 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Modelling Lips-State Detection Using CNN for Non-Verbal Communications
Dec 11, 2021
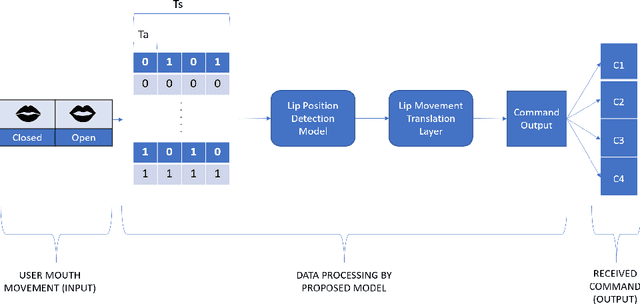
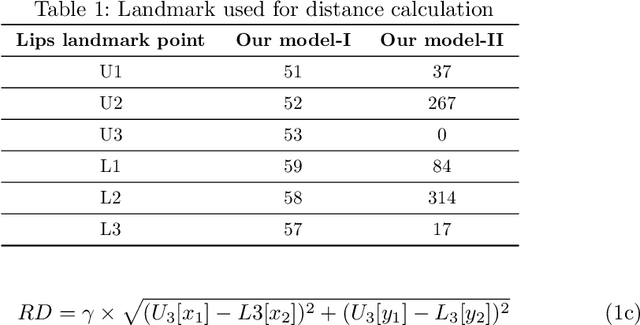
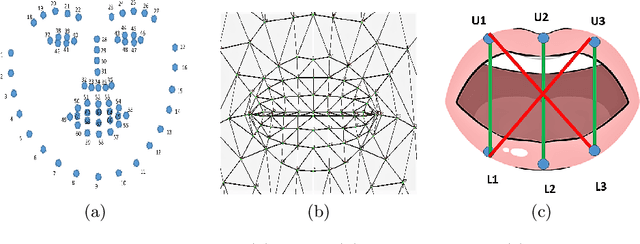
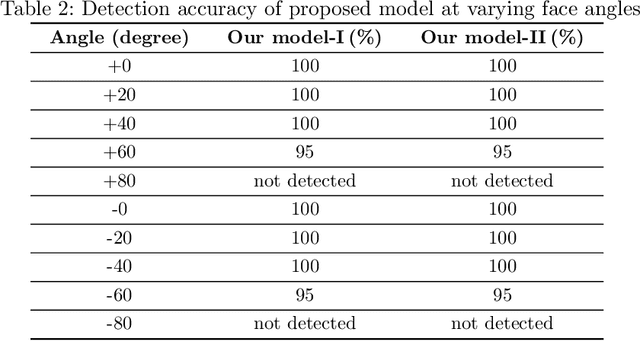
Vision-based deep learning models can be promising for speech-and-hearing-impaired and secret communications. While such non-verbal communications are primarily investigated with hand-gestures and facial expressions, no research endeavour is tracked so far for the lips state (i.e., open/close)-based interpretation/translation system. In support of this development, this paper reports two new Convolutional Neural Network (CNN) models for lips state detection. Building upon two prominent lips landmark detectors, DLIB and MediaPipe, we simplify lips-state model with a set of six key landmarks, and use their distances for the lips state classification. Thereby, both the models are developed to count the opening and closing of lips and thus, they can classify a symbol with the total count. Varying frame-rates, lips-movements and face-angles are investigated to determine the effectiveness of the models. Our early experimental results demonstrate that the model with DLIB is relatively slower in terms of an average of 6 frames per second (FPS) and higher average detection accuracy of 95.25%. In contrast, the model with MediaPipe offers faster landmark detection capability with an average FPS of 20 and detection accuracy of 94.4%. Both models thus could effectively interpret the lips state for non-verbal semantics into a natural language.
A Computer Vision Application for Assessing Facial Acne Severity from Selfie Images
Jul 31, 2019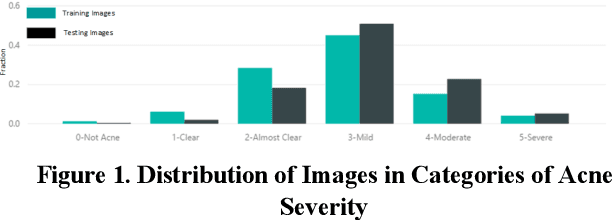
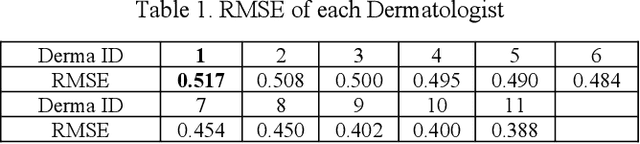
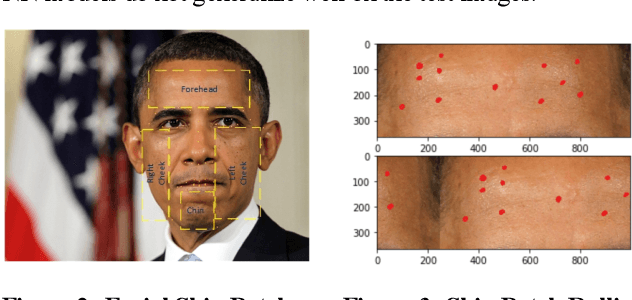
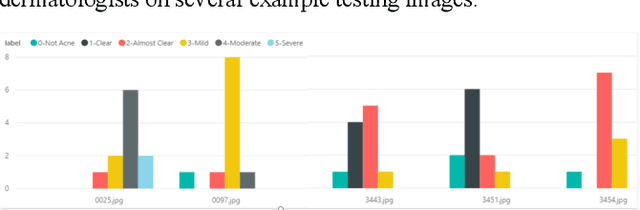
We worked with Nestle SHIELD (Skin Health, Innovation, Education, and Longevity Development, NSH) to develop a deep learning model that is able to assess acne severity from selfie images as accurate as dermatologists. The model was deployed as a mobile application, providing patients an easy way to assess and track the progress of their acne treatment. NSH acquired 4,700 selfie images for this study and recruited 11 internal dermatologists to label them in five categories: 1-Clear, 2- Almost Clear, 3-Mild, 4-Moderate, 5-Severe. Using OpenCV to detect facial landmarks we cut specific skin patches from the selfie images in order to minimize irrelevant background. We then applied a transfer learning approach by extracting features from the patches using a ResNet 152 pre-trained model, followed by a fully connected layer trained to approximate the desired severity rating. To address the problem of spatial sensitivity of CNN models, we introduce a new image rolling data augmentation approach, effectively causing acne lesions appeared in more locations in the training images. Our results demonstrate that this approach improved the generalization of the CNN model, outperforming more than half of the panel of human dermatologists on test images. To our knowledge, this is the first deep learning-based solution for acne assessment using selfie images.
Information-Theoretic Bias Assessment Of Learned Representations Of Pretrained Face Recognition
Nov 09, 2021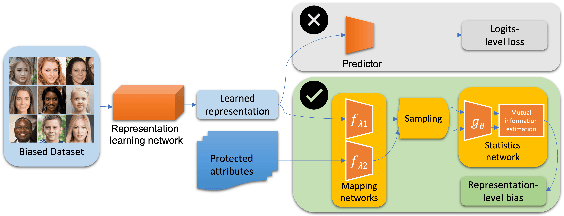
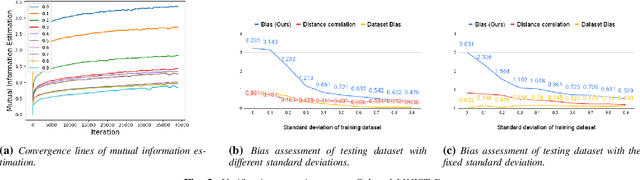
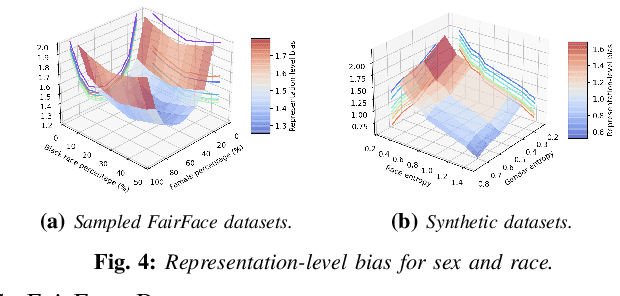

As equality issues in the use of face recognition have garnered a lot of attention lately, greater efforts have been made to debiased deep learning models to improve fairness to minorities. However, there is still no clear definition nor sufficient analysis for bias assessment metrics. We propose an information-theoretic, independent bias assessment metric to identify degree of bias against protected demographic attributes from learned representations of pretrained facial recognition systems. Our metric differs from other methods that rely on classification accuracy or examine the differences between ground truth and predicted labels of protected attributes predicted using a shallow network. Also, we argue, theoretically and experimentally, that logits-level loss is not adequate to explain bias since predictors based on neural networks will always find correlations. Further, we present a synthetic dataset that mitigates the issue of insufficient samples in certain cohorts. Lastly, we establish a benchmark metric by presenting advantages in clear discrimination and small variation comparing with other metrics, and evaluate the performance of different debiased models with the proposed metric.
SeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Nov 24, 2021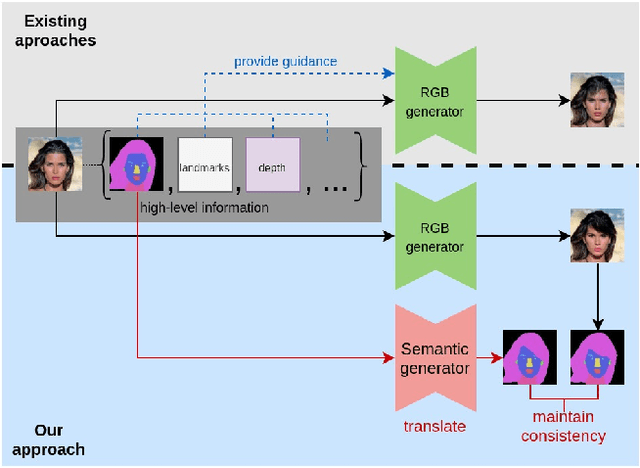
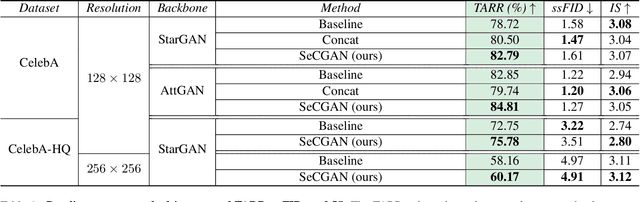
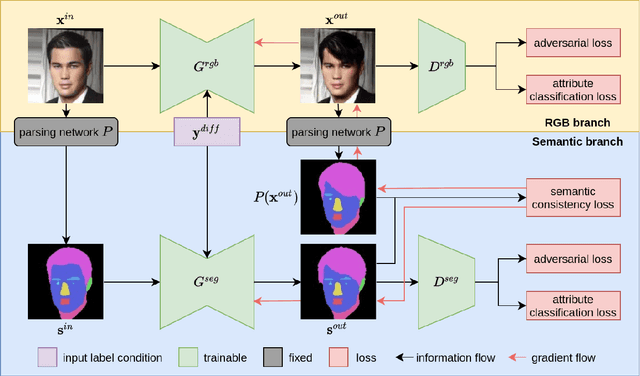
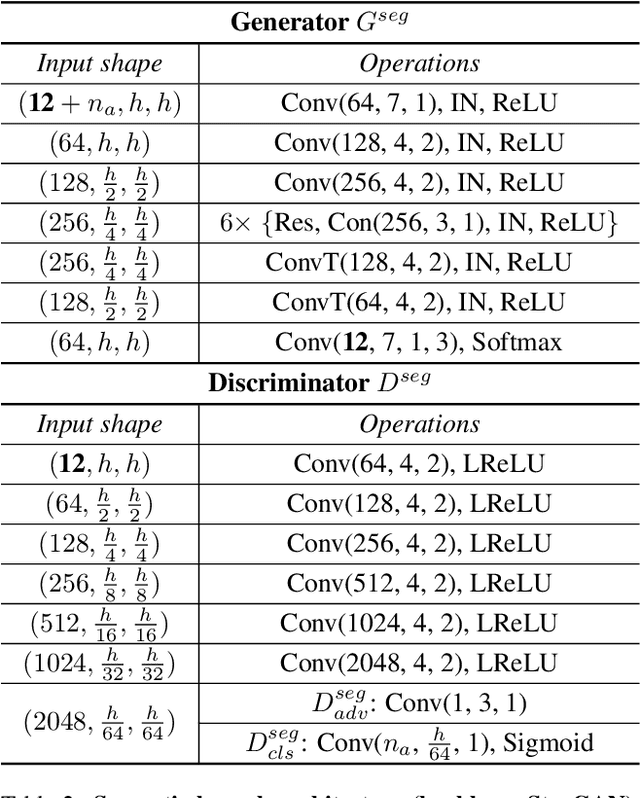
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.
MotionInput v2.0 supporting DirectX: A modular library of open-source gesture-based machine learning and computer vision methods for interacting and controlling existing software with a webcam
Aug 10, 2021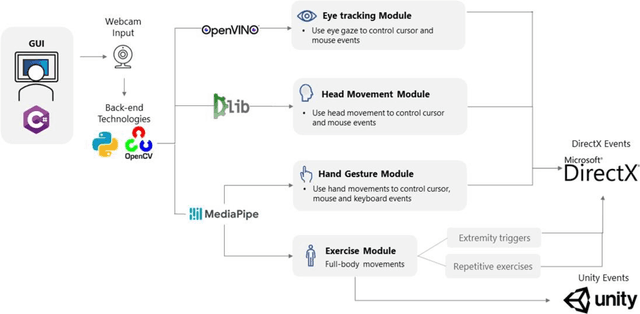
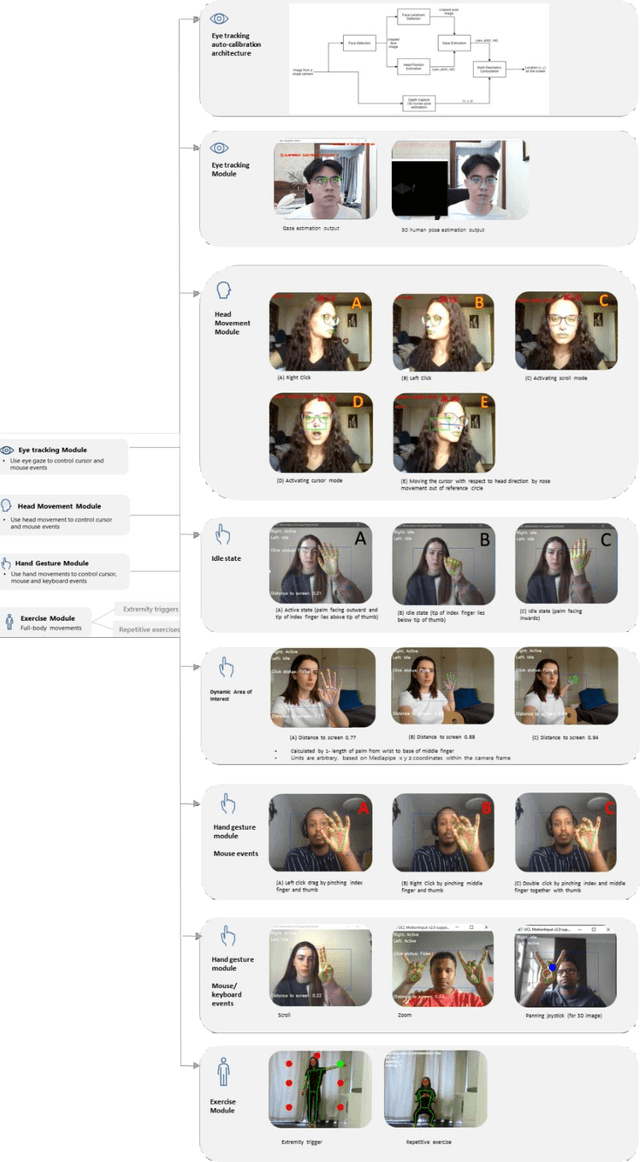
Touchless computer interaction has become an important consideration during the COVID-19 pandemic period. Despite progress in machine learning and computer vision that allows for advanced gesture recognition, an integrated collection of such open-source methods and a user-customisable approach to utilising them in a low-cost solution for touchless interaction in existing software is still missing. In this paper, we introduce the MotionInput v2.0 application. This application utilises published open-source libraries and additional gesture definitions developed to take the video stream from a standard RGB webcam as input. It then maps human motion gestures to input operations for existing applications and games. The user can choose their own preferred way of interacting from a series of motion types, including single and bi-modal hand gesturing, full-body repetitive or extremities-based exercises, head and facial movements, eye tracking, and combinations of the above. We also introduce a series of bespoke gesture recognition classifications as DirectInput triggers, including gestures for idle states, auto calibration, depth capture from a 2D RGB webcam stream and tracking of facial motions such as mouth motions, winking, and head direction with rotation. Three use case areas assisted the development of the modules: creativity software, office and clinical software, and gaming software. A collection of open-source libraries has been integrated and provide a layer of modular gesture mapping on top of existing mouse and keyboard controls in Windows via DirectX. With ease of access to webcams integrated into most laptops and desktop computers, touchless computing becomes more available with MotionInput v2.0, in a federated and locally processed method.
Visual Diver Face Recognition for Underwater Human-Robot Interaction
Nov 18, 2020

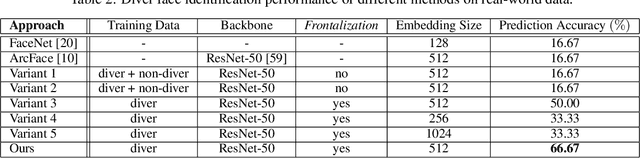
This paper presents a deep-learned facial recognition method for underwater robots to identify scuba divers. Specifically, the proposed method is able to recognize divers underwater with faces heavily obscured by scuba masks and breathing apparatus. Our contribution in this research is towards robust facial identification of individuals under significant occlusion of facial features and image degradation from underwater optical distortions. With the ability to correctly recognize divers, autonomous underwater vehicles (AUV) will be able to engage in collaborative tasks with the correct person in human-robot teams and ensure that instructions are accepted from only those authorized to command the robots. We demonstrate that our proposed framework is able to learn discriminative features from real-world diver faces through different data augmentation and generation techniques. Experimental evaluations show that this framework achieves a 3-fold increase in prediction accuracy compared to the state-of-the-art (SOTA) algorithms and is well-suited for embedded inference on robotic platforms.
Unimodal Face Classification with Multimodal Training
Dec 08, 2021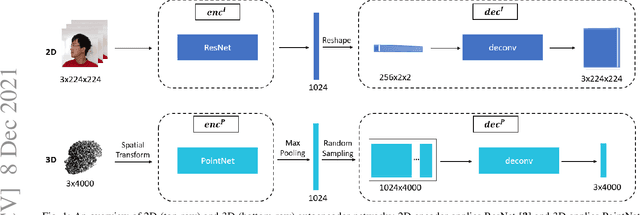
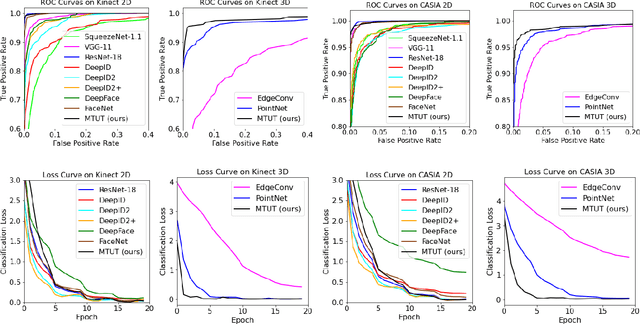
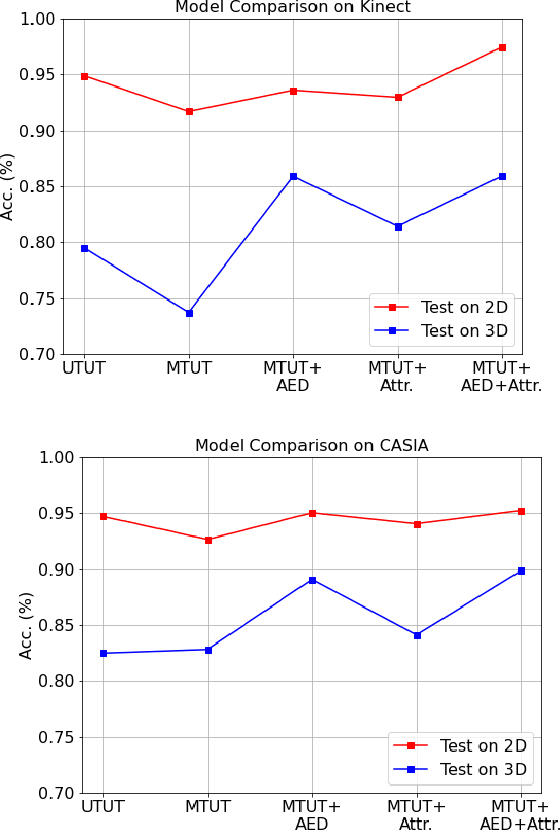
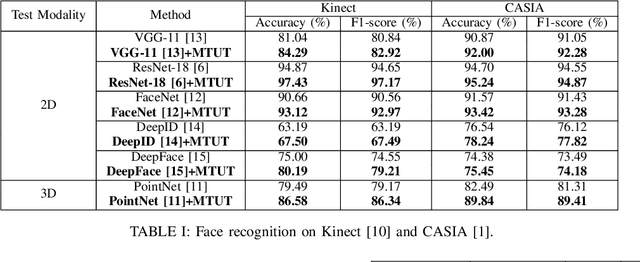
Face recognition is a crucial task in various multimedia applications such as security check, credential access and motion sensing games. However, the task is challenging when an input face is noisy (e.g. poor-condition RGB image) or lacks certain information (e.g. 3D face without color). In this work, we propose a Multimodal Training Unimodal Test (MTUT) framework for robust face classification, which exploits the cross-modality relationship during training and applies it as a complementary of the imperfect single modality input during testing. Technically, during training, the framework (1) builds both intra-modality and cross-modality autoencoders with the aid of facial attributes to learn latent embeddings as multimodal descriptors, (2) proposes a novel multimodal embedding divergence loss to align the heterogeneous features from different modalities, which also adaptively avoids the useless modality (if any) from confusing the model. This way, the learned autoencoders can generate robust embeddings in single-modality face classification on test stage. We evaluate our framework in two face classification datasets and two kinds of testing input: (1) poor-condition image and (2) point cloud or 3D face mesh, when both 2D and 3D modalities are available for training. We experimentally show that our MTUT framework consistently outperforms ten baselines on 2D and 3D settings of both datasets.
k-Same-Siamese-GAN: k-Same Algorithm with Generative Adversarial Network for Facial Image De-identification with Hyperparameter Tuning and Mixed Precision Training
Mar 27, 2019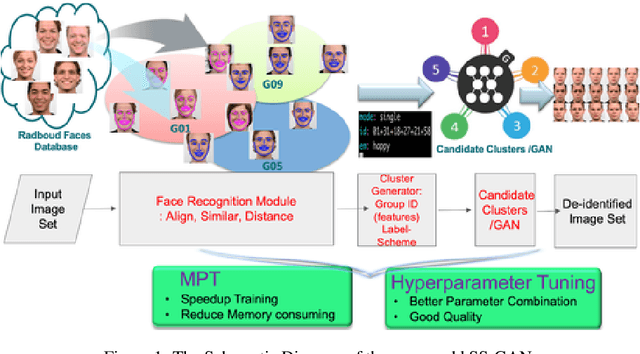

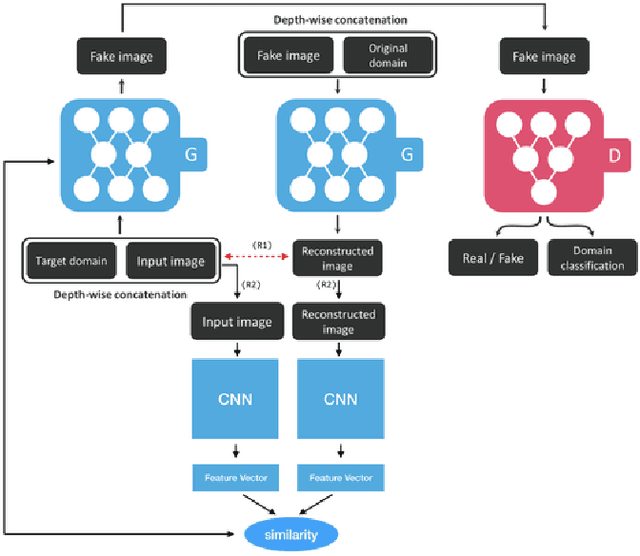

In recent years, advances in camera and computing hardware have made it easy to capture and store amounts of image and video data. Consider a data holder, such as a hospital or a government entity, who has a privately held collection of personal data. Then, how can we ensure that the data holder does conceal the identity of each individual in the imagery of personal data while still preserving certain useful aspects of the data after de-identification? In this work, we proposed a novel approach towards high-resolution facial image de-identification, called k-Same-Siamese-GAN (kSS-GAN), which leverages k-Same-Anonymity mechanism, Generative Adversarial Network (GAN), and hyperparameter tuning. To speed up training and reduce memory consumption, the mixed precision training (MPT) technique is also applied to make kSS-GAN provide guarantees regarding privacy protection on close-form identities and be trained much more efficiently as well. Finally, we dedicated our system to an actual dataset: RafD dataset for performance testing. Besides protecting privacy of high resolution of facial images, the proposed system is also justified for its ability in automating parameter tuning and breaking through the limitation of the number of adjustable parameters.
Preventing Personal Data Theft in Images with Adversarial ML
Oct 20, 2020
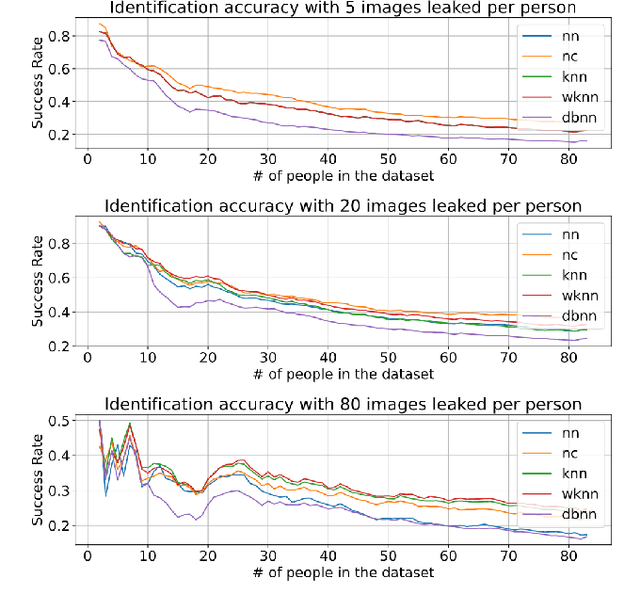
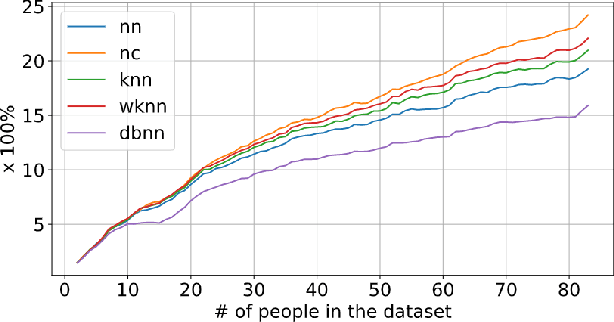

Facial recognition tools are becoming exceptionally accurate in identifying people from images. However, this comes at the cost of privacy for users of online services with photo management (e.g. social media platforms). Particularly troubling is the ability to leverage unsupervised learning to recognize faces even when the user has not labeled their images. This is made simpler by modern facial recognition tools, such as FaceNet, that use encoders to generate low dimensional embeddings that can be clustered to learn previously unknown faces. In this paper, we propose a strategy to generate non-invasive noise masks to apply to facial images for a newly introduced user, yielding adversarial examples and preventing the formation of identifiable clusters in the embedding space. We demonstrate the effectiveness of our method by showing that various classification and clustering methods cannot reliably cluster the adversarial examples we generate.