 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Stylebook: Content-Dependent Speaking Style Modeling for Any-to-Any Voice Conversion using Only Speech Data
Sep 12, 2023
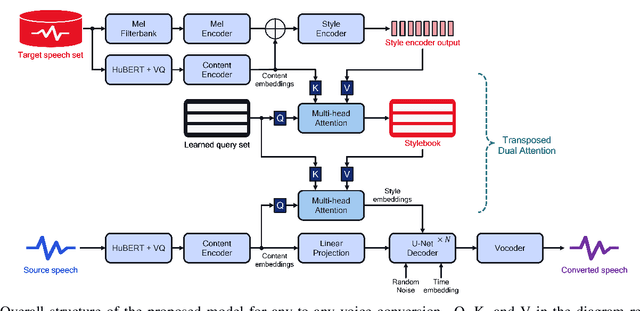
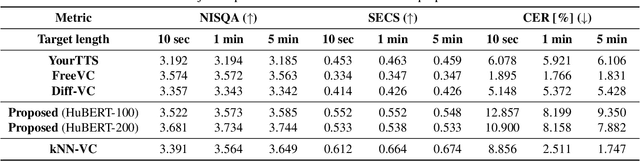
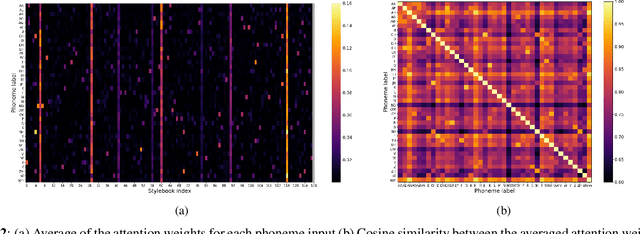
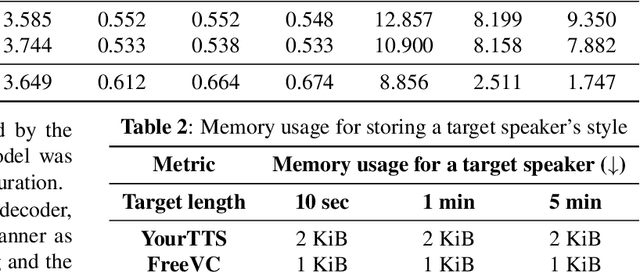
While many recent any-to-any voice conversion models succeed in transferring some target speech's style information to the converted speech, they still lack the ability to faithfully reproduce the speaking style of the target speaker. In this work, we propose a novel method to extract rich style information from target utterances and to efficiently transfer it to source speech content without requiring text transcriptions or speaker labeling. Our proposed approach introduces an attention mechanism utilizing a self-supervised learning (SSL) model to collect the speaking styles of a target speaker each corresponding to the different phonetic content. The styles are represented with a set of embeddings called stylebook. In the next step, the stylebook is attended with the source speech's phonetic content to determine the final target style for each source content. Finally, content information extracted from the source speech and content-dependent target style embeddings are fed into a diffusion-based decoder to generate the converted speech mel-spectrogram. Experiment results show that our proposed method combined with a diffusion-based generative model can achieve better speaker similarity in any-to-any voice conversion tasks when compared to baseline models, while the increase in computational complexity with longer utterances is suppressed.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 04, 2023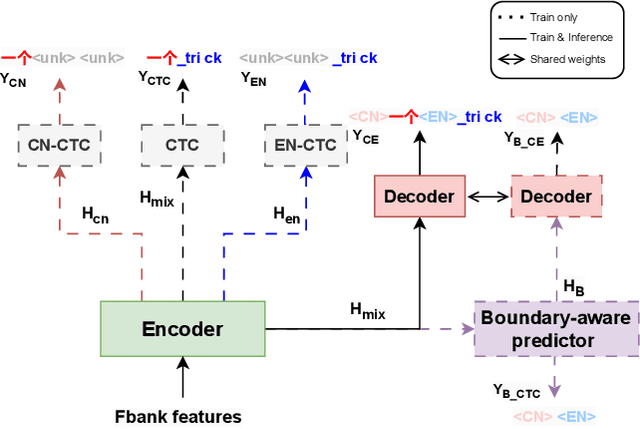
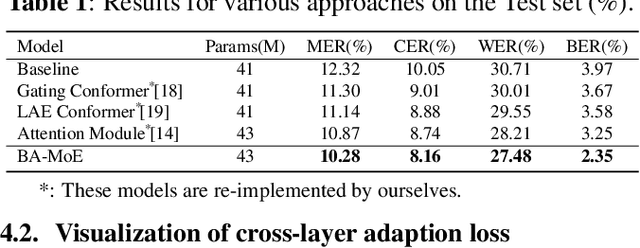
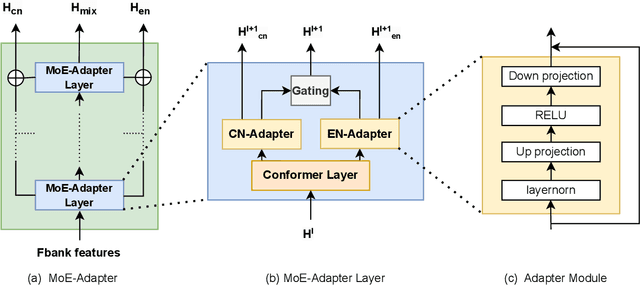
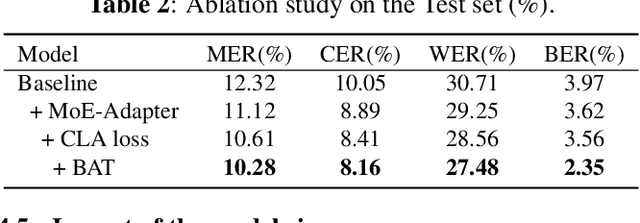
Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
End-to-End real time tracking of children's reading with pointer network
Oct 17, 2023In this work, we explore how a real time reading tracker can be built efficiently for children's voices. While previously proposed reading trackers focused on ASR-based cascaded approaches, we propose a fully end-to-end model making it less prone to lags in voice tracking. We employ a pointer network that directly learns to predict positions in the ground truth text conditioned on the streaming speech. To train this pointer network, we generate ground truth training signals by using forced alignment between the read speech and the text being read on the training set. Exploring different forced alignment models, we find a neural attention based model is at least as close in alignment accuracy to the Montreal Forced Aligner, but surprisingly is a better training signal for the pointer network. Our results are reported on one adult speech data (TIMIT) and two children's speech datasets (CMU Kids and Reading Races). Our best model can accurately track adult speech with 87.8% accuracy and the much harder and disfluent children's speech with 77.1% accuracy on CMU Kids data and a 65.3% accuracy on the Reading Races dataset.
SpatialCodec: Neural Spatial Speech Coding
Sep 14, 2023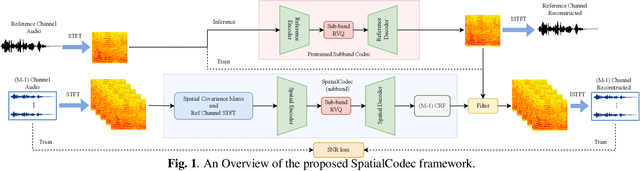
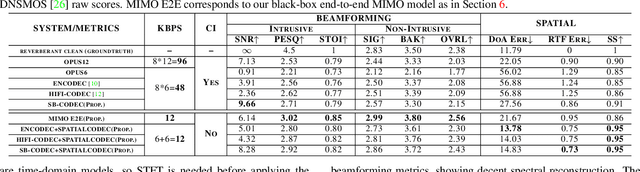
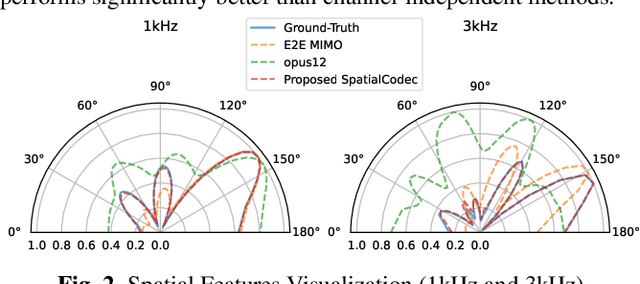
In this work, we address the challenge of encoding speech captured by a microphone array using deep learning techniques with the aim of preserving and accurately reconstructing crucial spatial cues embedded in multi-channel recordings. We propose a neural spatial audio coding framework that achieves a high compression ratio, leveraging single-channel neural sub-band codec and SpatialCodec. Our approach encompasses two phases: (i) a neural sub-band codec is designed to encode the reference channel with low bit rates, and (ii), a SpatialCodec captures relative spatial information for accurate multi-channel reconstruction at the decoder end. In addition, we also propose novel evaluation metrics to assess the spatial cue preservation: (i) spatial similarity, which calculates cosine similarity on a spatially intuitive beamspace, and (ii), beamformed audio quality. Our system shows superior spatial performance compared with high bitrate baselines and black-box neural architecture. Demos are available at https://xzwy.github.io/SpatialCodecDemo. Codes and models are available at https://github.com/XZWY/SpatialCodec.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 19, 2023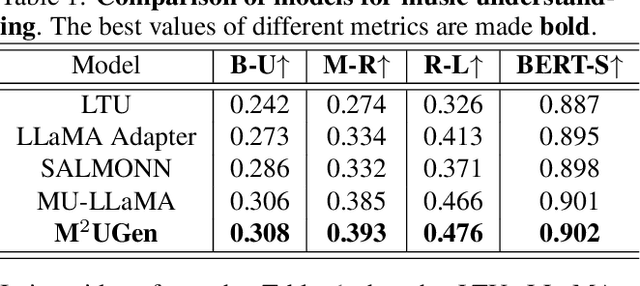
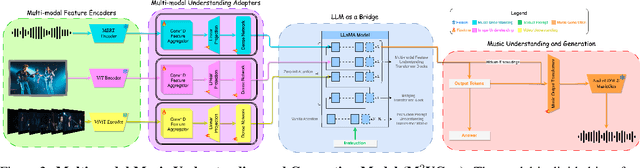
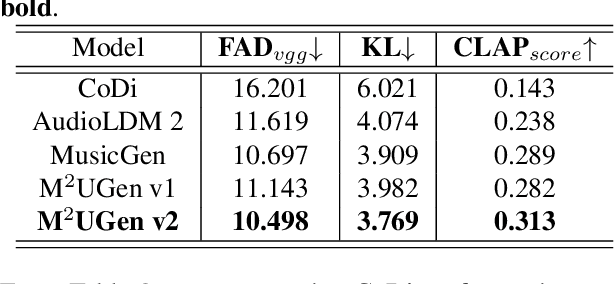
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
A Few-Shot Approach to Dysarthric Speech Intelligibility Level Classification Using Transformers
Sep 17, 2023
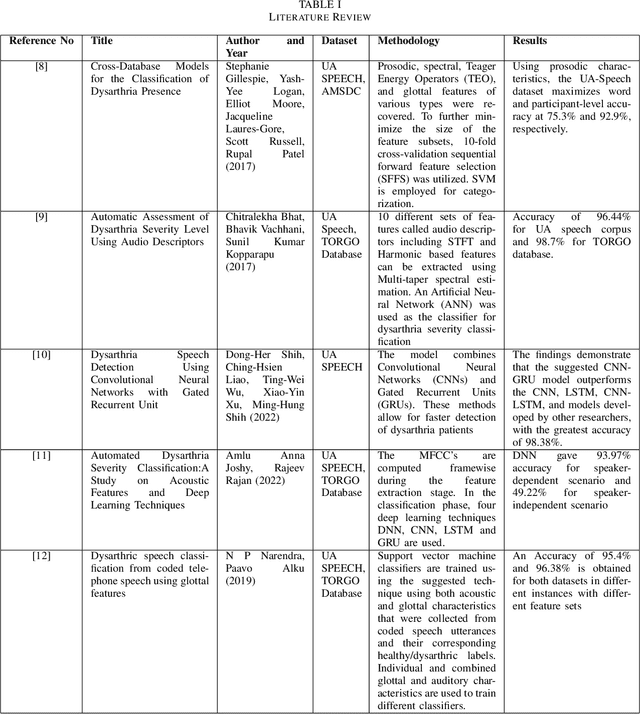
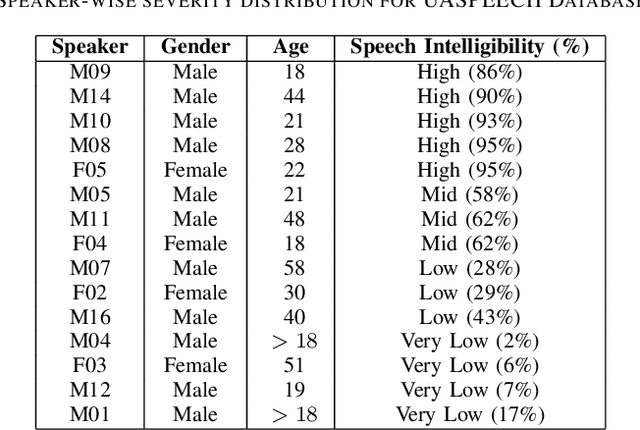
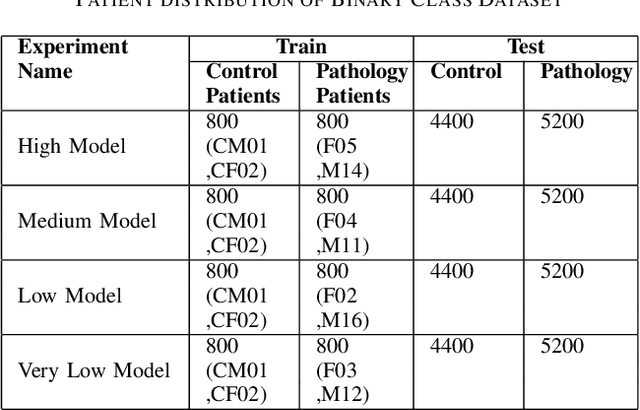
Dysarthria is a speech disorder that hinders communication due to difficulties in articulating words. Detection of dysarthria is important for several reasons as it can be used to develop a treatment plan and help improve a person's quality of life and ability to communicate effectively. Much of the literature focused on improving ASR systems for dysarthric speech. The objective of the current work is to develop models that can accurately classify the presence of dysarthria and also give information about the intelligibility level using limited data by employing a few-shot approach using a transformer model. This work also aims to tackle the data leakage that is present in previous studies. Our whisper-large-v2 transformer model trained on a subset of the UASpeech dataset containing medium intelligibility level patients achieved an accuracy of 85%, precision of 0.92, recall of 0.8 F1-score of 0.85, and specificity of 0.91. Experimental results also demonstrate that the model trained using the 'words' dataset performed better compared to the model trained on the 'letters' and 'digits' dataset. Moreover, the multiclass model achieved an accuracy of 67%.
Zero-shot audio captioning with audio-language model guidance and audio context keywords
Nov 14, 2023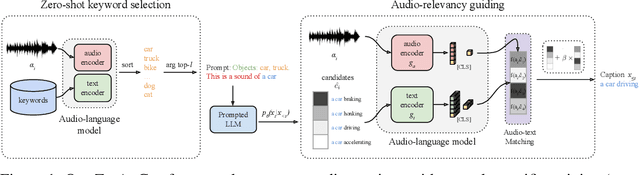
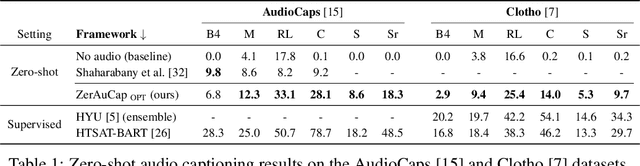

Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.
On Using Distribution-Based Compositionality Assessment to Evaluate Compositional Generalisation in Machine Translation
Nov 14, 2023Compositional generalisation (CG), in NLP and in machine learning more generally, has been assessed mostly using artificial datasets. It is important to develop benchmarks to assess CG also in real-world natural language tasks in order to understand the abilities and limitations of systems deployed in the wild. To this end, our GenBench Collaborative Benchmarking Task submission utilises the distribution-based compositionality assessment (DBCA) framework to split the Europarl translation corpus into a training and a test set in such a way that the test set requires compositional generalisation capacity. Specifically, the training and test sets have divergent distributions of dependency relations, testing NMT systems' capability of translating dependencies that they have not been trained on. This is a fully-automated procedure to create natural language compositionality benchmarks, making it simple and inexpensive to apply it further to other datasets and languages. The code and data for the experiments is available at https://github.com/aalto-speech/dbca.
Retrieve and Copy: Scaling ASR Personalization to Large Catalogs
Nov 14, 2023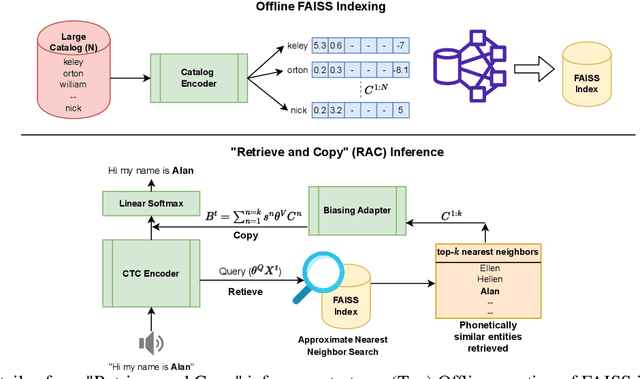

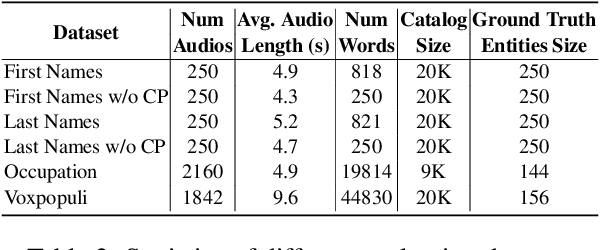
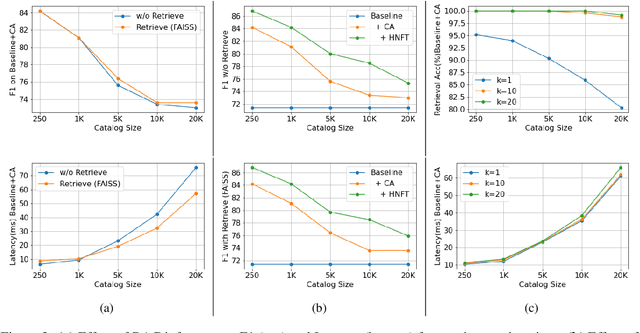
Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
A Study on Prosodic Entrainment in Relation to Therapist Empathy in Counseling Conversation
Oct 22, 2023Counseling is carried out as spoken conversation between a therapist and a client. The empathy level expressed by the therapist is considered an important index of the quality of counseling and often assessed by an observer or the client. This research investigates the entrainment of speech prosody in relation to subjectively rated empathy. Experimental results show that the entrainment of intensity is more influential to empathy observation than that of pitch or speech rate in client-therapist interaction. The observer and the client have different perceptions of therapist empathy with the same entrained phenomena in pitch and intensity. The client's intention to make adjustment on pitch variation and intensity of speech is considered an indicator of the client's perception of counseling quality.