 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Keyword Augmented Retrieval: Novel framework for Information Retrieval integrated with speech interface
Oct 06, 2023
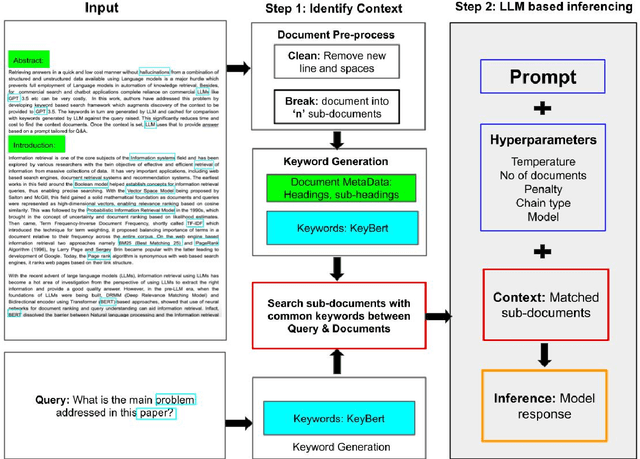
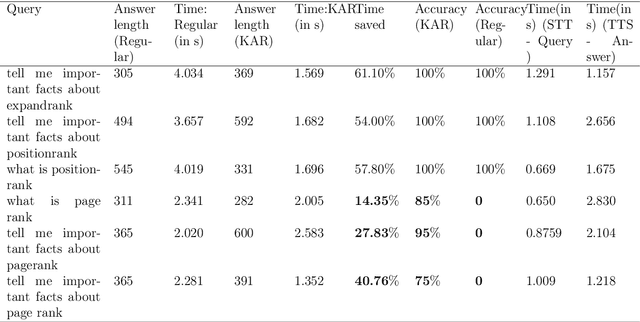
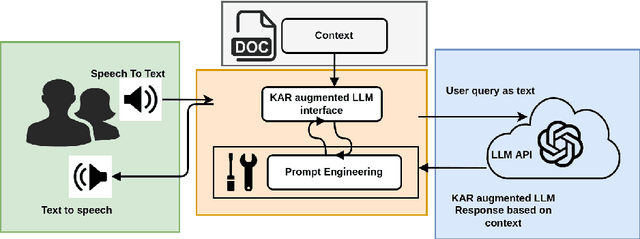
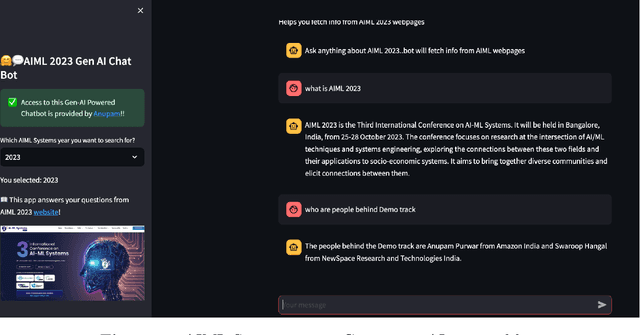
Retrieving answers in a quick and low cost manner without hallucinations from a combination of structured and unstructured data using Language models is a major hurdle which prevents employment of Language models in knowledge retrieval automation. This becomes accentuated when one wants to integrate a speech interface. Besides, for commercial search and chatbot applications, complete reliance on commercial large language models (LLMs) like GPT 3.5 etc. can be very costly. In this work, authors have addressed this problem by first developing a keyword based search framework which augments discovery of the context to be provided to the large language model. The keywords in turn are generated by LLM and cached for comparison with keywords generated by LLM against the query raised. This significantly reduces time and cost to find the context within documents. Once the context is set, LLM uses that to provide answers based on a prompt tailored for Q&A. This research work demonstrates that use of keywords in context identification reduces the overall inference time and cost of information retrieval. Given this reduction in inference time and cost with the keyword augmented retrieval framework, a speech based interface for user input and response readout was integrated. This allowed a seamless interaction with the language model.
Decoding Emotions: A comprehensive Multilingual Study of Speech Models for Speech Emotion Recognition
Aug 17, 2023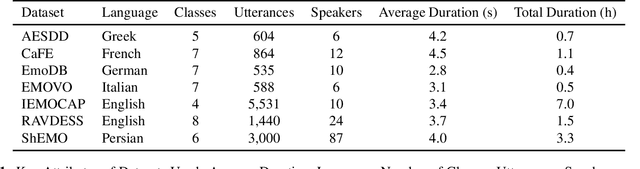
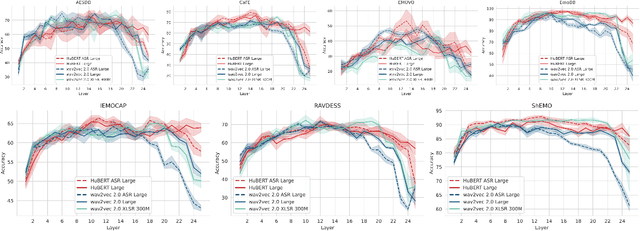
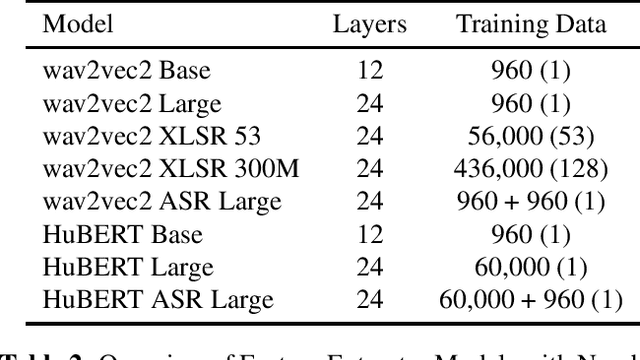
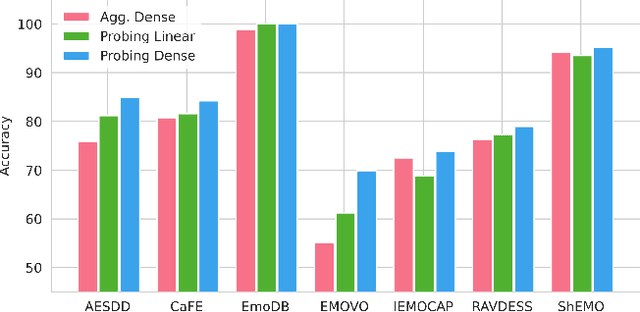
Recent advancements in transformer-based speech representation models have greatly transformed speech processing. However, there has been limited research conducted on evaluating these models for speech emotion recognition (SER) across multiple languages and examining their internal representations. This article addresses these gaps by presenting a comprehensive benchmark for SER with eight speech representation models and six different languages. We conducted probing experiments to gain insights into inner workings of these models for SER. We find that using features from a single optimal layer of a speech model reduces the error rate by 32\% on average across seven datasets when compared to systems where features from all layers of speech models are used. We also achieve state-of-the-art results for German and Persian languages. Our probing results indicate that the middle layers of speech models capture the most important emotional information for speech emotion recognition.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023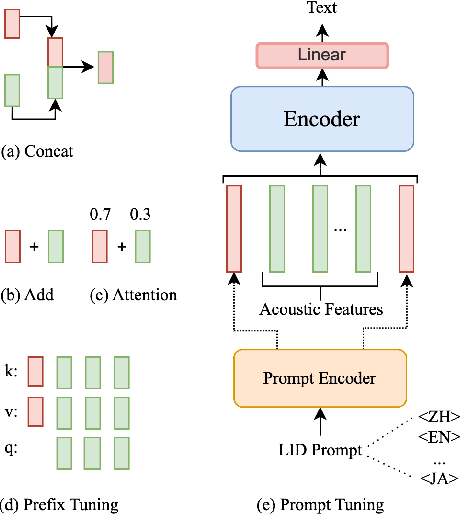
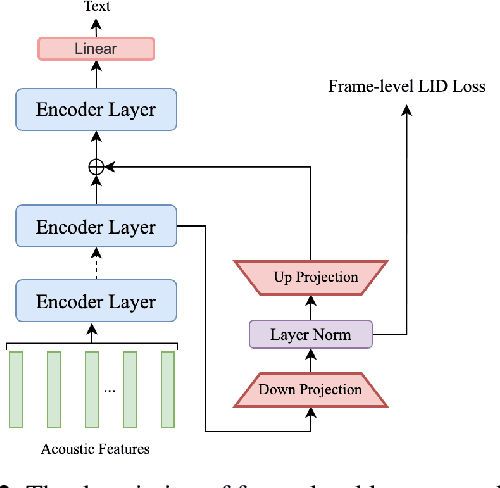
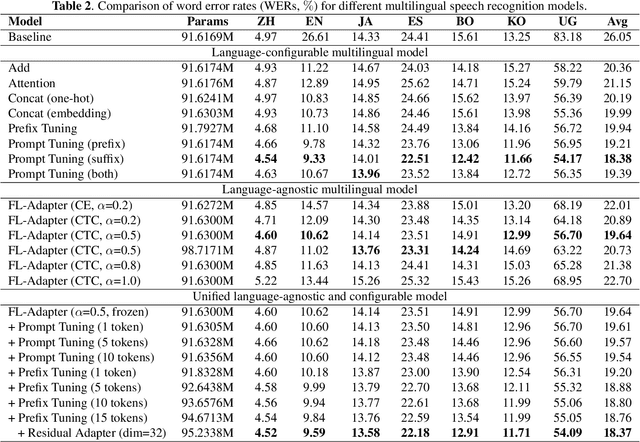
Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Sep 14, 2023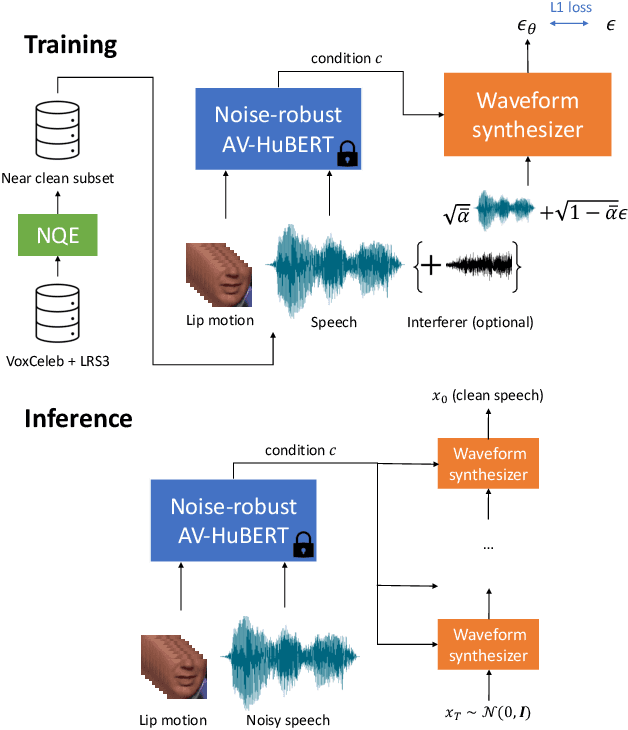
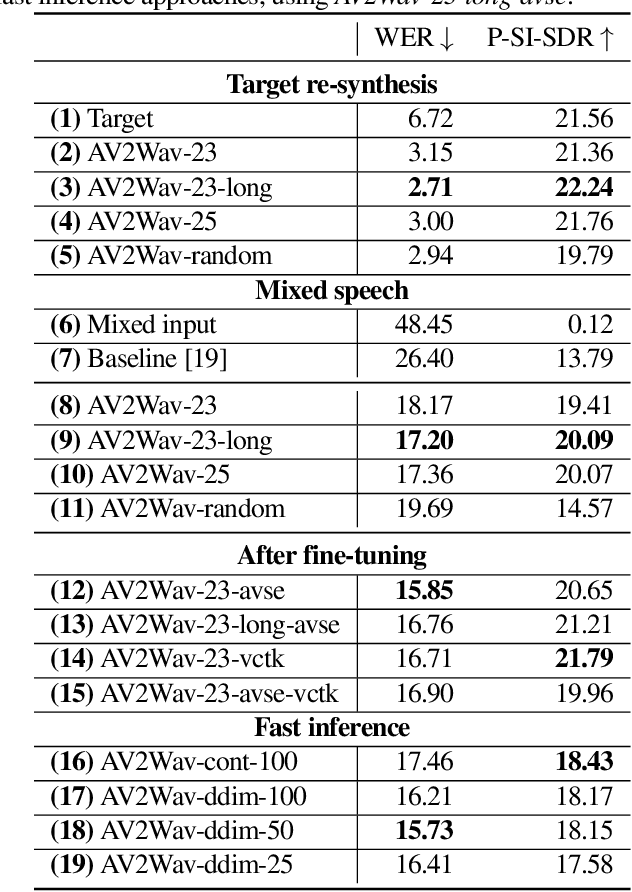

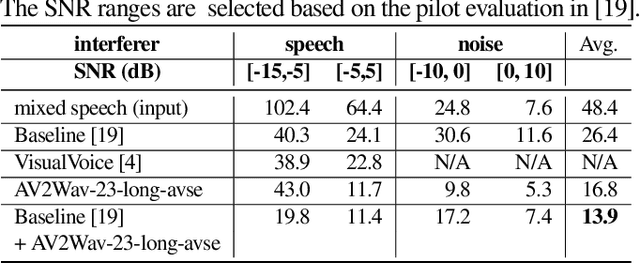
Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
Effect of Attention and Self-Supervised Speech Embeddings on Non-Semantic Speech Tasks
Aug 28, 2023Human emotion understanding is pivotal in making conversational technology mainstream. We view speech emotion understanding as a perception task which is a more realistic setting. With varying contexts (languages, demographics, etc.) different share of people perceive the same speech segment as a non-unanimous emotion. As part of the ACM Multimedia 2023 Computational Paralinguistics ChallengE (ComParE) in the EMotion Share track, we leverage their rich dataset of multilingual speakers and multi-label regression target of 'emotion share' or perception of that emotion. We demonstrate that the training scheme of different foundation models dictates their effectiveness for tasks beyond speech recognition, especially for non-semantic speech tasks like emotion understanding. This is a very complex task due to multilingual speakers, variability in the target labels, and inherent imbalance in the regression dataset. Our results show that HuBERT-Large with a self-attention-based light-weight sequence model provides 4.6% improvement over the reported baseline.
A Unified Framework for Multimodal, Multi-Part Human Motion Synthesis
Nov 28, 2023The field has made significant progress in synthesizing realistic human motion driven by various modalities. Yet, the need for different methods to animate various body parts according to different control signals limits the scalability of these techniques in practical scenarios. In this paper, we introduce a cohesive and scalable approach that consolidates multimodal (text, music, speech) and multi-part (hand, torso) human motion generation. Our methodology unfolds in several steps: We begin by quantizing the motions of diverse body parts into separate codebooks tailored to their respective domains. Next, we harness the robust capabilities of pre-trained models to transcode multimodal signals into a shared latent space. We then translate these signals into discrete motion tokens by iteratively predicting subsequent tokens to form a complete sequence. Finally, we reconstruct the continuous actual motion from this tokenized sequence. Our method frames the multimodal motion generation challenge as a token prediction task, drawing from specialized codebooks based on the modality of the control signal. This approach is inherently scalable, allowing for the easy integration of new modalities. Extensive experiments demonstrated the effectiveness of our design, emphasizing its potential for broad application.
Unifying Robustness and Fidelity: A Comprehensive Study of Pretrained Generative Methods for Speech Enhancement in Adverse Conditions
Sep 16, 2023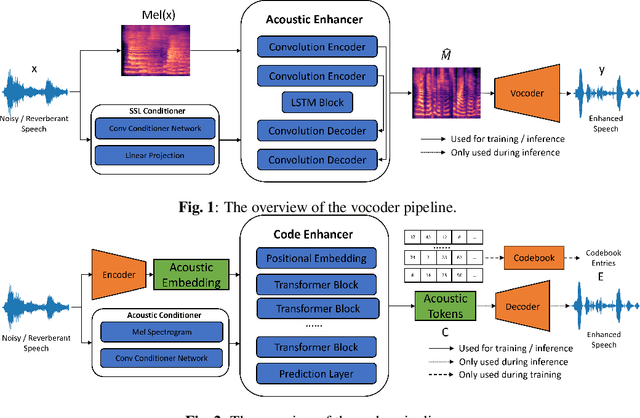

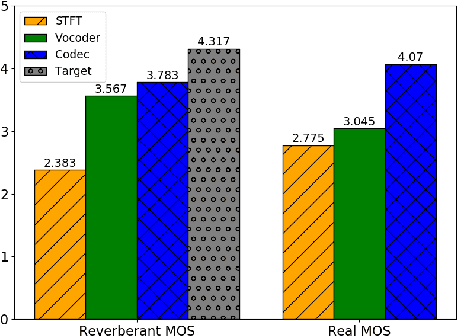
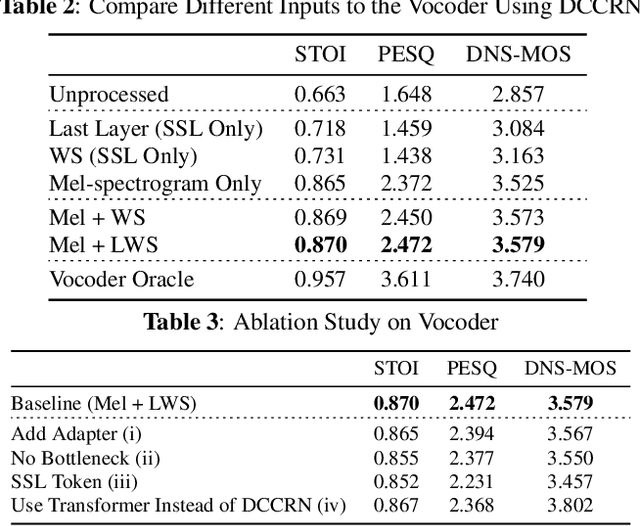
Enhancing speech signal quality in adverse acoustic environments is a persistent challenge in speech processing. Existing deep learning based enhancement methods often struggle to effectively remove background noise and reverberation in real-world scenarios, hampering listening experiences. To address these challenges, we propose a novel approach that uses pre-trained generative methods to resynthesize clean, anechoic speech from degraded inputs. This study leverages pre-trained vocoder or codec models to synthesize high-quality speech while enhancing robustness in challenging scenarios. Generative methods effectively handle information loss in speech signals, resulting in regenerated speech that has improved fidelity and reduced artifacts. By harnessing the capabilities of pre-trained models, we achieve faithful reproduction of the original speech in adverse conditions. Experimental evaluations on both simulated datasets and realistic samples demonstrate the effectiveness and robustness of our proposed methods. Especially by leveraging codec, we achieve superior subjective scores for both simulated and realistic recordings. The generated speech exhibits enhanced audio quality, reduced background noise, and reverberation. Our findings highlight the potential of pre-trained generative techniques in speech processing, particularly in scenarios where traditional methods falter. Demos are available at https://whmrtm.github.io/SoundResynthesis.
TurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023
Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
tinyCLAP: Distilling Constrastive Language-Audio Pretrained Models
Nov 24, 2023Contrastive Language-Audio Pretraining (CLAP) became of crucial importance in the field of audio and speech processing. Its employment ranges from sound event detection to text-to-audio generation. However, one of the main limitations is the considerable amount of data required in the training process and the overall computational complexity during inference. This paper investigates how we can reduce the complexity of contrastive language-audio pre-trained models, yielding an efficient model that we call tinyCLAP. We derive an unimodal distillation loss from first principles and explore how the dimensionality of the shared, multimodal latent space can be reduced via pruning. TinyCLAP uses only 6% of the original Microsoft CLAP parameters with a minimal reduction (less than 5%) in zero-shot classification performance across the three sound event detection datasets on which it was tested
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Sep 04, 2023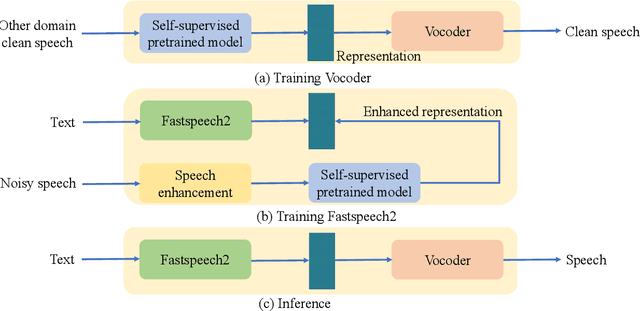


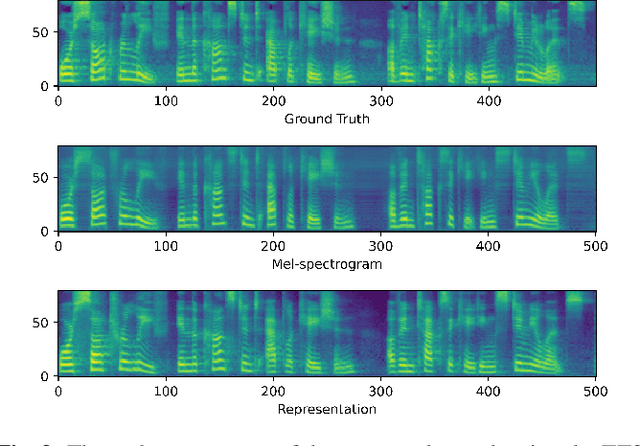
Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contains noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HiFi-GAN, we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation FastSpeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav.