 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021
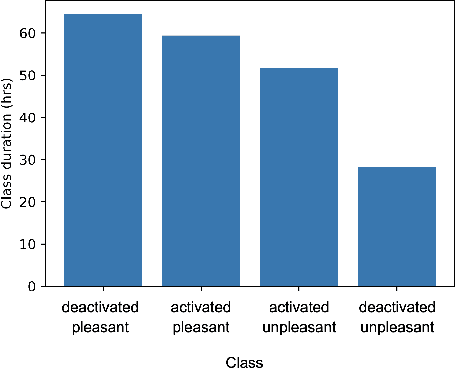
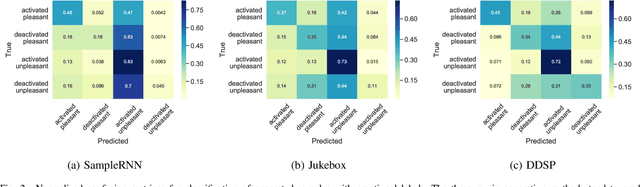
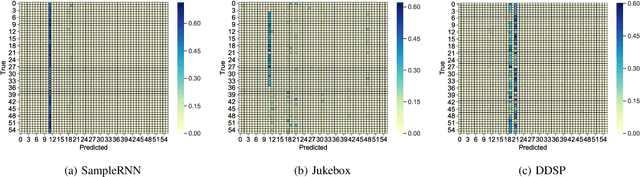
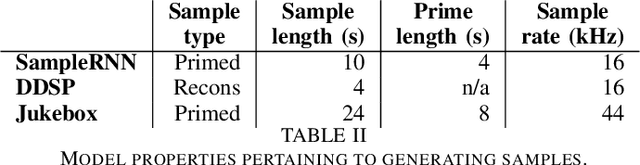
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
Scream Detection in Heavy Metal Music
May 11, 2022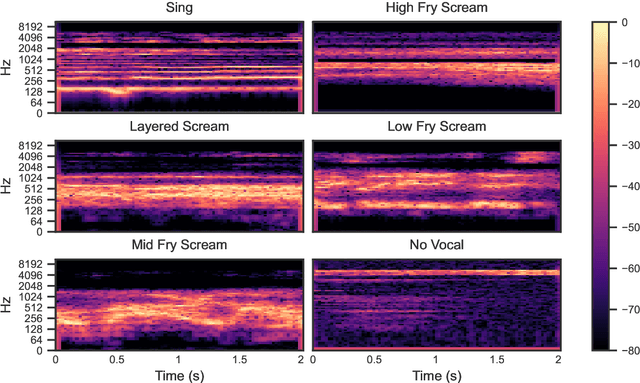
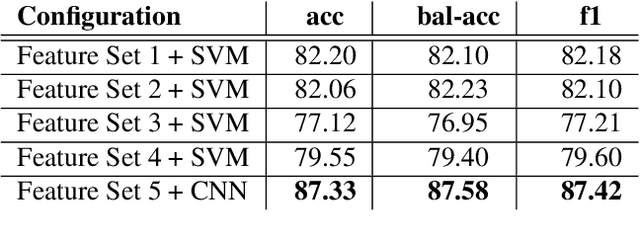
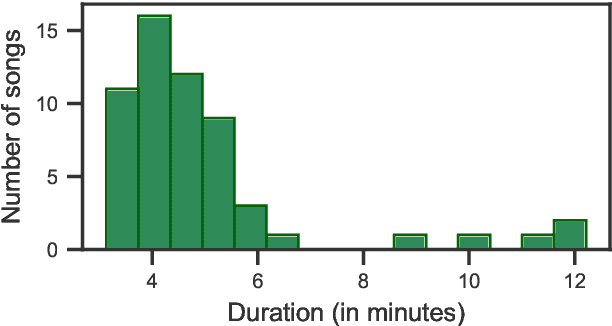
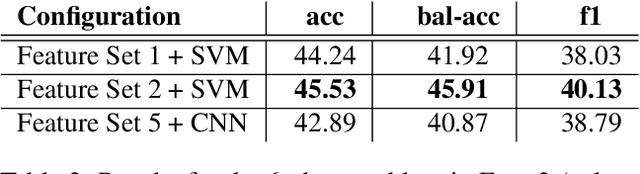
Harsh vocal effects such as screams or growls are far more common in heavy metal vocals than the traditionally sung vocal. This paper explores the problem of detection and classification of extreme vocal techniques in heavy metal music, specifically the identification of different scream techniques. We investigate the suitability of various feature representations, including cepstral, spectral, and temporal features as input representations for classification. The main contributions of this work are (i) a manually annotated dataset comprised of over 280 minutes of heavy metal songs of various genres with a statistical analysis of occurrences of different extreme vocal techniques in heavy metal music, and (ii) a systematic study of different input feature representations for the classification of heavy metal vocals
Genre-conditioned Acoustic Models for Automatic Lyrics Transcription of Polyphonic Music
Apr 07, 2022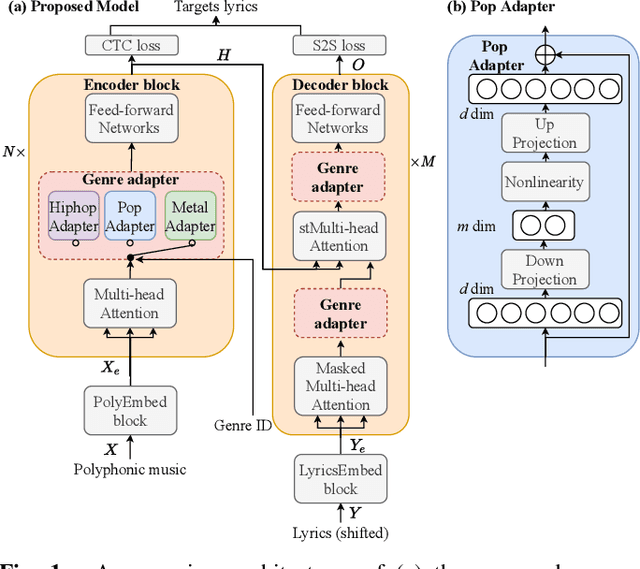
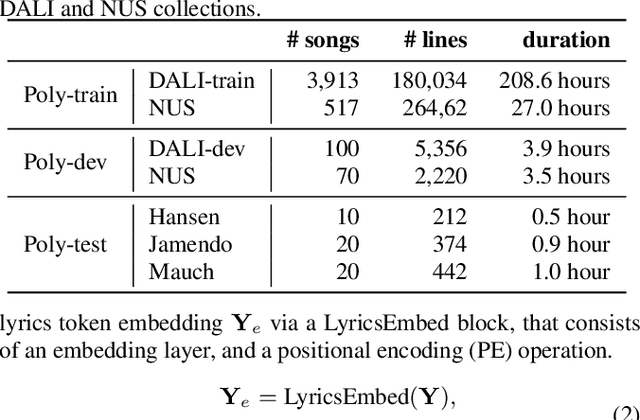
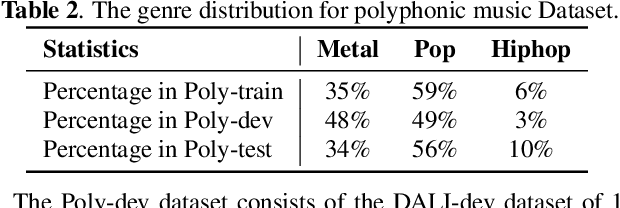
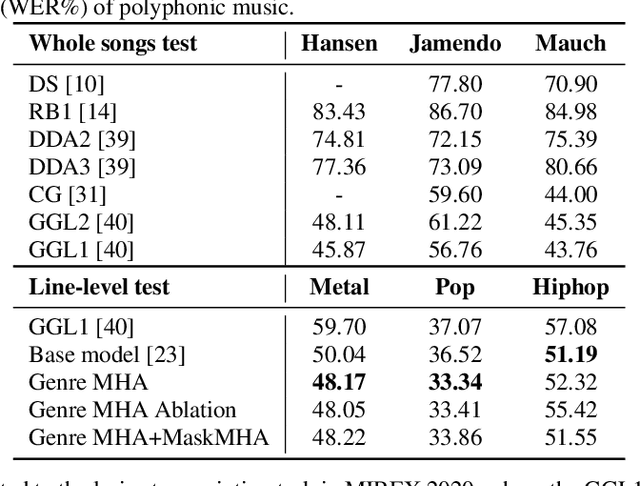
Lyrics transcription of polyphonic music is challenging not only because the singing vocals are corrupted by the background music, but also because the background music and the singing style vary across music genres, such as pop, metal, and hip hop, which affects lyrics intelligibility of the song in different ways. In this work, we propose to transcribe the lyrics of polyphonic music using a novel genre-conditioned network. The proposed network adopts pre-trained model parameters, and incorporates the genre adapters between layers to capture different genre peculiarities for lyrics-genre pairs, thereby only requiring lightweight genre-specific parameters for training. Our experiments show that the proposed genre-conditioned network outperforms the existing lyrics transcription systems.
Self-Supervised Pretraining on Paired Sequences of fMRI Data for Transfer Learning to Brain Decoding Tasks
May 15, 2023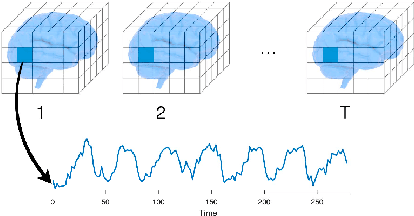
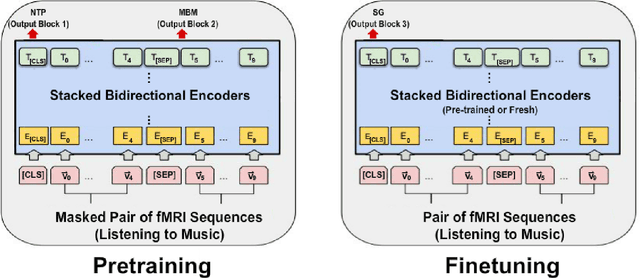

In this work we introduce a self-supervised pretraining framework for transformers on functional Magnetic Resonance Imaging (fMRI) data. First, we pretrain our architecture on two self-supervised tasks simultaneously to teach the model a general understanding of the temporal and spatial dynamics of human auditory cortex during music listening. Our pretraining results are the first to suggest a synergistic effect of multitask training on fMRI data. Second, we finetune the pretrained models and train additional fresh models on a supervised fMRI classification task. We observe significantly improved accuracy on held-out runs with the finetuned models, which demonstrates the ability of our pretraining tasks to facilitate transfer learning. This work contributes to the growing body of literature on transformer architectures for pretraining and transfer learning with fMRI data, and serves as a proof of concept for our pretraining tasks and multitask pretraining on fMRI data.
Tollywood Emotions: Annotation of Valence-Arousal in Telugu Song Lyrics
Mar 16, 2023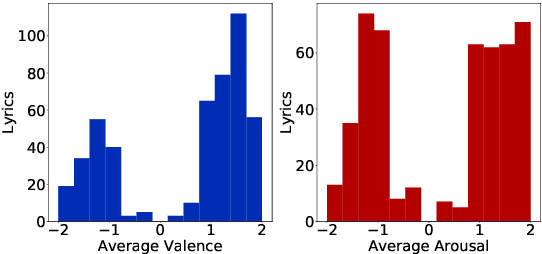
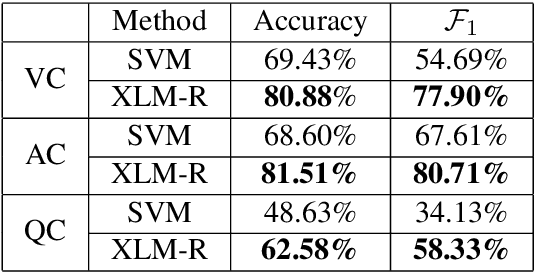
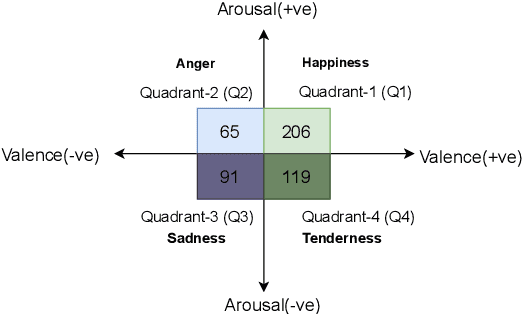
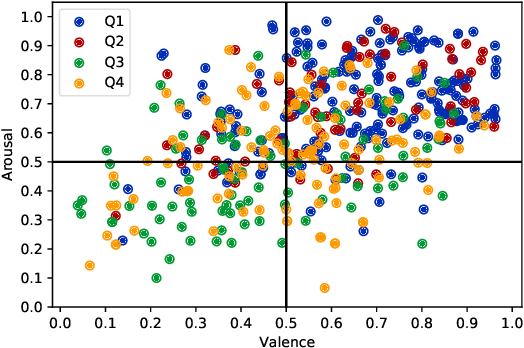
Emotion recognition from a given music track has heavily relied on acoustic features, social tags, and metadata but is seldom focused on lyrics. There are no datasets of Indian language songs that contain both valence and arousal manual ratings of lyrics. We present a new manually annotated dataset of Telugu songs' lyrics collected from Spotify with valence and arousal annotated on a discrete scale. A fairly high inter-annotator agreement was observed for both valence and arousal. Subsequently, we create two music emotion recognition models by using two classification techniques to identify valence, arousal and respective emotion quadrant from lyrics. Support vector machine (SVM) with term frequency-inverse document frequency (TF-IDF) features and fine-tuning the pre-trained XLMRoBERTa (XLM-R) model were used for valence, arousal and quadrant classification tasks. Fine-tuned XLMRoBERTa performs better than the SVM by improving macro-averaged F1-scores of 54.69%, 67.61%, 34.13% to 77.90%, 80.71% and 58.33% for valence, arousal and quadrant classifications, respectively, on 10-fold cross-validation. In addition, we compare our lyrics annotations with Spotify's annotations of valence and energy (same as arousal), which are based on entire music tracks. The implications of our findings are discussed. Finally, we make the dataset publicly available with lyrics, annotations and Spotify IDs.
Improving Recommendation Systems with User Personality Inferred from Product Reviews
Mar 21, 2023


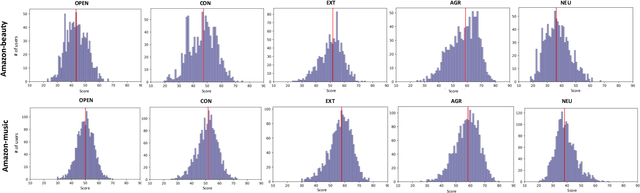
Personality is a psychological factor that reflects people's preferences, which in turn influences their decision-making. We hypothesize that accurate modeling of users' personalities improves recommendation systems' performance. However, acquiring such personality profiles is both sensitive and expensive. We address this problem by introducing a novel method to automatically extract personality profiles from public product review text. We then design and assess three context-aware recommendation architectures that leverage the profiles to test our hypothesis. Experiments on our two newly contributed personality datasets -- Amazon-beauty and Amazon-music -- validate our hypothesis, showing performance boosts of 3--28%.Our analysis uncovers that varying personality types contribute differently to recommendation performance: open and extroverted personalities are most helpful in music recommendation, while a conscientious personality is most helpful in beauty product recommendation.
E-PANNs: Sound Recognition Using Efficient Pre-trained Audio Neural Networks
May 30, 2023

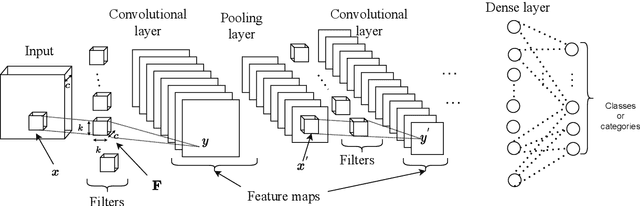
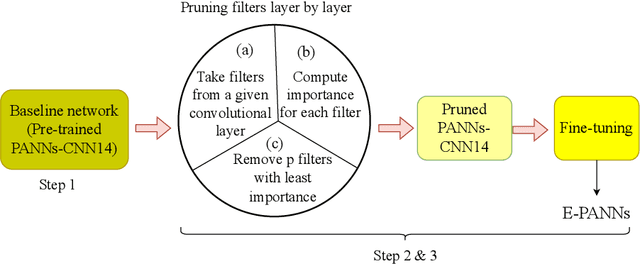
Sounds carry an abundance of information about activities and events in our everyday environment, such as traffic noise, road works, music, or people talking. Recent machine learning methods, such as convolutional neural networks (CNNs), have been shown to be able to automatically recognize sound activities, a task known as audio tagging. One such method, pre-trained audio neural networks (PANNs), provides a neural network which has been pre-trained on over 500 sound classes from the publicly available AudioSet dataset, and can be used as a baseline or starting point for other tasks. However, the existing PANNs model has a high computational complexity and large storage requirement. This could limit the potential for deploying PANNs on resource-constrained devices, such as on-the-edge sound sensors, and could lead to high energy consumption if many such devices were deployed. In this paper, we reduce the computational complexity and memory requirement of the PANNs model by taking a pruning approach to eliminate redundant parameters from the PANNs model. The resulting Efficient PANNs (E-PANNs) model, which requires 36\% less computations and 70\% less memory, also slightly improves the sound recognition (audio tagging) performance. The code for the E-PANNs model has been released under an open source license.
Music Interpretation Analysis. A Multimodal Approach To Score-Informed Resynthesis of Piano Recordings
May 02, 2022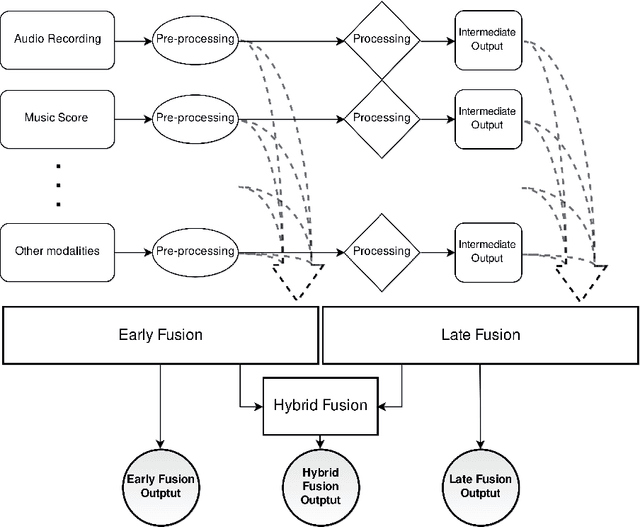
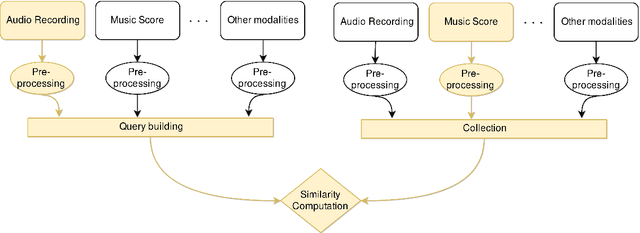
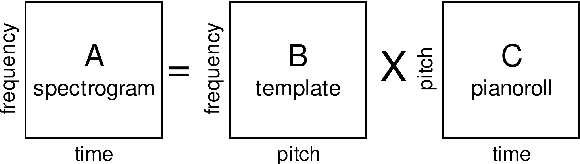
This Thesis discusses the development of technologies for the automatic resynthesis of music recordings using digital synthesizers. First, the main issue is identified in the understanding of how Music Information Processing (MIP) methods can take into consideration the influence of the acoustic context on the music performance. For this, a novel conceptual and mathematical framework named "Music Interpretation Analysis" (MIA) is presented. In the proposed framework, a distinction is made between the "performance" - the physical action of playing - and the "interpretation" - the action that the performer wishes to achieve. Second, the Thesis describes further works aiming at the democratization of music production tools via automatic resynthesis: 1) it elaborates software and file formats for historical music archiving and multimodal machine-learning datasets; 2) it explores and extends MIP technologies; 3) it presents the mathematical foundations of the MIA framework and shows preliminary evaluations to demonstrate the effectiveness of the approach
Cadence Detection in Symbolic Classical Music using Graph Neural Networks
Aug 31, 2022

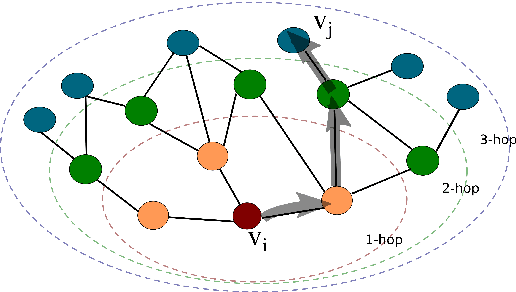
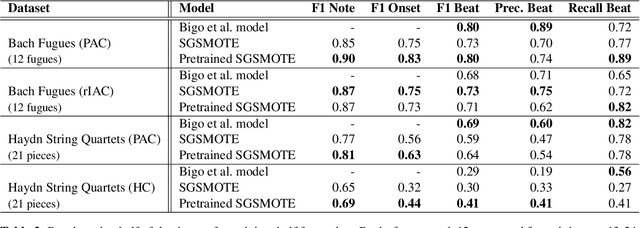
Cadences are complex structures that have been driving music from the beginning of contrapuntal polyphony until today. Detecting such structures is vital for numerous MIR tasks such as musicological analysis, key detection, or music segmentation. However, automatic cadence detection remains challenging mainly because it involves a combination of high-level musical elements like harmony, voice leading, and rhythm. In this work, we present a graph representation of symbolic scores as an intermediate means to solve the cadence detection task. We approach cadence detection as an imbalanced node classification problem using a Graph Convolutional Network. We obtain results that are roughly on par with the state of the art, and we present a model capable of making predictions at multiple levels of granularity, from individual notes to beats, thanks to the fine-grained, note-by-note representation. Moreover, our experiments suggest that graph convolution can learn non-local features that assist in cadence detection, freeing us from the need of having to devise specialized features that encode non-local context. We argue that this general approach to modeling musical scores and classification tasks has a number of potential advantages, beyond the specific recognition task presented here.
Ripple Knowledge Graph Convolutional Networks For Recommendation Systems
May 02, 2023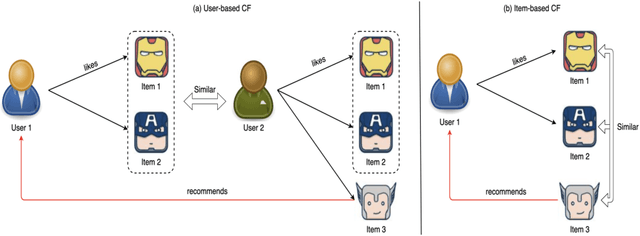

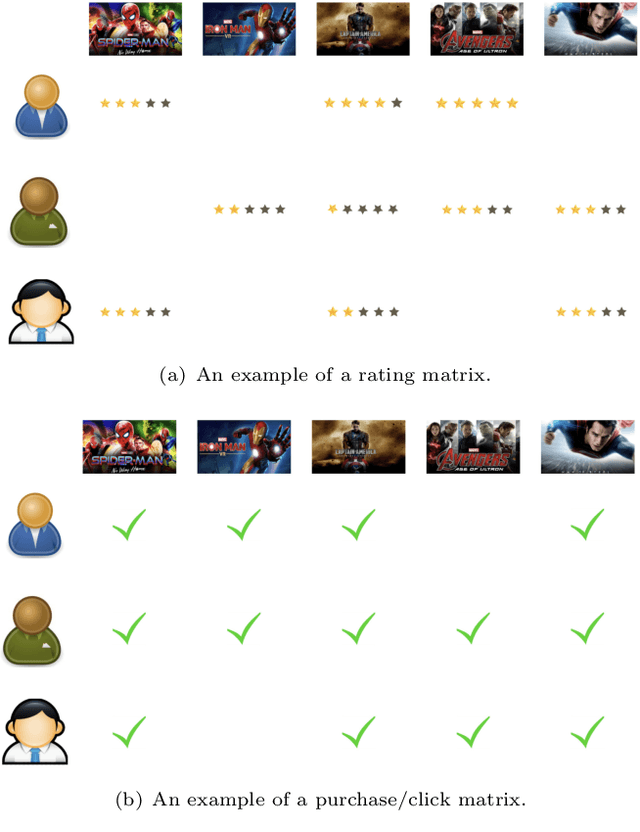
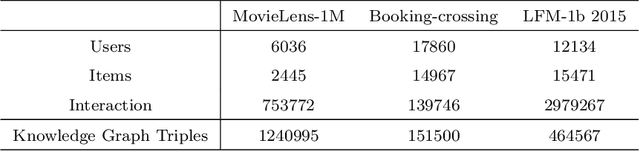
Using knowledge graphs to assist deep learning models in making recommendation decisions has recently been proven to effectively improve the model's interpretability and accuracy. This paper introduces an end-to-end deep learning model, named RKGCN, which dynamically analyses each user's preferences and makes a recommendation of suitable items. It combines knowledge graphs on both the item side and user side to enrich their representations to maximize the utilization of the abundant information in knowledge graphs. RKGCN is able to offer more personalized and relevant recommendations in three different scenarios. The experimental results show the superior effectiveness of our model over 5 baseline models on three real-world datasets including movies, books, and music.