 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Masked Student Dataset of Expressions
Apr 07, 2023
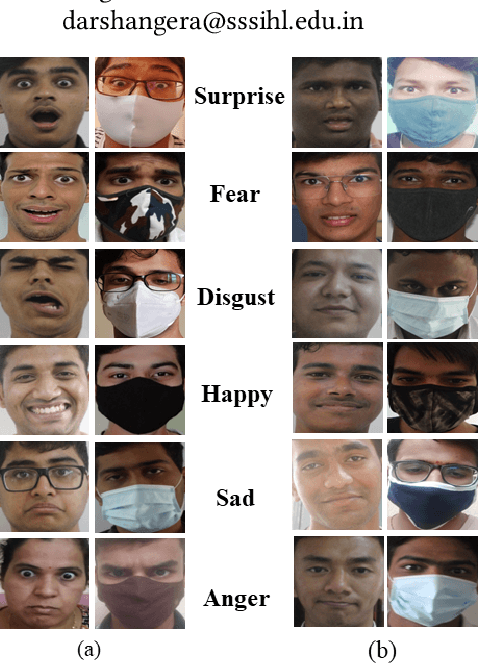

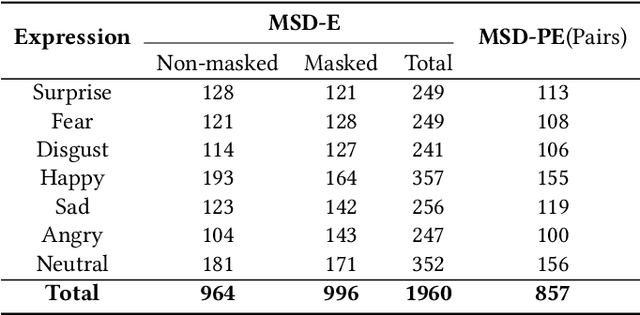
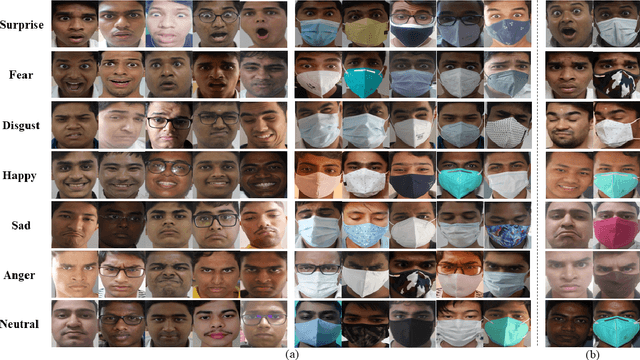
Facial expression recognition (FER) algorithms work well in constrained environments with little or no occlusion of the face. However, real-world face occlusion is prevalent, most notably with the need to use a face mask in the current Covid-19 scenario. While there are works on the problem of occlusion in FER, little has been done before on the particular face mask scenario. Moreover, the few works in this area largely use synthetically created masked FER datasets. Motivated by these challenges posed by the pandemic to FER, we present a novel dataset, the Masked Student Dataset of Expressions or MSD-E, consisting of 1,960 real-world non-masked and masked facial expression images collected from 142 individuals. Along with the issue of obfuscated facial features, we illustrate how other subtler issues in masked FER are represented in our dataset. We then provide baseline results using ResNet-18, finding that its performance dips in the non-masked case when trained for FER in the presence of masks. To tackle this, we test two training paradigms: contrastive learning and knowledge distillation, and find that they increase the model's performance in the masked scenario while maintaining its non-masked performance. We further visualise our results using t-SNE plots and Grad-CAM, demonstrating that these paradigms capitalise on the limited features available in the masked scenario. Finally, we benchmark SOTA methods on MSD-E.
Kinship Representation Learning with Face Componential Relation
Apr 12, 2023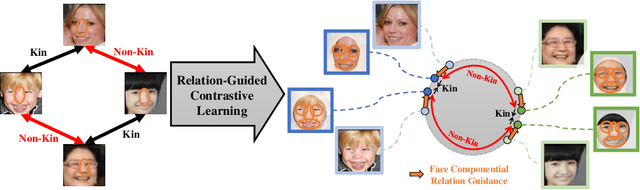
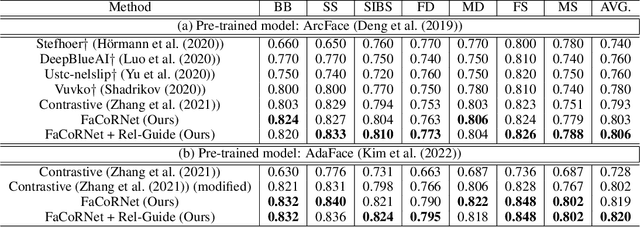
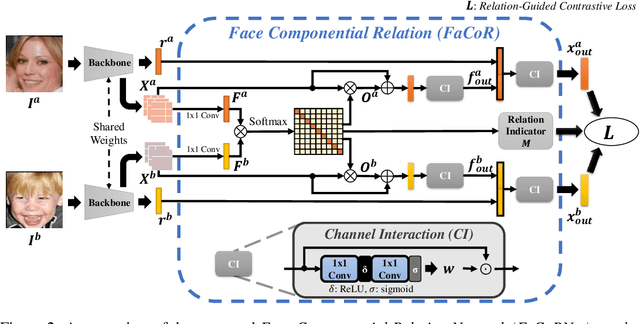
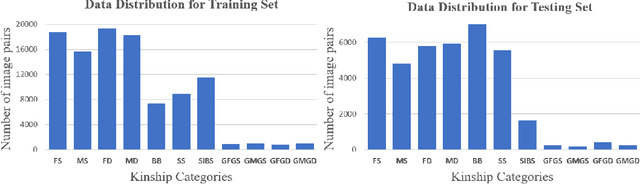
Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed \MainMethodAbbr~outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Privacy-preserving Adversarial Facial Features
May 08, 2023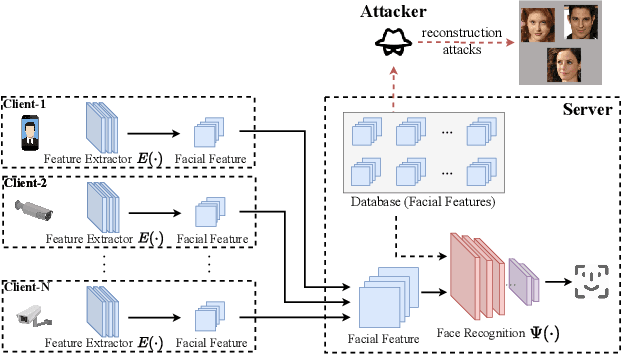

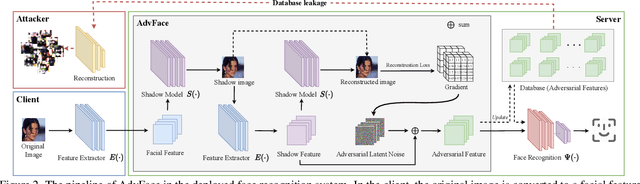

Face recognition service providers protect face privacy by extracting compact and discriminative facial features (representations) from images, and storing the facial features for real-time recognition. However, such features can still be exploited to recover the appearance of the original face by building a reconstruction network. Although several privacy-preserving methods have been proposed, the enhancement of face privacy protection is at the expense of accuracy degradation. In this paper, we propose an adversarial features-based face privacy protection (AdvFace) approach to generate privacy-preserving adversarial features, which can disrupt the mapping from adversarial features to facial images to defend against reconstruction attacks. To this end, we design a shadow model which simulates the attackers' behavior to capture the mapping function from facial features to images and generate adversarial latent noise to disrupt the mapping. The adversarial features rather than the original features are stored in the server's database to prevent leaked features from exposing facial information. Moreover, the AdvFace requires no changes to the face recognition network and can be implemented as a privacy-enhancing plugin in deployed face recognition systems. Extensive experimental results demonstrate that AdvFace outperforms the state-of-the-art face privacy-preserving methods in defending against reconstruction attacks while maintaining face recognition accuracy.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022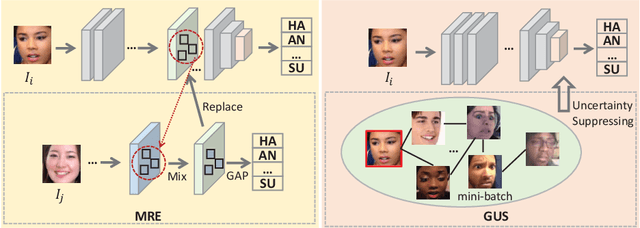
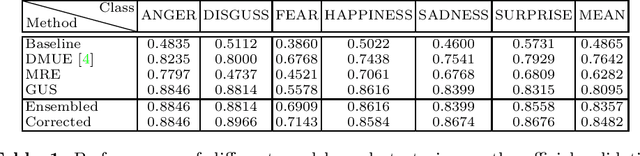
Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.
Evaluation of Self-taught Learning-based Representations for Facial Emotion Recognition
Apr 26, 2022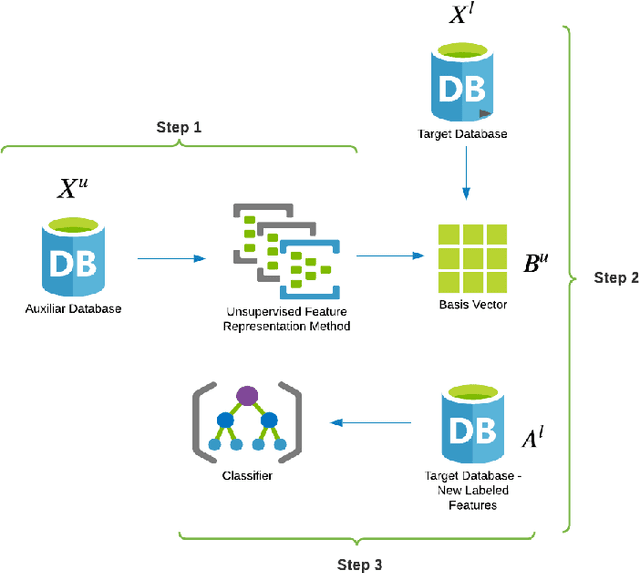
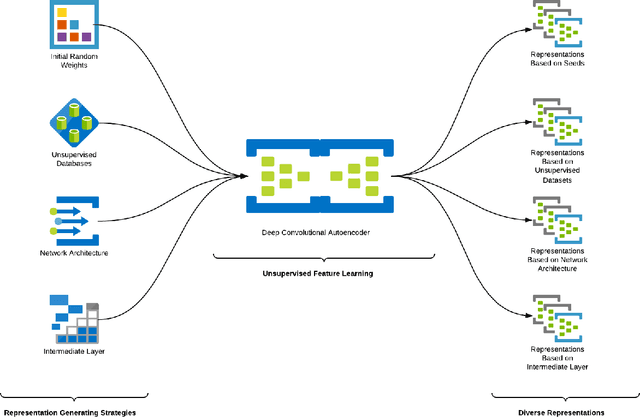


This work describes different strategies to generate unsupervised representations obtained through the concept of self-taught learning for facial emotion recognition (FER). The idea is to create complementary representations promoting diversity by varying the autoencoders' initialization, architecture, and training data. SVM, Bagging, Random Forest, and a dynamic ensemble selection method are evaluated as final classification methods. Experimental results on Jaffe and Cohn-Kanade datasets using a leave-one-subject-out protocol show that FER methods based on the proposed diverse representations compare favorably against state-of-the-art approaches that also explore unsupervised feature learning.
How far generated data can impact Neural Networks performance?
Mar 27, 2023
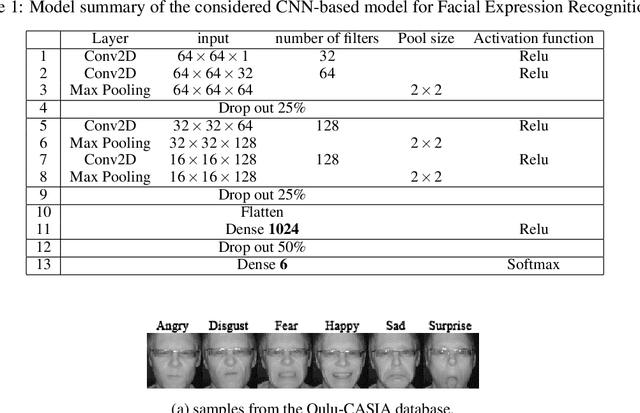

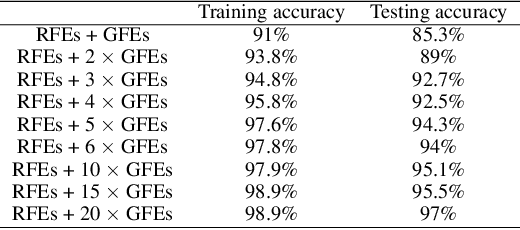
The success of deep learning models depends on the size and quality of the dataset to solve certain tasks. Here, we explore how far generated data can aid real data in improving the performance of Neural Networks. In this work, we consider facial expression recognition since it requires challenging local data generation at the level of local regions such as mouth, eyebrows, etc, rather than simple augmentation. Generative Adversarial Networks (GANs) provide an alternative method for generating such local deformations but they need further validation. To answer our question, we consider noncomplex Convolutional Neural Networks (CNNs) based classifiers for recognizing Ekman emotions. For the data generation process, we consider generating facial expressions (FEs) by relying on two GANs. The first generates a random identity while the second imposes facial deformations on top of it. We consider training the CNN classifier using FEs from: real-faces, GANs-generated, and finally using a combination of real and GAN-generated faces. We determine an upper bound regarding the data generation quantity to be mixed with the real one which contributes the most to enhancing FER accuracy. In our experiments, we find out that 5-times more synthetic data to the real FEs dataset increases accuracy by 16%.
A comparative study of emotion recognition methods using facial expressions
Dec 05, 2022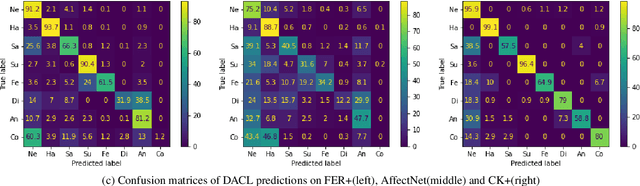
Understanding the facial expressions of our interlocutor is important to enrich the communication and to give it a depth that goes beyond the explicitly expressed. In fact, studying one's facial expression gives insight into their hidden emotion state. However, even as humans, and despite our empathy and familiarity with the human emotional experience, we are only able to guess what the other might be feeling. In the fields of artificial intelligence and computer vision, Facial Emotion Recognition (FER) is a topic that is still in full growth mostly with the advancement of deep learning approaches and the improvement of data collection. The main purpose of this paper is to compare the performance of three state-of-the-art networks, each having their own approach to improve on FER tasks, on three FER datasets. The first and second sections respectively describe the three datasets and the three studied network architectures designed for an FER task. The experimental protocol, the results and their interpretation are outlined in the remaining sections.
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Aug 22, 2022
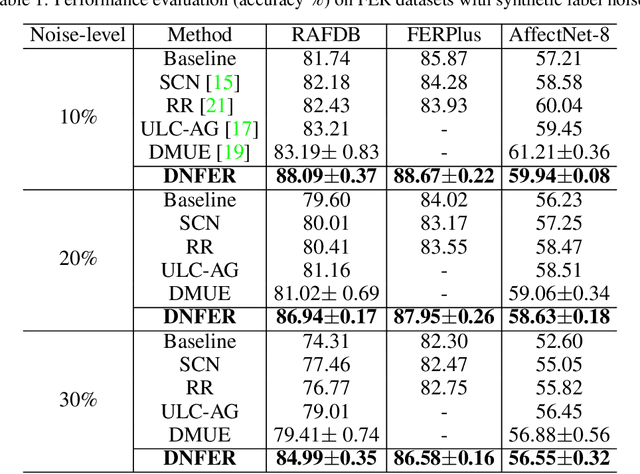
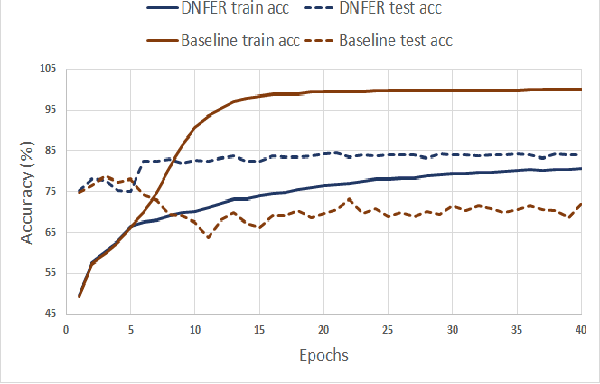
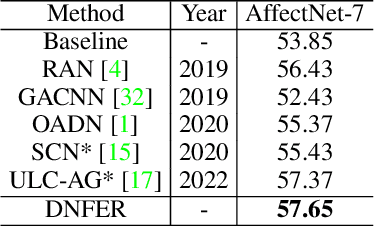
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.
Adversarial Attacks on Convolutional Neural Networks in Facial Recognition Domain
Jan 30, 2020

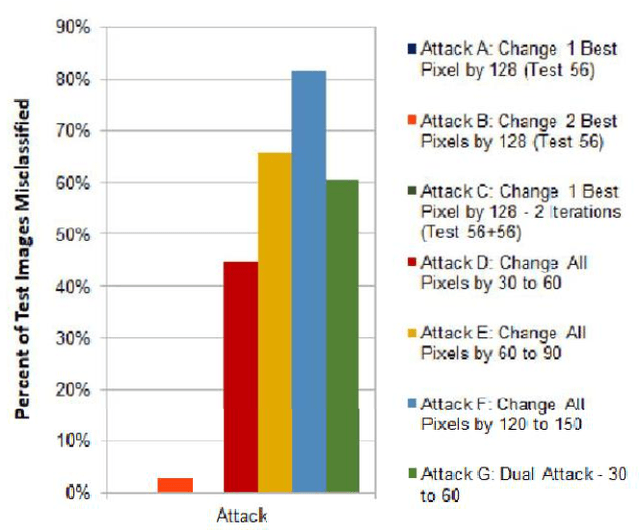
Numerous recent studies have demonstrated how Deep Neural Network (DNN) classifiers can be fooled by adversarial examples, in which an attacker adds perturbations to an original sample, causing the classifier to misclassify the sample. Adversarial attacks that render DNNs vulnerable in real life represent a serious threat, given the consequences of improperly functioning autonomous vehicles, malware filters, or biometric authentication systems. In this paper, we apply Fast Gradient Sign Method to introduce perturbations to a facial image dataset and then test the output on a different classifier that we trained ourselves, to analyze transferability of this method. Next, we craft a variety of different attack algorithms on a facial image dataset, with the intention of developing untargeted black-box approaches assuming minimal adversarial knowledge, to further assess the robustness of DNNs in the facial recognition realm. We explore modifying single optimal pixels by a large amount, or modifying all pixels by a smaller amount, or combining these two attack approaches. While our single-pixel attacks achieved about a 15% average decrease in classifier confidence level for the actual class, the all-pixel attacks were more successful and achieved up to an 84% average decrease in confidence, along with an 81.6% misclassification rate, in the case of the attack that we tested with the highest levels of perturbation. Even with these high levels of perturbation, the face images remained fairly clearly identifiable to a human. We hope our research may help to advance the study of adversarial attacks on DNNs and defensive mechanisms to counteract them, particularly in the facial recognition domain.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021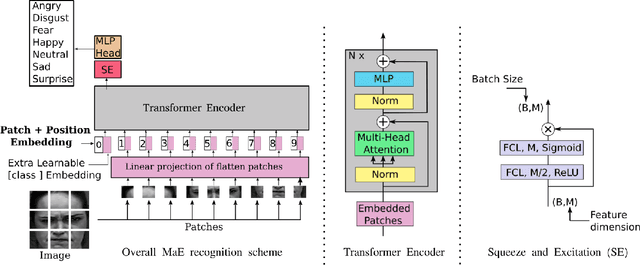
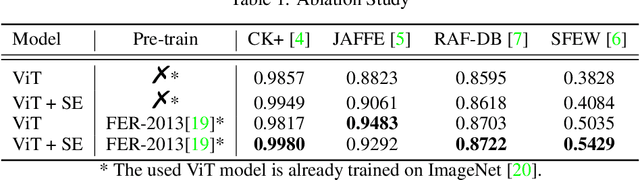
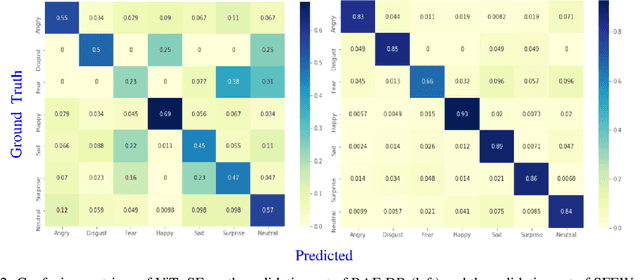
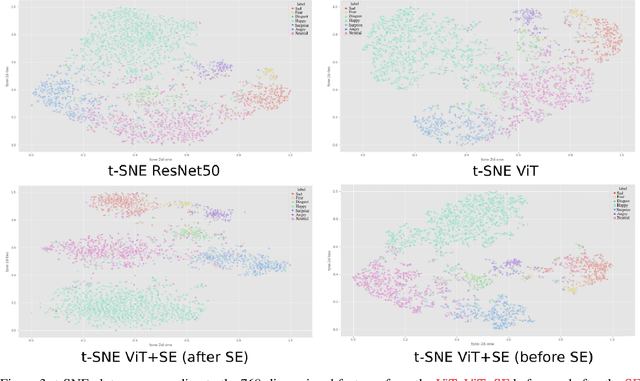
As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.