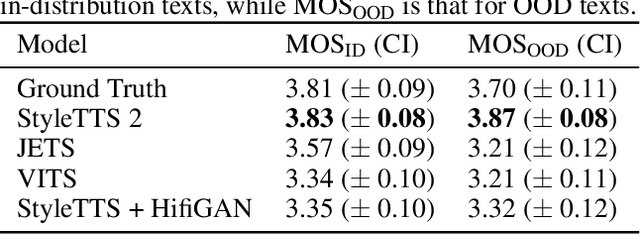
In this paper, we present StyleTTS 2, a text-to-speech (TTS) model that leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. StyleTTS 2 differs from its predecessor by modeling styles as a latent random variable through diffusion models to generate the most suitable style for the text without requiring reference speech, achieving efficient latent diffusion while benefiting from the diverse speech synthesis offered by diffusion models. Furthermore, we employ large pre-trained SLMs, such as WavLM, as discriminators with our novel differentiable duration modeling for end-to-end training, resulting in improved speech naturalness. StyleTTS 2 surpasses human recordings on the single-speaker LJSpeech dataset and matches it on the multispeaker VCTK dataset as judged by native English speakers. Moreover, when trained on the LibriTTS dataset, our model outperforms previous publicly available models for zero-shot speaker adaptation. This work achieves the first human-level TTS on both single and multispeaker datasets, showcasing the potential of style diffusion and adversarial training with large SLMs. The audio demos and source code are available at https://styletts2.github.io/.
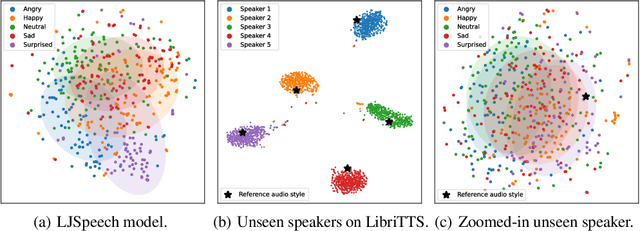
ZET-Speech: Zero-shot adaptive Emotion-controllable Text-to-Speech Synthesis with Diffusion and Style-based Models
May 23, 2023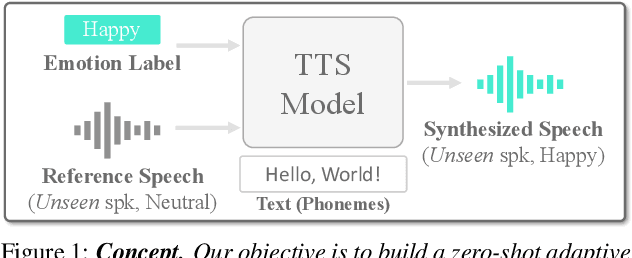
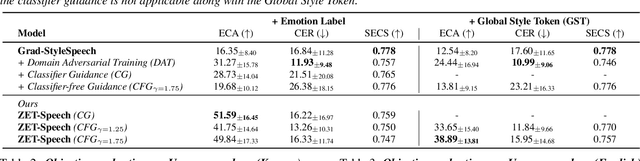
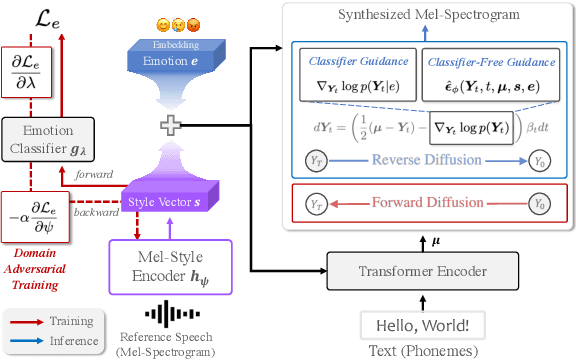
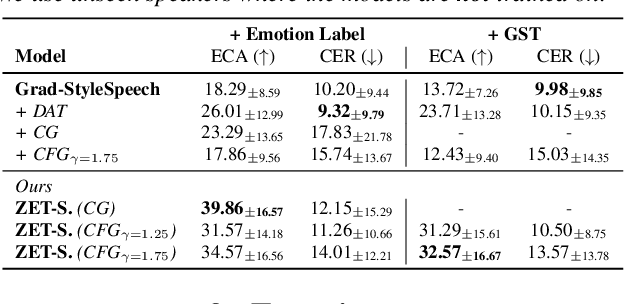
Emotional Text-To-Speech (TTS) is an important task in the development of systems (e.g., human-like dialogue agents) that require natural and emotional speech. Existing approaches, however, only aim to produce emotional TTS for seen speakers during training, without consideration of the generalization to unseen speakers. In this paper, we propose ZET-Speech, a zero-shot adaptive emotion-controllable TTS model that allows users to synthesize any speaker's emotional speech using only a short, neutral speech segment and the target emotion label. Specifically, to enable a zero-shot adaptive TTS model to synthesize emotional speech, we propose domain adversarial learning and guidance methods on the diffusion model. Experimental results demonstrate that ZET-Speech successfully synthesizes natural and emotional speech with the desired emotion for both seen and unseen speakers. Samples are at https://ZET-Speech.github.io/ZET-Speech-Demo/.
SynVox2: Towards a privacy-friendly VoxCeleb2 dataset
Sep 12, 2023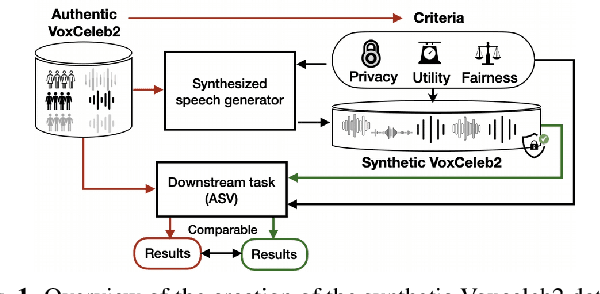
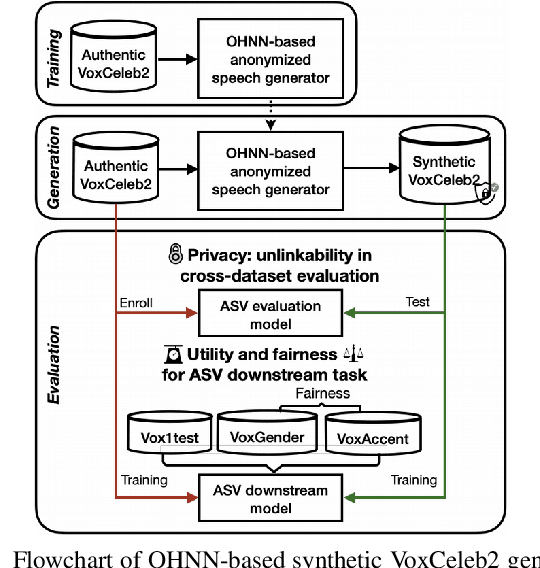
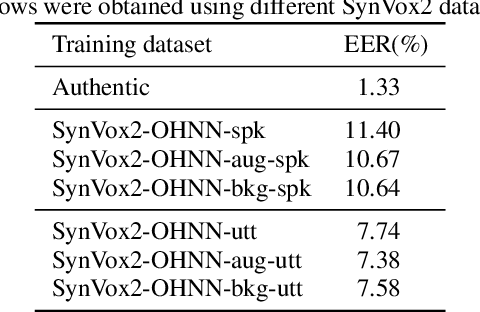
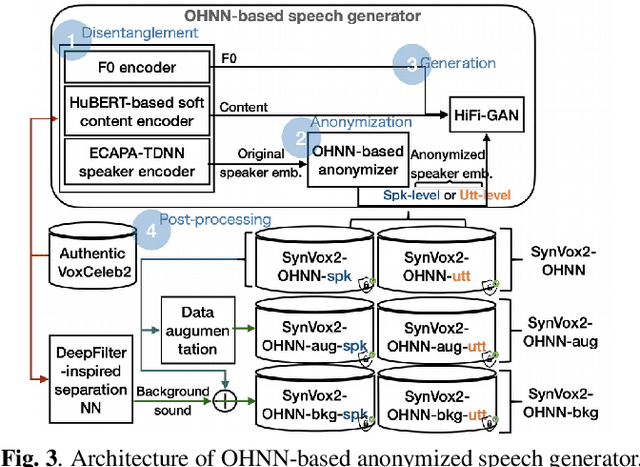
The success of deep learning in speaker recognition relies heavily on the use of large datasets. However, the data-hungry nature of deep learning methods has already being questioned on account the ethical, privacy, and legal concerns that arise when using large-scale datasets of natural speech collected from real human speakers. For example, the widely-used VoxCeleb2 dataset for speaker recognition is no longer accessible from the official website. To mitigate these concerns, this work presents an initiative to generate a privacy-friendly synthetic VoxCeleb2 dataset that ensures the quality of the generated speech in terms of privacy, utility, and fairness. We also discuss the challenges of using synthetic data for the downstream task of speaker verification.