 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022

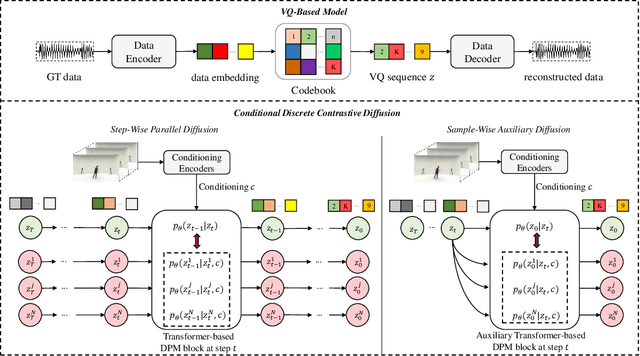

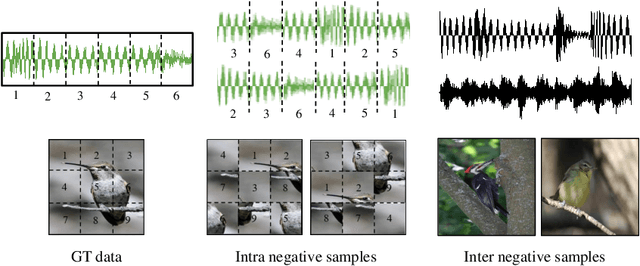
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning
Feb 08, 2020
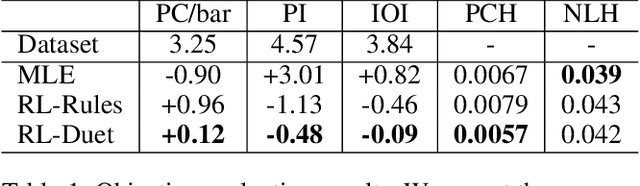

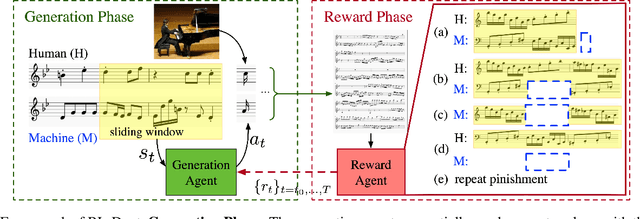
This paper presents a deep reinforcement learning algorithm for online accompaniment generation, with potential for real-time interactive human-machine duet improvisation. Different from offline music generation and harmonization, online music accompaniment requires the algorithm to respond to human input and generate the machine counterpart in a sequential order. We cast this as a reinforcement learning problem, where the generation agent learns a policy to generate a musical note (action) based on previously generated context (state). The key of this algorithm is the well-functioning reward model. Instead of defining it using music composition rules, we learn this model from monophonic and polyphonic training data. This model considers the compatibility of the machine-generated note with both the machine-generated context and the human-generated context. Experiments show that this algorithm is able to respond to the human part and generate a melodic, harmonic and diverse machine part. Subjective evaluations on preferences show that the proposed algorithm generates music pieces of higher quality than the baseline method.
MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation
Jul 18, 2017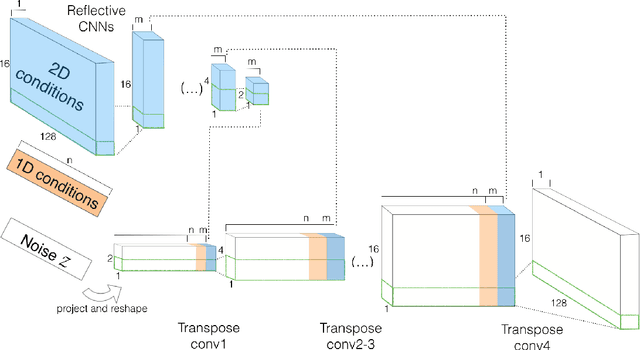
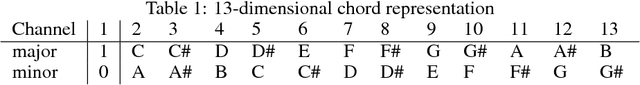

Most existing neural network models for music generation use recurrent neural networks. However, the recent WaveNet model proposed by DeepMind shows that convolutional neural networks (CNNs) can also generate realistic musical waveforms in the audio domain. Following this light, we investigate using CNNs for generating melody (a series of MIDI notes) one bar after another in the symbolic domain. In addition to the generator, we use a discriminator to learn the distributions of melodies, making it a generative adversarial network (GAN). Moreover, we propose a novel conditional mechanism to exploit available prior knowledge, so that the model can generate melodies either from scratch, by following a chord sequence, or by conditioning on the melody of previous bars (e.g. a priming melody), among other possibilities. The resulting model, named MidiNet, can be expanded to generate music with multiple MIDI channels (i.e. tracks). We conduct a user study to compare the melody of eight-bar long generated by MidiNet and by Google's MelodyRNN models, each time using the same priming melody. Result shows that MidiNet performs comparably with MelodyRNN models in being realistic and pleasant to listen to, yet MidiNet's melodies are reported to be much more interesting.
MusIAC: An extensible generative framework for Music Infilling Applications with multi-level Control
Feb 11, 2022
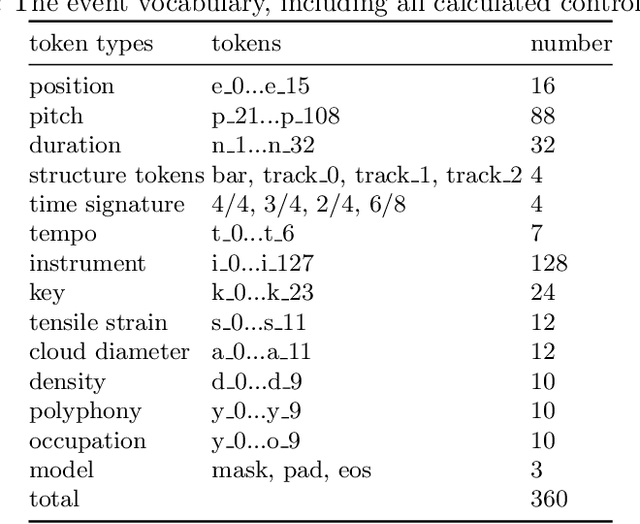


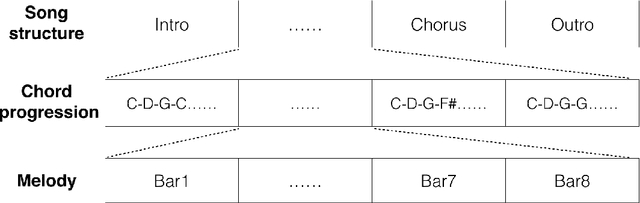
We present a novel music generation framework for music infilling, with a user friendly interface. Infilling refers to the task of generating musical sections given the surrounding multi-track music. The proposed transformer-based framework is extensible for new control tokens as the added music control tokens such as tonal tension per bar and track polyphony level in this work. We explore the effects of including several musically meaningful control tokens, and evaluate the results using objective metrics related to pitch and rhythm. Our results demonstrate that adding additional control tokens helps to generate music with stronger stylistic similarities to the original music. It also provides the user with more control to change properties like the music texture and tonal tension in each bar compared to previous research which only provided control for track density. We present the model in a Google Colab notebook to enable interactive generation.
Controllable deep melody generation via hierarchical music structure representation
Sep 02, 2021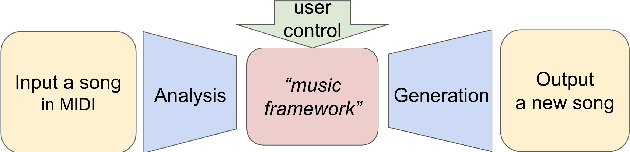
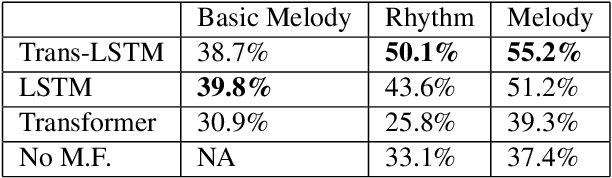
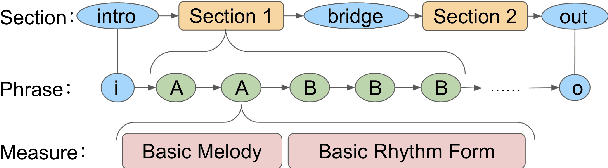
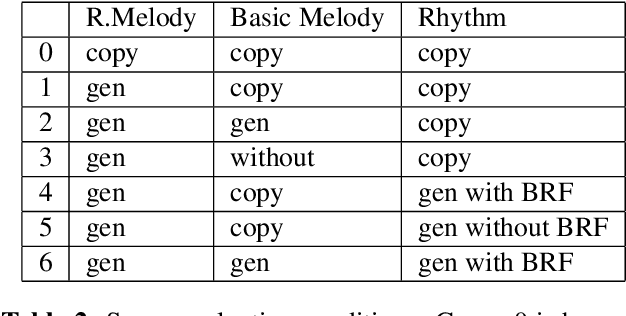
Recent advances in deep learning have expanded possibilities to generate music, but generating a customizable full piece of music with consistent long-term structure remains a challenge. This paper introduces MusicFrameworks, a hierarchical music structure representation and a multi-step generative process to create a full-length melody guided by long-term repetitive structure, chord, melodic contour, and rhythm constraints. We first organize the full melody with section and phrase-level structure. To generate melody in each phrase, we generate rhythm and basic melody using two separate transformer-based networks, and then generate the melody conditioned on the basic melody, rhythm and chords in an auto-regressive manner. By factoring music generation into sub-problems, our approach allows simpler models and requires less data. To customize or add variety, one can alter chords, basic melody, and rhythm structure in the music frameworks, letting our networks generate the melody accordingly. Additionally, we introduce new features to encode musical positional information, rhythm patterns, and melodic contours based on musical domain knowledge. A listening test reveals that melodies generated by our method are rated as good as or better than human-composed music in the POP909 dataset about half the time.
Music Generation using Three-layered LSTM
Jun 09, 2021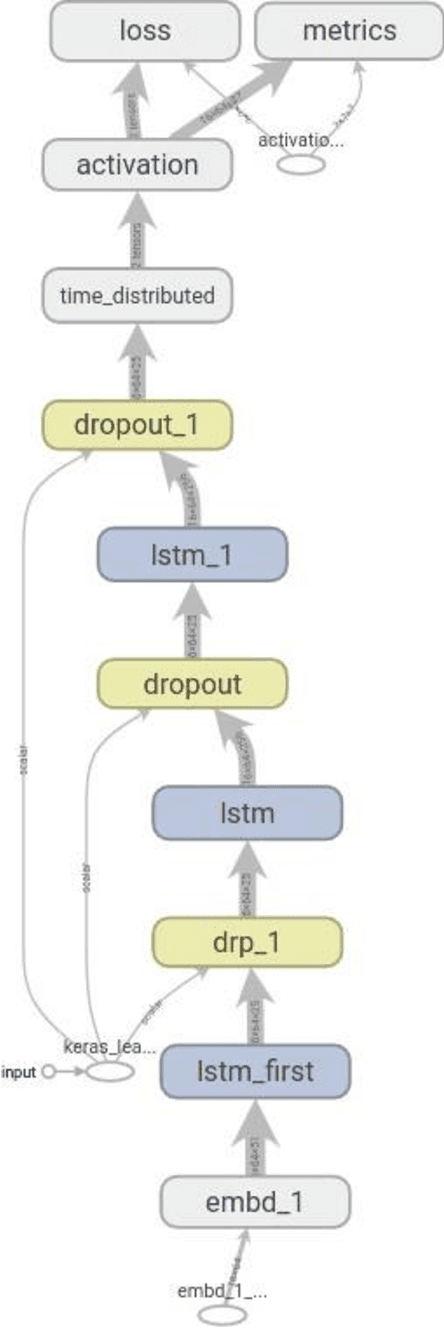
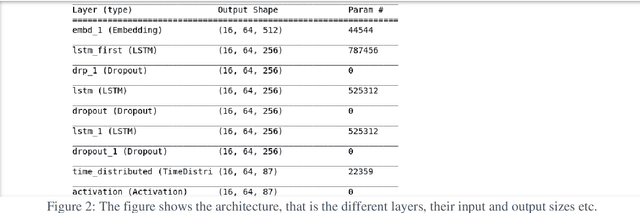
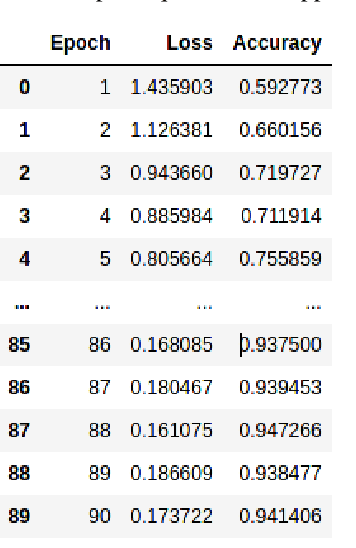
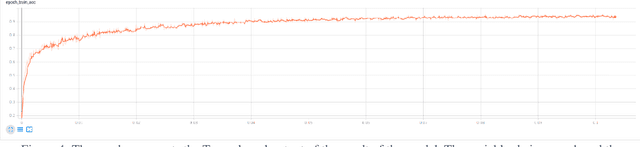
This paper explores the idea of utilising Long Short-Term Memory neural networks (LSTMNN) for the generation of musical sequences in ABC notation. The proposed approach takes ABC notations from the Nottingham dataset and encodes it to be fed as input for the neural networks. The primary objective is to input the neural networks with an arbitrary note, let the network process and augment a sequence based on the note until a good piece of music is produced. Multiple calibrations have been done to amend the parameters of the network for optimal generation. The output is assessed on the basis of rhythm, harmony, and grammar accuracy.
Actions Speak Louder than Listening: Evaluating Music Style Transfer based on Editing Experience
Oct 25, 2021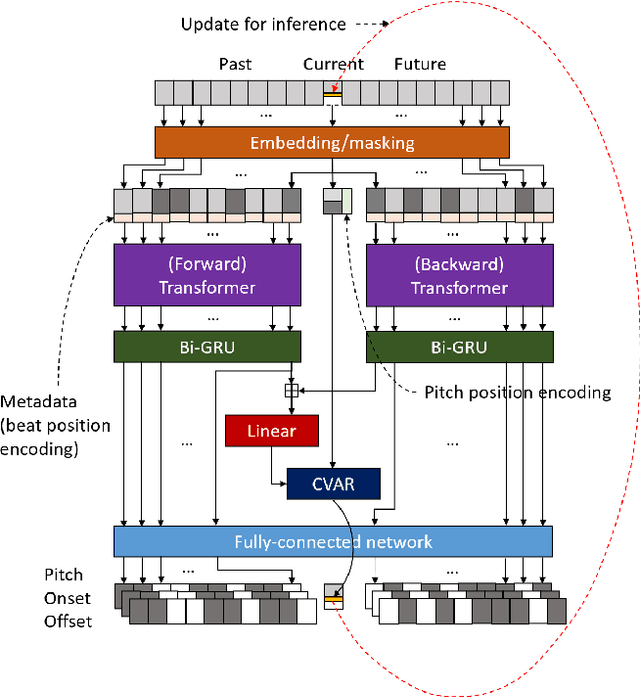

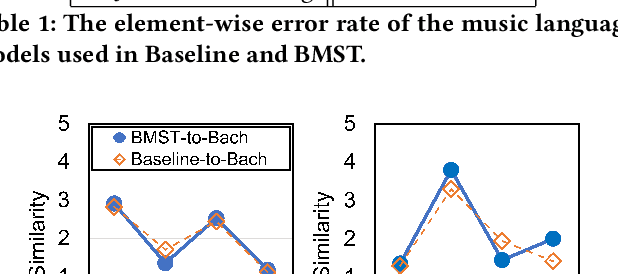
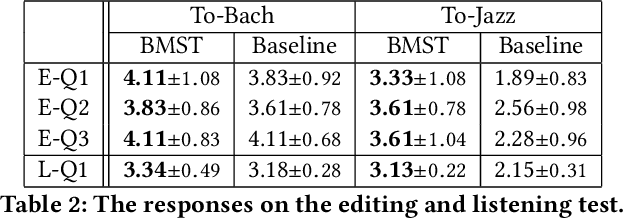
The subjective evaluation of music generation techniques has been mostly done with questionnaire-based listening tests while ignoring the perspectives from music composition, arrangement, and soundtrack editing. In this paper, we propose an editing test to evaluate users' editing experience of music generation models in a systematic way. To do this, we design a new music style transfer model combining the non-chronological inference architecture, autoregressive models and the Transformer, which serves as an improvement from the baseline model on the same style transfer task. Then, we compare the performance of the two models with a conventional listening test and the proposed editing test, in which the quality of generated samples is assessed by the amount of effort (e.g., the number of required keyboard and mouse actions) spent by users to polish a music clip. Results on two target styles indicate that the improvement over the baseline model can be reflected by the editing test quantitatively. Also, the editing test provides profound insights which are not accessible from usual listening tests. The major contribution of this paper is the systematic presentation of the editing test and the corresponding insights, while the proposed music style transfer model based on state-of-the-art neural networks represents another contribution.
An interactive music infilling interface for pop music composition
Mar 23, 2022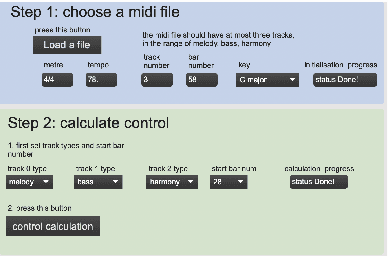
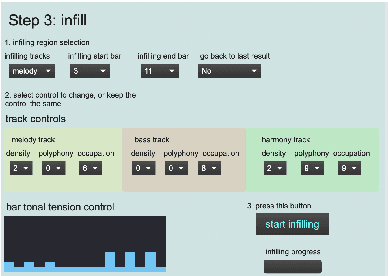
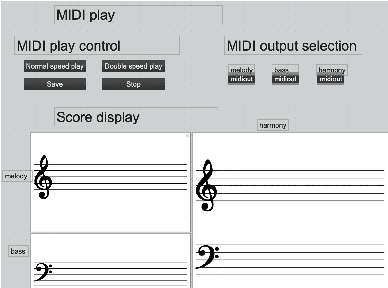
Artificial intelligence (AI) has been widely applied to music generation topics such as continuation, melody/harmony generation, genre transfer and music infilling application. Although with the burst interest to apply AI to music, there are still few interfaces for the musicians to take advantage of the latest progress of the AI technology. This makes those tools less valuable in practice and harder to find its advantage/drawbacks without utilizing them in the real scenario. This work builds a max patch for interactive music infilling application with different levels of control, including track density/polyphony/occupation rate and bar tonal tension control. The user can select the melody/bass/harmony track as the infilling content up to 16 bars. The infilling algorithm is based on the author's previous work, and the interface sends/receives messages to the AI system hosted in the cloud. This interface lowers the barrier of AI technology and can generate different variations of the selected content. Those results can give several alternatives to the musicians' composition, and the interactive process realizes the value of the AI infilling system.
Music Generation using Three layered LSTM
May 27, 2021This paper explores the idea of utilising Long Short-Term Memory neural networks (LSTMNN) for the generation of musical sequences in ABC notation. The proposed approach takes ABC notations from the Nottingham dataset and encodes it to beefed as input for the neural networks. The primary objective is to input the neural networks with an arbitrary note, let the network process and augment a sequence based on the note until a good piece of music is produced. Multiple tunings have been done to amend the parameters of the network for optimal generation. The output is assessed on the basis of rhythm, harmony, and grammar accuracy.
AccoMontage: Accompaniment Arrangement via Phrase Selection and Style Transfer
Aug 25, 2021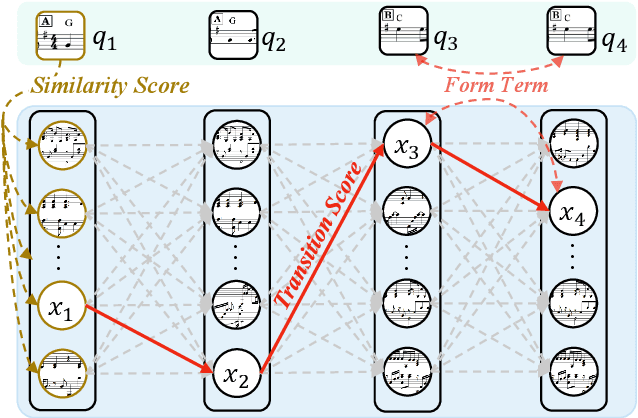



Accompaniment arrangement is a difficult music generation task involving intertwined constraints of melody, harmony, texture, and music structure. Existing models are not yet able to capture all these constraints effectively, especially for long-term music generation. To address this problem, we propose AccoMontage, an accompaniment arrangement system for whole pieces of music through unifying phrase selection and neural style transfer. We focus on generating piano accompaniments for folk/pop songs based on a lead sheet (i.e., melody with chord progression). Specifically, AccoMontage first retrieves phrase montages from a database while recombining them structurally using dynamic programming. Second, chords of the retrieved phrases are manipulated to match the lead sheet via style transfer. Lastly, the system offers controls over the generation process. In contrast to pure learning-based approaches, AccoMontage introduces a novel hybrid pathway, in which rule-based optimization and deep learning are both leveraged to complement each other for high-quality generation. Experiments show that our model generates well-structured accompaniment with delicate texture, significantly outperforming the baselines.