 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Multilingual Speech Recognition using Knowledge Transfer across Learning Processes
Oct 15, 2021
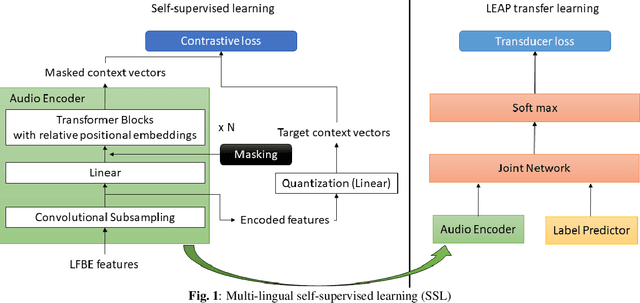
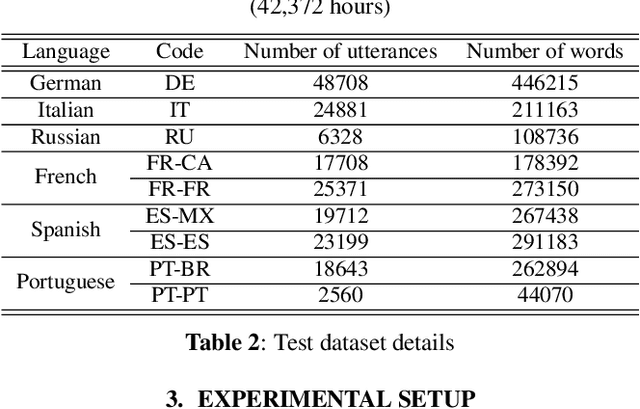
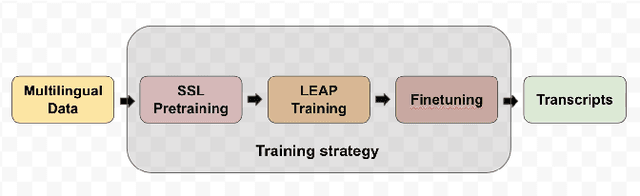
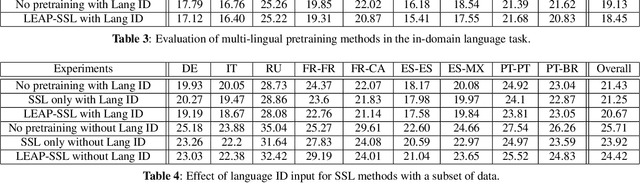
Multilingual end-to-end(E2E) models have shown a great potential in the expansion of the language coverage in the realm of automatic speech recognition(ASR). In this paper, we aim to enhance the multilingual ASR performance in two ways, 1)studying the impact of feeding a one-hot vector identifying the language, 2)formulating the task with a meta-learning objective combined with self-supervised learning (SSL). We associate every language with a distinct task manifold and attempt to improve the performance by transferring knowledge across learning processes itself as compared to transferring through final model parameters. We employ this strategy on a dataset comprising of 6 languages for an in-domain ASR task, by minimizing an objective related to expected gradient path length. Experimental results reveal the best pre-training strategy resulting in 3.55% relative reduction in overall WER. A combination of LEAP and SSL yields 3.51% relative reduction in overall WER when using language ID.
Mitigating Closed-model Adversarial Examples with Bayesian Neural Modeling for Enhanced End-to-End Speech Recognition
Feb 17, 2022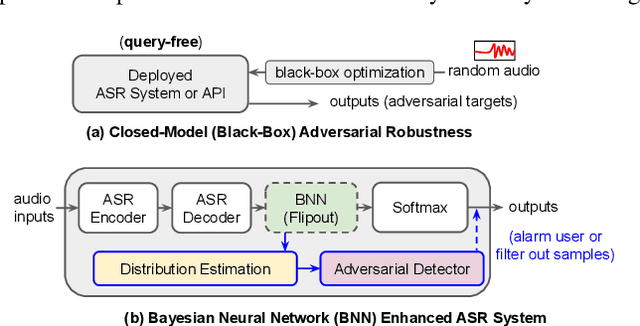

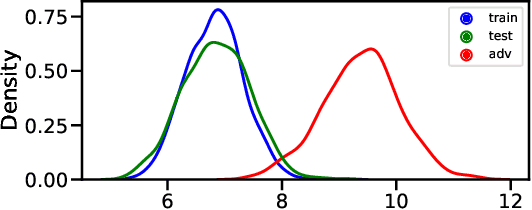
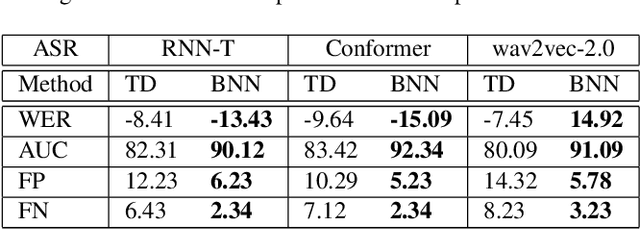
In this work, we aim to enhance the system robustness of end-to-end automatic speech recognition (ASR) against adversarially-noisy speech examples. We focus on a rigorous and empirical "closed-model adversarial robustness" setting (e.g., on-device or cloud applications). The adversarial noise is only generated by closed-model optimization (e.g., evolutionary and zeroth-order estimation) without accessing gradient information of a targeted ASR model directly. We propose an advanced Bayesian neural network (BNN) based adversarial detector, which could model latent distributions against adaptive adversarial perturbation with divergence measurement. We further simulate deployment scenarios of RNN Transducer, Conformer, and wav2vec-2.0 based ASR systems with the proposed adversarial detection system. Leveraging the proposed BNN based detection system, we improve detection rate by +2.77 to +5.42% (relative +3.03 to +6.26%) and reduce the word error rate by 5.02 to 7.47% on LibriSpeech datasets compared to the current model enhancement methods against the adversarial speech examples.
Effect of different splitting criteria on the performance of speech emotion recognition
Oct 26, 2022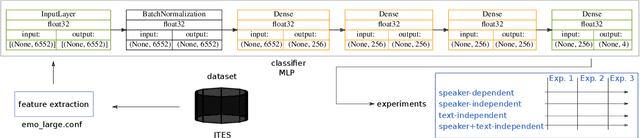


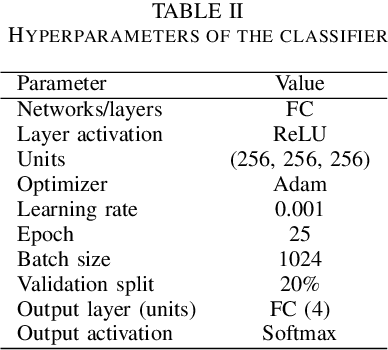
Traditional speech emotion recognition (SER) evaluations have been performed merely on a speaker-independent condition; some of them even did not evaluate their result on this condition. This paper highlights the importance of splitting training and test data for SER by script, known as sentence-open or text-independent criteria. The results show that employing sentence-open criteria degraded the performance of SER. This finding implies the difficulties of recognizing emotion from speech in different linguistic information embedded in acoustic information. Surprisingly, text-independent criteria consistently performed worse than speaker+text-independent criteria. The full order of difficulties for splitting criteria on SER performances from the most difficult to the easiest is text-independent, speaker+text-independent, speaker-independent, and speaker+text-dependent. The gap between speaker+text-independent and text-independent was smaller than other criteria, strengthening the difficulties of recognizing emotion from speech in different sentences.
* Accepted at TENCON 2021
Reducing language context confusion for end-to-end code-switching automatic speech recognition
Jan 28, 2022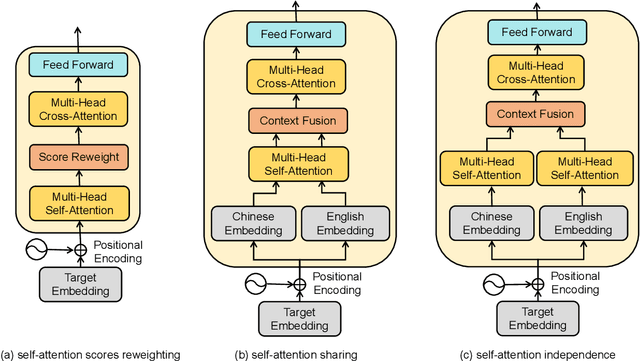
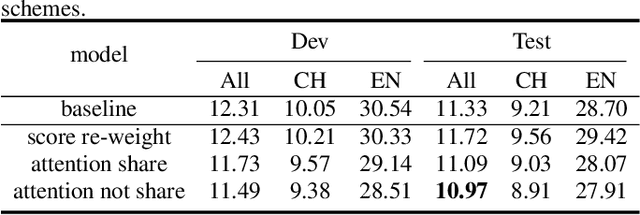
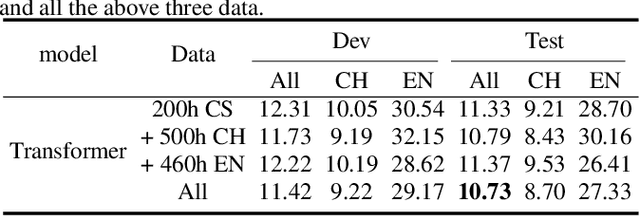
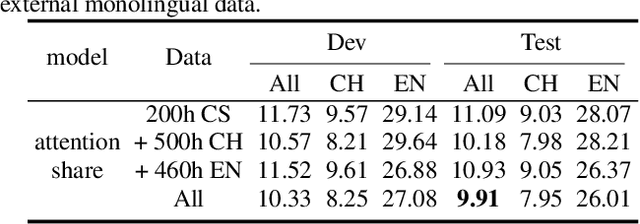
Code-switching is about dealing with alternative languages in the communication process. Training end-to-end (E2E) automatic speech recognition (ASR) systems for code-switching is known to be a challenging problem because of the lack of data compounded by the increased language context confusion due to the presence of more than one language. In this paper, we propose a language-related attention mechanism to reduce multilingual context confusion for the E2E code-switching ASR model based on the Equivalence Constraint Theory (EC). The linguistic theory requires that any monolingual fragment that occurs in the code-switching sentence must occur in one of the monolingual sentences. It establishes a bridge between monolingual data and code-switching data. By calculating the respective attention of multiple languages, our method can efficiently transfer language knowledge from rich monolingual data. We evaluate our method on ASRU 2019 Mandarin-English code-switching challenge dataset. Compared with the baseline model, the proposed method achieves 11.37% relative mix error rate reduction.
The Use of Voice Source Features for Sung Speech Recognition
Feb 23, 2021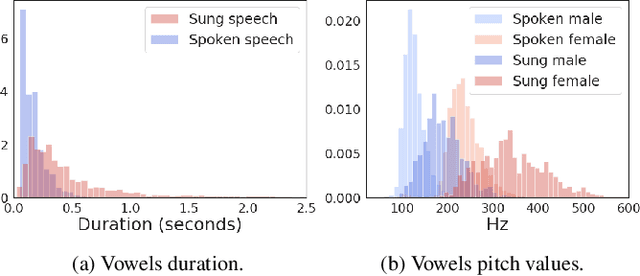
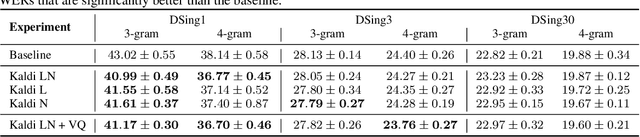
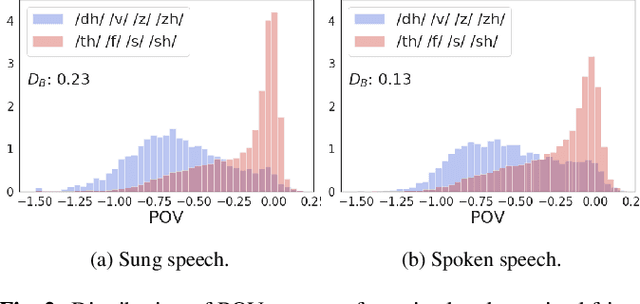
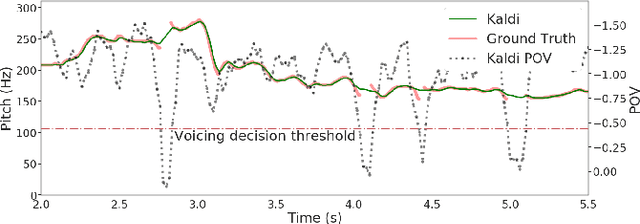
In this paper, we ask whether vocal source features (pitch, shimmer, jitter, etc) can improve the performance of automatic sung speech recognition, arguing that conclusions previously drawn from spoken speech studies may not be valid in the sung speech domain. We first use a parallel singing/speaking corpus (NUS-48E) to illustrate differences in sung vs spoken voicing characteristics including pitch range, syllables duration, vibrato, jitter and shimmer. We then use this analysis to inform speech recognition experiments on the sung speech DSing corpus, using a state of the art acoustic model and augmenting conventional features with various voice source parameters. Experiments are run with three standard (increasingly large) training sets, DSing1 (15.1 hours), DSing3 (44.7 hours) and DSing30 (149.1 hours). Pitch combined with degree of voicing produces a significant decrease in WER from 38.1% to 36.7% when training with DSing1 however smaller decreases in WER observed when training with the larger more varied DSing3 and DSing30 sets were not seen to be statistically significant. Voicing quality characteristics did not improve recognition performance although analysis suggests that they do contribute to an improved discrimination between voiced/unvoiced phoneme pairs.
Stutter-TTS: Controlled Synthesis and Improved Recognition of Stuttered Speech
Nov 04, 2022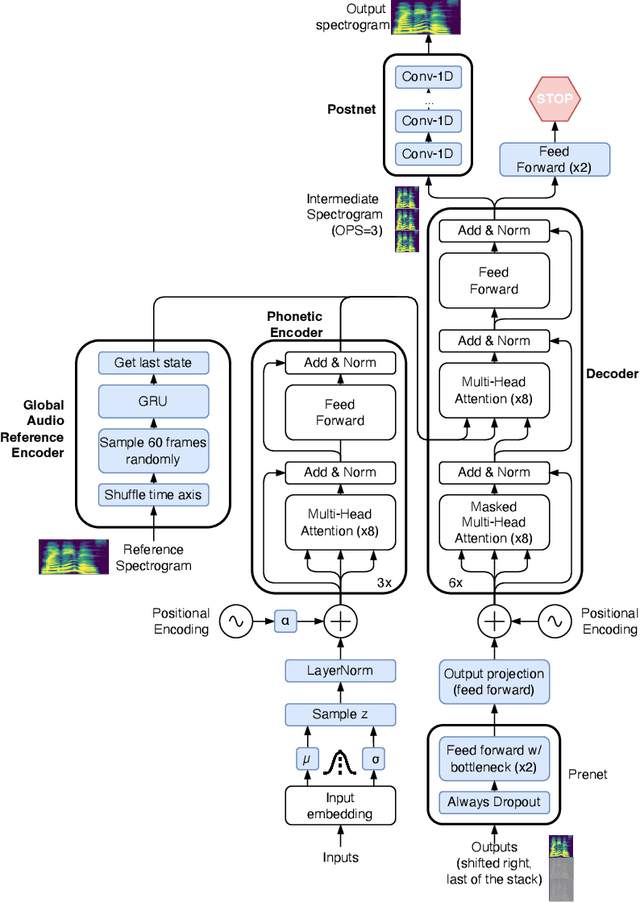

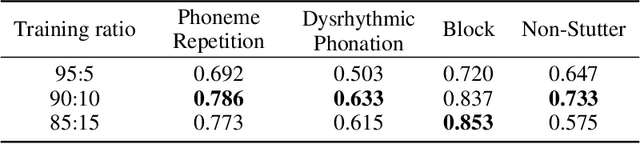
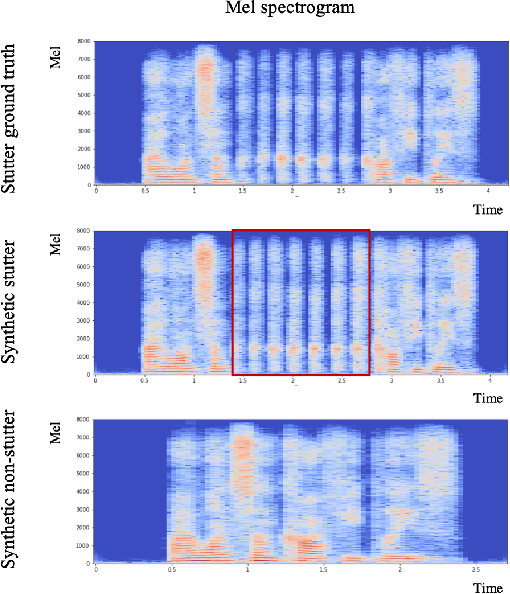
Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of speech with stutter thus presents an opportunity to improve ASR for this type of speech. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent specific stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance. We are able to synthesize stutter events with high accuracy (F1-scores between 0.63 and 0.84, depending on stutter type). By fine-tuning an ASR model on synthetic stuttered speech we are able to reduce word error by 5.7% relative on stuttered utterances, with only minor (<0.2% relative) degradation for fluent utterances.
* 8 pages, 3 figures, 2 tables
A study on native American English speech recognition by Indian listeners with varying word familiarity level
Dec 08, 2021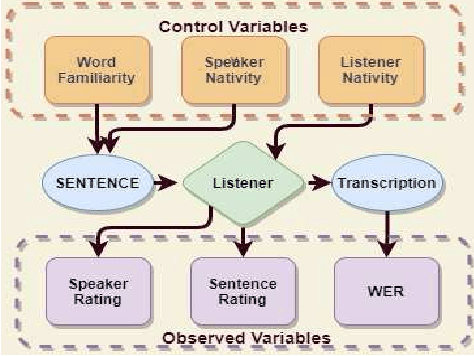
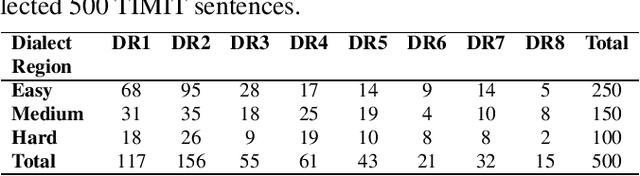
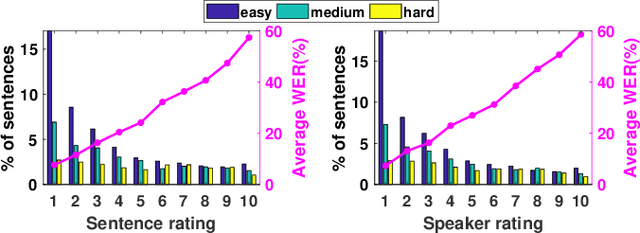
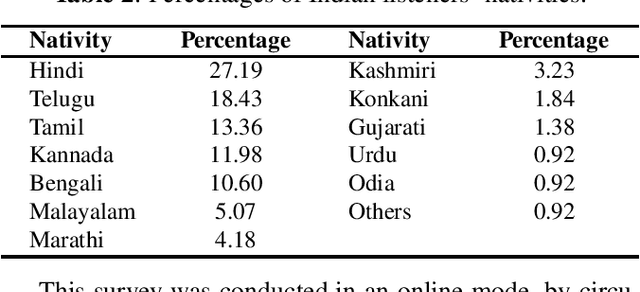
In this study, listeners of varied Indian nativities are asked to listen and recognize TIMIT utterances spoken by American speakers. We have three kinds of responses from each listener while they recognize an utterance: 1. Sentence difficulty ratings, 2. Speaker difficulty ratings, and 3. Transcription of the utterance. From these transcriptions, word error rate (WER) is calculated and used as a metric to evaluate the similarity between the recognized and the original sentences.The sentences selected in this study are categorized into three groups: Easy, Medium and Hard, based on the frequency ofoccurrence of the words in them. We observe that the sentence, speaker difficulty ratings and the WERs increase from easy to hard categories of sentences. We also compare the human speech recognition performance with that using three automatic speech recognition (ASR) under following three combinations of acoustic model (AM) and language model(LM): ASR1) AM trained with recordings from speakers of Indian origin and LM built on TIMIT text, ASR2) AM using recordings from native American speakers and LM built ontext from LIBRI speech corpus, and ASR3) AM using recordings from native American speakers and LM build on LIBRI speech and TIMIT text. We observe that HSR performance is similar to that of ASR1 whereas ASR3 achieves the best performance. Speaker nativity wise analysis shows that utterances from speakers of some nativity are more difficult to recognize by Indian listeners compared to few other nativities
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023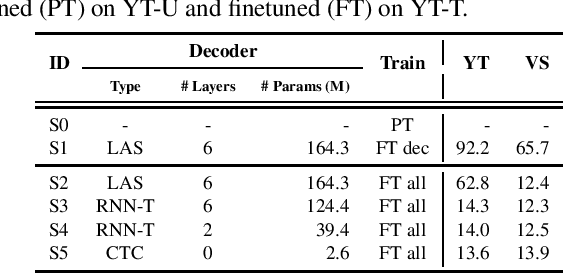
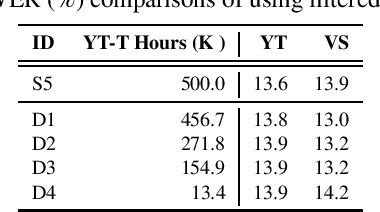
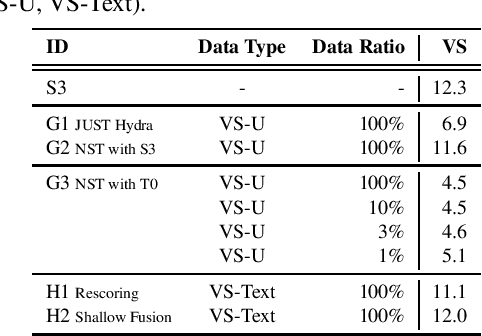
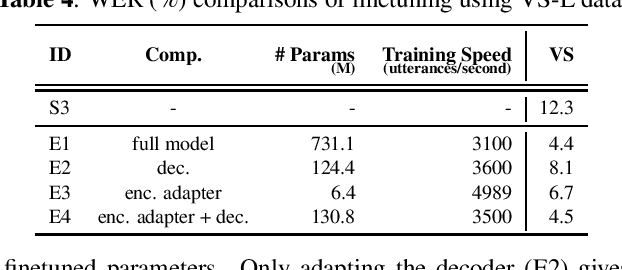
Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Fusing information streams in end-to-end audio-visual speech recognition
Apr 19, 2021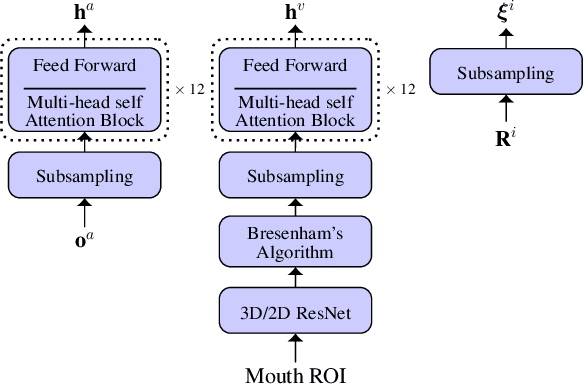
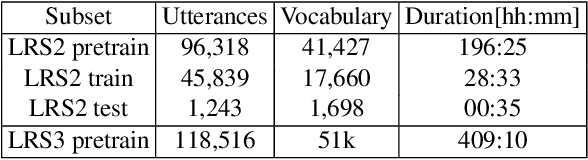
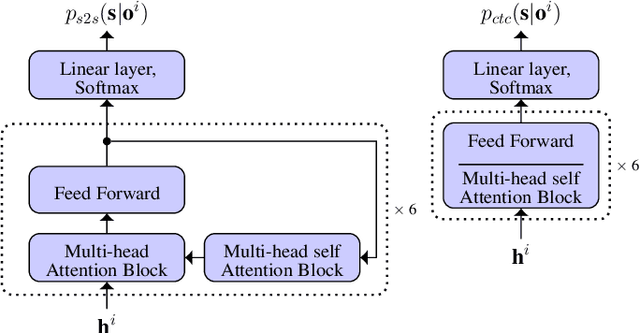
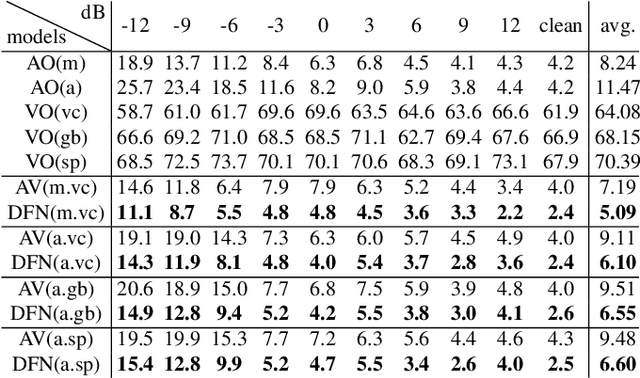
End-to-end acoustic speech recognition has quickly gained widespread popularity and shows promising results in many studies. Specifically the joint transformer/CTC model provides very good performance in many tasks. However, under noisy and distorted conditions, the performance still degrades notably. While audio-visual speech recognition can significantly improve the recognition rate of end-to-end models in such poor conditions, it is not obvious how to best utilize any available information on acoustic and visual signal quality and reliability in these models. We thus consider the question of how to optimally inform the transformer/CTC model of any time-variant reliability of the acoustic and visual information streams. We propose a new fusion strategy, incorporating reliability information in a decision fusion net that considers the temporal effects of the attention mechanism. This approach yields significant improvements compared to a state-of-the-art baseline model on the Lip Reading Sentences 2 and 3 (LRS2 and LRS3) corpus. On average, the new system achieves a relative word error rate reduction of 43% compared to the audio-only setup and 31% compared to the audiovisual end-to-end baseline.
* 5 pages