 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Pronoun Use Fidelity with English LLMs: Are they Reasoning, Repeating, or Just Biased?
Apr 04, 2024
Robust, faithful and harm-free pronoun use for individuals is an important goal for language models as their use increases, but prior work tends to study only one or two of these components at a time. To measure progress towards the combined goal, we introduce the task of pronoun use fidelity: given a context introducing a co-referring entity and pronoun, the task is to reuse the correct pronoun later, independent of potential distractors. We present a carefully-designed dataset of over 5 million instances to evaluate pronoun use fidelity in English, and we use it to evaluate 37 popular large language models across architectures (encoder-only, decoder-only and encoder-decoder) and scales (11M-70B parameters). We find that while models can mostly faithfully reuse previously-specified pronouns in the presence of no distractors, they are significantly worse at processing she/her/her, singular they and neopronouns. Additionally, models are not robustly faithful to pronouns, as they are easily distracted. With even one additional sentence containing a distractor pronoun, accuracy drops on average by 34%. With 5 distractor sentences, accuracy drops by 52% for decoder-only models and 13% for encoder-only models. We show that widely-used large language models are still brittle, with large gaps in reasoning and in processing different pronouns in a setting that is very simple for humans, and we encourage researchers in bias and reasoning to bridge them.
Site-specific Deterministic Temperature and Humidity Forecasts with Explainable and Reliable Machine Learning
Apr 04, 2024Site-specific weather forecasts are essential to accurate prediction of power demand and are consequently of great interest to energy operators. However, weather forecasts from current numerical weather prediction (NWP) models lack the fine-scale detail to capture all important characteristics of localised real-world sites. Instead they provide weather information representing a rectangular gridbox (usually kilometres in size). Even after post-processing and bias correction, area-averaged information is usually not optimal for specific sites. Prior work on site optimised forecasts has focused on linear methods, weighted consensus averaging, time-series methods, and others. Recent developments in machine learning (ML) have prompted increasing interest in applying ML as a novel approach towards this problem. In this study, we investigate the feasibility of optimising forecasts at sites by adopting the popular machine learning model gradient boosting decision tree, supported by the Python version of the XGBoost package. Regression trees have been trained with historical NWP and site observations as training data, aimed at predicting temperature and dew point at multiple site locations across Australia. We developed a working ML framework, named 'Multi-SiteBoost' and initial testing results show a significant improvement compared with gridded values from bias-corrected NWP models. The improvement from XGBoost is found to be comparable with non-ML methods reported in literature. With the insights provided by SHapley Additive exPlanations (SHAP), this study also tests various approaches to understand the ML predictions and increase the reliability of the forecasts generated by ML.
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
Apr 03, 2024This work presents BAdam, an optimizer that leverages the block coordinate optimization framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models and reduces running time of the backward process thanks to the chain rule property. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B model on the Alpaca-GPT4 dataset using a single RTX3090-24GB GPU. The results indicate that BAdam exhibits superior convergence behavior in comparison to LoRA and LOMO. Furthermore, our downstream performance evaluation of the instruction-tuned models using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam. Our code is available at https://github.com/Ledzy/BAdam.
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Apr 03, 2024This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Adversarial Combinatorial Bandits with Switching Costs
Apr 02, 2024We study the problem of adversarial combinatorial bandit with a switching cost $\lambda$ for a switch of each selected arm in each round, considering both the bandit feedback and semi-bandit feedback settings. In the oblivious adversarial case with $K$ base arms and time horizon $T$, we derive lower bounds for the minimax regret and design algorithms to approach them. To prove these lower bounds, we design stochastic loss sequences for both feedback settings, building on an idea from previous work in Dekel et al. (2014). The lower bound for bandit feedback is $ \tilde{\Omega}\big( (\lambda K)^{\frac{1}{3}} (TI)^{\frac{2}{3}}\big)$ while that for semi-bandit feedback is $ \tilde{\Omega}\big( (\lambda K I)^{\frac{1}{3}} T^{\frac{2}{3}}\big)$ where $I$ is the number of base arms in the combinatorial arm played in each round. To approach these lower bounds, we design algorithms that operate in batches by dividing the time horizon into batches to restrict the number of switches between actions. For the bandit feedback setting, where only the total loss of the combinatorial arm is observed, we introduce the Batched-Exp2 algorithm which achieves a regret upper bound of $\tilde{O}\big((\lambda K)^{\frac{1}{3}}T^{\frac{2}{3}}I^{\frac{4}{3}}\big)$ as $T$ tends to infinity. In the semi-bandit feedback setting, where all losses for the combinatorial arm are observed, we propose the Batched-BROAD algorithm which achieves a regret upper bound of $\tilde{O}\big( (\lambda K)^{\frac{1}{3}} (TI)^{\frac{2}{3}}\big)$.
ShadowRemovalNet: Efficient Real-Time Shadow Removal
Mar 13, 2024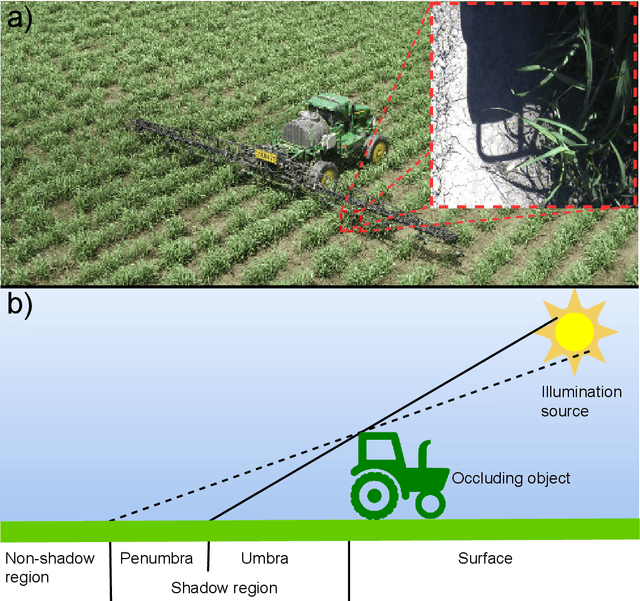
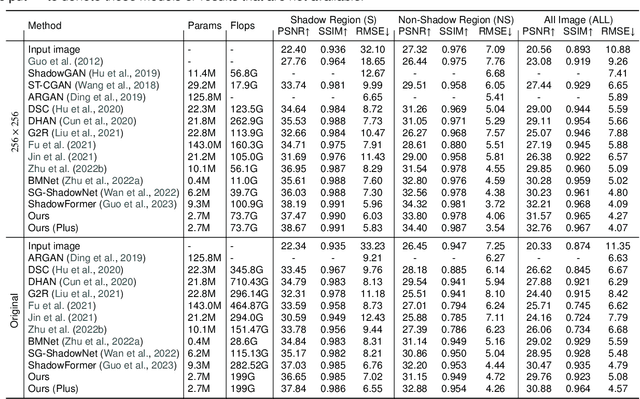
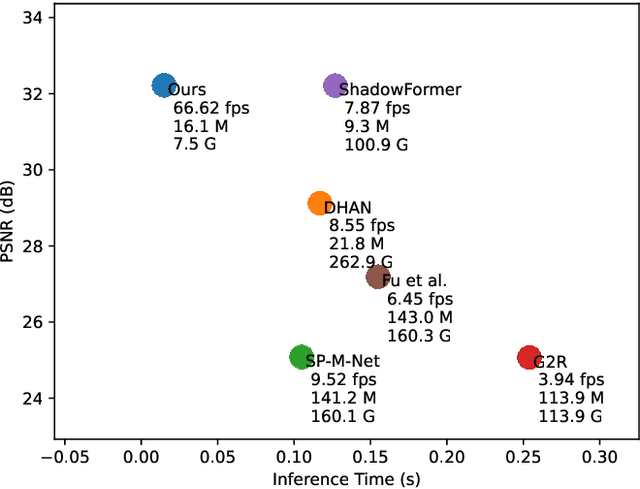
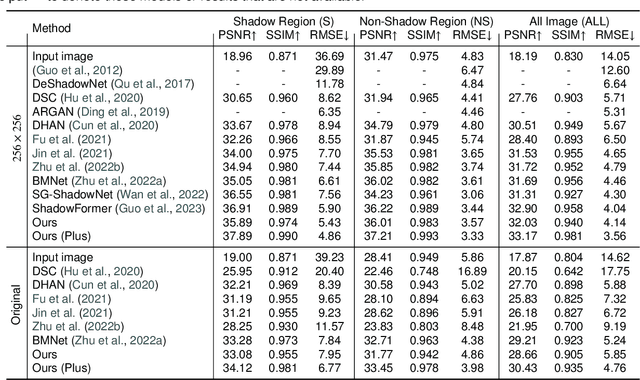
Shadows significantly impact computer vision tasks, particularly in outdoor environments. State-of-the-art shadow removal methods are typically too computationally intensive for real-time image processing on edge hardware. We propose ShadowRemovalNet, a novel method designed for real-time image processing on resource-constrained hardware. ShadowRemovalNet achieves significantly higher frame rates compared to existing methods, making it suitable for real-time computer vision pipelines like those used in field robotics. Beyond speed, ShadowRemovalNet offers advantages in efficiency and simplicity, as it does not require a separate shadow mask during inference. ShadowRemovalNet also addresses challenges associated with Generative Adversarial Networks (GANs) for shadow removal, including artefacts, inaccurate mask estimations, and inconsistent supervision between shadow and boundary pixels. To address these limitations, we introduce a novel loss function that substantially reduces shadow removal errors. ShadowRemovalNet's efficiency and straightforwardness make it a robust and effective solution for real-time shadow removal in outdoor robotics and edge computing applications.
Generalizable, Fast, and Accurate DeepQSPR with fastprop Part 1: Framework and Benchmarks
Apr 02, 2024Quantitative Structure Property Relationship studies aim to define a mapping between molecular structure and arbitrary quantities of interest. This was historically accomplished via the development of descriptors which requires significant domain expertise and struggles to generalize. Thus the field has morphed into Molecular Property Prediction and been given over to learned representations which are highly generalizable. The paper introduces fastprop, a DeepQSPR framework which uses a cogent set of molecular level descriptors to meet and exceed the performance of learned representations on diverse datasets in dramatically less time. fastprop is freely available on github at github.com/JacksonBurns/fastprop.
Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
Mar 21, 2024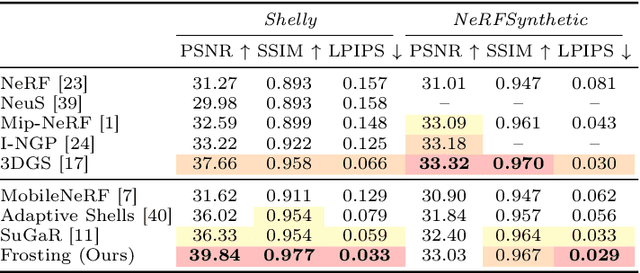
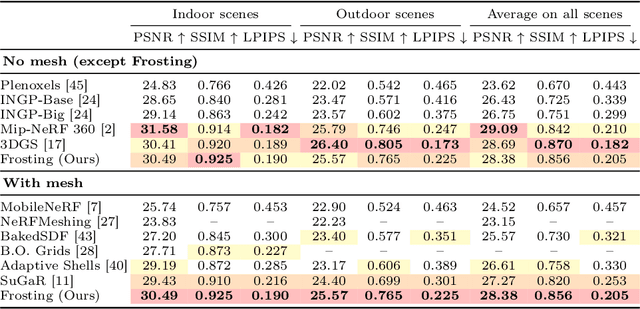
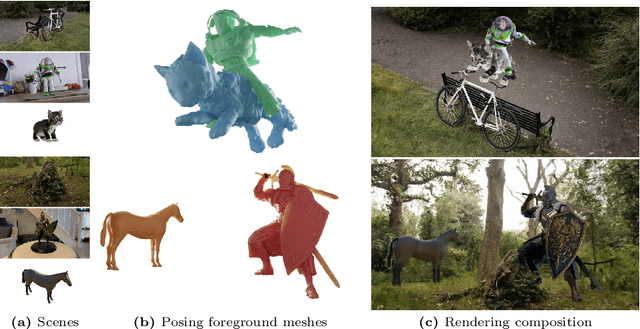
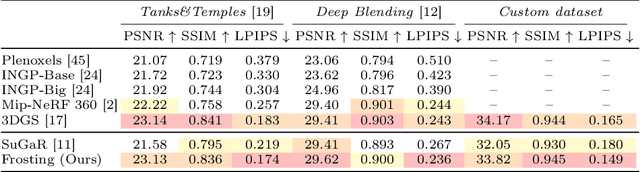
We propose Gaussian Frosting, a novel mesh-based representation for high-quality rendering and editing of complex 3D effects in real-time. Our approach builds on the recent 3D Gaussian Splatting framework, which optimizes a set of 3D Gaussians to approximate a radiance field from images. We propose first extracting a base mesh from Gaussians during optimization, then building and refining an adaptive layer of Gaussians with a variable thickness around the mesh to better capture the fine details and volumetric effects near the surface, such as hair or grass. We call this layer Gaussian Frosting, as it resembles a coating of frosting on a cake. The fuzzier the material, the thicker the frosting. We also introduce a parameterization of the Gaussians to enforce them to stay inside the frosting layer and automatically adjust their parameters when deforming, rescaling, editing or animating the mesh. Our representation allows for efficient rendering using Gaussian splatting, as well as editing and animation by modifying the base mesh. We demonstrate the effectiveness of our method on various synthetic and real scenes, and show that it outperforms existing surface-based approaches. We will release our code and a web-based viewer as additional contributions. Our project page is the following: https://anttwo.github.io/frosting/
Measuring audio prompt adherence with distribution-based embedding distances
Apr 04, 2024An increasing number of generative music models can be conditioned on an audio prompt that serves as musical context for which the model is to create an accompaniment (often further specified using a text prompt). Evaluation of how well model outputs adhere to the audio prompt is often done in a model or problem specific manner, presumably because no generic evaluation method for audio prompt adherence has emerged. Such a method could be useful both in the development and training of new models, and to make performance comparable across models. In this paper we investigate whether commonly used distribution-based distances like Fr\'echet Audio Distance (FAD), can be used to measure audio prompt adherence. We propose a simple procedure based on a small number of constituents (an embedding model, a projection, an embedding distance, and a data fusion method), that we systematically assess using a baseline validation. In a follow-up experiment we test the sensitivity of the proposed audio adherence measure to pitch and time shift perturbations. The results show that the proposed measure is sensitive to such perturbations, even when the reference and candidate distributions are from different music collections. Although more experimentation is needed to answer unaddressed questions like the robustness of the measure to acoustic artifacts that do not affect the audio prompt adherence, the current results suggest that distribution-based embedding distances provide a viable way of measuring audio prompt adherence. An python/pytorch implementation of the proposed measure is publicly available as a github repository.
Decentralized Learning Strategies for Estimation Error Minimization with Graph Neural Networks
Apr 04, 2024We address the challenge of sampling and remote estimation for autoregressive Markovian processes in a multi-hop wireless network with statistically-identical agents. Agents cache the most recent samples from others and communicate over wireless collision channels governed by an underlying graph topology. Our goal is to minimize time-average estimation error and/or age of information with decentralized scalable sampling and transmission policies, considering both oblivious (where decision-making is independent of the physical processes) and non-oblivious policies (where decision-making depends on physical processes). We prove that in oblivious policies, minimizing estimation error is equivalent to minimizing the age of information. The complexity of the problem, especially the multi-dimensional action spaces and arbitrary network topologies, makes theoretical methods for finding optimal transmission policies intractable. We optimize the policies using a graphical multi-agent reinforcement learning framework, where each agent employs a permutation-equivariant graph neural network architecture. Theoretically, we prove that our proposed framework exhibits desirable transferability properties, allowing transmission policies trained on small- or moderate-size networks to be executed effectively on large-scale topologies. Numerical experiments demonstrate that (i) Our proposed framework outperforms state-of-the-art baselines; (ii) The trained policies are transferable to larger networks, and their performance gains increase with the number of agents; (iii) The training procedure withstands non-stationarity even if we utilize independent learning techniques; and, (iv) Recurrence is pivotal in both independent learning and centralized training and decentralized execution, and improves the resilience to non-stationarity in independent learning.