 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Error Performance of Coded AFDM Systems in Doubly Selective Channels
Nov 27, 2023
Affine frequency division multiplexing (AFDM) is a strong candidate for the sixth-generation wireless network thanks to its strong resilience to delay-Doppler spreads. In this letter, we investigate the error performance of coded AFDM systems in doubly selective channels. We first study the conditional pairwise-error probability (PEP) of AFDM system and derive its conditional coding gain. Then, we show that there is a fundamental trade-off between the diversity gain and the coding gain of AFDM system, namely the coding gain declines with a descending speed with respect to the number of separable paths, while the diversity gain increases linearly. Moreover, we propose a near-optimal turbo decoder based on the sum-product algorithm for coded AFDM systems to improve its error performance. Simulation results verify our analyses and the effectiveness of the proposed turbo decoder, showing that AFDM outperforms orthogonal frequency division multiplexing (OFDM) and orthogonal time frequency space (OTFS) in both coded and uncoded cases over high-mobility channels.
Streaming Lossless Volumetric Compression of Medical Images Using Gated Recurrent Convolutional Neural Network
Nov 27, 2023Deep learning-based lossless compression methods offer substantial advantages in compressing medical volumetric images. Nevertheless, many learning-based algorithms encounter a trade-off between practicality and compression performance. This paper introduces a hardware-friendly streaming lossless volumetric compression framework, utilizing merely one-thousandth of the model weights compared to other learning-based compression frameworks. We propose a gated recurrent convolutional neural network that combines diverse convolutional structures and fusion gate mechanisms to capture the inter-slice dependencies in volumetric images. Based on such contextual information, we can predict the pixel-by-pixel distribution for entropy coding. Guided by hardware/software co-design principles, we implement the proposed framework on Field Programmable Gate Array to achieve enhanced real-time performance. Extensive experimental results indicate that our method outperforms traditional lossless volumetric compressors and state-of-the-art learning-based lossless compression methods across various medical image benchmarks. Additionally, our method exhibits robust generalization ability and competitive compression speed
A Convergence result of a continuous model of deep learning via Łojasiewicz--Simon inequality
Nov 26, 2023This study focuses on a Wasserstein-type gradient flow, which represents an optimization process of a continuous model of a Deep Neural Network (DNN). First, we establish the existence of a minimizer for an average loss of the model under $L^2$-regularization. Subsequently, we show the existence of a curve of maximal slope of the loss. Our main result is the convergence of flow to a critical point of the loss as time goes to infinity. An essential aspect of proving this result involves the establishment of the \L{}ojasiewicz--Simon gradient inequality for the loss. We derive this inequality by assuming the analyticity of NNs and loss functions. Our proofs offer a new approach for analyzing the asymptotic behavior of Wasserstein-type gradient flows for nonconvex functionals.
Exploring Lip Segmentation Techniques in Computer Vision: A Comparative Analysis
Nov 20, 2023Lip segmentation is crucial in computer vision, especially for lip reading. Despite extensive face segmentation research, lip segmentation has received limited attention. The aim of this study is to compare state-of-the-art lip segmentation models using a standardized setting and a publicly available dataset. Five techniques, namely EHANet, Mask2Former, BiSeNet V2, PIDNet, and STDC1, are qualitatively selected based on their reported performance, inference time, code availability, recency, and popularity. The CelebAMask-HQ dataset, comprising manually annotated face images, is used to fairly assess the lip segmentation performance of the selected models. Inference experiments are conducted on a Raspberry Pi4 to emulate limited computational resources. The results show that Mask2Former and EHANet have the best performances in terms of mIoU score. BiSeNet V2 demonstrate competitive performance, while PIDNet excels in recall but has lower precision. Most models present inference time ranging from 1000 to around 3000 milliseconds on a Raspberry Pi4, with PIDNet having the lowest mean inference time. This study provides a comprehensive evaluation of lip segmentation models, highlighting their performance and inference times. The findings contribute to the development of lightweight techniques and establish benchmarks for future advances in lip segmentation, especially in IoT and edge computing scenarios.
Gaussian Shell Maps for Efficient 3D Human Generation
Nov 29, 2023Efficient generation of 3D digital humans is important in several industries, including virtual reality, social media, and cinematic production. 3D generative adversarial networks (GANs) have demonstrated state-of-the-art (SOTA) quality and diversity for generated assets. Current 3D GAN architectures, however, typically rely on volume representations, which are slow to render, thereby hampering the GAN training and requiring multi-view-inconsistent 2D upsamplers. Here, we introduce Gaussian Shell Maps (GSMs) as a framework that connects SOTA generator network architectures with emerging 3D Gaussian rendering primitives using an articulable multi shell--based scaffold. In this setting, a CNN generates a 3D texture stack with features that are mapped to the shells. The latter represent inflated and deflated versions of a template surface of a digital human in a canonical body pose. Instead of rasterizing the shells directly, we sample 3D Gaussians on the shells whose attributes are encoded in the texture features. These Gaussians are efficiently and differentiably rendered. The ability to articulate the shells is important during GAN training and, at inference time, to deform a body into arbitrary user-defined poses. Our efficient rendering scheme bypasses the need for view-inconsistent upsamplers and achieves high-quality multi-view consistent renderings at a native resolution of $512 \times 512$ pixels. We demonstrate that GSMs successfully generate 3D humans when trained on single-view datasets, including SHHQ and DeepFashion.
AutArch: An AI-assisted workflow for object detection and automated recording in archaeological catalogues
Nov 29, 2023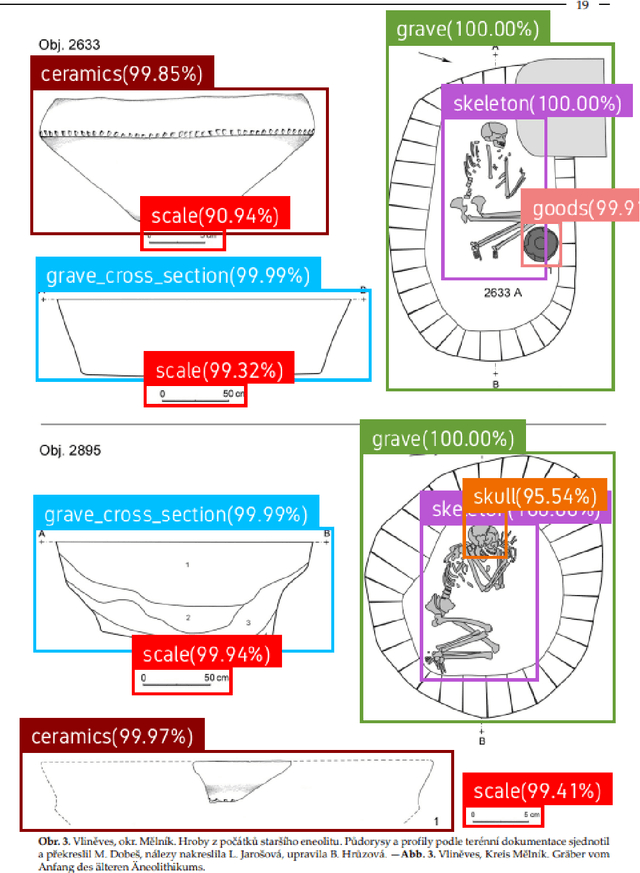

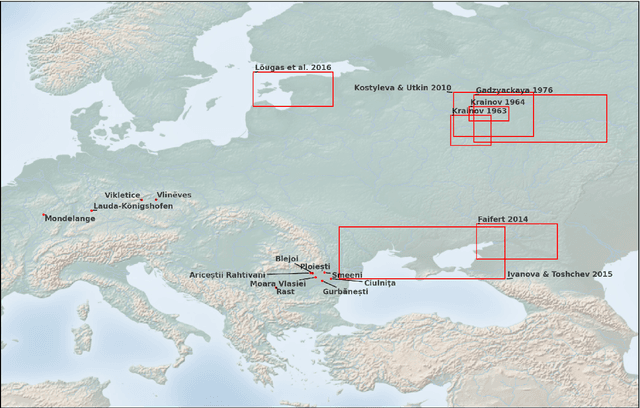

Compiling large datasets from published resources, such as archaeological find catalogues presents fundamental challenges: identifying relevant content and manually recording it is a time-consuming, repetitive and error-prone task. For the data to be useful, it must be of comparable quality and adhere to the same recording standards, which is hardly ever the case in archaeology. Here, we present a new data collection method exploiting recent advances in Artificial Intelligence. Our software uses an object detection neural network combined with further classification networks to speed up, automate, and standardise data collection from legacy resources, such as archaeological drawings and photographs in large unsorted PDF files. The AI-assisted workflow detects common objects found in archaeological catalogues, such as graves, skeletons, ceramics, ornaments, stone tools and maps, and spatially relates and analyses these objects on the page to extract real-life attributes, such as the size and orientation of a grave based on the north arrow and the scale. A graphical interface allows for and assists with manual validation. We demonstrate the benefits of this approach by collecting a range of shapes and numerical attributes from richly-illustrated archaeological catalogues, and benchmark it in a real-world experiment with ten users. Moreover, we record geometric whole-outlines through contour detection, an alternative to landmark-based geometric morphometrics not achievable by hand.
Guided Prompting in SAM for Weakly Supervised Cell Segmentation in Histopathological Images
Nov 29, 2023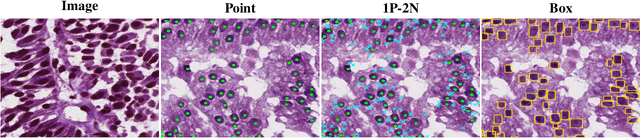
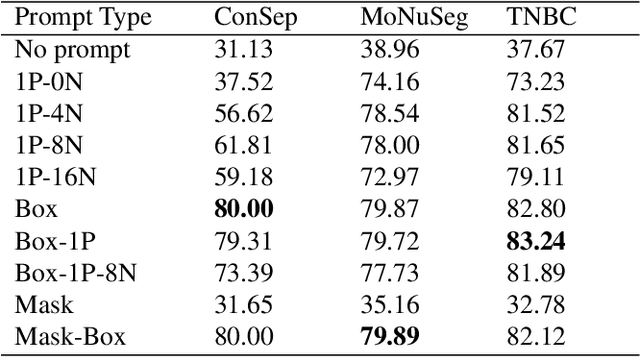
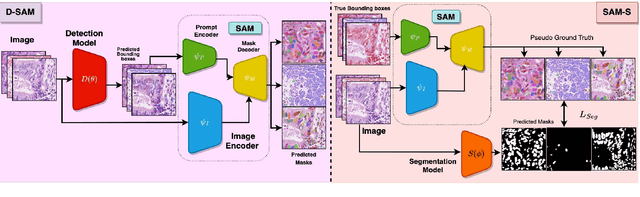
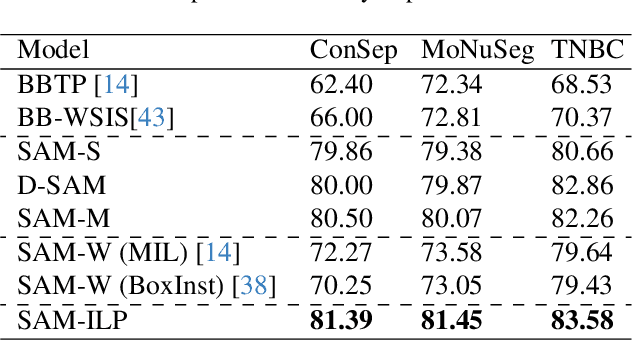
Cell segmentation in histopathological images plays a crucial role in understanding, diagnosing, and treating many diseases. However, data annotation for this is expensive since there can be a large number of cells per image, and expert pathologists are needed for labelling images. Instead, our paper focuses on using weak supervision -- annotation from related tasks -- to induce a segmenter. Recent foundation models, such as Segment Anything (SAM), can use prompts to leverage additional supervision during inference. SAM has performed remarkably well in natural image segmentation tasks; however, its applicability to cell segmentation has not been explored. In response, we investigate guiding the prompting procedure in SAM for weakly supervised cell segmentation when only bounding box supervision is available. We develop two workflows: (1) an object detector's output as a test-time prompt to SAM (D-SAM), and (2) SAM as pseudo mask generator over training data to train a standalone segmentation model (SAM-S). On finding that both workflows have some complementary strengths, we develop an integer programming-based approach to reconcile the two sets of segmentation masks, achieving yet higher performance. We experiment on three publicly available cell segmentation datasets namely, ConSep, MoNuSeg, and TNBC, and find that all SAM-based solutions hugely outperform existing weakly supervised image segmentation models, obtaining 9-15 pt Dice gains.
PatchBMI-Net: Lightweight Facial Patch-based Ensemble for BMI Prediction
Nov 29, 2023Due to an alarming trend related to obesity affecting 93.3 million adults in the United States alone, body mass index (BMI) and body weight have drawn significant interest in various health monitoring applications. Consequently, several studies have proposed self-diagnostic facial image-based BMI prediction methods for healthy weight monitoring. These methods have mostly used convolutional neural network (CNN) based regression baselines, such as VGG19, ResNet50, and Efficient-NetB0, for BMI prediction from facial images. However, the high computational requirement of these heavy-weight CNN models limits their deployment to resource-constrained mobile devices, thus deterring weight monitoring using smartphones. This paper aims to develop a lightweight facial patch-based ensemble (PatchBMI-Net) for BMI prediction to facilitate the deployment and weight monitoring using smartphones. Extensive experiments on BMI-annotated facial image datasets suggest that our proposed PatchBMI-Net model can obtain Mean Absolute Error (MAE) in the range [3.58, 6.51] with a size of about 3.3 million parameters. On cross-comparison with heavyweight models, such as ResNet-50 and Xception, trained for BMI prediction from facial images, our proposed PatchBMI-Net obtains equivalent MAE along with the model size reduction of about 5.4x and the average inference time reduction of about 3x when deployed on Apple-14 smartphone. Thus, demonstrating performance efficiency as well as low latency for on-device deployment and weight monitoring using smartphone applications.
Gene-MOE: A Sparsely-gated Framework for Pan-Cancer Genomic Analysis
Nov 29, 2023Analyzing the genomic information from the Pan-Cancer database can help us understand cancer-related factors and contribute to the cancer diagnosis and prognosis. However, existing computational methods and deep learning methods can not effectively find the deep correlations between tens of thousands of genes, which leads to precision loss. In this paper, we proposed a novel pretrained model called Gene-MOE to learn the general feature representations of the Pan-Cancer dataset and transfer the pretrained weights to the downstream tasks. The Gene-MOE fully exploits the mixture of expert (MOE) layers to learn rich feature representations of high-dimensional genes. At the same time, we build a mixture of attention expert (MOAE) model to learn the deep semantic relationships within genetic features. Finally, we proposed a new self-supervised pretraining strategy including loss function design, data enhancement, and optimization strategy to train the Gene-MOE and further improve the performance for the downstream analysis. We carried out cancer classification and survival analysis experiments based on the Gene-MOE. According to the survival analysis results on 14 cancer types, using Gene-MOE outperformed state-of-the-art models on 12 cancer types. According to the classification results, the total accuracy of the classification model for 33 cancer classifications reached 95.2\%. Through detailed feature analysis, we found the Gene-MOE model can learn rich feature representations of high-dimensional genes.
The Trifecta: Three simple techniques for training deeper Forward-Forward networks
Nov 29, 2023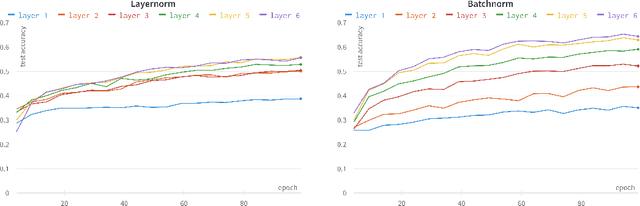
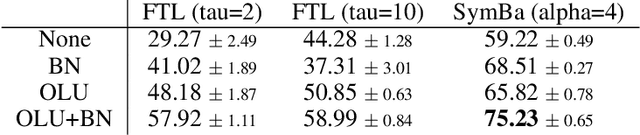
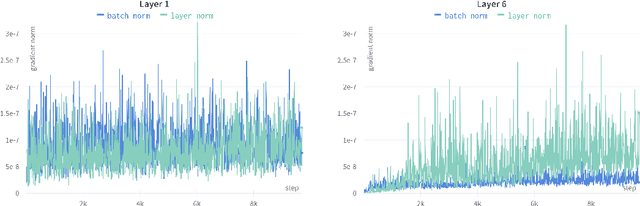
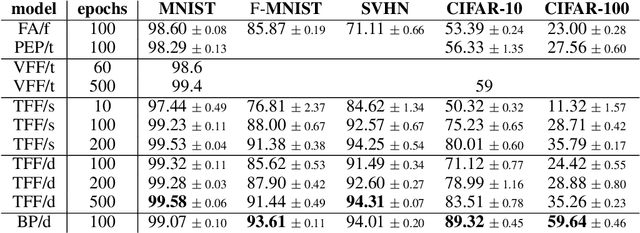
Modern machine learning models are able to outperform humans on a variety of non-trivial tasks. However, as the complexity of the models increases, they consume significant amounts of power and still struggle to generalize effectively to unseen data. Local learning, which focuses on updating subsets of a model's parameters at a time, has emerged as a promising technique to address these issues. Recently, a novel local learning algorithm, called Forward-Forward, has received widespread attention due to its innovative approach to learning. Unfortunately, its application has been limited to smaller datasets due to scalability issues. To this end, we propose The Trifecta, a collection of three simple techniques that synergize exceptionally well and drastically improve the Forward-Forward algorithm on deeper networks. Our experiments demonstrate that our models are on par with similarly structured, backpropagation-based models in both training speed and test accuracy on simple datasets. This is achieved by the ability to learn representations that are informative locally, on a layer-by-layer basis, and retain their informativeness when propagated to deeper layers in the architecture. This leads to around 84\% accuracy on CIFAR-10, a notable improvement (25\%) over the original FF algorithm. These results highlight the potential of Forward-Forward as a genuine competitor to backpropagation and as a promising research avenue.