 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Sentiment Transfer
Oct 12, 2021
Music sentiment transfer is a completely novel task. Sentiment transfer is a natural evolution of the heavily-studied style transfer task, as sentiment transfer is rooted in applying the sentiment of a source to be the new sentiment for a target piece of media; yet compared to style transfer, sentiment transfer has been only scantily studied on images. Music sentiment transfer attempts to apply the high level objective of sentiment transfer to the domain of music. We propose CycleGAN to bridge disparate domains. In order to use the network, we choose to use symbolic, MIDI, data as the music format. Through the use of a cycle consistency loss, we are able to create one-to-one mappings that preserve the content and realism of the source data. Results and literature suggest that the task of music sentiment transfer is more difficult than image sentiment transfer because of the temporal characteristics of music and lack of existing datasets.
Musical creativity enabled by nonlinear oscillations of a bubble in water
Apr 03, 2023
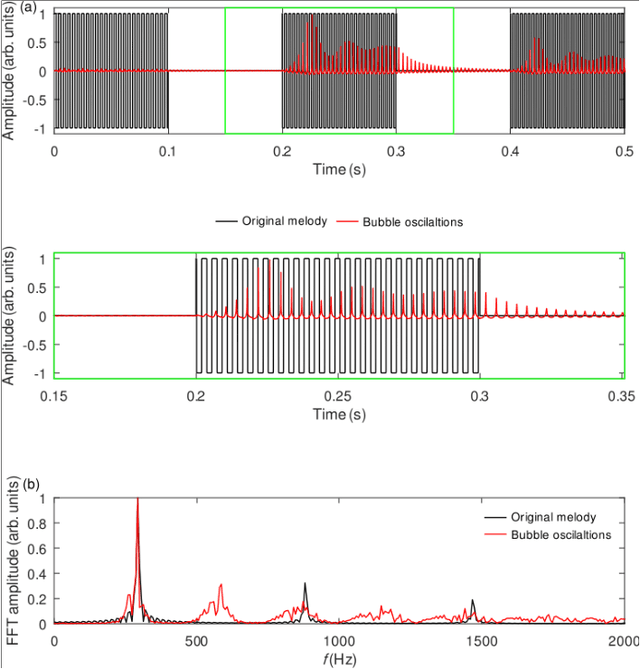
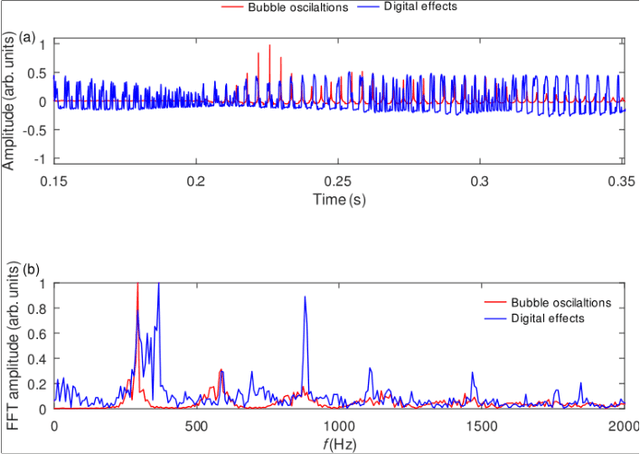
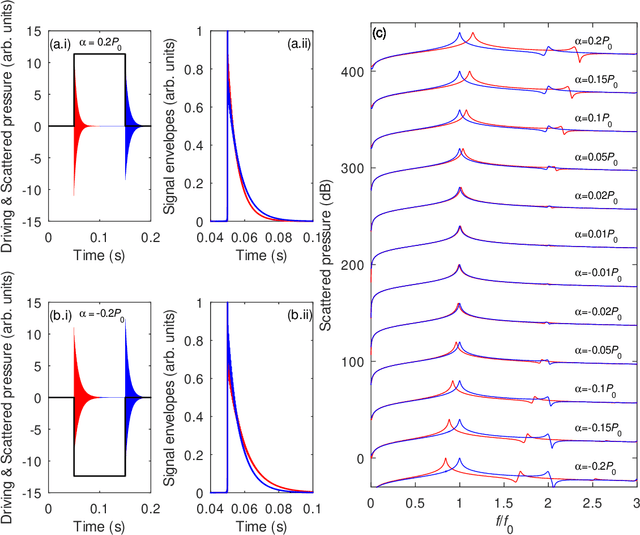
Producing original and arranging existing musical outcomes is an art that takes years of learning and practice to master. Yet, despite the constant advances in the field of AI-powered musical creativity, production of quality musical outcomes remains a prerogative of the humans. Here we demonstrate that a single bubble in water can be used to produce creative musical outcomes, when it nonlinearly oscillates under an acoustic pressure signal that encodes a piece of classical music. The audio signal of the response of the bubble resembles an electric guitar version of the original composition. We suggest, and provide plausible theoretical supporting arguments, that this property of the bubble can be used to create physics-inspired AI systems capable of simulating human creativity in arrangement and composition of music.
PoLyScribers: Joint Training of Vocal Extractor and Lyrics Transcriber for Polyphonic Music
Jul 15, 2022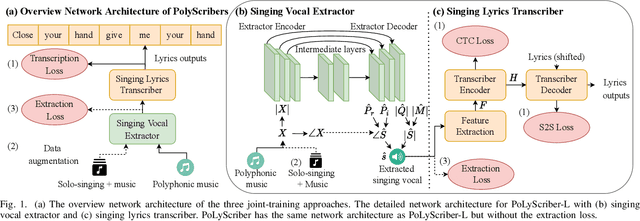
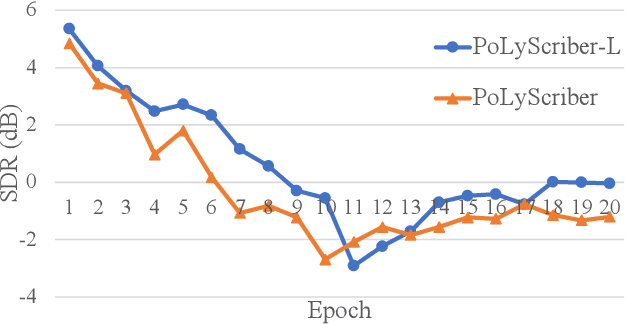
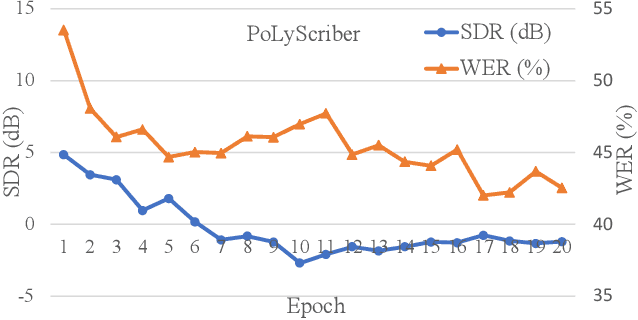
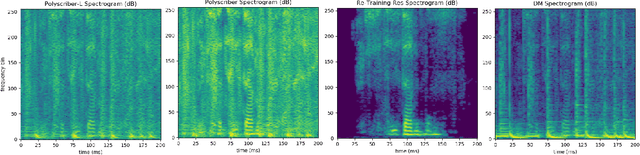
Lyrics transcription of polyphonic music is challenging as the background music affects lyrics intelligibility. Typically, lyrics transcription can be performed by a two step pipeline, i.e. singing vocal extraction frontend, followed by a lyrics transcriber decoder backend, where the frontend and backend are trained separately. Such a two step pipeline suffers from both imperfect vocal extraction and mismatch between frontend and backend. In this work, we propose novel end-to-end joint-training framework, that we call PoLyScribers, to jointly optimize the vocal extractor front-end and lyrics transcriber backend for lyrics transcription in polyphonic music. The experimental results show that our proposed joint-training model achieves substantial improvements over the existing approaches on publicly available test datasets.
A Non-iterative Spatio-temporal Multi-task Assignments based Collision-free Trajectories for Music Playing Robots
Oct 14, 2022



In this paper, a non-iterative spatio-temporal multi-task assignment approach is used for playing the piano music by a team of robots. This paper considers the piano playing problem, in which an algorithm needs to compute the trajectories for a dynamically sized team of robots who will play the musical notes by traveling through the specific locations associated with musical notes at their respective specific times. A two-step dynamic resource allocation based on a spatio-temporal multi-task assignment problem (DREAM), has been implemented to assign robots for playing the musical tune. The algorithm computes the required number of robots to play the music in the first step. In the second step, optimal assignments are computed for the updated team of robots, which minimizes the total distance traveled by the team. Furthermore, if robots are operating in Euclidean space, then the solution of DREAM approach provides collision-free trajectories, and the same has been proven. The working of DREAM approach has been illustrated with the help of the high fidelity simulations in Gazebo operated using ROS2. The result clearly shows that the DREAM approach computes the required number of robots and assigns multiple tasks to robots in at most two step. The simulation of the robots playing music, using computed assignments, is demonstrated in the attached video. video link: \url{https://youtu.be/XToicNm-CO8}
Contrastive Learning with Positive-Negative Frame Mask for Music Representation
Apr 03, 2022
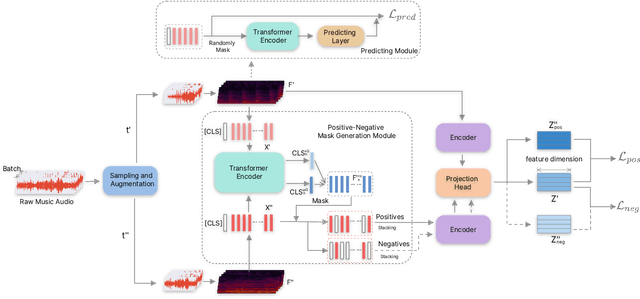
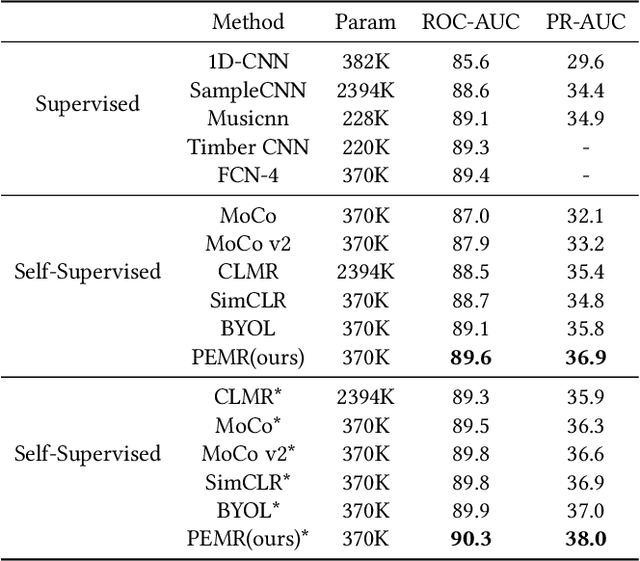
Self-supervised learning, especially contrastive learning, has made an outstanding contribution to the development of many deep learning research fields. Recently, researchers in the acoustic signal processing field noticed its success and leveraged contrastive learning for better music representation. Typically, existing approaches maximize the similarity between two distorted audio segments sampled from the same music. In other words, they ensure a semantic agreement at the music level. However, those coarse-grained methods neglect some inessential or noisy elements at the frame level, which may be detrimental to the model to learn the effective representation of music. Towards this end, this paper proposes a novel Positive-nEgative frame mask for Music Representation based on the contrastive learning framework, abbreviated as PEMR. Concretely, PEMR incorporates a Positive-Negative Mask Generation module, which leverages transformer blocks to generate frame masks on the Log-Mel spectrogram. We can generate self-augmented negative and positive samples by masking important components or inessential components, respectively. We devise a novel contrastive learning objective to accommodate both self-augmented positives/negatives sampled from the same music. We conduct experiments on four public datasets. The experimental results of two music-related downstream tasks, music classification, and cover song identification, demonstrate the generalization ability and transferability of music representation learned by PEMR.
Music Generation Using an LSTM
Mar 23, 2022Over the past several years, deep learning for sequence modeling has grown in popularity. To achieve this goal, LSTM network structures have proven to be very useful for making predictions for the next output in a series. For instance, a smartphone predicting the next word of a text message could use an LSTM. We sought to demonstrate an approach of music generation using Recurrent Neural Networks (RNN). More specifically, a Long Short-Term Memory (LSTM) neural network. Generating music is a notoriously complicated task, whether handmade or generated, as there are a myriad of components involved. Taking this into account, we provide a brief synopsis of the intuition, theory, and application of LSTMs in music generation, develop and present the network we found to best achieve this goal, identify and address issues and challenges faced, and include potential future improvements for our network.
Pitch Estimation by Denoising Preprocessor and Hybrid Estimation Model
May 06, 2023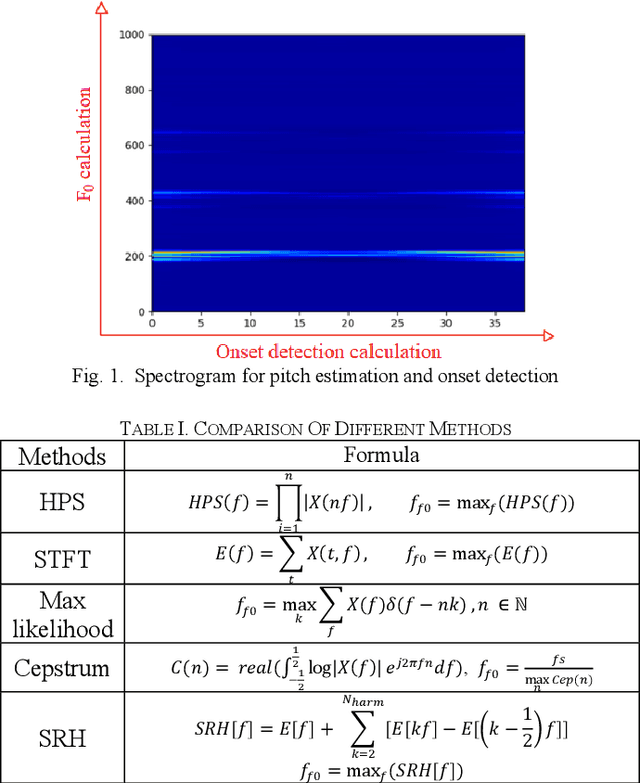
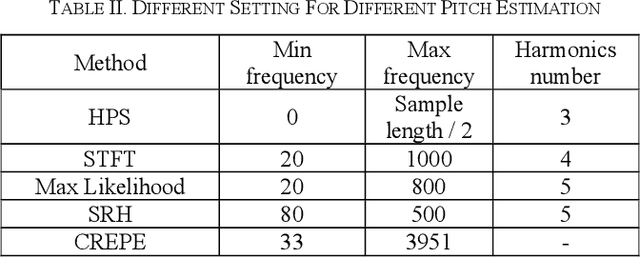
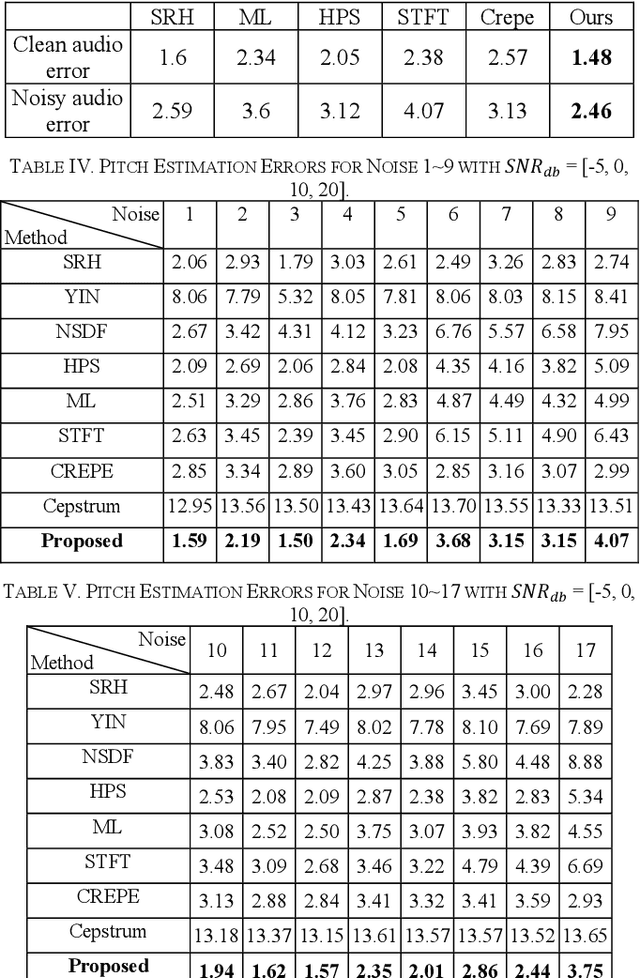
Pitch estimation is to estimate the fundamental frequency and the midi number and plays a critical role in music signal analysis and vocal signal processing. In this work, we proposed a new architecture based on a learning-based enhancement preprocessor and a combination of several traditional and deep learning pitch estimation methods to achieve better pitch estimation performance in both noisy and clean scenarios. We test 17 different types of noise and 4 SNRdb noise levels. The results show that the proposed pitch estimation can perform better in both noisy and clean scenarios with short response time.
It's Time for Artistic Correspondence in Music and Video
Jun 14, 2022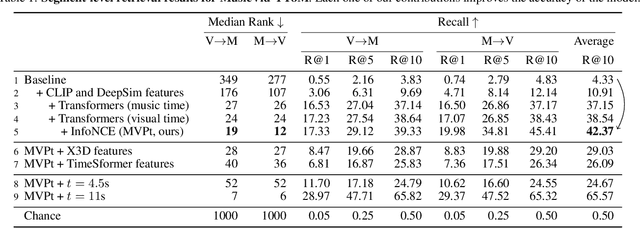
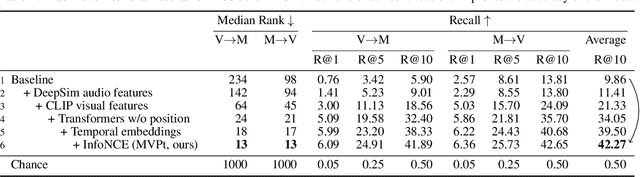
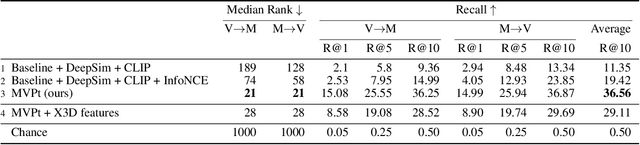
We present an approach for recommending a music track for a given video, and vice versa, based on both their temporal alignment and their correspondence at an artistic level. We propose a self-supervised approach that learns this correspondence directly from data, without any need of human annotations. In order to capture the high-level concepts that are required to solve the task, we propose modeling the long-term temporal context of both the video and the music signals, using Transformer networks for each modality. Experiments show that this approach strongly outperforms alternatives that do not exploit the temporal context. The combination of our contributions improve retrieval accuracy up to 10x over prior state of the art. This strong improvement allows us to introduce a wide range of analyses and applications. For instance, we can condition music retrieval based on visually defined attributes.
Late multimodal fusion for image and audio music transcription
Apr 06, 2022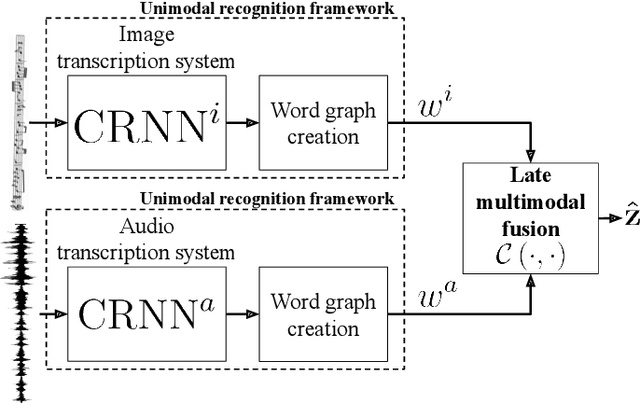
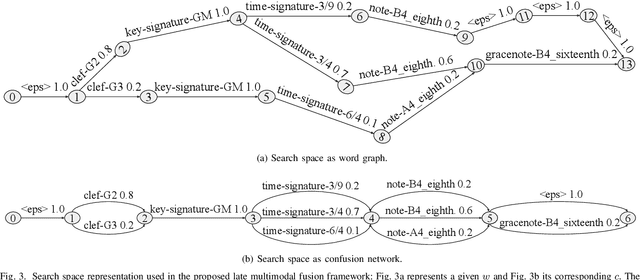

Music transcription, which deals with the conversion of music sources into a structured digital format, is a key problem for Music Information Retrieval (MIR). When addressing this challenge in computational terms, the MIR community follows two lines of research: music documents, which is the case of Optical Music Recognition (OMR), or audio recordings, which is the case of Automatic Music Transcription (AMT). The different nature of the aforementioned input data has conditioned these fields to develop modality-specific frameworks. However, their recent definition in terms of sequence labeling tasks leads to a common output representation, which enables research on a combined paradigm. In this respect, multimodal image and audio music transcription comprises the challenge of effectively combining the information conveyed by image and audio modalities. In this work, we explore this question at a late-fusion level: we study four combination approaches in order to merge, for the first time, the hypotheses regarding end-to-end OMR and AMT systems in a lattice-based search space. The results obtained for a series of performance scenarios -- in which the corresponding single-modality models yield different error rates -- showed interesting benefits of these approaches. In addition, two of the four strategies considered significantly improve the corresponding unimodal standard recognition frameworks.
Data Augmentation for Improving Tail-traffic Robustness in Skill-routing for Dialogue Systems
Jun 07, 2023
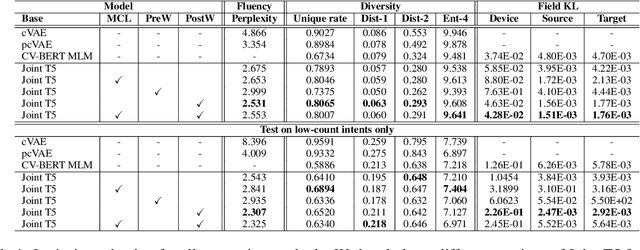
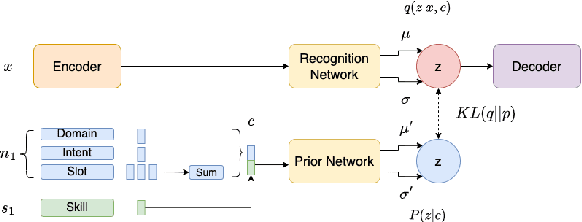
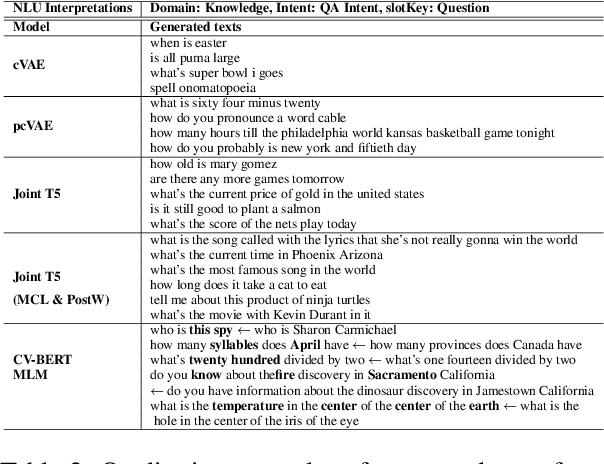
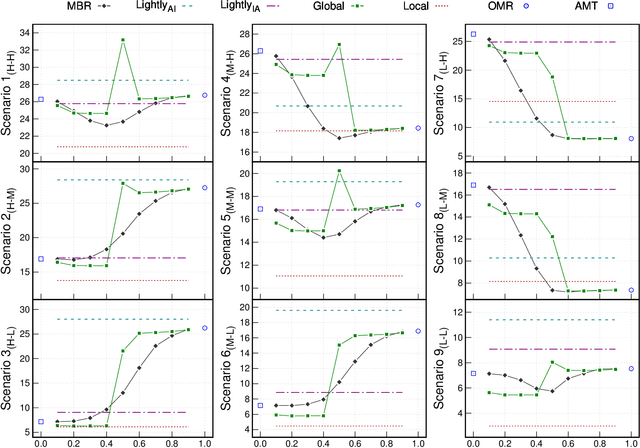
Large-scale conversational systems typically rely on a skill-routing component to route a user request to an appropriate skill and interpretation to serve the request. In such system, the agent is responsible for serving thousands of skills and interpretations which create a long-tail distribution due to the natural frequency of requests. For example, the samples related to play music might be a thousand times more frequent than those asking for theatre show times. Moreover, inputs used for ML-based skill routing are often a heterogeneous mix of strings, embedding vectors, categorical and scalar features which makes employing augmentation-based long-tail learning approaches challenging. To improve the skill-routing robustness, we propose an augmentation of heterogeneous skill-routing data and training targeted for robust operation in long-tail data regimes. We explore a variety of conditional encoder-decoder generative frameworks to perturb original data fields and create synthetic training data. To demonstrate the effectiveness of the proposed method, we conduct extensive experiments using real-world data from a commercial conversational system. Based on the experiment results, the proposed approach improves more than 80% (51 out of 63) of intents with less than 10K of traffic instances in the skill-routing replication task.