 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Architectural Sweet Spots for Modeling Human Label Variation by the Example of Argument Quality: It's Best to Relate Perspectives!
Nov 06, 2023
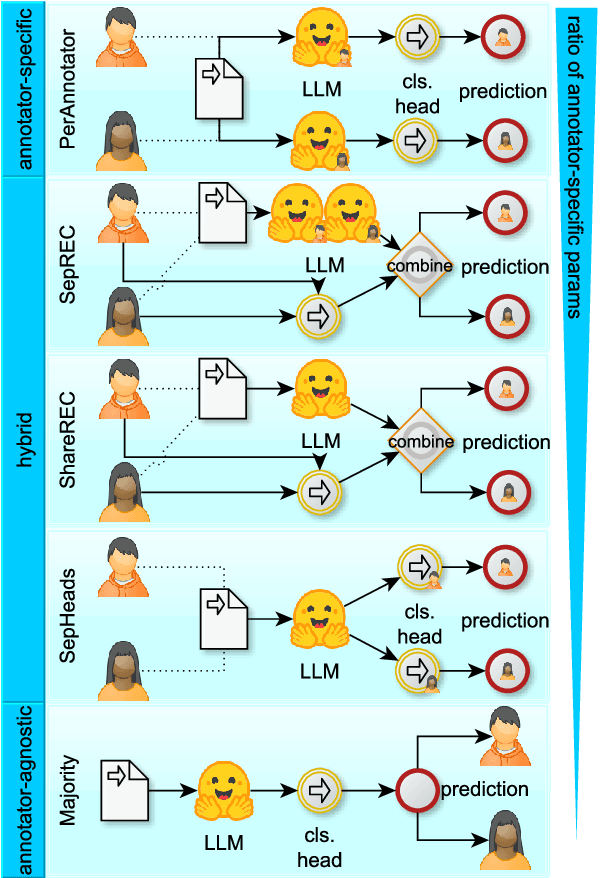
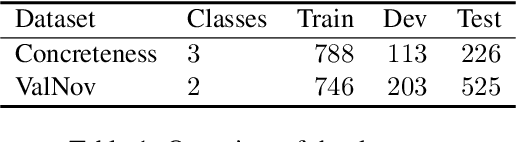
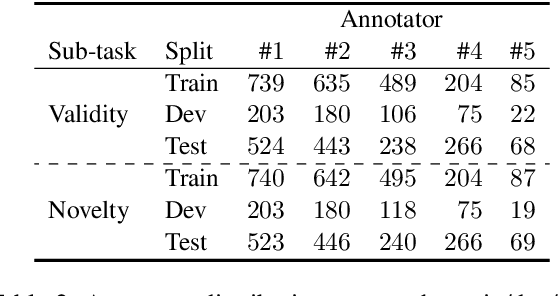
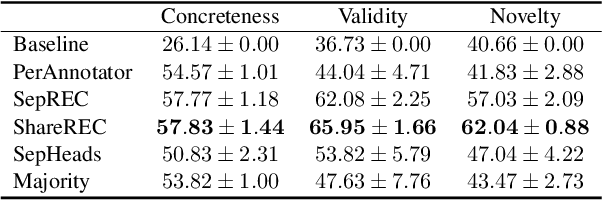
Many annotation tasks in natural language processing are highly subjective in that there can be different valid and justified perspectives on what is a proper label for a given example. This also applies to the judgment of argument quality, where the assignment of a single ground truth is often questionable. At the same time, there are generally accepted concepts behind argumentation that form a common ground. To best represent the interplay of individual and shared perspectives, we consider a continuum of approaches ranging from models that fully aggregate perspectives into a majority label to "share nothing"-architectures in which each annotator is considered in isolation from all other annotators. In between these extremes, inspired by models used in the field of recommender systems, we investigate the extent to which architectures that include layers to model the relations between different annotators are beneficial for predicting single-annotator labels. By means of two tasks of argument quality classification (argument concreteness and validity/novelty of conclusions), we show that recommender architectures increase the averaged annotator-individual F$_1$-scores up to $43\%$ over a majority label model. Our findings indicate that approaches to subjectivity can benefit from relating individual perspectives.
Obstacle- and Occlusion-Responsive Visual Tracking Control for Redundant Manipulators using Reachability Measure
Nov 06, 2023A vision system attached to a manipulator excels at tracing a moving target object while effectively handling obstacles, overcoming limitations arising from the camera's confined field of view and occluded line of sight. Meanwhile, the manipulator may encounter certain challenges, including restricted motion due to kinematic constraints and the risk of colliding with external obstacles. These challenges are typically addressed by assigning multiple task objectives to the manipulator. However, doing so can cause an increased risk of driving the manipulator to its kinematic limits, leading to failures in object tracking or obstacle avoidance. To address this issue, we propose a novel visual tracking control method for a redundant manipulator that takes the kinematic constraints into account via a reachability measure. Our method employs an optimization-based controller that considers object tracking, occlusion avoidance, collision avoidance, and the kinematic constraints represented by the reachability measure. Subsequently, it determines a suitable joint configuration through real-time inverse kinematics, accounting for dynamic obstacle avoidance and the continuity of joint configurations. To validate our approach, we conducted simulations and hardware experiments involving a moving target and dynamic obstacles. The results of our evaluations highlight the significance of incorporating the reachability measure.
BanLemma: A Word Formation Dependent Rule and Dictionary Based Bangla Lemmatizer
Nov 06, 2023Lemmatization holds significance in both natural language processing (NLP) and linguistics, as it effectively decreases data density and aids in comprehending contextual meaning. However, due to the highly inflected nature and morphological richness, lemmatization in Bangla text poses a complex challenge. In this study, we propose linguistic rules for lemmatization and utilize a dictionary along with the rules to design a lemmatizer specifically for Bangla. Our system aims to lemmatize words based on their parts of speech class within a given sentence. Unlike previous rule-based approaches, we analyzed the suffix marker occurrence according to the morpho-syntactic values and then utilized sequences of suffix markers instead of entire suffixes. To develop our rules, we analyze a large corpus of Bangla text from various domains, sources, and time periods to observe the word formation of inflected words. The lemmatizer achieves an accuracy of 96.36% when tested against a manually annotated test dataset by trained linguists and demonstrates competitive performance on three previously published Bangla lemmatization datasets. We are making the code and datasets publicly available at https://github.com/eblict-gigatech/BanLemma in order to contribute to the further advancement of Bangla NLP.
Fast and Interpretable Face Identification for Out-Of-Distribution Data Using Vision Transformers
Nov 06, 2023Most face identification approaches employ a Siamese neural network to compare two images at the image embedding level. Yet, this technique can be subject to occlusion (e.g. faces with masks or sunglasses) and out-of-distribution data. DeepFace-EMD (Phan et al. 2022) reaches state-of-the-art accuracy on out-of-distribution data by first comparing two images at the image level, and then at the patch level. Yet, its later patch-wise re-ranking stage admits a large $O(n^3 \log n)$ time complexity (for $n$ patches in an image) due to the optimal transport optimization. In this paper, we propose a novel, 2-image Vision Transformers (ViTs) that compares two images at the patch level using cross-attention. After training on 2M pairs of images on CASIA Webface (Yi et al. 2014), our model performs at a comparable accuracy as DeepFace-EMD on out-of-distribution data, yet at an inference speed more than twice as fast as DeepFace-EMD (Phan et al. 2022). In addition, via a human study, our model shows promising explainability through the visualization of cross-attention. We believe our work can inspire more explorations in using ViTs for face identification.
MultiSPANS: A Multi-range Spatial-Temporal Transformer Network for Traffic Forecast via Structural Entropy Optimization
Nov 06, 2023Traffic forecasting is a complex multivariate time-series regression task of paramount importance for traffic management and planning. However, existing approaches often struggle to model complex multi-range dependencies using local spatiotemporal features and road network hierarchical knowledge. To address this, we propose MultiSPANS. First, considering that an individual recording point cannot reflect critical spatiotemporal local patterns, we design multi-filter convolution modules for generating informative ST-token embeddings to facilitate attention computation. Then, based on ST-token and spatial-temporal position encoding, we employ the Transformers to capture long-range temporal and spatial dependencies. Furthermore, we introduce structural entropy theory to optimize the spatial attention mechanism. Specifically, The structural entropy minimization algorithm is used to generate optimal road network hierarchies, i.e., encoding trees. Based on this, we propose a relative structural entropy-based position encoding and a multi-head attention masking scheme based on multi-layer encoding trees. Extensive experiments demonstrate the superiority of the presented framework over several state-of-the-art methods in real-world traffic datasets, and the longer historical windows are effectively utilized. The code is available at https://github.com/SELGroup/MultiSPANS.
VET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Nov 08, 2023In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.
TWIST: Teacher-Student World Model Distillation for Efficient Sim-to-Real Transfer
Nov 07, 2023Model-based RL is a promising approach for real-world robotics due to its improved sample efficiency and generalization capabilities compared to model-free RL. However, effective model-based RL solutions for vision-based real-world applications require bridging the sim-to-real gap for any world model learnt. Due to its significant computational cost, standard domain randomisation does not provide an effective solution to this problem. This paper proposes TWIST (Teacher-Student World Model Distillation for Sim-to-Real Transfer) to achieve efficient sim-to-real transfer of vision-based model-based RL using distillation. Specifically, TWIST leverages state observations as readily accessible, privileged information commonly garnered from a simulator to significantly accelerate sim-to-real transfer. Specifically, a teacher world model is trained efficiently on state information. At the same time, a matching dataset is collected of domain-randomised image observations. The teacher world model then supervises a student world model that takes the domain-randomised image observations as input. By distilling the learned latent dynamics model from the teacher to the student model, TWIST achieves efficient and effective sim-to-real transfer for vision-based model-based RL tasks. Experiments in simulated and real robotics tasks demonstrate that our approach outperforms naive domain randomisation and model-free methods in terms of sample efficiency and task performance of sim-to-real transfer.
Enhanced Information Extraction from Cylindrical Visual-Tactile Sensors via Image Fusion
Nov 07, 2023Vision-based tactile sensors equipped with planar contact structures acquire the shape, force, and motion states of objects in contact. The limited planar contact area presents a challenge in acquiring information about larger target objects. In contrast, vision-based tactile sensors with cylindrical contact structures could extend the contact area by rolling, which can acquire much tactile information that exceeds the sensing projection area in a single contact. However, the tactile data acquired by cylindrical structures does not consistently correspond to the same depth level. Therefore, stitching and analyzing the data in an extended contact area is a challenging problem. In this work, we propose an image fusion method based on cylindrical vision-based tactile sensors. The method takes advantage of the changing characteristics of the contact depth of cylindrical structures, extracts the effective information of different contact depths in the frequency domain, and performs differential fusion for the information characteristics. The results show that in object contact confronting an area larger than single sensing, the images fused with our proposed method have higher information and structural similarity compared with the method of stitching based on motion distance sampling. Meanwhile, it is robust to sampling time. We complement this method with a deep neural network to illustrate its potential for fusing and recognizing object contact information using cylindrical vision-based tactile sensors.
Implementation and Comparison of Methods to Extract Reliability KPIs out of Textual Wind Turbine Maintenance Work Orders
Nov 07, 2023Maintenance work orders are commonly used to document information about wind turbine operation and maintenance. This includes details about proactive and reactive wind turbine downtimes, such as preventative and corrective maintenance. However, the information contained in maintenance work orders is often unstructured and difficult to analyze, making it challenging for decision-makers to use this information for optimizing operation and maintenance. To address this issue, this work presents three different approaches to calculate reliability key performance indicators from maintenance work orders. The first approach involves manual labeling of the maintenance work orders by domain experts, using the schema defined in an industrial guideline to assign the label accordingly. The second approach involves the development of a model that automatically labels the maintenance work orders using text classification methods. The third technique uses an AI-assisted tagging tool to tag and structure the raw maintenance information contained in the maintenance work orders. The resulting calculated reliability key performance indicator of the first approach are used as a benchmark for comparison with the results of the second and third approaches. The quality and time spent are considered as criteria for evaluation. Overall, these three methods make extracting maintenance information from maintenance work orders more efficient, enable the assessment of reliability key performance indicators and therefore support the optimization of wind turbine operation and maintenance.
Hardware Aware Evolutionary Neural Architecture Search using Representation Similarity Metric
Nov 07, 2023Hardware-aware Neural Architecture Search (HW-NAS) is a technique used to automatically design the architecture of a neural network for a specific task and target hardware. However, evaluating the performance of candidate architectures is a key challenge in HW-NAS, as it requires significant computational resources. To address this challenge, we propose an efficient hardware-aware evolution-based NAS approach called HW-EvRSNAS. Our approach re-frames the neural architecture search problem as finding an architecture with performance similar to that of a reference model for a target hardware, while adhering to a cost constraint for that hardware. This is achieved through a representation similarity metric known as Representation Mutual Information (RMI) employed as a proxy performance evaluator. It measures the mutual information between the hidden layer representations of a reference model and those of sampled architectures using a single training batch. We also use a penalty term that penalizes the search process in proportion to how far an architecture's hardware cost is from the desired hardware cost threshold. This resulted in a significantly reduced search time compared to the literature that reached up to 8000x speedups resulting in lower CO2 emissions. The proposed approach is evaluated on two different search spaces while using lower computational resources. Furthermore, our approach is thoroughly examined on six different edge devices under various hardware cost constraints.