 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Record Deduplication for Entity Distribution Modeling in ASR Transcripts
Jun 09, 2023
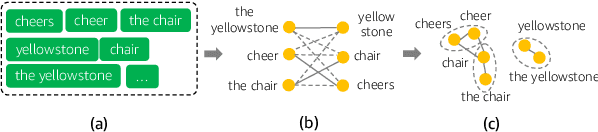
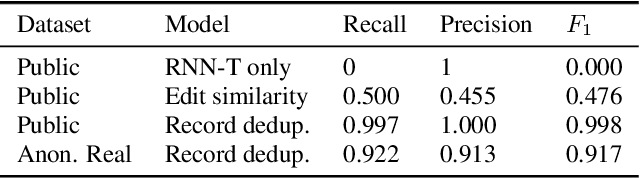
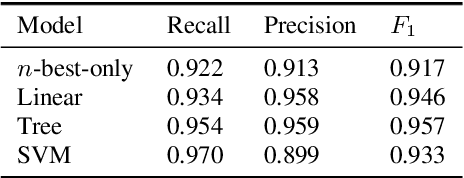

Voice digital assistants must keep up with trending search queries. We rely on a speech recognition model using contextual biasing with a rapidly updated set of entities, instead of frequent model retraining, to keep up with trends. There are several challenges with this approach: (1) the entity set must be frequently reconstructed, (2) the entity set is of limited size due to latency and accuracy trade-offs, and (3) finding the true entity distribution for biasing is complicated by ASR misrecognition. We address these challenges and define an entity set by modeling customers true requested entity distribution from ASR output in production using record deduplication, a technique from the field of entity resolution. Record deduplication resolves or deduplicates coreferences, including misrecognitions, of the same latent entity. Our method successfully retrieves 95% of misrecognized entities and when used for contextual biasing shows an estimated 5% relative word error rate reduction.
Alzheimer Disease Classification through ASR-based Transcriptions: Exploring the Impact of Punctuation and Pauses
Jun 06, 2023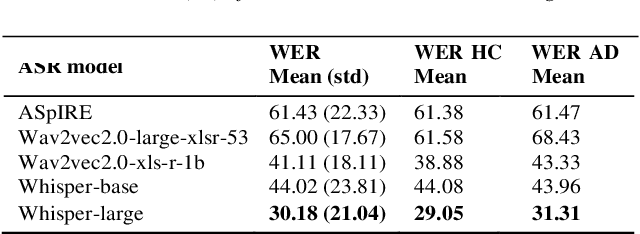
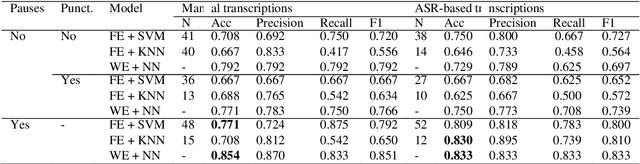
Alzheimer's Disease (AD) is the world's leading neurodegenerative disease, which often results in communication difficulties. Analysing speech can serve as a diagnostic tool for identifying the condition. The recent ADReSS challenge provided a dataset for AD classification and highlighted the utility of manual transcriptions. In this study, we used the new state-of-the-art Automatic Speech Recognition (ASR) model Whisper to obtain the transcriptions, which also include automatic punctuation. The classification models achieved test accuracy scores of 0.854 and 0.833 combining the pretrained FastText word embeddings and recurrent neural networks on manual and ASR transcripts respectively. Additionally, we explored the influence of including pause information and punctuation in the transcriptions. We found that punctuation only yielded minor improvements in some cases, whereas pause encoding aided AD classification for both manual and ASR transcriptions across all approaches investigated.
Automatic Speech Recognition of Low-Resource Languages Based on Chukchi
Oct 11, 2022
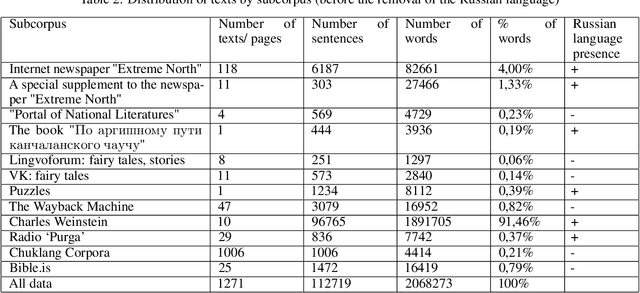
The following paper presents a project focused on the research and creation of a new Automatic Speech Recognition (ASR) based in the Chukchi language. There is no one complete corpus of the Chukchi language, so most of the work consisted in collecting audio and texts in the Chukchi language from open sources and processing them. We managed to collect 21:34:23 hours of audio recordings and 112,719 sentences (or 2,068,273 words) of text in the Chukchi language. The XLSR model was trained on the obtained data, which showed good results even with a small amount of data. Besides the fact that the Chukchi language is a low-resource language, it is also polysynthetic, which significantly complicates any automatic processing. Thus, the usual WER metric for evaluating ASR becomes less indicative for a polysynthetic language. However, the CER metric showed good results. The question of metrics for polysynthetic languages remains open.
RASR2: The RWTH ASR Toolkit for Generic Sequence-to-sequence Speech Recognition
May 28, 2023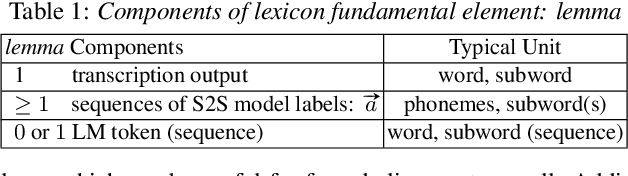
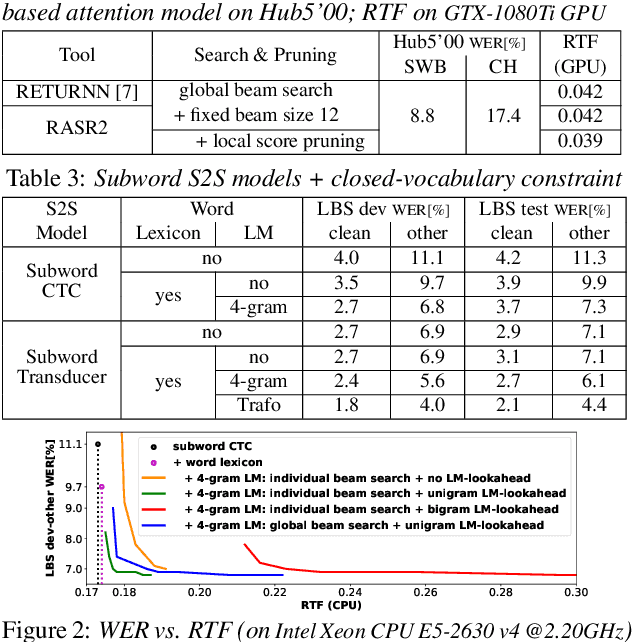
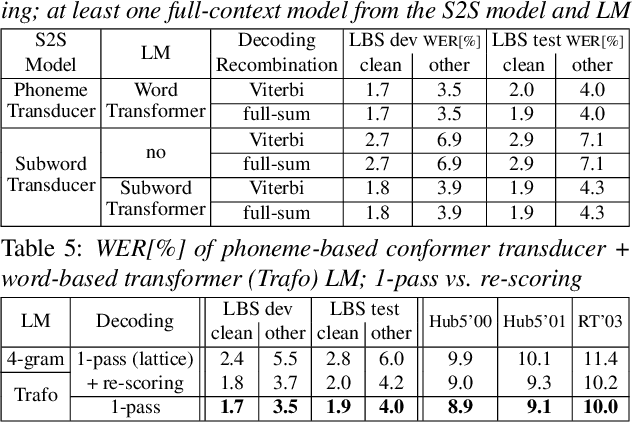
Modern public ASR tools usually provide rich support for training various sequence-to-sequence (S2S) models, but rather simple support for decoding open-vocabulary scenarios only. For closed-vocabulary scenarios, public tools supporting lexical-constrained decoding are usually only for classical ASR, or do not support all S2S models. To eliminate this restriction on research possibilities such as modeling unit choice, we present RASR2 in this work, a research-oriented generic S2S decoder implemented in C++. It offers a strong flexibility/compatibility for various S2S models, language models, label units/topologies and neural network architectures. It provides efficient decoding for both open- and closed-vocabulary scenarios based on a generalized search framework with rich support for different search modes and settings. We evaluate RASR2 with a wide range of experiments on both switchboard and Librispeech corpora. Our source code is public online.
A Highly Adaptive Acoustic Model for Accurate Multi-Dialect Speech Recognition
May 06, 2022
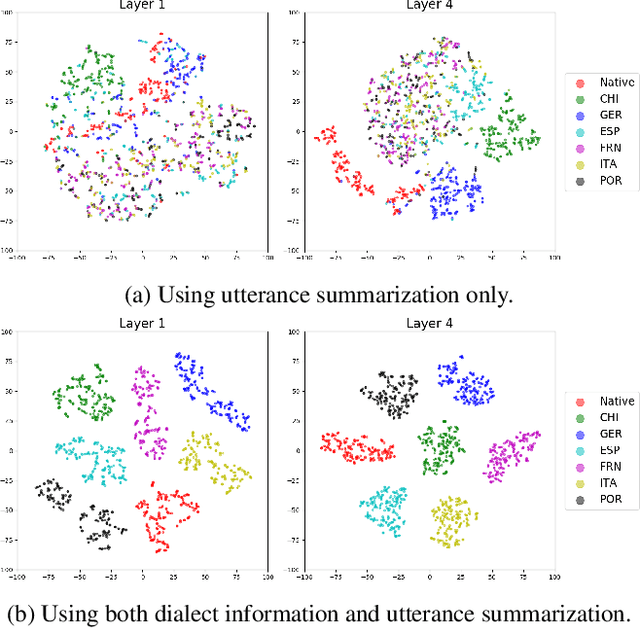
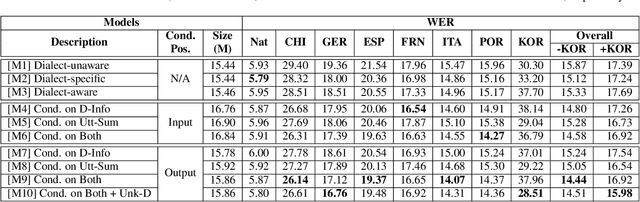
Despite the success of deep learning in speech recognition, multi-dialect speech recognition remains a difficult problem. Although dialect-specific acoustic models are known to perform well in general, they are not easy to maintain when dialect-specific data is scarce and the number of dialects for each language is large. Therefore, a single unified acoustic model (AM) that generalizes well for many dialects has been in demand. In this paper, we propose a novel acoustic modeling technique for accurate multi-dialect speech recognition with a single AM. Our proposed AM is dynamically adapted based on both dialect information and its internal representation, which results in a highly adaptive AM for handling multiple dialects simultaneously. We also propose a simple but effective training method to deal with unseen dialects. The experimental results on large scale speech datasets show that the proposed AM outperforms all the previous ones, reducing word error rates (WERs) by 8.11% relative compared to a single all-dialects AM and by 7.31% relative compared to dialect-specific AMs.
AfriNames: Most ASR models "butcher" African Names
Jun 02, 2023
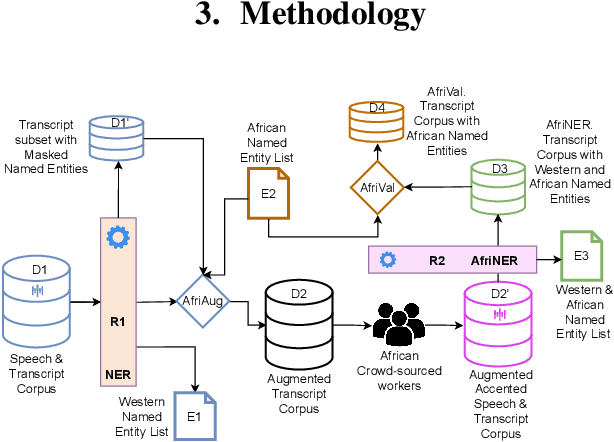
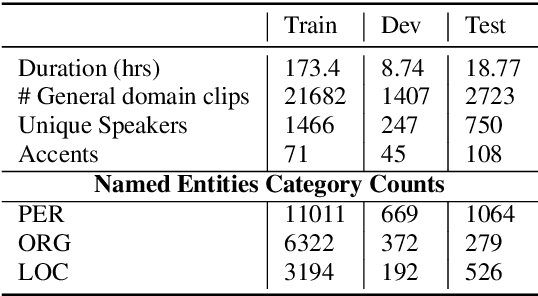
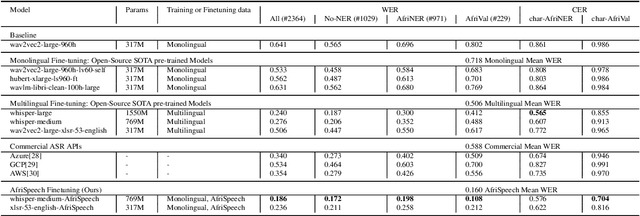
Useful conversational agents must accurately capture named entities to minimize error for downstream tasks, for example, asking a voice assistant to play a track from a certain artist, initiating navigation to a specific location, or documenting a laboratory result for a patient. However, where named entities such as ``Ukachukwu`` (Igbo), ``Lakicia`` (Swahili), or ``Ingabire`` (Rwandan) are spoken, automatic speech recognition (ASR) models' performance degrades significantly, propagating errors to downstream systems. We model this problem as a distribution shift and demonstrate that such model bias can be mitigated through multilingual pre-training, intelligent data augmentation strategies to increase the representation of African-named entities, and fine-tuning multilingual ASR models on multiple African accents. The resulting fine-tuned models show an 81.5\% relative WER improvement compared with the baseline on samples with African-named entities.
Adaptive Activation Network For Low Resource Multilingual Speech Recognition
May 28, 2022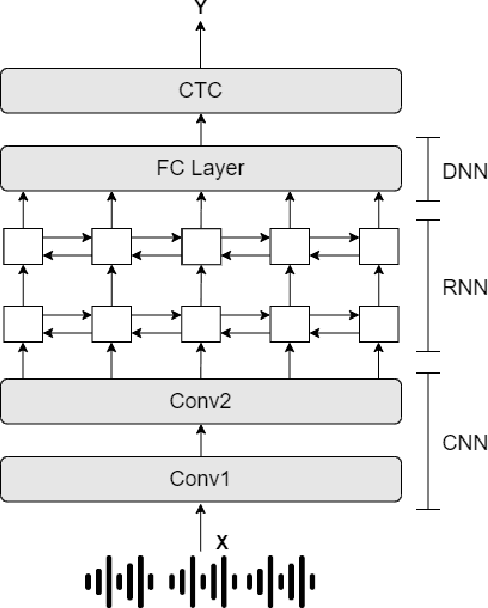
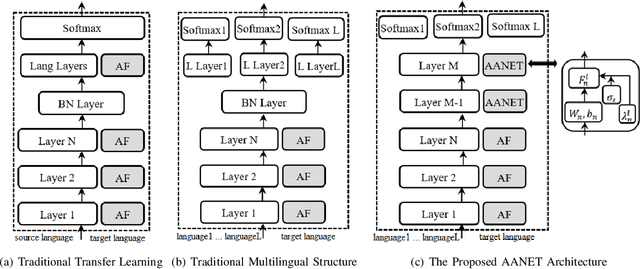
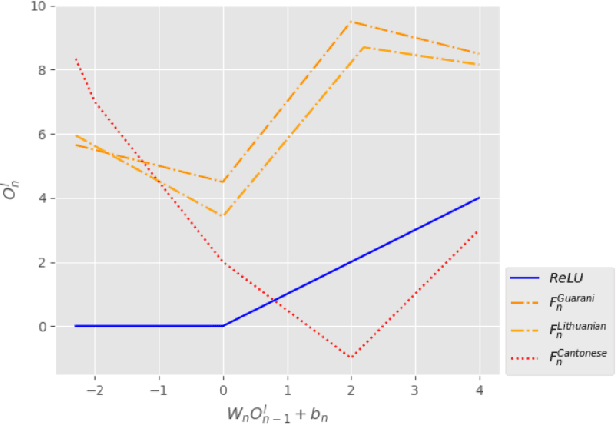
Low resource automatic speech recognition (ASR) is a useful but thorny task, since deep learning ASR models usually need huge amounts of training data. The existing models mostly established a bottleneck (BN) layer by pre-training on a large source language, and transferring to the low resource target language. In this work, we introduced an adaptive activation network to the upper layers of ASR model, and applied different activation functions to different languages. We also proposed two approaches to train the model: (1) cross-lingual learning, replacing the activation function from source language to target language, (2) multilingual learning, jointly training the Connectionist Temporal Classification (CTC) loss of each language and the relevance of different languages. Our experiments on IARPA Babel datasets demonstrated that our approaches outperform the from-scratch training and traditional bottleneck feature based methods. In addition, combining the cross-lingual learning and multilingual learning together could further improve the performance of multilingual speech recognition.
Huqariq: A Multilingual Speech Corpus of Native Languages of Peru for Speech Recognition
Jul 12, 2022
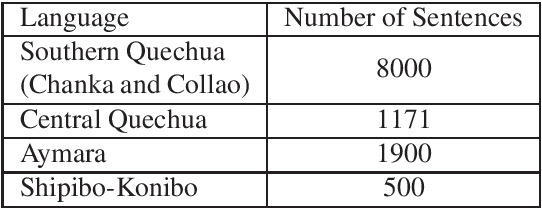
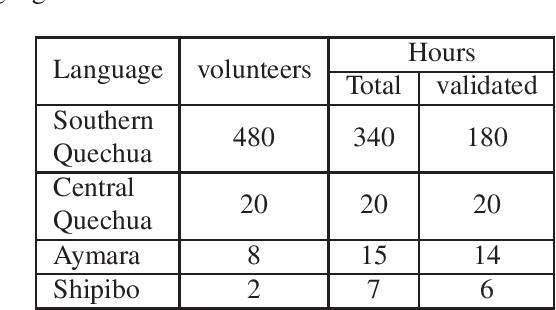
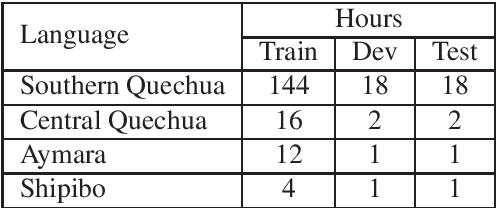
The Huqariq corpus is a multilingual collection of speech from native Peruvian languages. The transcribed corpus is intended for the research and development of speech technologies to preserve endangered languages in Peru. Huqariq is primarily designed for the development of automatic speech recognition, language identification and text-to-speech tools. In order to achieve corpus collection sustainably, we employ the crowdsourcing methodology. Huqariq includes four native languages of Peru, and it is expected that by the end of the year 2022, it can reach up to 20 native languages out of the 48 native languages in Peru. The corpus has 220 hours of transcribed audio recorded by more than 500 volunteers, making it the largest speech corpus for native languages in Peru. In order to verify the quality of the corpus, we present speech recognition experiments using 220 hours of fully transcribed audio.
Noise-robust Speech Recognition with 10 Minutes Unparalleled In-domain Data
Mar 29, 2022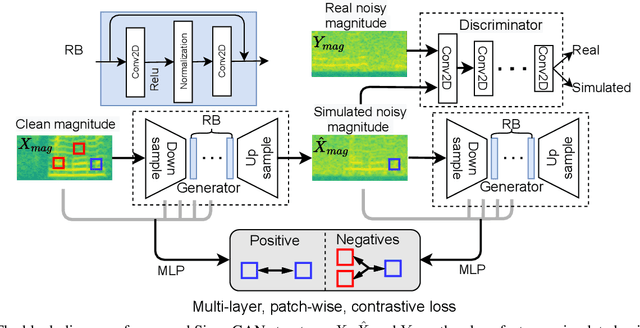
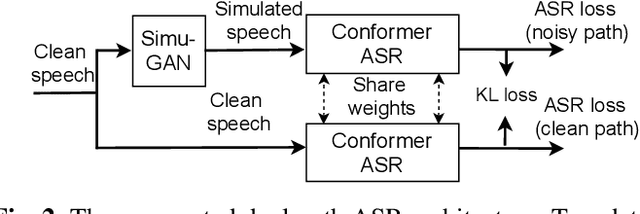
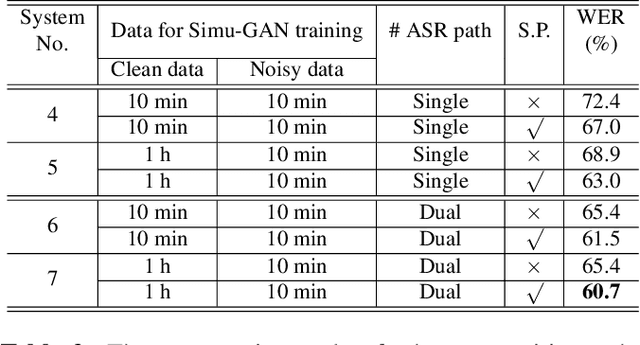
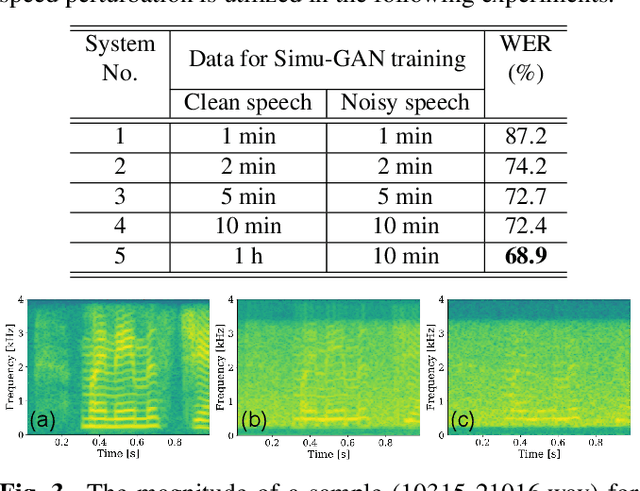
Noise-robust speech recognition systems require large amounts of training data including noisy speech data and corresponding transcripts to achieve state-of-the-art performances in face of various practical environments. However, such plenty of in-domain data is not always available in the real-life world. In this paper, we propose a generative adversarial network to simulate noisy spectrum from the clean spectrum (Simu-GAN), where only 10 minutes of unparalleled in-domain noisy speech data is required as labels. Furthermore, we also propose a dual-path speech recognition system to improve the robustness of the system under noisy conditions. Experimental results show that the proposed speech recognition system achieves 7.3% absolute improvement with simulated noisy data by Simu-GAN over the best baseline in terms of word error rate (WER).
Adversarial Training For Low-Resource Disfluency Correction
Jun 10, 2023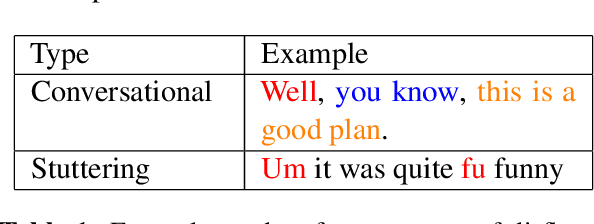
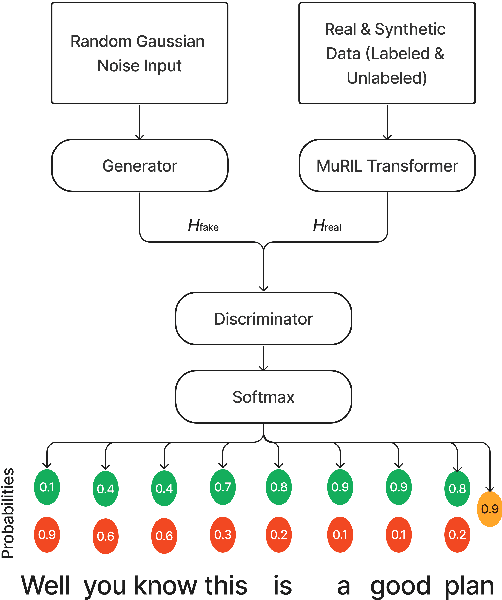
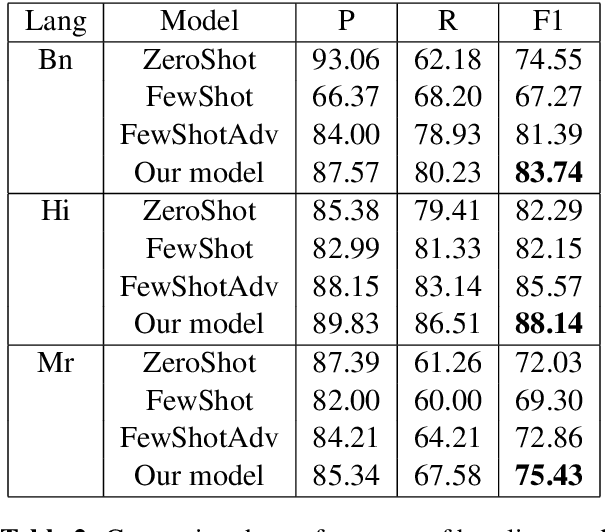
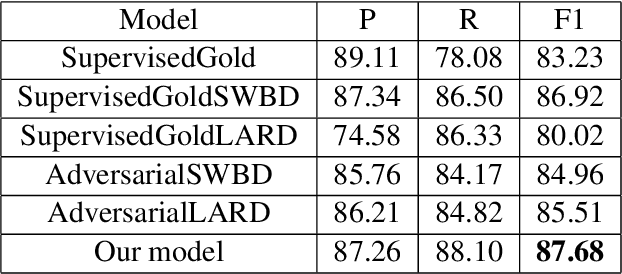
Disfluencies commonly occur in conversational speech. Speech with disfluencies can result in noisy Automatic Speech Recognition (ASR) transcripts, which affects downstream tasks like machine translation. In this paper, we propose an adversarially-trained sequence-tagging model for Disfluency Correction (DC) that utilizes a small amount of labeled real disfluent data in conjunction with a large amount of unlabeled data. We show the benefit of our proposed technique, which crucially depends on synthetically generated disfluent data, by evaluating it for DC in three Indian languages- Bengali, Hindi, and Marathi (all from the Indo-Aryan family). Our technique also performs well in removing stuttering disfluencies in ASR transcripts introduced by speech impairments. We achieve an average 6.15 points improvement in F1-score over competitive baselines across all three languages mentioned. To the best of our knowledge, we are the first to utilize adversarial training for DC and use it to correct stuttering disfluencies in English, establishing a new benchmark for this task.