 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multimodal Depression Classification Using Articulatory Coordination Features And Hierarchical Attention Based Text Embeddings
Feb 13, 2022
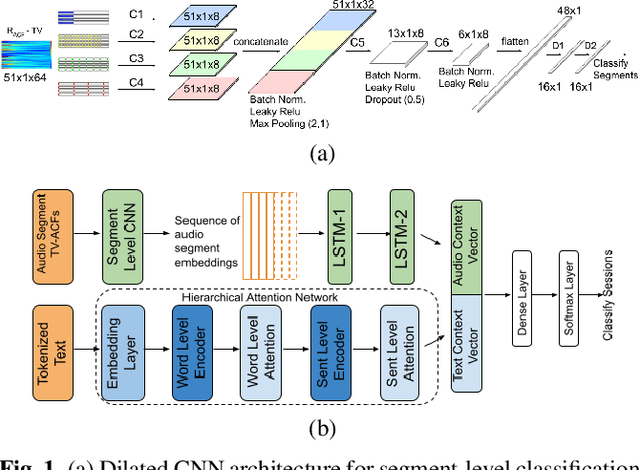

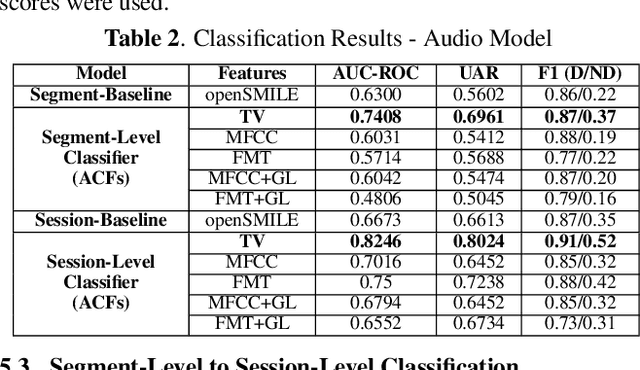
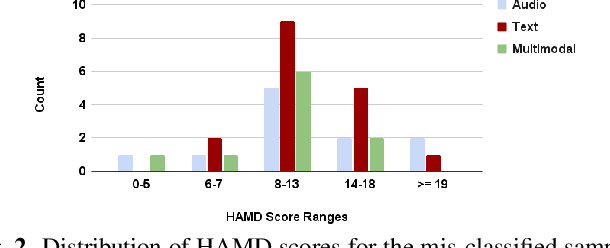
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to uni-modal classifiers (7.5% and 13.7% for audio and text respectively). We show that in the case of limited training data, a segment-level classifier can first be trained to then obtain a session-wise prediction without hindering the performance, using a multi-stage convolutional recurrent neural network. A text model is trained using a Hierarchical Attention Network (HAN). The multimodal system is developed by combining embeddings from the session-level audio model and the HAN text model
Analysis of Joint Speech-Text Embeddings for Semantic Matching
Apr 04, 2022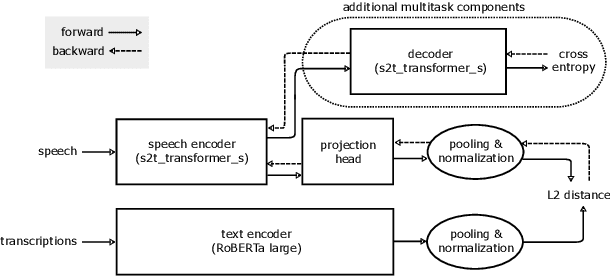
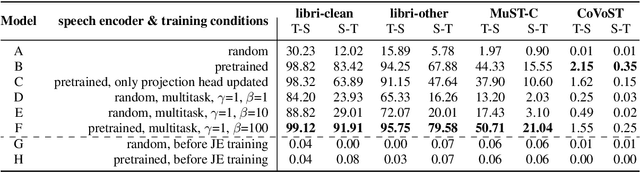

Embeddings play an important role in many recent end-to-end solutions for language processing problems involving more than one data modality. Although there has been some effort to understand the properties of single-modality embedding spaces, particularly that of text, their cross-modal counterparts are less understood. In this work, we study a joint speech-text embedding space trained for semantic matching by minimizing the distance between paired utterance and transcription inputs. This was done through dual encoders in a teacher-student model setup, with a pretrained language model acting as the teacher and a transformer-based speech encoder as the student. We extend our method to incorporate automatic speech recognition through both pretraining and multitask scenarios and found that both approaches improve semantic matching. Multiple techniques were utilized to analyze and evaluate cross-modal semantic alignment of the embeddings: a quantitative retrieval accuracy metric, zero-shot classification to investigate generalizability, and probing of the encoders to observe the extent of knowledge transfer from one modality to another.
E2E-based Multi-task Learning Approach to Joint Speech and Accent Recognition
Jun 15, 2021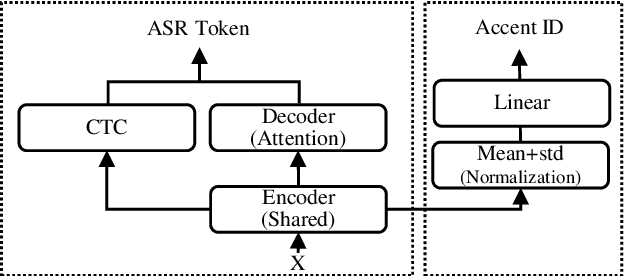
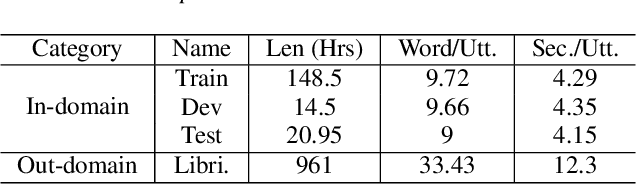
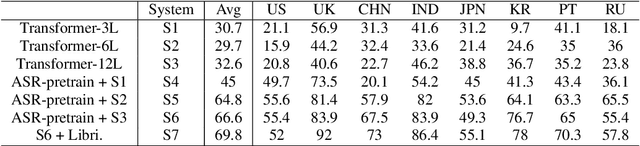
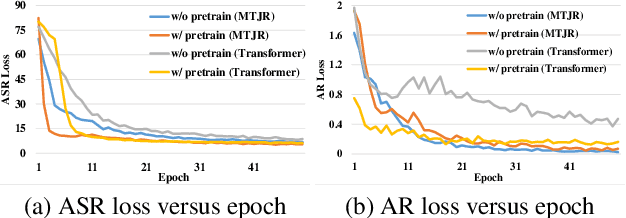
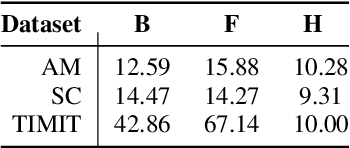
In this paper, we propose a single multi-task learning framework to perform End-to-End (E2E) speech recognition (ASR) and accent recognition (AR) simultaneously. The proposed framework is not only more compact but can also yield comparable or even better results than standalone systems. Specifically, we found that the overall performance is predominantly determined by the ASR task, and the E2E-based ASR pretraining is essential to achieve improved performance, particularly for the AR task. Additionally, we conduct several analyses of the proposed method. First, though the objective loss for the AR task is much smaller compared with its counterpart of ASR task, a smaller weighting factor with the AR task in the joint objective function is necessary to yield better results for each task. Second, we found that sharing only a few layers of the encoder yields better AR results than sharing the overall encoder. Experimentally, the proposed method produces WER results close to the best standalone E2E ASR ones, while it achieves 7.7% and 4.2% relative improvement over standalone and single-task-based joint recognition methods on test set for accent recognition respectively.
Accounting for Variations in Speech Emotion Recognition with Nonparametric Hierarchical Neural Network
Sep 09, 2021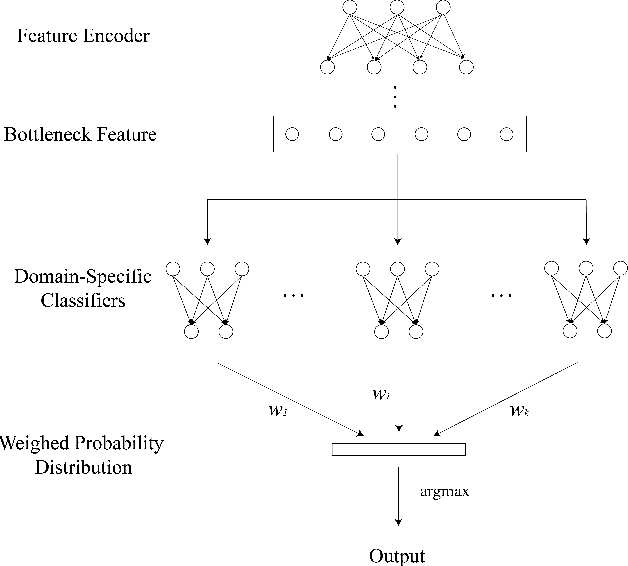

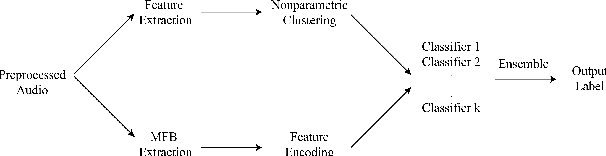

In recent years, deep-learning-based speech emotion recognition models have outperformed classical machine learning models. Previously, neural network designs, such as Multitask Learning, have accounted for variations in emotional expressions due to demographic and contextual factors. However, existing models face a few constraints: 1) they rely on a clear definition of domains (e.g. gender, noise condition, etc.) and the availability of domain labels; 2) they often attempt to learn domain-invariant features while emotion expressions can be domain-specific. In the present study, we propose the Nonparametric Hierarchical Neural Network (NHNN), a lightweight hierarchical neural network model based on Bayesian nonparametric clustering. In comparison to Multitask Learning approaches, the proposed model does not require domain/task labels. In our experiments, the NHNN models generally outperform the models with similar levels of complexity and state-of-the-art models in within-corpus and cross-corpus tests. Through clustering analysis, we show that the NHNN models are able to learn group-specific features and bridge the performance gap between groups.
3D Feature Pyramid Attention Module for Robust Visual Speech Recognition
Oct 17, 2018
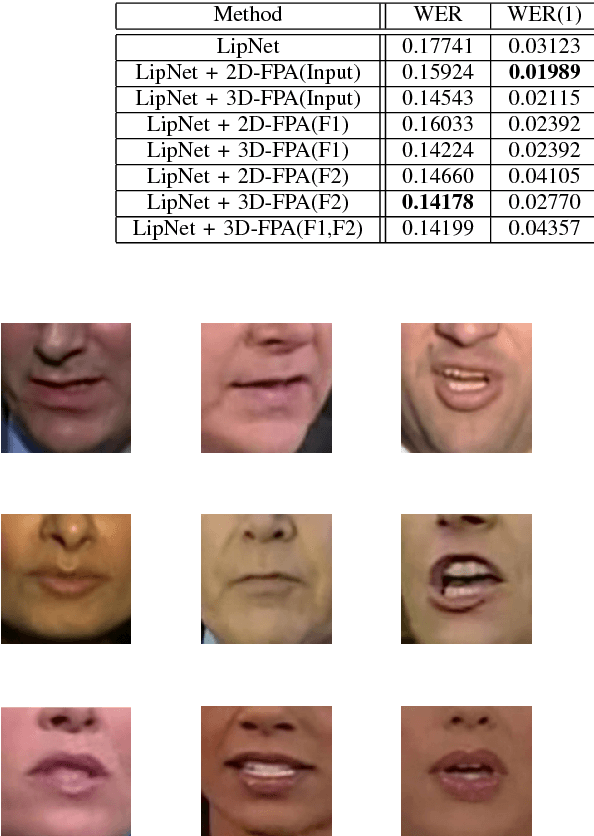


Visual speech recognition is the task to decode the speech content from a video based on visual information, especially the movements of lips. It is also referenced as lipreading. Motivated by two problems existing in lipreading, words with similar pronunciation and the variation of word duration, we propose a novel 3D Feature Pyramid Attention (3D-FPA) module to jointly improve the representation power of features in both the spatial and temporal domains. Specifically, the input features are downsampled for 3 times in both the spatial and temporal dimensions to construct spatiotemporal feature pyramids. Then high-level features are upsampled and combined with low-level features, finally generating a pixel-level soft attention mask to be multiplied with the input features.It enhances the discriminative power of features and exploits the temporal multi-scale information while decoding the visual speeches. Also, this module provides a new method to construct and utilize temporal pyramid structures in video analysis tasks. The field of temporal featrue pyramids are still under exploring compared to the plentiful works on spatial feature pyramids for image analysis tasks. To validate the effectiveness and adaptability of our proposed module, we embed the module in a sentence-level lipreading model, LipNet, with the result of 3.6% absolute decrease in word error rate, and a word-level model, with the result of 1.4% absolute improvement in accuracy.
Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation
Aug 08, 2021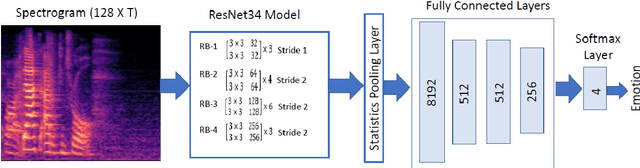
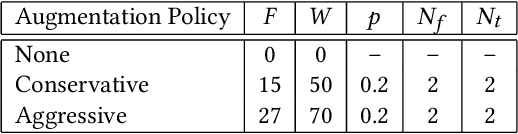
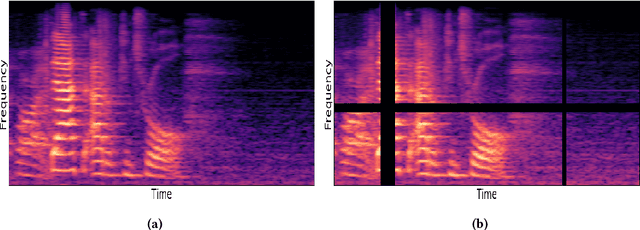
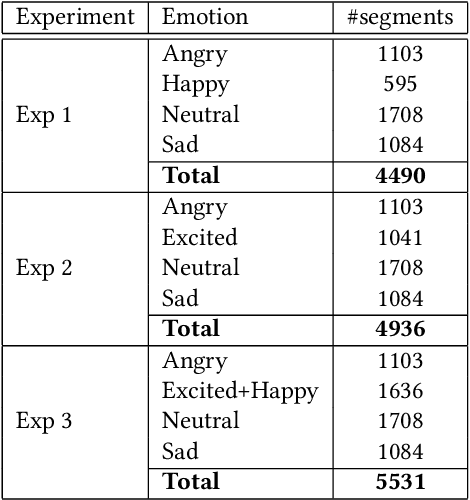
Automatic speech emotion recognition (SER) is a challenging task that plays a crucial role in natural human-computer interaction. One of the main challenges in SER is data scarcity, i.e., insufficient amounts of carefully labeled data to build and fully explore complex deep learning models for emotion classification. This paper aims to address this challenge using a transfer learning strategy combined with spectrogram augmentation. Specifically, we propose a transfer learning approach that leverages a pre-trained residual network (ResNet) model including a statistics pooling layer from speaker recognition trained using large amounts of speaker-labeled data. The statistics pooling layer enables the model to efficiently process variable-length input, thereby eliminating the need for sequence truncation which is commonly used in SER systems. In addition, we adopt a spectrogram augmentation technique to generate additional training data samples by applying random time-frequency masks to log-mel spectrograms to mitigate overfitting and improve the generalization of emotion recognition models. We evaluate the effectiveness of our proposed approach on the interactive emotional dyadic motion capture (IEMOCAP) dataset. Experimental results indicate that the transfer learning and spectrogram augmentation approaches improve the SER performance, and when combined achieve state-of-the-art results.
Learn Spelling from Teachers: Transferring Knowledge from Language Models to Sequence-to-Sequence Speech Recognition
Jul 13, 2019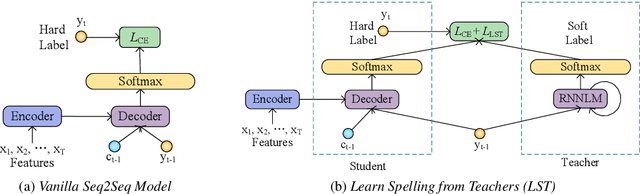
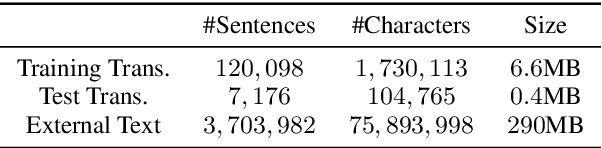
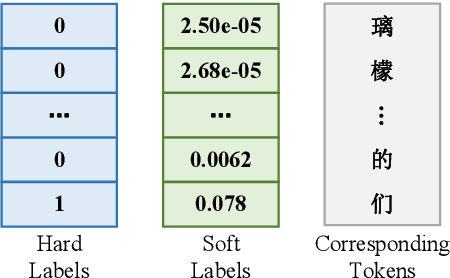

Integrating an external language model into a sequence-to-sequence speech recognition system is non-trivial. Previous works utilize linear interpolation or a fusion network to integrate external language models. However, these approaches introduce external components, and increase decoding computation. In this paper, we instead propose a knowledge distillation based training approach to integrating external language models into a sequence-to-sequence model. A recurrent neural network language model, which is trained on large scale external text, generates soft labels to guide the sequence-to-sequence model training. Thus, the language model plays the role of the teacher. This approach does not add any external component to the sequence-to-sequence model during testing. And this approach is flexible to be combined with shallow fusion technique together for decoding. The experiments are conducted on public Chinese datasets AISHELL-1 and CLMAD. Our approach achieves a character error rate of 9.3%, which is relatively reduced by 18.42% compared with the vanilla sequence-to-sequence model.
Improved training of end-to-end attention models for speech recognition
May 08, 2018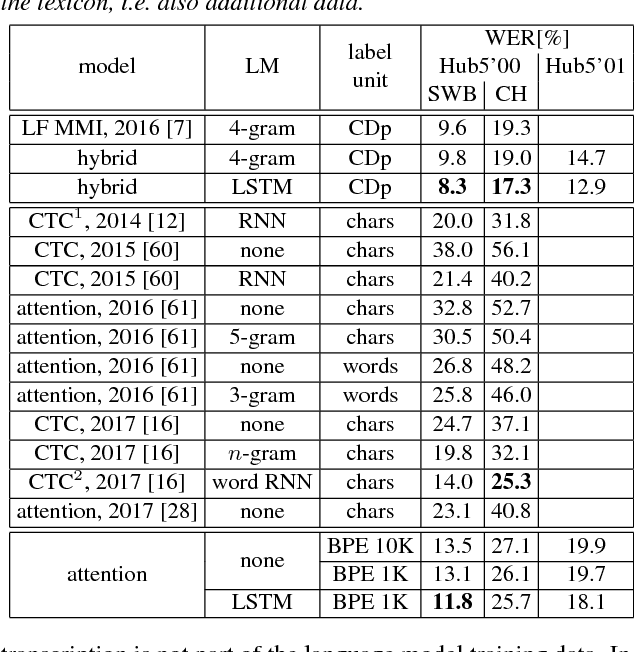
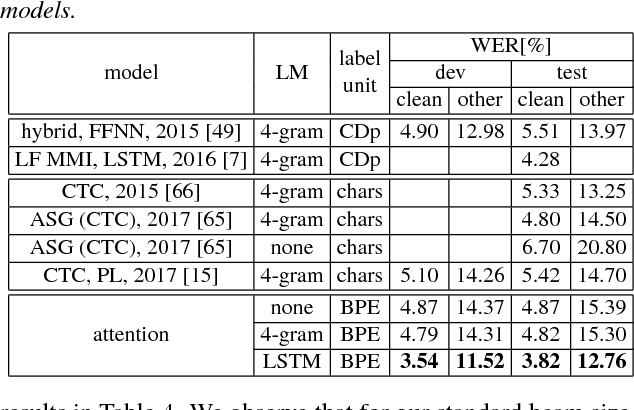
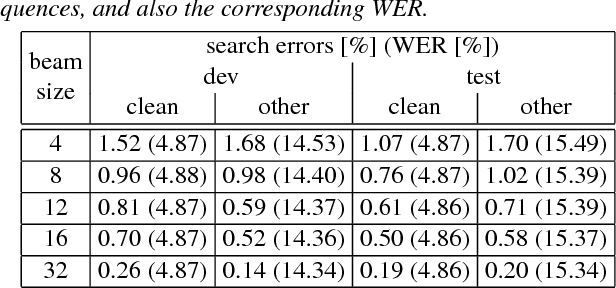
Sequence-to-sequence attention-based models on subword units allow simple open-vocabulary end-to-end speech recognition. In this work, we show that such models can achieve competitive results on the Switchboard 300h and LibriSpeech 1000h tasks. In particular, we report the state-of-the-art word error rates (WER) of 3.54% on the dev-clean and 3.82% on the test-clean evaluation subsets of LibriSpeech. We introduce a new pretraining scheme by starting with a high time reduction factor and lowering it during training, which is crucial both for convergence and final performance. In some experiments, we also use an auxiliary CTC loss function to help the convergence. In addition, we train long short-term memory (LSTM) language models on subword units. By shallow fusion, we report up to 27% relative improvements in WER over the attention baseline without a language model.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

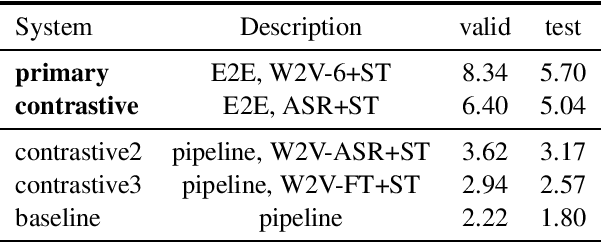

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Multilingual Speech Recognition With A Single End-To-End Model
Feb 15, 2018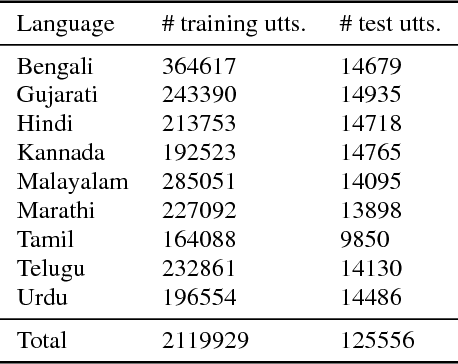
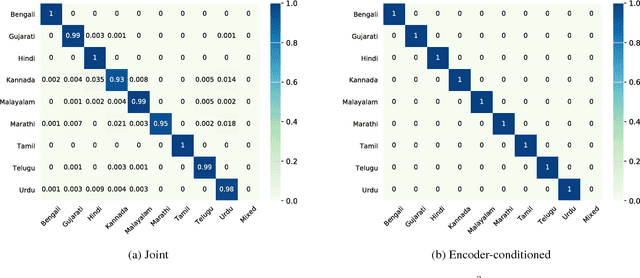
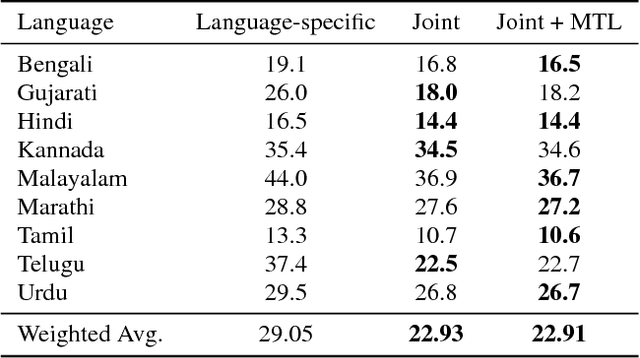
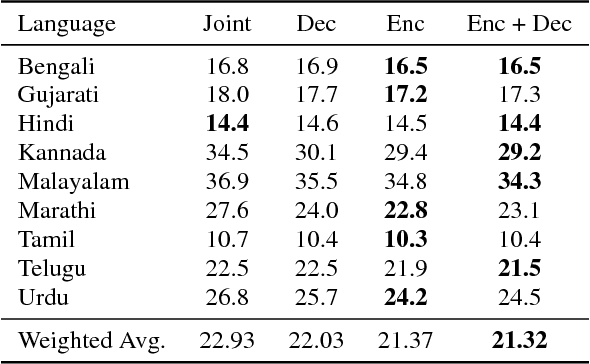
Training a conventional automatic speech recognition (ASR) system to support multiple languages is challenging because the sub-word unit, lexicon and word inventories are typically language specific. In contrast, sequence-to-sequence models are well suited for multilingual ASR because they encapsulate an acoustic, pronunciation and language model jointly in a single network. In this work we present a single sequence-to-sequence ASR model trained on 9 different Indian languages, which have very little overlap in their scripts. Specifically, we take a union of language-specific grapheme sets and train a grapheme-based sequence-to-sequence model jointly on data from all languages. We find that this model, which is not explicitly given any information about language identity, improves recognition performance by 21% relative compared to analogous sequence-to-sequence models trained on each language individually. By modifying the model to accept a language identifier as an additional input feature, we further improve performance by an additional 7% relative and eliminate confusion between different languages.