 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Blobs to Spokes: High-Fidelity Surface Reconstruction via Oriented Gaussians
Apr 08, 20263D Gaussian Splatting (3DGS) has revolutionized fast novel view synthesis, yet its opacity-based formulation makes surface extraction fundamentally difficult. Unlike implicit methods built on Signed Distance Fields or occupancy, 3DGS lacks a global geometric field, forcing existing approaches to resort to heuristics such as TSDF fusion of blended depth maps. Inspired by the Objects as Volumes framework, we derive a principled occupancy field for Gaussian Splatting and show how it can be used to extract highly accurate watertight meshes of complex scenes. Our key contribution is to introduce a learnable oriented normal at each Gaussian element and to define an adapted attenuation formulation, which leads to closed-form expressions for both the normal and occupancy fields at arbitrary locations in space. We further introduce a novel consistency loss and a dedicated densification strategy to enforce Gaussians to wrap the entire surface by closing geometric holes, ensuring a complete shell of oriented primitives. We modify the differentiable rasterizer to output depth as an isosurface of our continuous model, and introduce Primal Adaptive Meshing for Region-of-Interest meshing at arbitrary resolution. We additionally expose fundamental biases in standard surface evaluation protocols and propose two more rigorous alternatives. Overall, our method Gaussian Wrapping sets a new state-of-the-art on DTU and Tanks and Temples, producing complete, watertight meshes at a fraction of the size of concurrent work-recovering thin structures such as the notoriously elusive bicycle spokes.
Detailed Geometry and Appearance from Opportunistic Motion
Mar 27, 2026Reconstructing 3D geometry and appearance from a sparse set of fixed cameras is a foundational task with broad applications, yet it remains fundamentally constrained by the limited viewpoints. We show that this bound can be broken by exploiting opportunistic object motion: as a person manipulates an object~(e.g., moving a chair or lifting a mug), the static cameras effectively ``orbit'' the object in its local coordinate frame, providing additional virtual viewpoints. Harnessing this object motion, however, poses two challenges: the tight coupling of object pose and geometry estimation and the complex appearance variations of a moving object under static illumination. We address these by formulating a joint pose and shape optimization using 2D Gaussian splatting with alternating minimization of 6DoF trajectories and primitive parameters, and by introducing a novel appearance model that factorizes diffuse and specular components with reflected directional probing within the spherical harmonics space. Extensive experiments on synthetic and real-world datasets with extremely sparse viewpoints demonstrate that our method recovers significantly more accurate geometry and appearance than state-of-the-art baselines.
MAGICIAN: Efficient Long-Term Planning with Imagined Gaussians for Active Mapping
Mar 23, 2026Active mapping aims to determine how an agent should move to efficiently reconstruct an unknown environment. Most existing approaches rely on greedy next-best-view prediction, resulting in inefficient exploration and incomplete scene reconstruction. To address this limitation, we introduce MAGICIAN, a novel long-term planning framework that maximizes accumulated surface coverage gain through Imagined Gaussians, a scene representation derived from a pre-trained occupancy network with strong structural priors. This representation enables efficient computation of coverage gain for any novel viewpoint via fast volumetric rendering, allowing its integration into a tree-search algorithm for long-horizon planning. We update Imagined Gaussians and refine the planned trajectory in a closed-loop manner. Our method achieves state-of-the-art performance across indoor and outdoor benchmarks with varying action spaces, demonstrating the critical advantage of long-term planning in active mapping.
NextBestPath: Efficient 3D Mapping of Unseen Environments
Feb 07, 2025



This work addresses the problem of active 3D mapping, where an agent must find an efficient trajectory to exhaustively reconstruct a new scene. Previous approaches mainly predict the next best view near the agent's location, which is prone to getting stuck in local areas. Additionally, existing indoor datasets are insufficient due to limited geometric complexity and inaccurate ground truth meshes. To overcome these limitations, we introduce a novel dataset AiMDoom with a map generator for the Doom video game, enabling to better benchmark active 3D mapping in diverse indoor environments. Moreover, we propose a new method we call next-best-path (NBP), which predicts long-term goals rather than focusing solely on short-sighted views. The model jointly predicts accumulated surface coverage gains for long-term goals and obstacle maps, allowing it to efficiently plan optimal paths with a unified model. By leveraging online data collection, data augmentation and curriculum learning, NBP significantly outperforms state-of-the-art methods on both the existing MP3D dataset and our AiMDoom dataset, achieving more efficient mapping in indoor environments of varying complexity.
MAtCha Gaussians: Atlas of Charts for High-Quality Geometry and Photorealism From Sparse Views
Dec 09, 2024



We present a novel appearance model that simultaneously realizes explicit high-quality 3D surface mesh recovery and photorealistic novel view synthesis from sparse view samples. Our key idea is to model the underlying scene geometry Mesh as an Atlas of Charts which we render with 2D Gaussian surfels (MAtCha Gaussians). MAtCha distills high-frequency scene surface details from an off-the-shelf monocular depth estimator and refines it through Gaussian surfel rendering. The Gaussian surfels are attached to the charts on the fly, satisfying photorealism of neural volumetric rendering and crisp geometry of a mesh model, i.e., two seemingly contradicting goals in a single model. At the core of MAtCha lies a novel neural deformation model and a structure loss that preserve the fine surface details distilled from learned monocular depths while addressing their fundamental scale ambiguities. Results of extensive experimental validation demonstrate MAtCha's state-of-the-art quality of surface reconstruction and photorealism on-par with top contenders but with dramatic reduction in the number of input views and computational time. We believe MAtCha will serve as a foundational tool for any visual application in vision, graphics, and robotics that require explicit geometry in addition to photorealism. Our project page is the following: https://anttwo.github.io/matcha/
Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
Mar 21, 2024We propose Gaussian Frosting, a novel mesh-based representation for high-quality rendering and editing of complex 3D effects in real-time. Our approach builds on the recent 3D Gaussian Splatting framework, which optimizes a set of 3D Gaussians to approximate a radiance field from images. We propose first extracting a base mesh from Gaussians during optimization, then building and refining an adaptive layer of Gaussians with a variable thickness around the mesh to better capture the fine details and volumetric effects near the surface, such as hair or grass. We call this layer Gaussian Frosting, as it resembles a coating of frosting on a cake. The fuzzier the material, the thicker the frosting. We also introduce a parameterization of the Gaussians to enforce them to stay inside the frosting layer and automatically adjust their parameters when deforming, rescaling, editing or animating the mesh. Our representation allows for efficient rendering using Gaussian splatting, as well as editing and animation by modifying the base mesh. We demonstrate the effectiveness of our method on various synthetic and real scenes, and show that it outperforms existing surface-based approaches. We will release our code and a web-based viewer as additional contributions. Our project page is the following: https://anttwo.github.io/frosting/
SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering
Dec 02, 2023



We propose a method to allow precise and extremely fast mesh extraction from 3D Gaussian Splatting. Gaussian Splatting has recently become very popular as it yields realistic rendering while being significantly faster to train than NeRFs. It is however challenging to extract a mesh from the millions of tiny 3D gaussians as these gaussians tend to be unorganized after optimization and no method has been proposed so far. Our first key contribution is a regularization term that encourages the gaussians to align well with the surface of the scene. We then introduce a method that exploits this alignment to extract a mesh from the Gaussians using Poisson reconstruction, which is fast, scalable, and preserves details, in contrast to the Marching Cubes algorithm usually applied to extract meshes from Neural SDFs. Finally, we introduce an optional refinement strategy that binds gaussians to the surface of the mesh, and jointly optimizes these Gaussians and the mesh through Gaussian splatting rendering. This enables easy editing, sculpting, rigging, animating, compositing and relighting of the Gaussians using traditional softwares by manipulating the mesh instead of the gaussians themselves. Retrieving such an editable mesh for realistic rendering is done within minutes with our method, compared to hours with the state-of-the-art methods on neural SDFs, while providing a better rendering quality. Our project page is the following: https://anttwo.github.io/sugar/
MACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision
Mar 06, 2023



We introduce a method that simultaneously learns to explore new large environments and to reconstruct them in 3D from color images only. This is closely related to the Next Best View problem (NBV), where one has to identify where to move the camera next to improve the coverage of an unknown scene. However, most of the current NBV methods rely on depth sensors, need 3D supervision and/or do not scale to large scenes. Our method requires only a color camera and no 3D supervision. It simultaneously learns in a self-supervised fashion to predict a "volume occupancy field" from color images and, from this field, to predict the NBV. Thanks to this approach, our method performs well on new scenes as it is not biased towards any training 3D data. We demonstrate this on a recent dataset made of various 3D scenes and show it performs even better than recent methods requiring a depth sensor, which is not a realistic assumption for outdoor scenes captured with a flying drone.
SCONE: Surface Coverage Optimization in Unknown Environments by Volumetric Integration
Aug 22, 2022
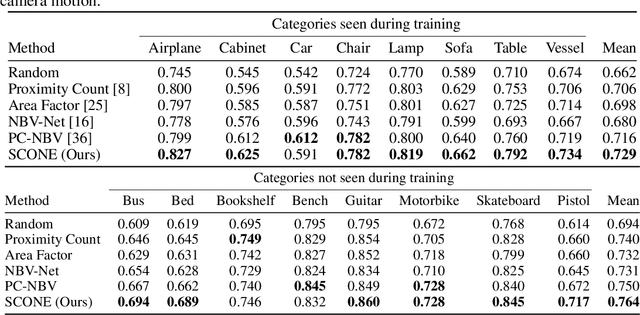
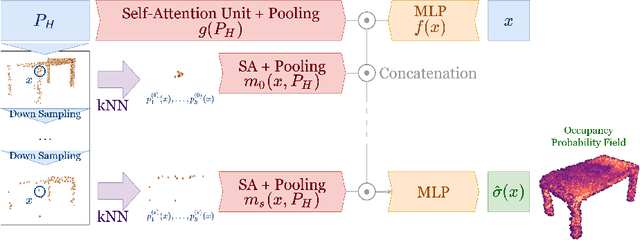
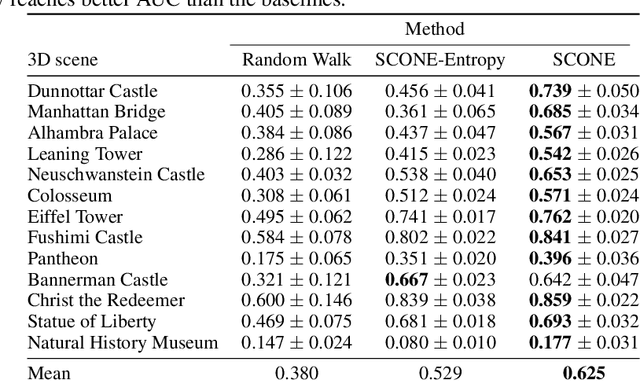
Next Best View computation (NBV) is a long-standing problem in robotics, and consists in identifying the next most informative sensor position(s) for reconstructing a 3D object or scene efficiently and accurately. Like most current methods, we consider NBV prediction from a depth sensor. Learning-based methods relying on a volumetric representation of the scene are suitable for path planning, but do not scale well with the size of the scene and have lower accuracy than methods using a surface-based representation. However, the latter constrain the camera to a small number of poses. To obtain the advantages of both representations, we show that we can maximize surface metrics by Monte Carlo integration over a volumetric representation. Our method scales to large scenes and handles free camera motion: It takes as input an arbitrarily large point cloud gathered by a depth sensor like Lidar systems as well as camera poses to predict NBV. We demonstrate our approach on a novel dataset made of large and complex 3D scenes.