 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Policy Learning for Linear Quadratic Regulator with Entropy Regularization
Nov 23, 2023
This paper proposes and analyzes two new policy learning methods: regularized policy gradient (RPG) and iterative policy optimization (IPO), for a class of discounted linear-quadratic regulator (LQR) problems over an infinite time horizon with entropy regularization. Assuming access to the exact policy evaluation, both proposed approaches are proved to converge linearly in finding optimal policies of the regularized LQR. Moreover, the IPO method can achieve a super-linear convergence rate once it enters a local region around the optimal policy. Finally, when the optimal policy from a well-understood environment in an RL problem is appropriately transferred as the initial policy to an RL problem with an unknown environment, the IPO method is shown to enable a super-linear convergence rate if the latter is sufficiently close to the former. The performances of these proposed algorithms are supported by numerical examples.
DGR: Tackling Drifted and Correlated Noise in Quantum Error Correction via Decoding Graph Re-weighting
Nov 27, 2023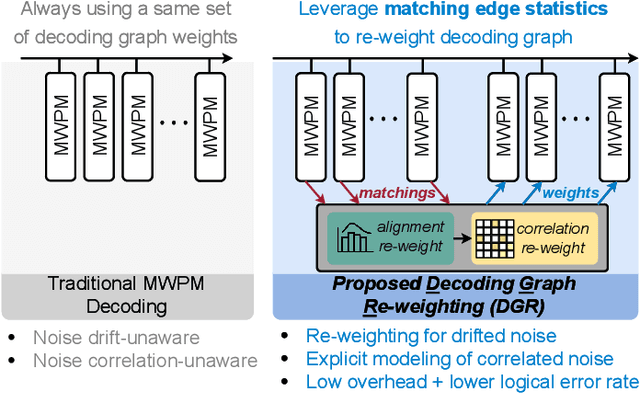
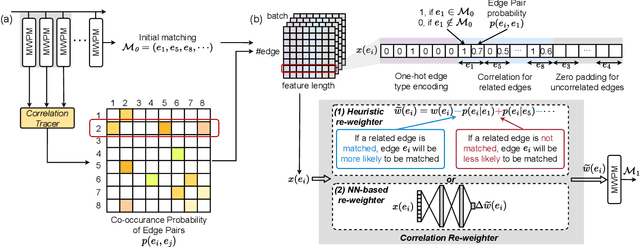
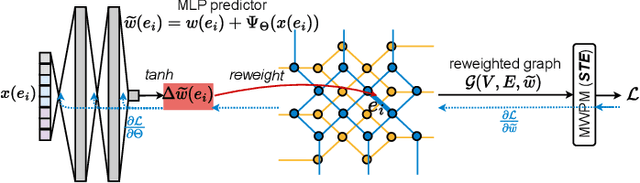
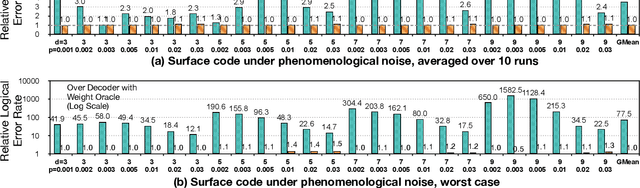
Quantum hardware suffers from high error rates and noise, which makes directly running applications on them ineffective. Quantum Error Correction (QEC) is a critical technique towards fault tolerance which encodes the quantum information distributively in multiple data qubits and uses syndrome qubits to check parity. Minimum-Weight-Perfect-Matching (MWPM) is a popular QEC decoder that takes the syndromes as input and finds the matchings between syndromes that infer the errors. However, there are two paramount challenges for MWPM decoders. First, as noise in real quantum systems can drift over time, there is a potential misalignment with the decoding graph's initial weights, leading to a severe performance degradation in the logical error rates. Second, while the MWPM decoder addresses independent errors, it falls short when encountering correlated errors typical on real hardware, such as those in the 2Q depolarizing channel. We propose DGR, an efficient decoding graph edge re-weighting strategy with no quantum overhead. It leverages the insight that the statistics of matchings across decoding iterations offer rich information about errors on real quantum hardware. By counting the occurrences of edges and edge pairs in decoded matchings, we can statistically estimate the up-to-date probabilities of each edge and the correlations between them. The reweighting process includes two vital steps: alignment re-weighting and correlation re-weighting. The former updates the MWPM weights based on statistics to align with actual noise, and the latter adjusts the weight considering edge correlations. Extensive evaluations on surface code and honeycomb code under various settings show that DGR reduces the logical error rate by 3.6x on average-case noise mismatch with exceeding 5000x improvement under worst-case mismatch.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
SpotServe: Serving Generative Large Language Models on Preemptible Instances
Nov 27, 2023The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them cheaply. This paper aims to reduce the monetary cost for serving LLMs by leveraging preemptible GPU instances on modern clouds, which offer accesses to spare GPUs at a much cheaper price than regular instances but may be preempted by the cloud at any time. Serving LLMs on preemptible instances requires addressing challenges induced by frequent instance preemptions and the necessity of migrating instances to handle these preemptions. This paper presents SpotServe, the first distributed LLM serving system on preemptible instances. Several key techniques in SpotServe realize fast and reliable serving of generative LLMs on cheap preemptible instances. First, SpotServe dynamically adapts the LLM parallelization configuration for dynamic instance availability and fluctuating workload, while balancing the trade-off among the overall throughput, inference latency and monetary costs. Second, to minimize the cost of migrating instances for dynamic reparallelization, the task of migrating instances is formulated as a bipartite graph matching problem, which uses the Kuhn-Munkres algorithm to identify an optimal migration plan that minimizes communications. Finally, to take advantage of the grace period offered by modern clouds, we introduce stateful inference recovery, a new inference mechanism that commits inference progress at a much finer granularity and allows SpotServe to cheaply resume inference upon preemption. We evaluate on real spot instance preemption traces and various popular LLMs and show that SpotServe can reduce the P99 tail latency by 2.4 - 9.1x compared with the best existing LLM serving systems. We also show that SpotServe can leverage the price advantage of preemptive instances, saving 54% monetary cost compared with only using on-demand instances.
Ultra-short-term multi-step wind speed prediction for wind farms based on adaptive noise reduction technology and temporal convolutional network
Nov 27, 2023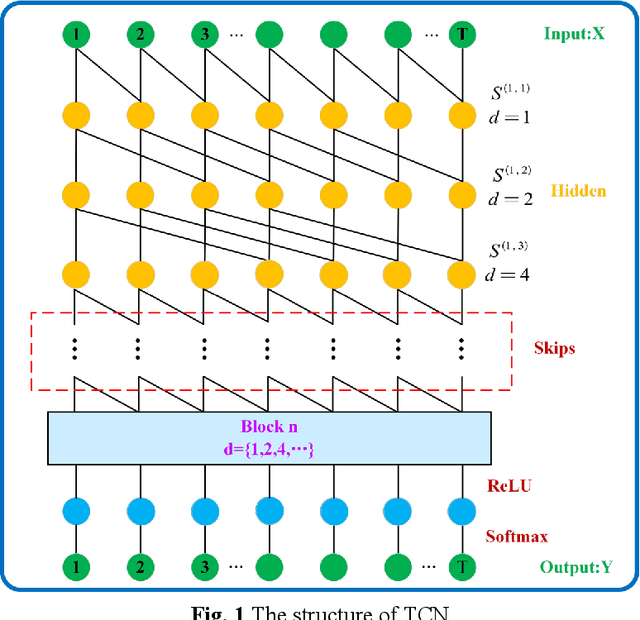
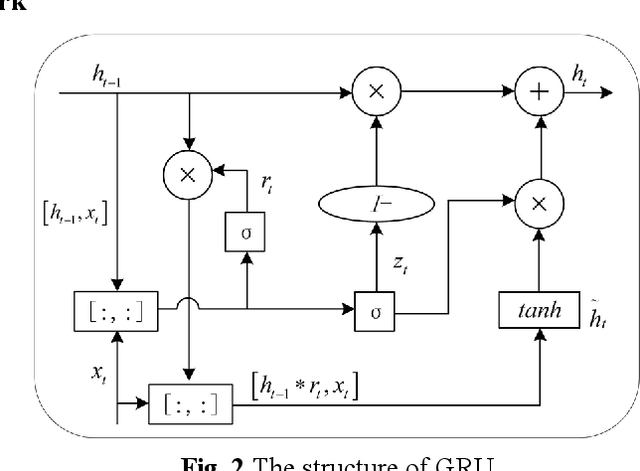

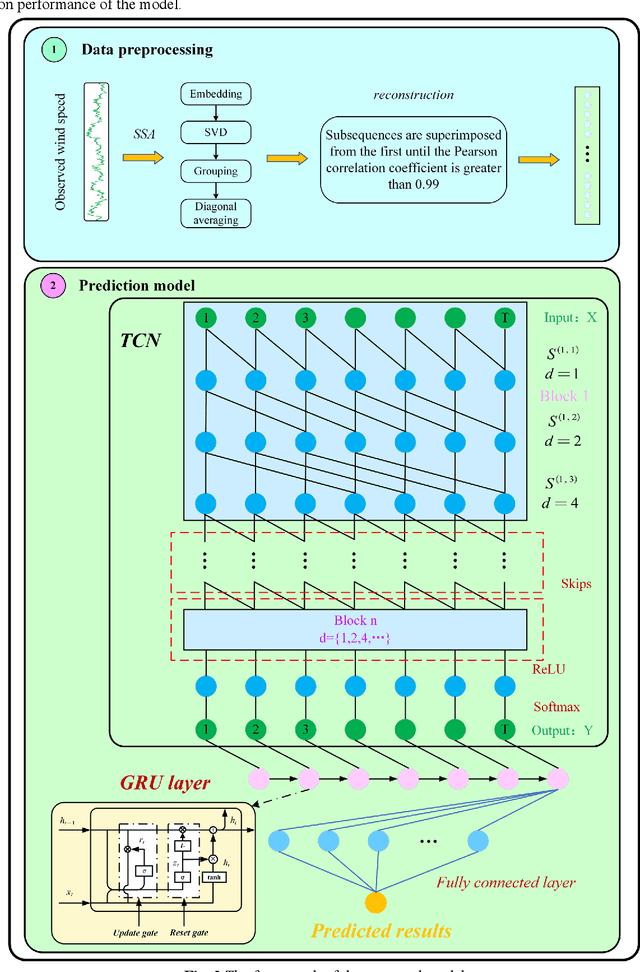
As an important clean and renewable kind of energy, wind power plays an important role in coping with energy crisis and environmental pollution. However, the volatility and intermittency of wind speed restrict the development of wind power. To improve the utilization of wind power, this study proposes a new wind speed prediction model based on data noise reduction technology, temporal convolutional network (TCN), and gated recurrent unit (GRU). Firstly, an adaptive data noise reduction algorithm P-SSA is proposed based on singular spectrum analysis (SSA) and Pearson correlation coefficient. The original wind speed is decomposed into multiple subsequences by SSA and then reconstructed. When the Pearson correlation coefficient between the reconstructed sequence and the original sequence is greater than 0.99, other noise subsequences are deleted to complete the data denoising. Then, the receptive field of the samples is expanded through the causal convolution and dilated convolution of TCN, and the characteristics of wind speed change are extracted. Then, the time feature information of the sequence is extracted by GRU, and then the wind speed is predicted to form the wind speed sequence prediction model of P-SSA-TCN-GRU. The proposed model was validated on three wind farms in Shandong Province. The experimental results show that the prediction performance of the proposed model is better than that of the traditional model and other models based on TCN, and the wind speed prediction of wind farms with high precision and strong stability is realized. The wind speed predictions of this model have the potential to become the data that support the operation and management of wind farms. The code is available at link.
"HoVer-UNet": Accelerating HoVerNet with UNet-based multi-class nuclei segmentation via knowledge distillation
Nov 21, 2023We present "HoVer-UNet", an approach to distill the knowledge of the multi-branch HoVerNet framework for nuclei instance segmentation and classification in histopathology. We propose a compact, streamlined single UNet network with a Mix Vision Transformer backbone, and equip it with a custom loss function to optimally encode the distilled knowledge of HoVerNet, reducing computational requirements without compromising performances. We show that our model achieved results comparable to HoVerNet on the public PanNuke and Consep datasets with a three-fold reduction in inference time. We make the code of our model publicly available at https://github.com/DIAGNijmegen/HoVer-UNet.
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
Future Full-Ocean Deep SSPs Prediction based on Hierarchical Long Short-Term Memory Neural Networks
Nov 16, 2023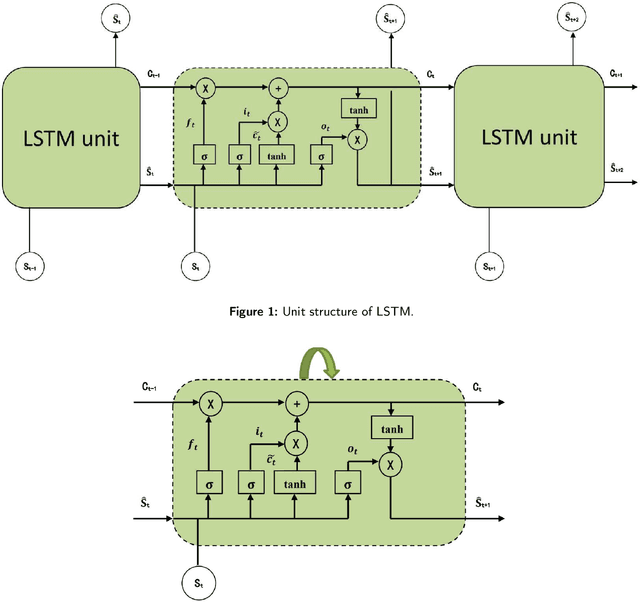


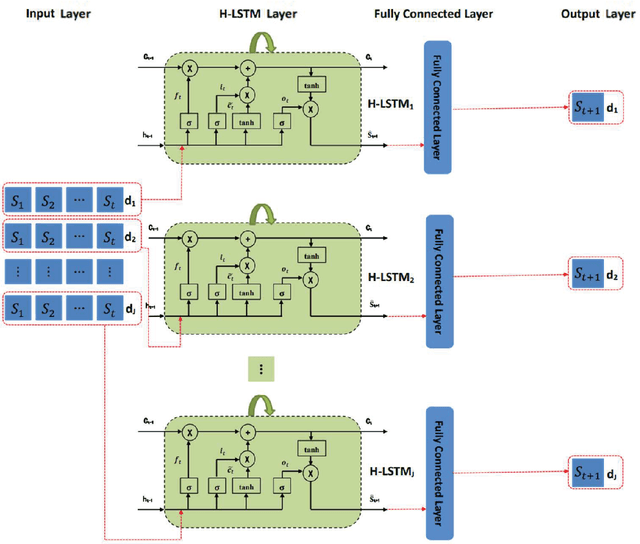
The spatial-temporal distribution of underwater sound velocity affects the propagation mode of underwater acoustic signals. Therefore, rapid estimation and prediction of underwater sound velocity distribution is crucial for providing underwater positioning, navigation and timing (PNT) services. Currently, sound speed profile (SSP) inversion methods have a faster time response rate compared to direct measurement methods, however, most SSP inversion methods focus on constructing spatial dimensional sound velocity fields and are highly dependent on sonar observation data, thus high requirements have been placed on observation data sources. To explore the distribution pattern of sound velocity in the time dimension and achieve future SSP prediction without sonar observation data, we propose a hierarchical long short-term memory (H-LSTM) neural network for SSP prediction. By our SSP prediction method, the sound speed distribution could be estimated without any on-site data measurement process, so that the time efficiency could be greatly improved. Through comparing with other state-of-the-art methods, H-LSTM has better accuracy performance on prediction of monthly average sound velocity distribution, which is less than 1 m/s in different depth layers.
Time-Optimal Trajectory Planning in Highway Scenarios using Basis-Spline Parameterization
Oct 05, 2023Basis splines enable a time-continuous feasibility check with a finite number of constraints. Constraints apply to the whole trajectory for motion planning applications that require a collision-free and dynamically feasible trajectory. Existing motion planners that rely on gradient-based optimization apply time scaling to implement a shrinking planning horizon. They neither guarantee a recursively feasible trajectory nor enable reaching two terminal manifold parts at different time scales. This paper proposes a nonlinear optimization problem that addresses the drawbacks of existing approaches. Therefore, the spline breakpoints are included in the optimization variables. Transformations between spline bases are implemented so a sparse problem formulation is achieved. A strategy for breakpoint removal enables the convergence into a terminal manifold. The evaluation in an overtaking scenario shows the influence of the breakpoint number on the solution quality and the time required for optimization.
Enhancing IoT Security via Automatic Network Traffic Analysis: The Transition from Machine Learning to Deep Learning
Nov 20, 2023This work provides a comparative analysis illustrating how Deep Learning (DL) surpasses Machine Learning (ML) in addressing tasks within Internet of Things (IoT), such as attack classification and device-type identification. Our approach involves training and evaluating a DL model using a range of diverse IoT-related datasets, allowing us to gain valuable insights into how adaptable and practical these models can be when confronted with various IoT configurations. We initially convert the unstructured network traffic data from IoT networks, stored in PCAP files, into images by processing the packet data. This conversion process adapts the data to meet the criteria of DL classification methods. The experiments showcase the ability of DL to surpass the constraints tied to manually engineered features, achieving superior results in attack detection and maintaining comparable outcomes in device-type identification. Additionally, a notable feature extraction time difference becomes evident in the experiments: traditional methods require around 29 milliseconds per data packet, while DL accomplishes the same task in just 2.9 milliseconds. The significant time gap, DL's superior performance, and the recognized limitations of manually engineered features, presents a compelling call to action within the IoT community. This encourages us to shift from exploring new IoT features for each dataset to addressing the challenges of integrating DL into IoT, making it a more efficient solution for real-world IoT scenarios.